Downloaded 10 times








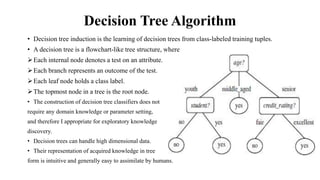





















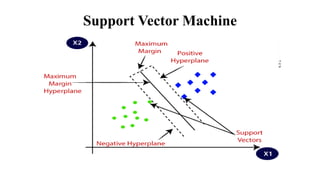












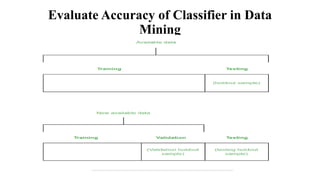







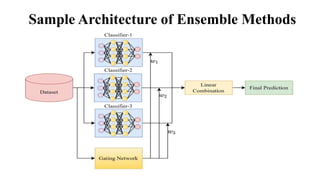



This document provides an overview of classification and prediction methods in data mining, detailing various techniques such as decision trees and Bayesian classification. Key issues addressed include data preprocessing, evaluation metrics, and various algorithms for implementing these methods. The document emphasizes the importance of accuracy, speed, robustness, and scalability in the classification and prediction processes.














































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)




































