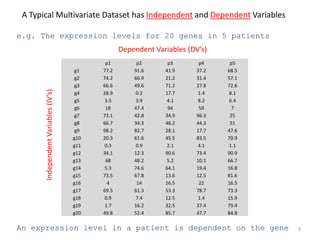
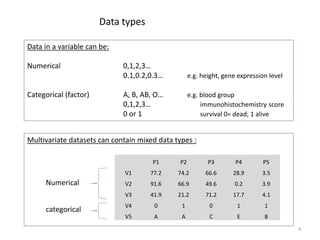
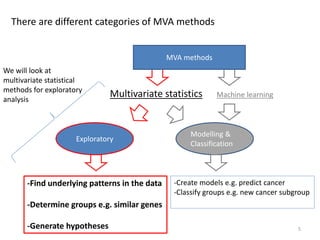
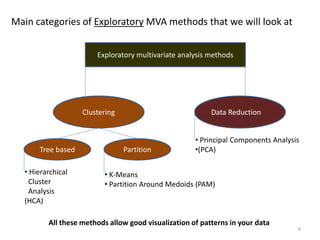
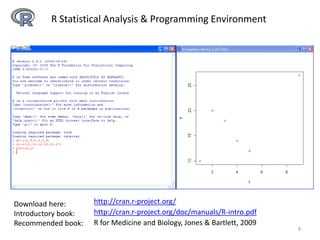
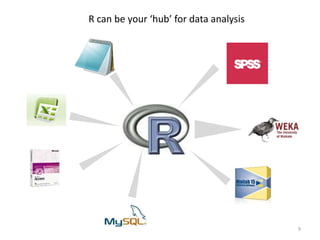
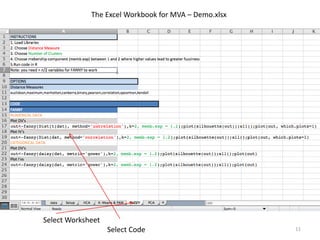
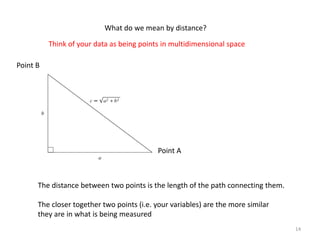
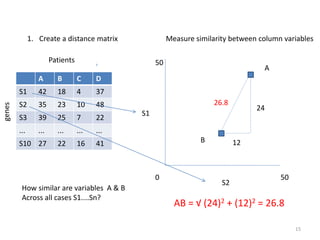
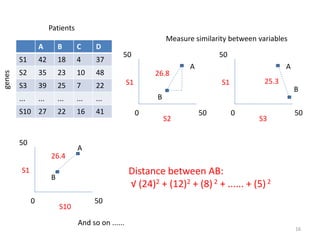
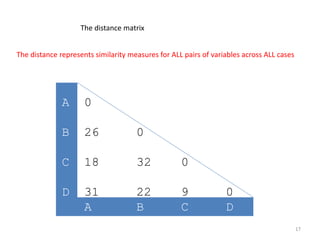
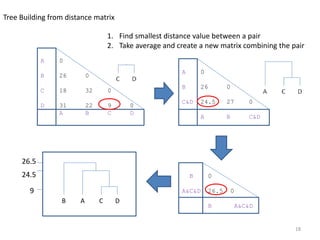
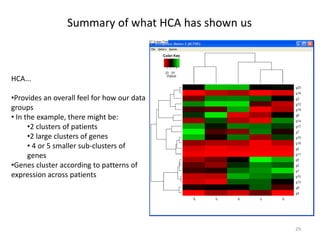
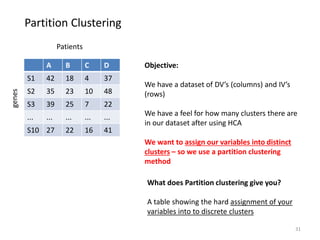
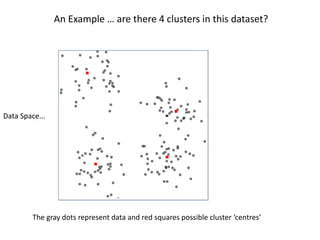
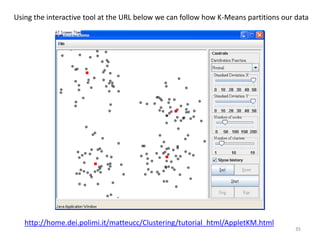
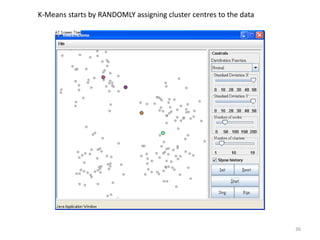
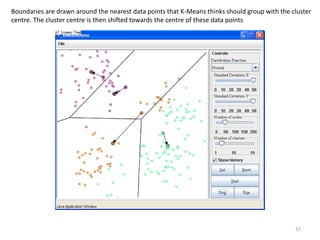
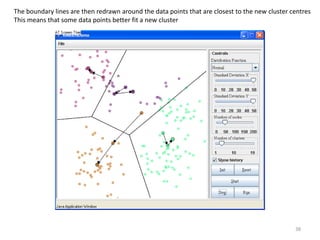
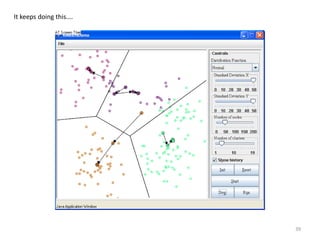
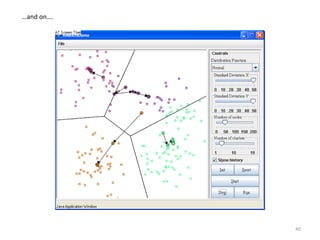
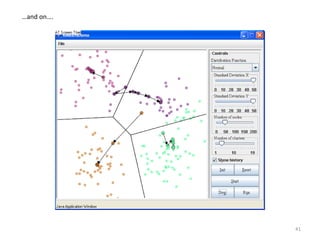
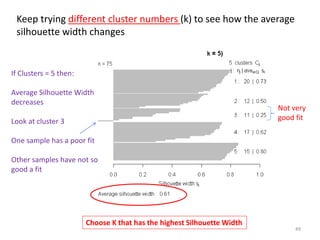
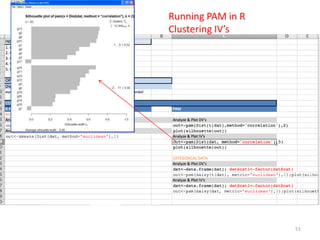
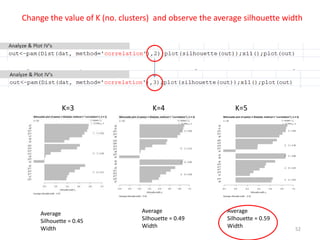
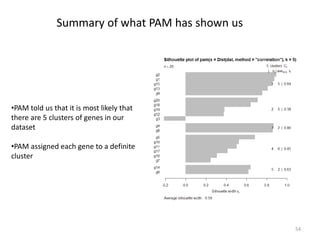
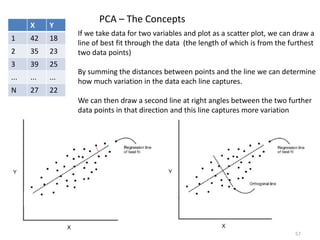
