Download to read offline













![• Given a matrix of m × n dimensionality, construct a m × k matrix, where k << n
• M = U Σ VT
• U is an m × m orthogonal matrix (UUT = I)
• Σ is a m × n diagonal matrix, with diagonal values ordered from largest to smallest (σ1 ≥
σ2 ≥ · · · ≥ σr ≥ 0, where r = min(m, n)) [σi’s are known as singular values]
• V is an n × n orthogonal matrix (VVT = I)
• We construct M’ s.t. rank(M’) = k
• We compute M’ = U Σ’ V, where Σ’ = Σ with k largest singular values
• k captures desired percentage variance
• Then, submatrix U v,k is our desired word embedding matrix.
14](https://image.slidesharecdn.com/dlblrtalk-170528144612-170529051245/85/Deep-Learning-Bangalore-meet-up-14-320.jpg)



















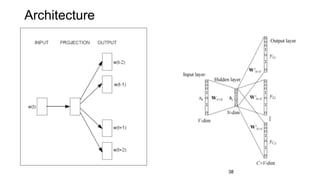





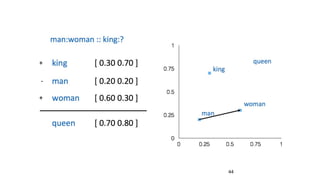






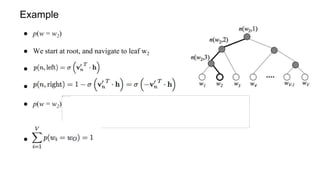














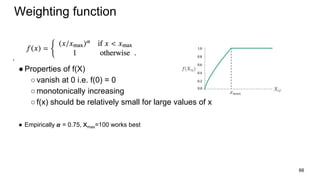








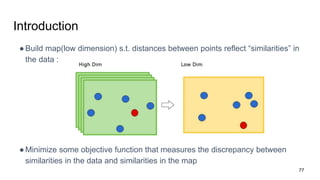
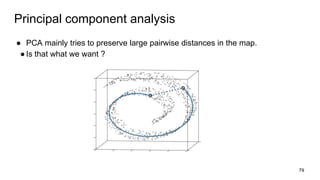
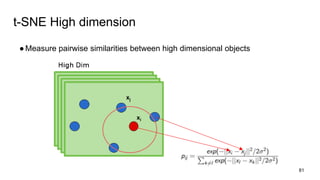
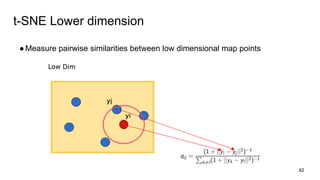






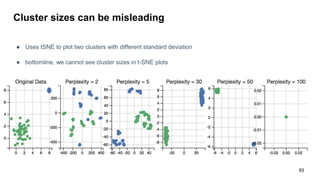

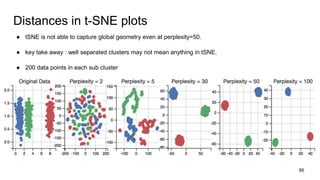
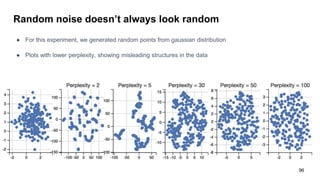
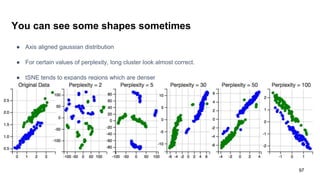



















The document discusses representation learning in natural language processing (NLP), focusing on word vectors and models such as Word2Vec, GloVe, and the concept of semantic similarity derived from co-occurrence in text. It covers techniques, including bigram, continuous bag of words (CBOW), and skip-gram models, alongside evaluation methods for assessing word vector quality. Furthermore, it addresses the computational challenges in training these models and methods to enhance efficiency, such as hierarchical softmax and negative sampling.



































































