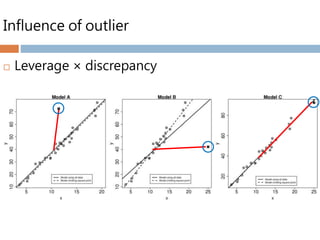
This document discusses important concepts for screening data, including detecting and handling errors, missing data, outliers, and ensuring assumptions of analyses are met. It describes why data screening is important to obtain accurate results and avoid bias. Key topics covered include identifying patterns of missing data, different types of missing data (MCAR, MAR, MNAR), and various methods for treating missing values. Outliers are defined and their impact explained. Common transformations are presented to achieve normality, linearity, and homoscedasticity. Checklists are provided for conducting data screening.