Downloaded 41 times






















![Lamport’s Algorithm
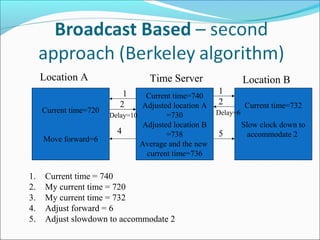
Each process increments its clock counter
between every two consecutive events.
If a sends a message to b, then the message must
include T(a). Upon receiving a and T(a), the
receiving process must set its clock to the greater
of [T(a)+d, Current Clock]. That is, if the
recipient’s clock is behind, it must be advanced to
preserve the happen-before relationship. Usually
d=1.](https://image.slidesharecdn.com/unit-4-181220090834/85/CS6601-Unit-4-Distributed-Systems-24-320.jpg)













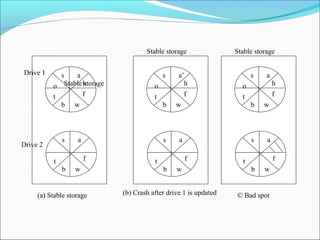















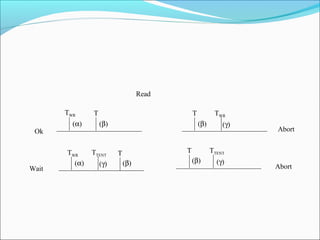


This document summarizes key concepts related to time and clocks in distributed systems. It discusses how physical clocks work, including obtaining accurate time from sources like atomic clocks and synchronizing clocks across distributed systems. It also covers logical clocks and how they are used to order events in a way that preserves causality. Other distributed computing topics summarized include mutual exclusion algorithms, elections, and atomic transactions including concurrency control methods like two-phase locking and optimistic concurrency control.




















































































