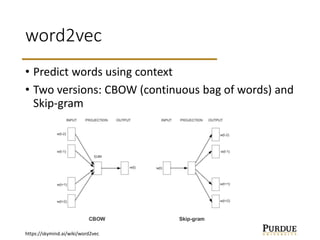
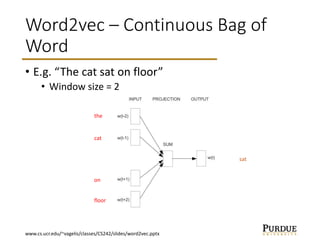
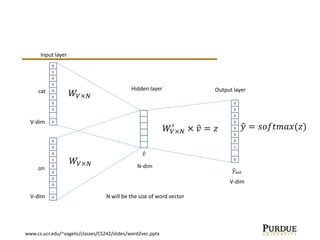
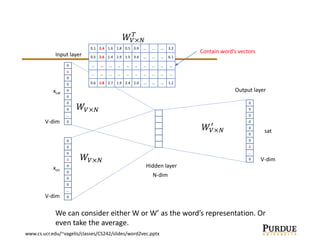
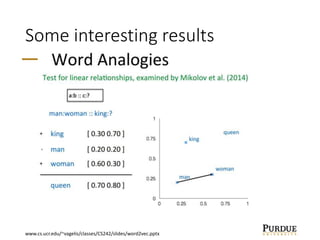
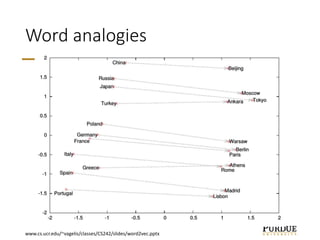
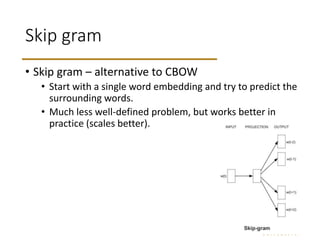
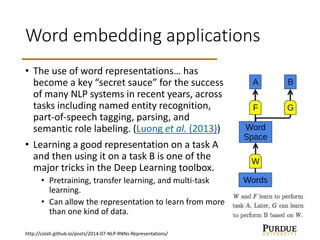
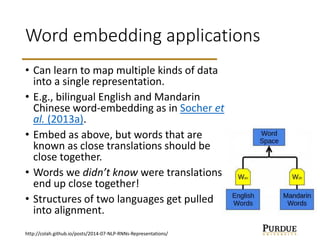
The document discusses word embeddings, which learn vector representations of words from large corpora of text. It describes two popular methods for learning word embeddings: continuous bag-of-words (CBOW) and skip-gram. CBOW predicts a word based on surrounding context words, while skip-gram predicts surrounding words from the target word. The document also discusses techniques like subsampling frequent words and negative sampling that improve the training of word embeddings on large datasets. Finally, it outlines several applications of word embeddings, such as multi-task learning across languages and embedding images with text.


























































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)







