Download to read offline



















![From Association Mining to Correlation
Analysis
A correlation measure can be used to augment the support-confidence
framework for association rules.
This leads to correlation rules of the form:
A=>B [support, confidence, correlation]
That is, a correlation rule is measured not only by its support and confidence
but also by the correlation between itemsets A and B.](https://image.slidesharecdn.com/unit2-dwdmpart2-240227095614-a5060cf5/75/UNIT-2-Part-2-Data-Warehousing-and-Data-Mining-30-2048.jpg)

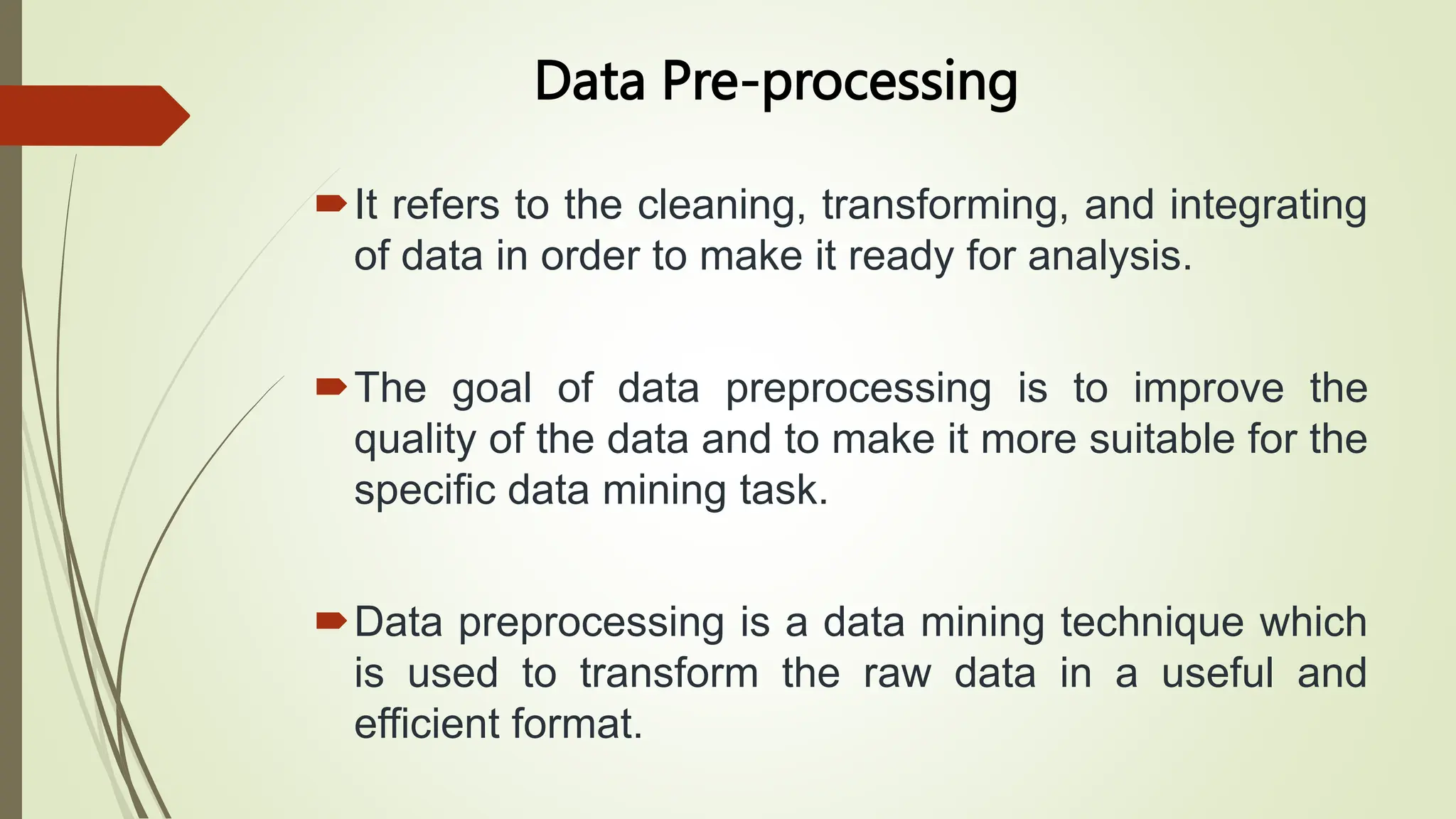
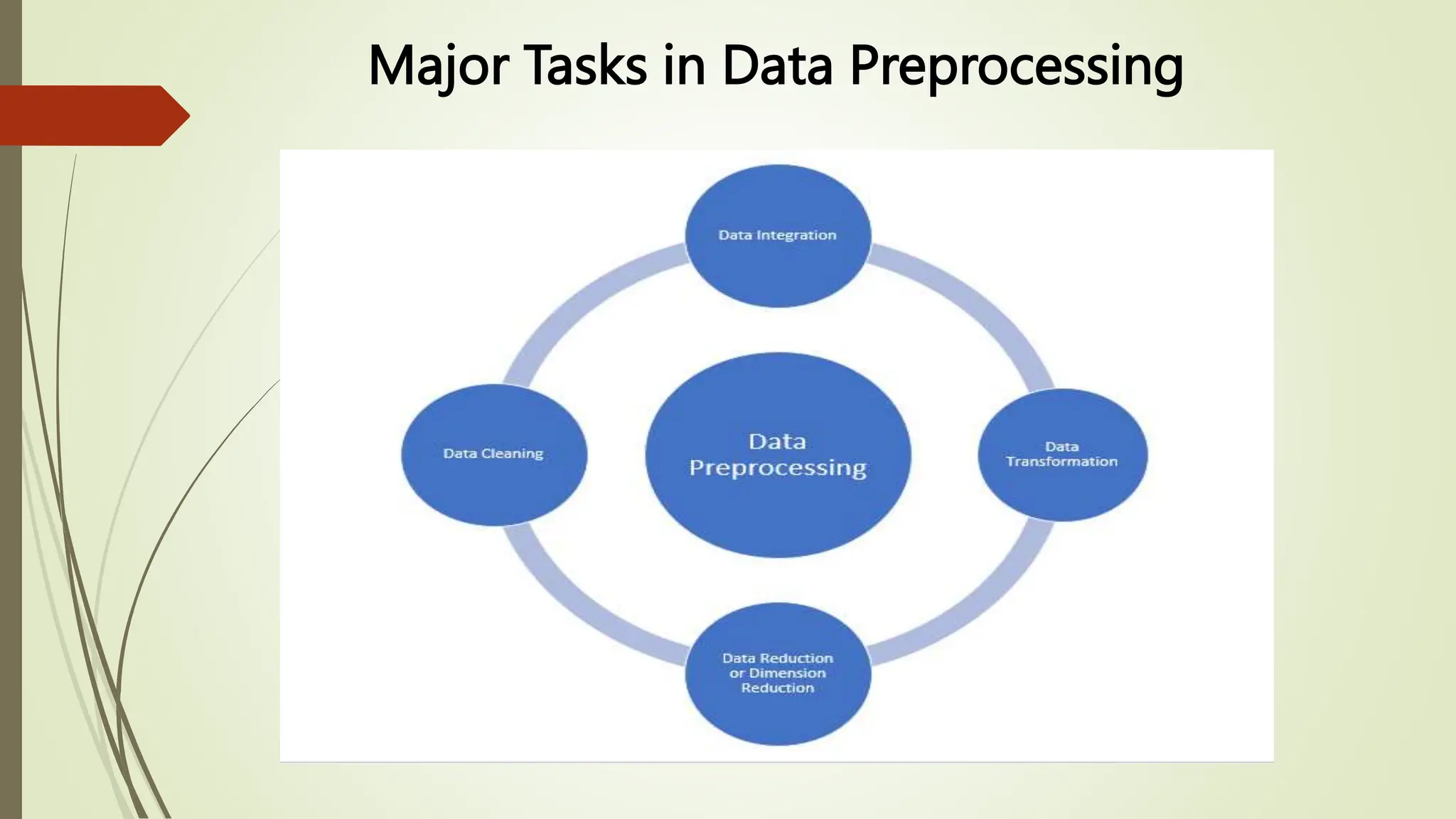
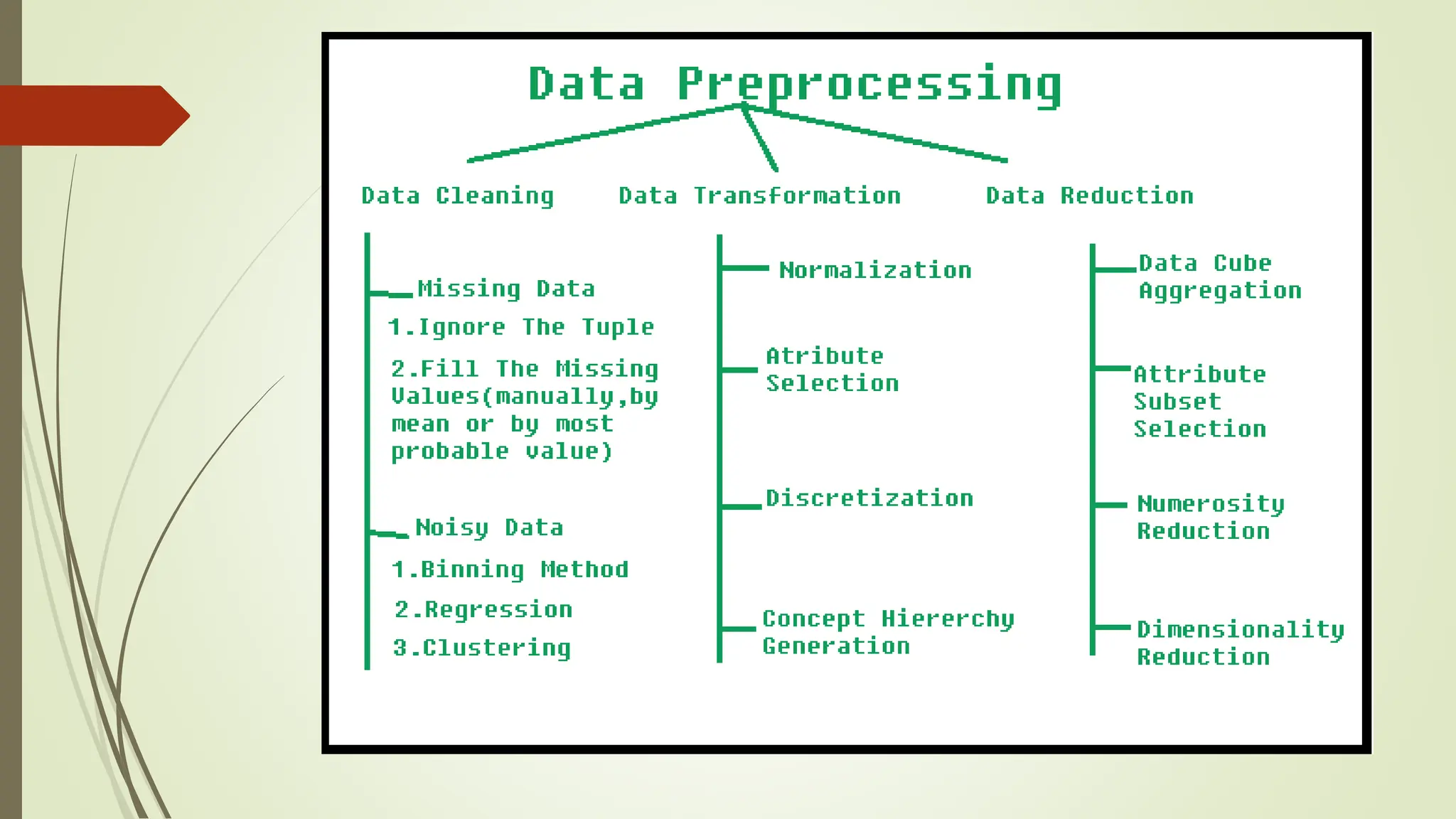
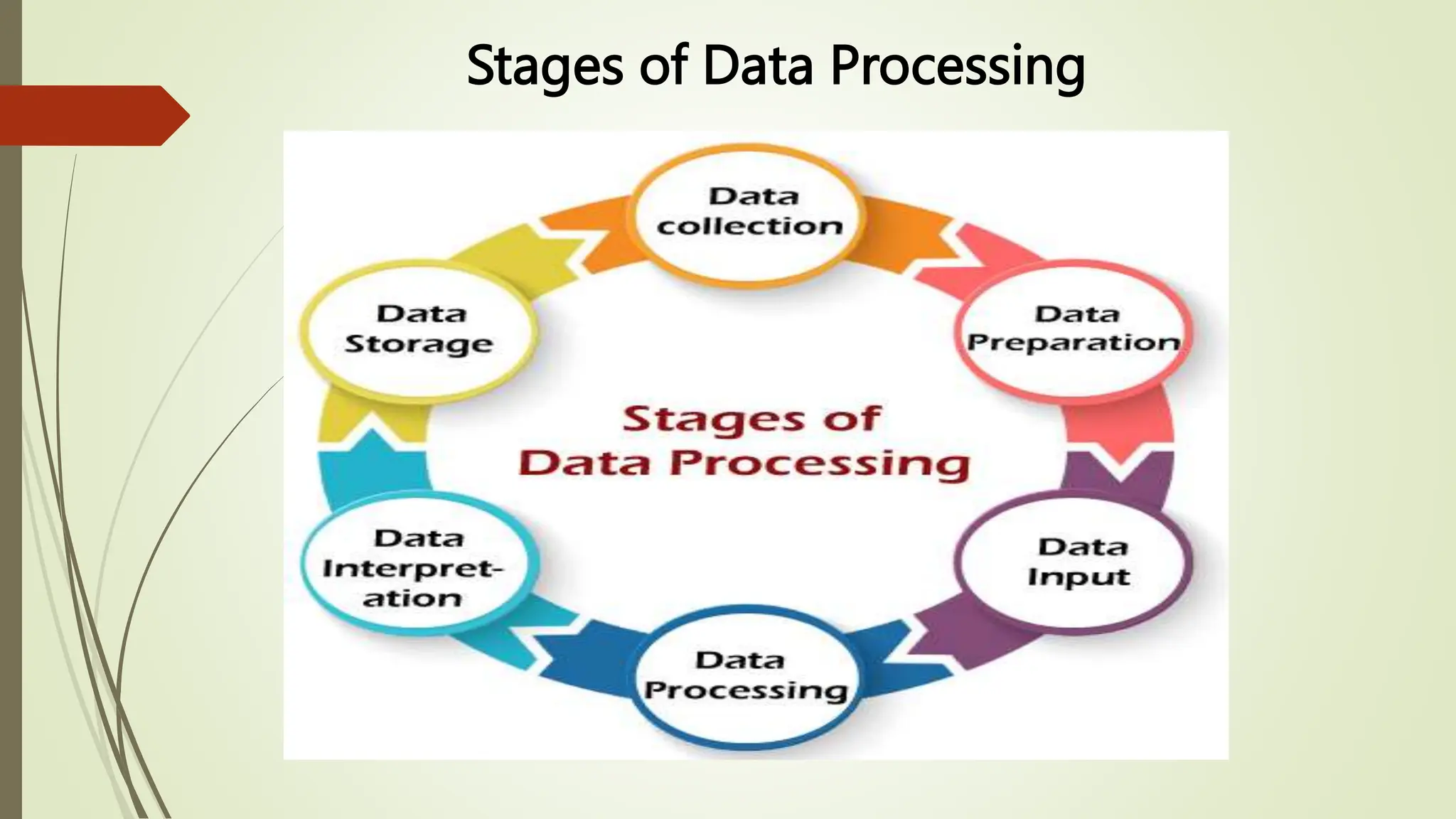
