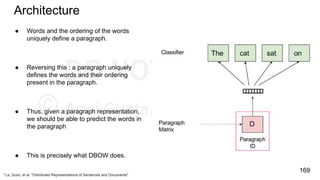
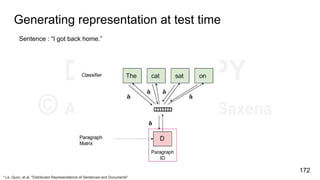
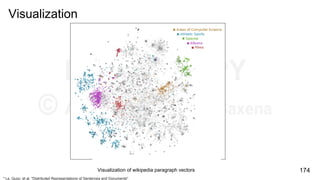
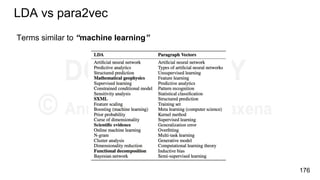
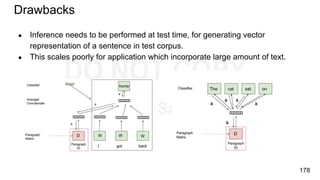
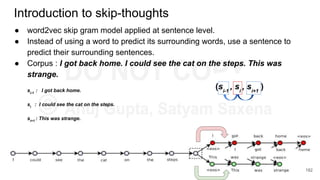
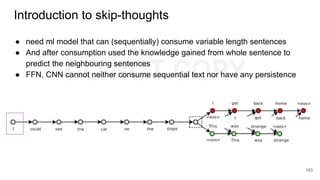
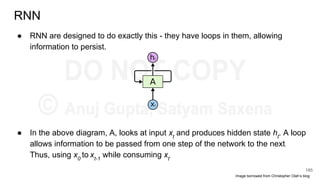
Download as PDF, PPTX













![• Use word ID, to get a basic representation of
word through.
• This is done via one-hot encoding of the ID
• one-hot vector of an ID is a vector filled with 0s,
except for a 1 at the position associated with the
ID.
• ex.: for vocabulary size D=10, the one-hot
vector of word (w) ID=4 is e(w) = [ 0 0 0 1 0
0 0 0 0 0 ]
• a one-hot encoding makes no assumption about
word similarity
• all words are equally similar/different from
each other
• this is a natural representation to start with,
though a poor one
23](https://image.slidesharecdn.com/anthillinsideworkshoponnlp-170731110125/85/Representation-Learning-of-Text-for-NLP-23-320.jpg)
























![• Given a matrix of m × n dimensionality, construct a m × k matrix, where k << n
• M = U Σ VT
• U is an m × m orthogonal matrix (UUT
= I)
• Σ is a m × n diagonal matrix, with diagonal values ordered from largest to smallest (σ1
≥
σ2
≥ · · · ≥ σr
≥ 0, where r = min(m, n)) [σi
’s are known as singular values]
• V is an n × n orthogonal matrix (VVT
= I)
• We construct M’
s.t. rank(M’
) = k
•We compute M’
= U Σ
’
V, where Σ’
= Σ with k largest singular values
• k captures desired percentage variance
• Then, submatrix U v,k
is our desired word embedding matrix.
51](https://image.slidesharecdn.com/anthillinsideworkshoponnlp-170731110125/85/Representation-Learning-of-Text-for-NLP-51-320.jpg)

















































































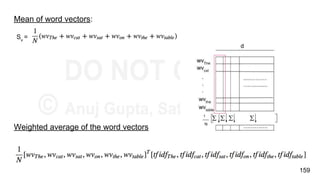
![Possible Solutions
Sentence (S) - “The cat sat on the table”
Concatenation : Our sentence is one word followed by another.
So, its representation can be - word vectors for every word in sentence in same
order.
Sv
= [wvThe
wvcat
wvsat
wvon
wvthe
wvtable
]
Each word is represented by a d-dimensional vector, so a sentence with k words
has k X d dimensions.
Problem : Different sentences in corpus will have different lengths. Most ML
models work with fixed length input.
158](https://image.slidesharecdn.com/anthillinsideworkshoponnlp-170731110125/85/Representation-Learning-of-Text-for-NLP-158-320.jpg)




