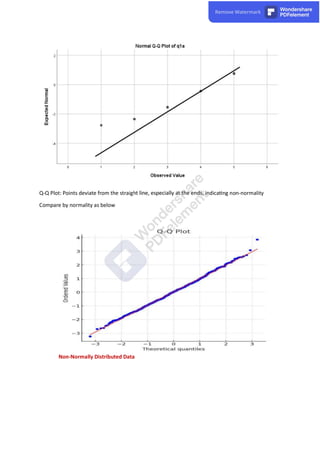
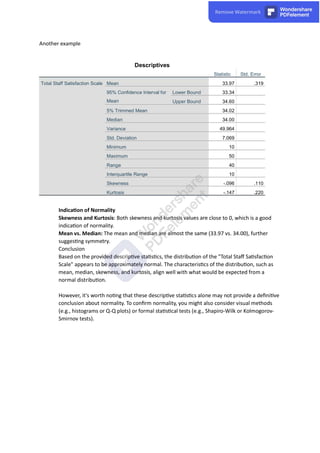
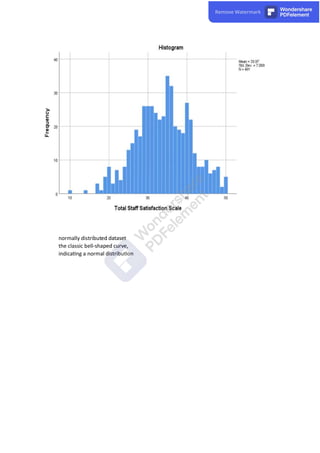
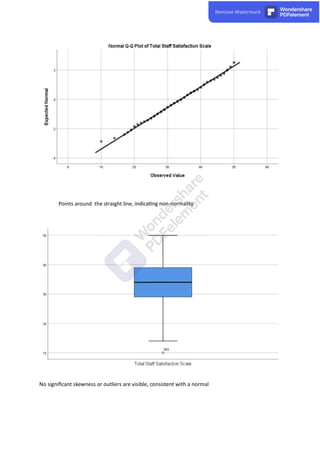
The document discusses the various types of missing data encountered in research: Missing Completely at Random (MCAR), Missing at Random (MAR), and Missing Not at Random (MNAR), each with distinct implications for data analysis. It explores methods for handling missing data including listwise deletion, pairwise deletion, and imputation techniques, specifically multiple imputation, emphasizing the importance of maintaining statistical power while addressing missing values. Additionally, it highlights the need to assess normality in data to utilize appropriate statistical methods, discussing various techniques such as histograms and Q-Q plots to evaluate whether data follows a normal distribution.







![The median is more robust to outliers than the mean. However, the median alone also
doesn't provide enough informa on to judge normality.
Mode
The mode is the value that appears most frequently in a data set.
Example
Using the same data set: 2, 4, 4, 4, 5, 5, 7, 9
Mode = 4 (because 4 appears the most mes)
Normality
The mode also doesn't provide a complete picture of normality. In a perfectly normal
distribu on, the mode, median, and mean would all be the same. Mul ple modes or a large
difference between the mode and mean/median can suggest non-normality.
Certainly! Let's break down the calcula on of the standard devia on for the given data set
in more detail. The data set is: 2, 4, 4, 4, 5, 5, 7, 9.
### Standard Devia on
The standard devia on gives you a measure of how spread out the numbers are from the
mean. It's calculated using the following steps:
1. **Calculate the Mean**: First, you'll need to find the mean of the data.
[
text{Mean} = frac{2 + 4 + 4 + 4 + 5 + 5 + 7 + 9}{8} = 5
]
2. **Subtract the Mean and Square the Result**: Subtract the mean and square the result
for each number in the data set.
[
(2 - 5)^2 = 9
(4 - 5)^2 = 1
(4 - 5)^2 = 1
(4 - 5)^2 = 1
(5 - 5)^2 = 0
(5 - 5)^2 = 0
(7 - 5)^2 = 4
(9 - 5)^2 = 16
]
3. **Calculate the Mean of the Squared Differences**: Add up all the squared differences
and divide by the total number of numbers.
[
frac{9 + 1 + 1 + 1 + 0 + 0 + 4 + 16}{8} = frac{32}{8} = 4
]
4. **Take the Square Root**: Finally, the standard devia on is the square root of the mean
of the squared differences.
[
sqrt{4} = 2
]](https://image.slidesharecdn.com/spssguideassessingnormalityhandlingmissingdataandcalculatingscores-230805061823-0834c80c/85/SPSS-GuideAssessing-Normality-Handling-Missing-Data-and-Calculating-Scores-pdf-8-320.jpg)