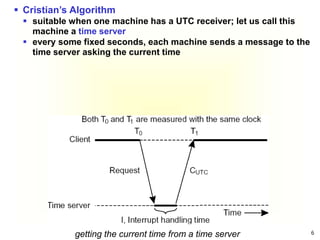
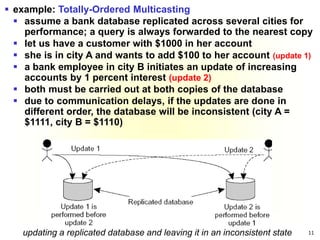
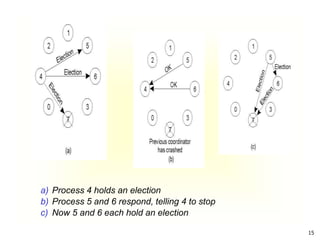
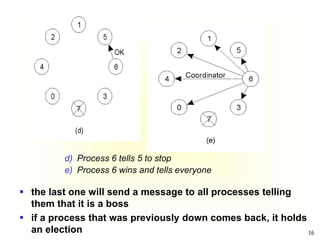
This document summarizes key concepts around synchronization in distributed systems including clock synchronization, logical clocks, election algorithms, and mutual exclusion. It discusses how physical clocks become unsynchronized over time, introduces Lamport timestamps and logical clocks, describes the Bully and Ring election algorithms, and covers a centralized mutual exclusion algorithm that uses a coordinator to grant processes permission to enter a critical region.





























![38
a) a transaction
b) – d) the log before each statement is executed
x = 0;
y = 0;
BEGIN_TRANSACTION;
x = x + 1;
y = y + 2;
x = y * y;
END_TRANSACTION;
(a)
Log
[x = 0/1]
(b)
Log
[x = 0/1]
[y = 0/2]
(c)
Log
[x = 0/1]
[y = 0/2]
[x = 1/4]
(d)
example](https://image.slidesharecdn.com/chapter5-synchronozation-221209061808-38ad8b71/85/Chapter-5-Synchronozation-ppt-38-320.jpg)
































![CSCI 5235_Present WiMax_[Zhen-Yu Fang].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/csci5235presentwimaxzhen-yufang-231227144921-d3930f74-thumbnail.jpg?width=640&height=640&fit=bounds)






