Download as PDF, PPTX




![[Jussi Karlgren, NLP Sthlm Meetup 2014]](https://image.slidesharecdn.com/280415deeplearningforinformationretrieval-150428090255-conversion-gate02/85/Deep-Learning-for-Information-Retrieval-5-320.jpg)



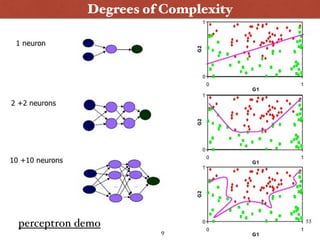

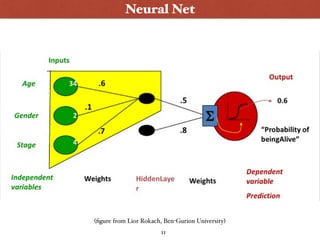










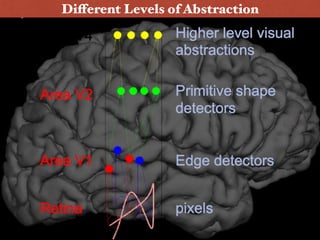

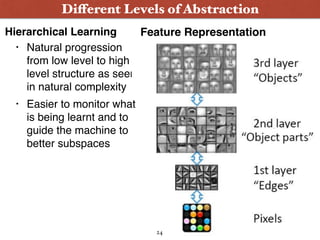



![[Kudos to Richard Socher, for this eloquent summary :) ]
• Manually designed features are often over-specified, incomplete
and take a long time to design and validate
• Learned Features are easy to adapt, fast to learn
• Deep learning provides a very flexible, (almost?) universal,
learnable framework for representing world, visual and
linguistic information.
• Deep learning can learn unsupervised (from raw text/audio/
images/whatever content) and supervised (with specific labels
like positive/negative)
Why Deep Learning ?
29](https://image.slidesharecdn.com/280415deeplearningforinformationretrieval-150428090255-conversion-gate02/85/Deep-Learning-for-Information-Retrieval-29-320.jpg)


![• NLP treats words mainly (rule-based/statistical
approaches at least) as atomic symbols:
• or in vector space:
• also known as “one hot” representation.
• Its problem ?
Language Representation
Love Candy Store
[0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 …]
Candy [0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 …] AND
Store [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 …] = 0 !
32](https://image.slidesharecdn.com/280415deeplearningforinformationretrieval-150428090255-conversion-gate02/85/Deep-Learning-for-Information-Retrieval-32-320.jpg)



























































This document provides an overview of deep learning for information retrieval. It begins with background on the speaker and discusses how the data landscape is changing with increasing amounts of diverse data types. It then introduces neural networks and how deep learning can learn hierarchical representations from data. Key aspects of deep learning that help with natural language processing tasks like word embeddings and modeling compositionality are discussed. Several influential papers that advanced word embeddings and recursive neural networks are also summarized.

















































































