Download as PDF, PPTX







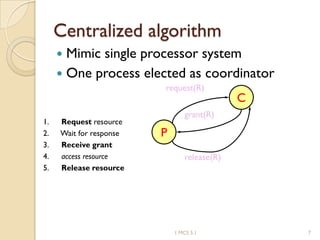
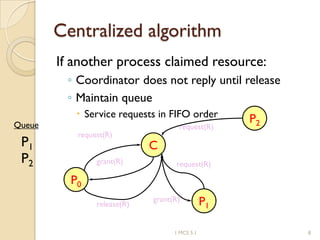


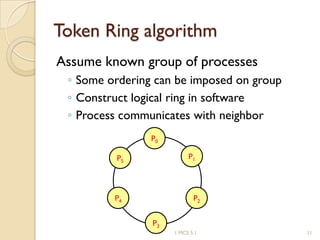
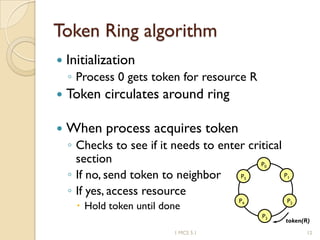

























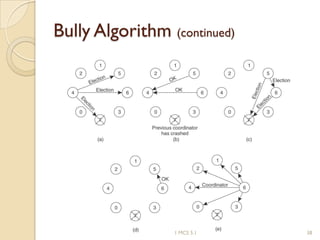



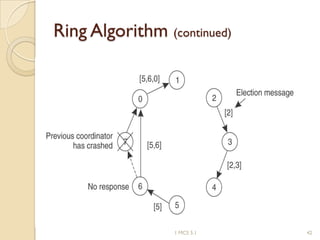

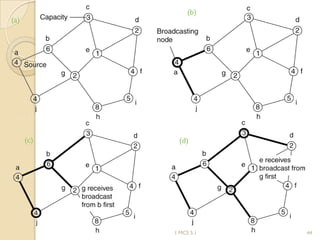
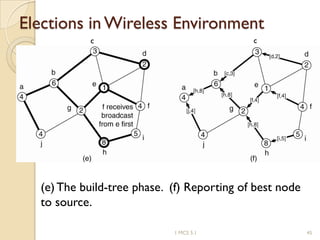


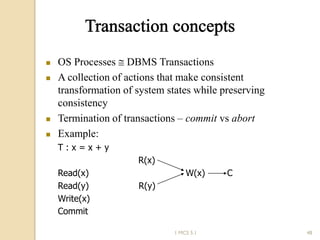


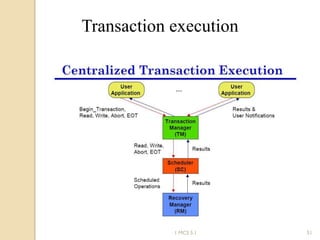
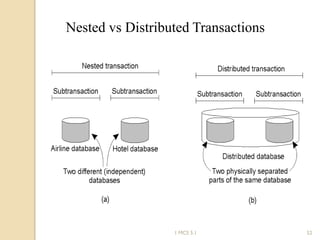
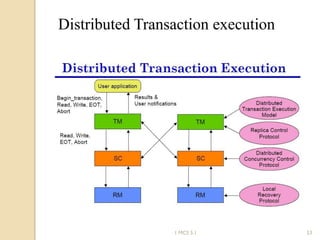










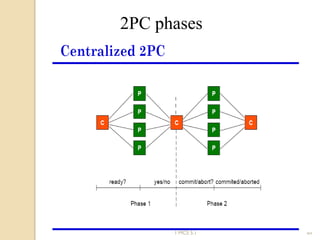




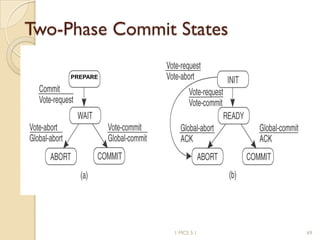







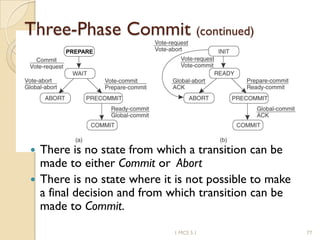





The document discusses various algorithms for achieving distributed mutual exclusion and process synchronization in distributed systems. It covers centralized, token ring, Ricart-Agrawala, Lamport, and decentralized algorithms. It also discusses election algorithms for selecting a coordinator process, including the Bully algorithm. The key techniques discussed are using logical clocks, message passing, and quorums to achieve mutual exclusion without a single point of failure.














































