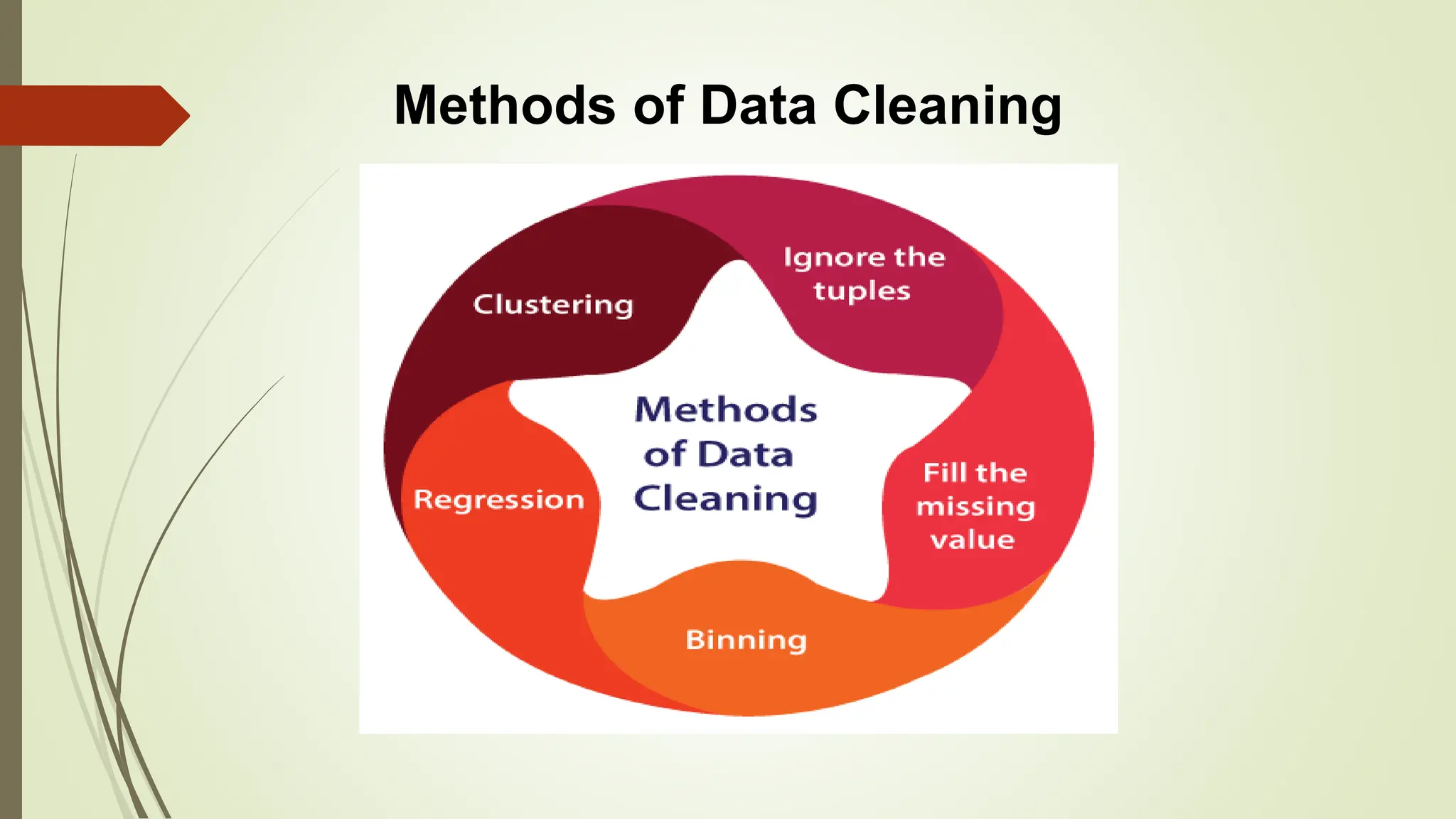
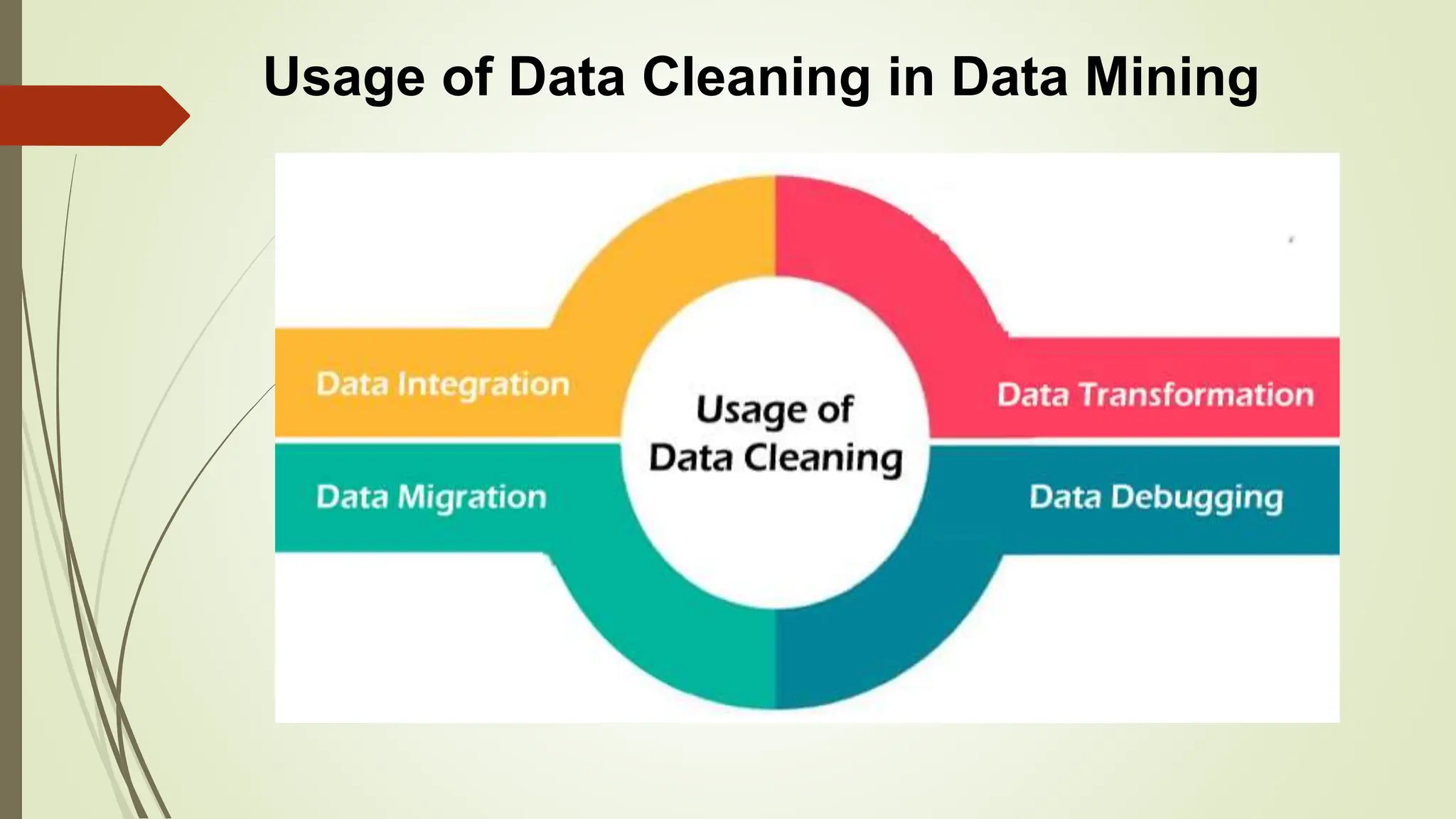
This document provides an overview of data pre-processing techniques used in data mining. It discusses common steps in data pre-processing including data cleaning, integration, transformation, reduction, and discretization. Specific techniques covered include handling missing and noisy data, data normalization, attribute selection, dimensionality reduction, and the Apriori and FP-Growth algorithms for frequent pattern mining. The goals of data pre-processing are to improve data quality, handle inconsistencies, and prepare the data for analysis.



















































































