The document discusses representation learning for words and phrases, starting with one-hot encoding and its limitations, particularly high dimensionality and vulnerability to overfitting. It explores language modeling, n-gram models, and the introduction of neural network language models like word2vec, which captures linguistic regularities and allows for word and phrase representations. Additionally, it touches upon recursive neural networks and the paragraph vector for learning sentence representations that maintain semantic meaning.





![One-hot encoding
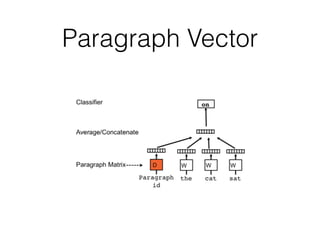
• From its word ID, we get a basic representation of a word through
the one-hot encoding of the ID
• the one-hot vector of an ID is a vector filled with 0s, except for a 1
at the position associated with the ID
• ex.: for vocabulary size D=10, the one-hot vector of word ID w=4
is
e(w) = [ 0 0 0 1 0 0 0 0 0 0 ]
• a one-hot encoding makes no assumption about word similarity
• all words are equally different from each other
• this is a natural representation to start with, though a poor one](https://image.slidesharecdn.com/latin-150313140222-conversion-gate01/85/Representation-Learning-of-Vectors-of-Words-and-Phrases-6-320.jpg)

![N-gram Model
• An n-gram is a sequence of n words
• unigrams(n=1):’‘is’’,‘‘a’’,‘‘sequence’’,etc.
• bigrams(n=2): [‘‘is’’,‘‘a’’], [‘’a’’,‘‘sequence’’],etc.
• trigrams(n=3): [‘’is’’,‘‘a’’,‘‘sequence’’],[‘‘a’’,‘‘sequence’’,‘‘of’’],etc.
• n-gram models estimate the conditional from n-grams counts
• the counts are obtained from a training corpus (a data set of word
text)](https://image.slidesharecdn.com/latin-150313140222-conversion-gate01/85/Representation-Learning-of-Vectors-of-Words-and-Phrases-9-320.jpg)










![Data Structures - Lecture 1 [introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-1introduction-141217054305-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



