Download as PDF, PPTX














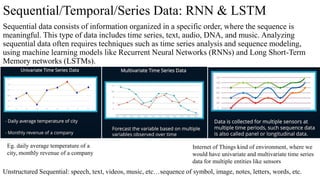








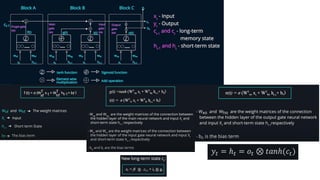
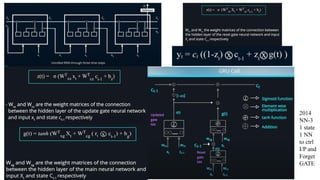





This document provides an overview of Natural Language Processing (NLP) and its applications, including sentiment analysis, text summarization, and language translation. It details key techniques such as tokenization, word embeddings, and recurrent neural networks (RNNs), highlighting algorithms like word2vec and LSTM for enhancing language comprehension. Additionally, it discusses frameworks for sequence-to-sequence tasks and evaluation methods like BLEU for assessing machine-generated text quality.


































































