Downloaded 581 times















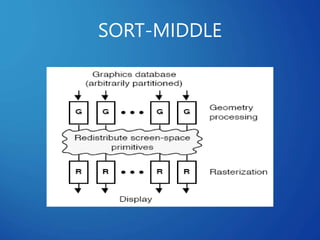


























This document discusses distributed systems applications in real life, including three key areas: distributed rendering in computer graphics, peer-to-peer networks, and massively multiplayer online gaming. It describes how distributed rendering parallelizes graphics processing across multiple computers. Peer-to-peer networks are defined as decentralized networks where nodes act as both suppliers and consumers of resources. Examples of peer-to-peer applications include file sharing and content delivery networks. The document also outlines the challenges of designing multiplayer online games using a distributed architecture rather than a traditional client-server model.






















































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












