The document discusses the development of word2vec, a model for representing words in vector space to improve natural language processing tasks. It covers previous methods of word representation, introduces the continuous-bag-of-words and skip-gram models, and describes enhancements like negative sampling and subsampling. The findings demonstrate that word2vec offers more efficient and accurate word representations compared to traditional methods.








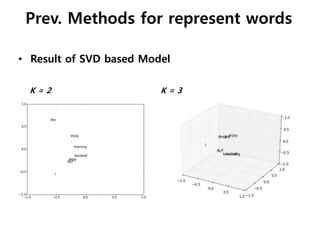
![• Another problem of discrete representation
• Can’t gives similarity
• Too sparse
e.g. Horse = [ 0 0 0 0 1 0 0 0 0 0 0 0 0 0 ]
Zebra = [ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 ]
“one-hot” representation: Typical, simple representation.
All 0s with one 1, Identical
Horse ∩ Zebra
= [ 0 0 0 0 1 0 0 0 0 0 0 0 0 0 ] ∩ [ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 ]
= 0 (nothing) (But, we know does are mammal)
- Discrete Representation
Mammal
Prev. Methods for represent words](https://image.slidesharecdn.com/word2vecslidejplee-151125062502-lva1-app6891/85/Word2vec-slide-lab-seminar-9-320.jpg)










![CBOW (Original)
• Continuous-Bag-of-word model
• Input
• “one-hot” word vector
• Remove nonlinear hidden layer
• Back-propagate error from
output layer to Weight matrix
(Adjust W s)
It
is
finish
to
time
[
0
1
0
0
0
]
Wout T∙h =
𝒚(predicted)
[0 0 1 0 0]T
Win
∙
h
Win ∙ x i
[0 0 0 0 1]T
Win
∙
y(true) =
Backpropagate to
Minimize error
vs
Win(old) Wout(old)
Win(new) Wout(new)
Win
,Wout
∈ ℝ 𝑛×|𝑉|
: Input, output Weight
-matrix, n is dimension for word embedding
x 𝑖
, 𝑦 𝑖
: input, output word vector
(one-hot) from vocabulary V
ℎ: hidden vector, avg of W*x
[NxV]*[Vx1] [Nx1] [VxN]*[Nx1] [Vx1]
Initial input, not results
14/31](https://image.slidesharecdn.com/word2vecslidejplee-151125062502-lva1-app6891/85/Word2vec-slide-lab-seminar-22-320.jpg)
![• Skip-gram model
• Idea: With center word,
we can predict context words
• Mirror of CBOW (vice versa)
i.e. Probability( “time” “It is ( ? ) to finish” )
• Loss-function:
Skip-Gram (Original)
𝐸 = − log 𝑝(𝑤𝑡−𝐶. . 𝑤𝑡+𝐶|𝑤𝑡)
time
It
is
to
finish
Win ∙ x i
h
y i
Win(old) Wout(old)
Win(new) Wout(new)
[NxV]*[Vx1] [Nx1] [VxN]*[Nx1] [Vx1]
CBOW: 𝐸 = − log 𝑝(𝑤𝑡|𝑤𝑡−𝐶. . 𝑤𝑡+𝐶)
15/31](https://image.slidesharecdn.com/word2vecslidejplee-151125062502-lva1-app6891/85/Word2vec-slide-lab-seminar-23-320.jpg)




























![[BEDROCK] Claude Prompt Engineering Techniques.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bedrockclaudepromptengineeringtechniques-231213183236-1d873607-thumbnail.jpg?width=640&height=640&fit=bounds)









































































