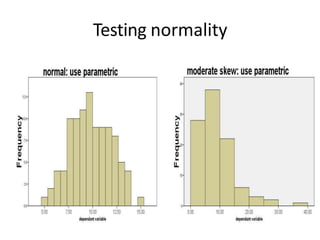
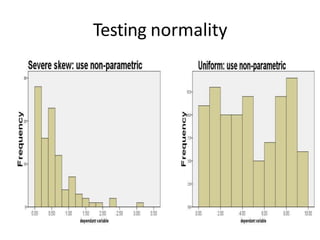
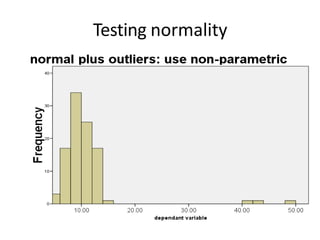
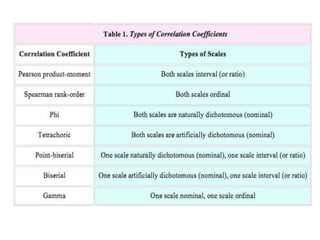
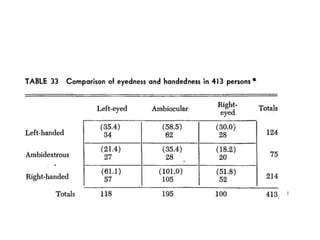
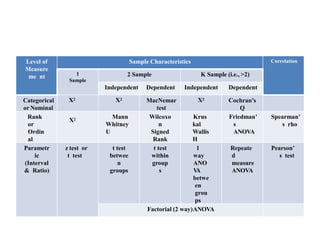
This document provides information about non-parametric tests. It begins by explaining that non-parametric tests do not assume a specific distribution or make assumptions about the population. It then discusses tests for normality like the Kolmogorov-Smirnov test and Shapiro-Wilk test. Commonly used non-parametric tests like Spearman's rank correlation, Mann-Whitney U test, and Kruskal-Wallis H test are explained. The chi-square test and assumptions are also covered in detail. Advantages of non-parametric tests include fewer assumptions and applicability to small sample sizes. A disadvantage is they are less powerful than parametric tests.
































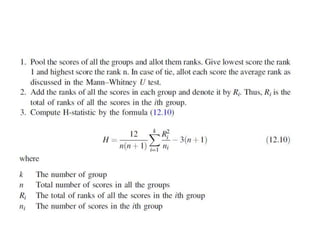
















![Non_parametric_test-4[1].pptx -[1] 2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nonparametrictest-41-260115135338-f2d1eaa3-thumbnail.jpg?width=640&height=640&fit=bounds)























![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)










