Downloaded 328 times






![Formal Model
• X = set of Customers
• S = set of Items
• Utility function u: X × S R
– R = set of ratings
– R is a totally ordered set
– e.g., 0-5 stars, real number in [0,1]
Viet-Trung Tran 8](https://image.slidesharecdn.com/4-recommendationcolaborativefiltering-150818025112-lva1-app6892/85/Recommender-systems-Content-based-and-collaborative-filtering-8-320.jpg)














![Finding “Similar” Users
• Let rx be the vector of user x’s ratings
• Jaccard similarity measure
– Problem: Ignores the value of the rating
• Cosine similarity measure
– Problem: Treats missing ratings as “negative”
• Pearson correlation coefficient
– Sxy = items rated by both users x and y
Viet-Trung Tran 23
rx = [*, _, _, *, ***]
ry = [*, _, **, **, _]
rx, ry as sets:
rx = {1, 4, 5}
ry = {1, 3, 4}
rx, ry as points:
rx = {1, 0, 0, 1, 3}
ry = {1, 0, 2, 2, 0}
rx, ry … avg.
rating of x, y](https://image.slidesharecdn.com/4-recommendationcolaborativefiltering-150818025112-lva1-app6892/85/Recommender-systems-Content-based-and-collaborative-filtering-23-320.jpg)





![Item-Item CF (|N|=2)
Viet-Trung Tran 29
121110987654321
455?311
3124452
534321423
245424
5224345
423316
users
Neighbor selection:
Identify movies similar to
movie 1, rated by user 5
movies
1.00
-0.18
0.41
-0.10
-0.31
0.59
sim(1,m)
Here we use Pearson correlation as similarity:
1) Subtract mean rating mi from each movie i
m1 = (1+3+5+5+4)/5 = 3.6
row 1: [-2.6, 0, -0.6, 0, 0, 1.4, 0, 0, 1.4, 0, 0.4, 0]
2) Compute cosine similarities between rows](https://image.slidesharecdn.com/4-recommendationcolaborativefiltering-150818025112-lva1-app6892/85/Recommender-systems-Content-based-and-collaborative-filtering-29-320.jpg)














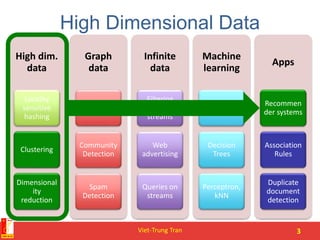
This document provides an overview of recommender systems, including content-based and collaborative filtering approaches. It discusses how content-based systems make recommendations based on item profiles and calculating similarity between user and item profiles. Collaborative filtering is described as finding similar users and making predictions based on their ratings. The document also covers evaluation metrics, complexity issues, and tips for building recommender systems.

























![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)























