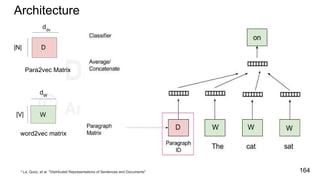


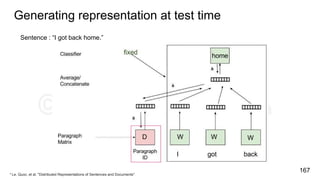










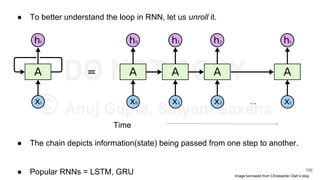









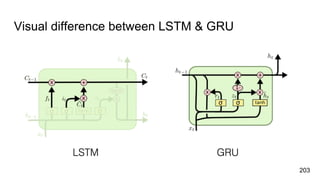

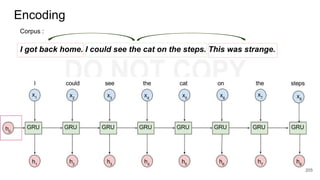



















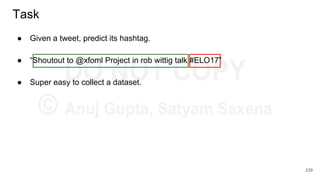
![char2vec : Toy Example
Example training
sequence: “hello”
Vocabulary: [h,e,l,o]
227](https://image.slidesharecdn.com/anthillinsideworkshoponnlp-170731110125/85/Representation-Learning-of-Text-for-NLP-227-320.jpg)
















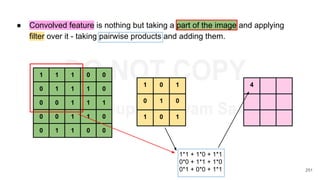

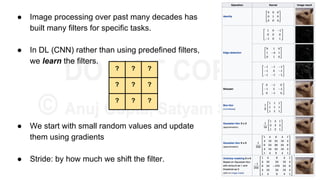

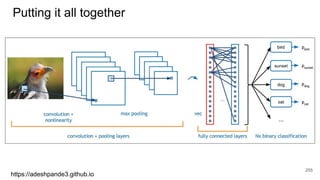

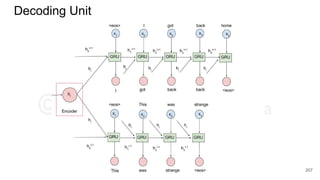
![Details
● C - vocabulary of characters. D - dimensionality
of character embeddings. R - matrix character
embeddings.
● Let wk
= [c1
,....,cl
]. Ck
be character-level
representation of wk
● Apply filter H to Ck
to obtain feature map fk
given
by:
|C|
D R
l
D Ck
c1
c2
cl
l - w +1
fk
257](https://image.slidesharecdn.com/anthillinsideworkshoponnlp-170731110125/85/Representation-Learning-of-Text-for-NLP-257-320.jpg)








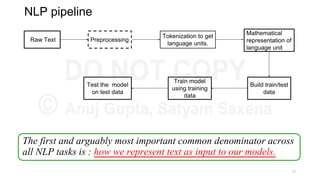
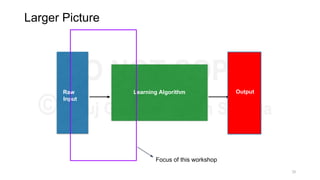
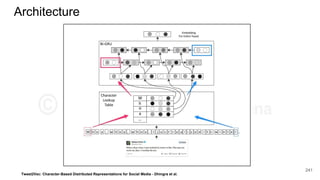
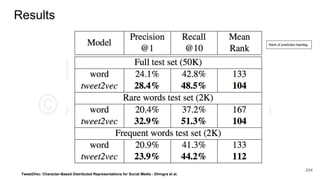
This document provides an overview of representation learning techniques for natural language processing (NLP). It begins with introducing the speakers and objectives of the workshop, which is to provide a deep dive into state-of-the-art text representation techniques and how to apply them to solve NLP problems. The workshop covers four modules: 1) archaic techniques, 2) word vectors, 3) sentence/paragraph/document vectors, and 4) character vectors. It emphasizes that representation learning is key to NLP as it transforms raw text into a numeric form that machine learning models can understand.











































































