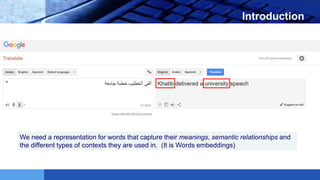
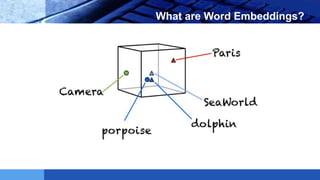
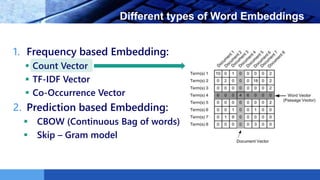
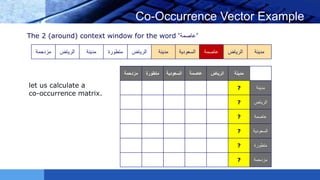
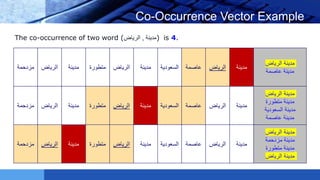
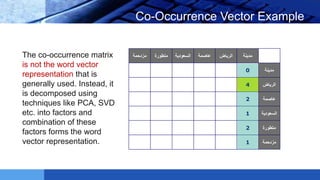
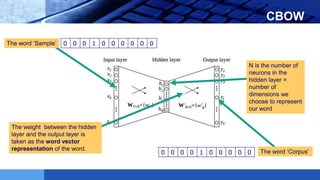
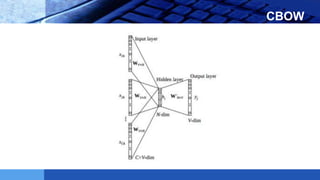
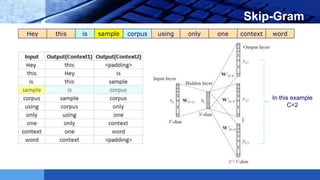
This document provides an introduction to word embeddings in deep learning. It defines word embeddings as vectors of real numbers that represent words, where similar words have similar vector representations. Word embeddings are needed because they allow words to be treated as numeric inputs for machine learning algorithms. The document outlines different types of word embeddings, including frequency-based methods like count vectors and co-occurrence matrices, and prediction-based methods like CBOW and skip-gram models from Word2Vec. It also discusses tools for generating word embeddings like Word2Vec, GloVe, and fastText. Finally, it provides a tutorial on implementing Word2Vec in Python using Gensim.





![LOGO Example of Simple Method
sentence=
” Word Embeddings are Word converted into numbers ”
dictionary =
[‘Word’,’Embeddings’,’are’,’Converted’,’into’,’numbers’]
The vector representation of “numbers” in a one-hot encoded vector
encoded vector according to the above dictionary is:
“numbers” [0,0,0,0,0,1]](https://image.slidesharecdn.com/word-embeddings-workshop-180213165515/85/Word-embeddings-workshop-8-320.jpg)
















![LOGO Word2Vec Tutorial
Use the following python codes to do each step:
7. Getting word vector of a word:
print(model[‘)]’محمد
8. picking odd word out:
print(model.doesnt_match(" السبع السماوات
الجبال االرضمكه ".split()))
9. Load a pre-trained model:
model =
gensim.models.KeyedVectors.load_word2vec_f
ormat(‘…/workshop.bin', binary=True)](https://image.slidesharecdn.com/word-embeddings-workshop-180213165515/85/Word-embeddings-workshop-32-320.jpg)

























![[2019] Class-based N-gram Models of Natural Language](https://cdn.slidesharecdn.com/ss_thumbnails/victorialawlor2019-190124160303-thumbnail.jpg?width=640&height=640&fit=bounds)
































































