Downloaded 46 times














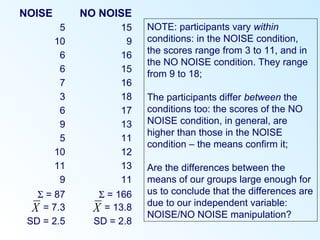



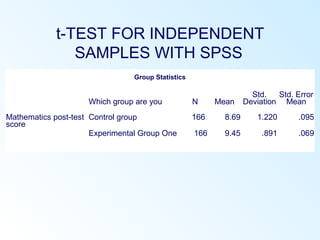













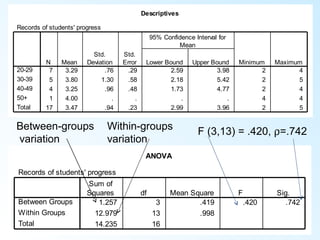




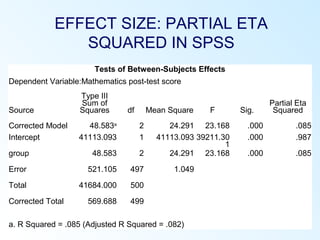




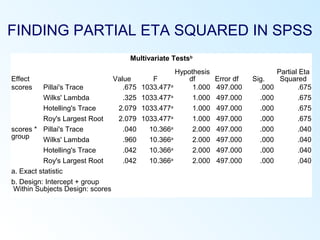
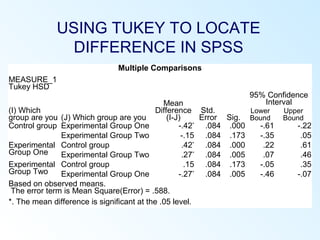







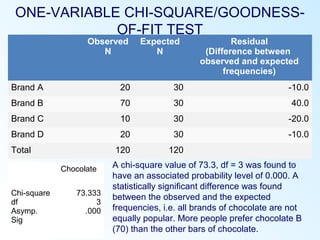






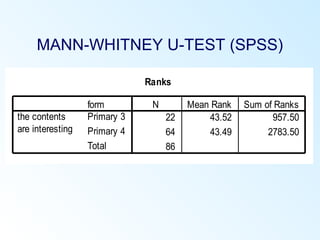
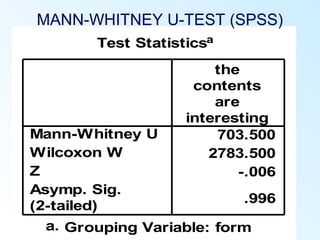

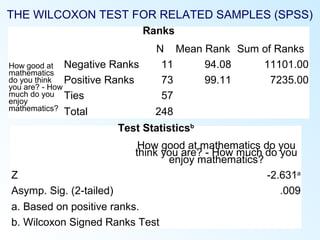

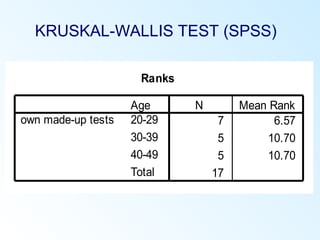



This document discusses inferential statistics and various statistical tests used to analyze differences between groups. It describes measures of difference such as the t-test, analysis of variance (ANOVA), chi-square test, Mann-Whitney test, and Kruskal-Wallis test. It also covers regression analysis techniques like simple and multiple linear regression. Key steps are outlined for conducting t-tests, ANOVA, and interpreting their results from SPSS output. Degrees of freedom and their role in statistical tests are also explained.









































































