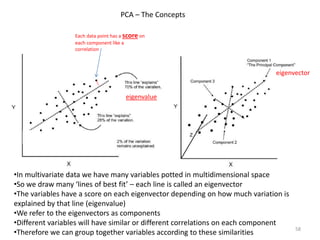
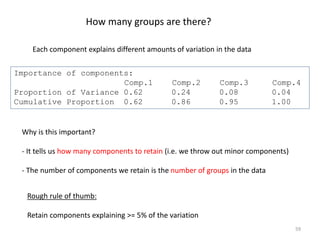
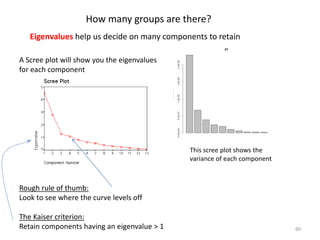
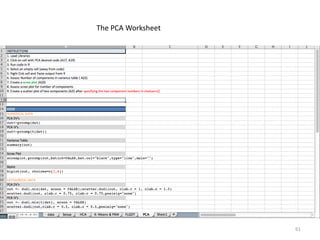
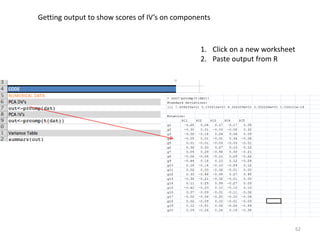
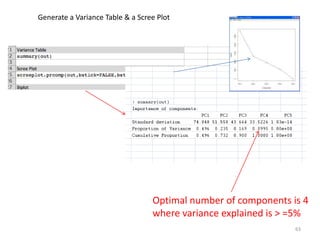
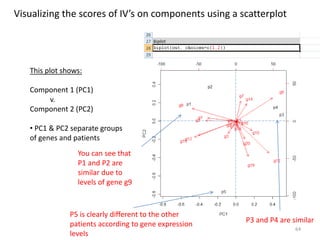
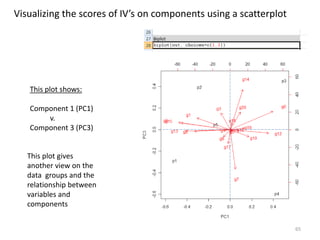
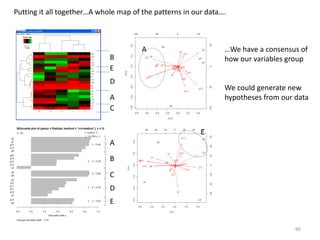
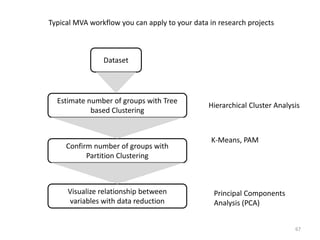
This document provides an introduction to multivariate data analysis (MVA) using R. It defines what multivariate analysis is and explains that multivariate datasets contain multiple variables and can include mixed data types. Common MVA methods are discussed, including hierarchical cluster analysis (HCA) and partition clustering for exploratory analysis. HCA involves calculating distances between variables, building a tree to visualize relationships, and can identify potential subgroups. Partition clustering assigns variables to discrete clusters. The document demonstrates HCA and partition clustering on gene expression data to explore patterns among patients and genes.