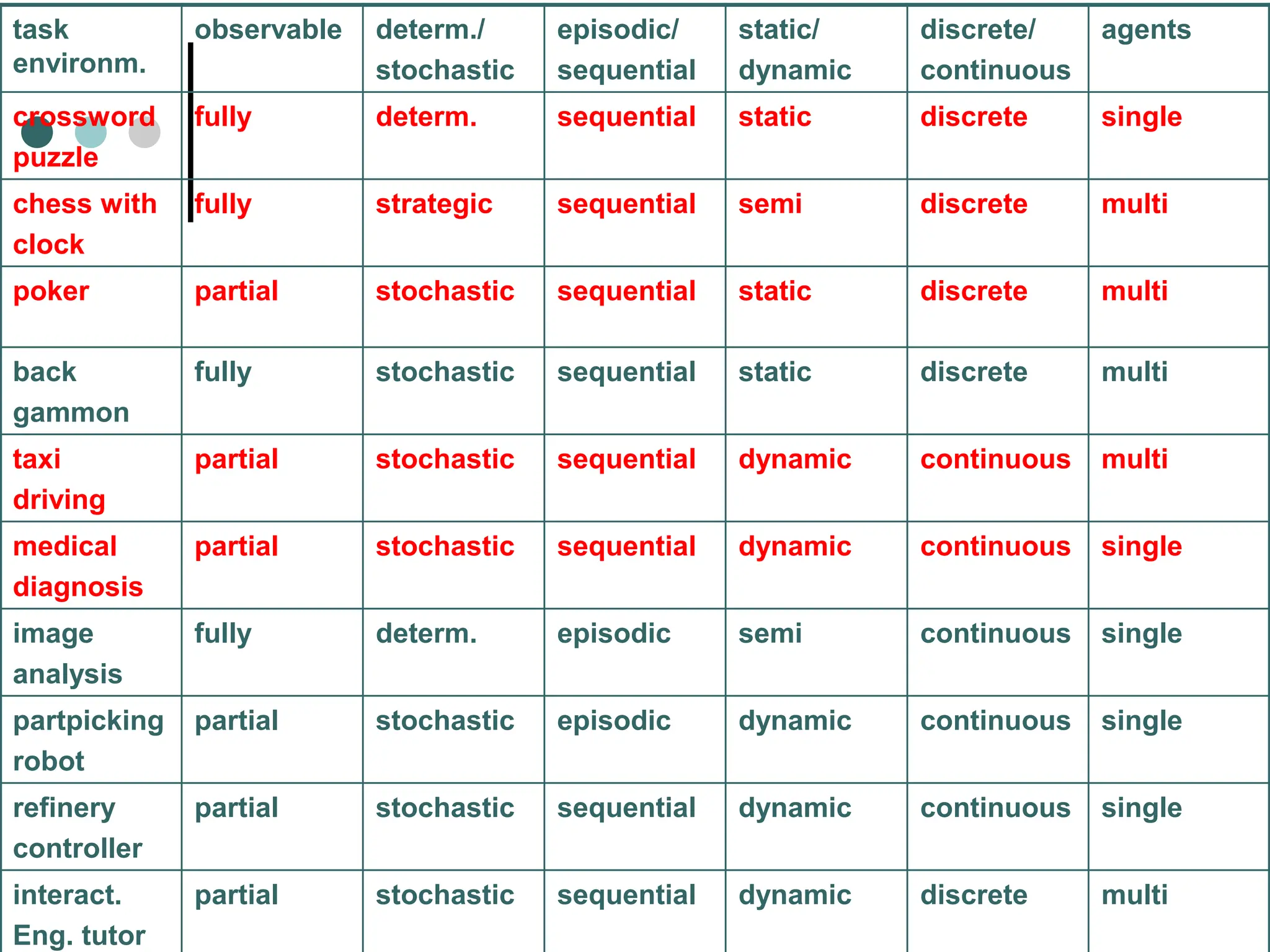
An agent is anything that perceives its environment and acts upon it. The document discusses the history, current status, and key concepts of artificial intelligence (AI) such as agents, environments, and rational behavior. It provides examples to illustrate agents and their task environments, describing properties like being fully/partially observable, deterministic/stochastic, episodic/sequential, static/dynamic, discrete/continuous, and single/multi-agent. The document also summarizes the four main approaches to AI as thinking and acting humanly or rationally.






















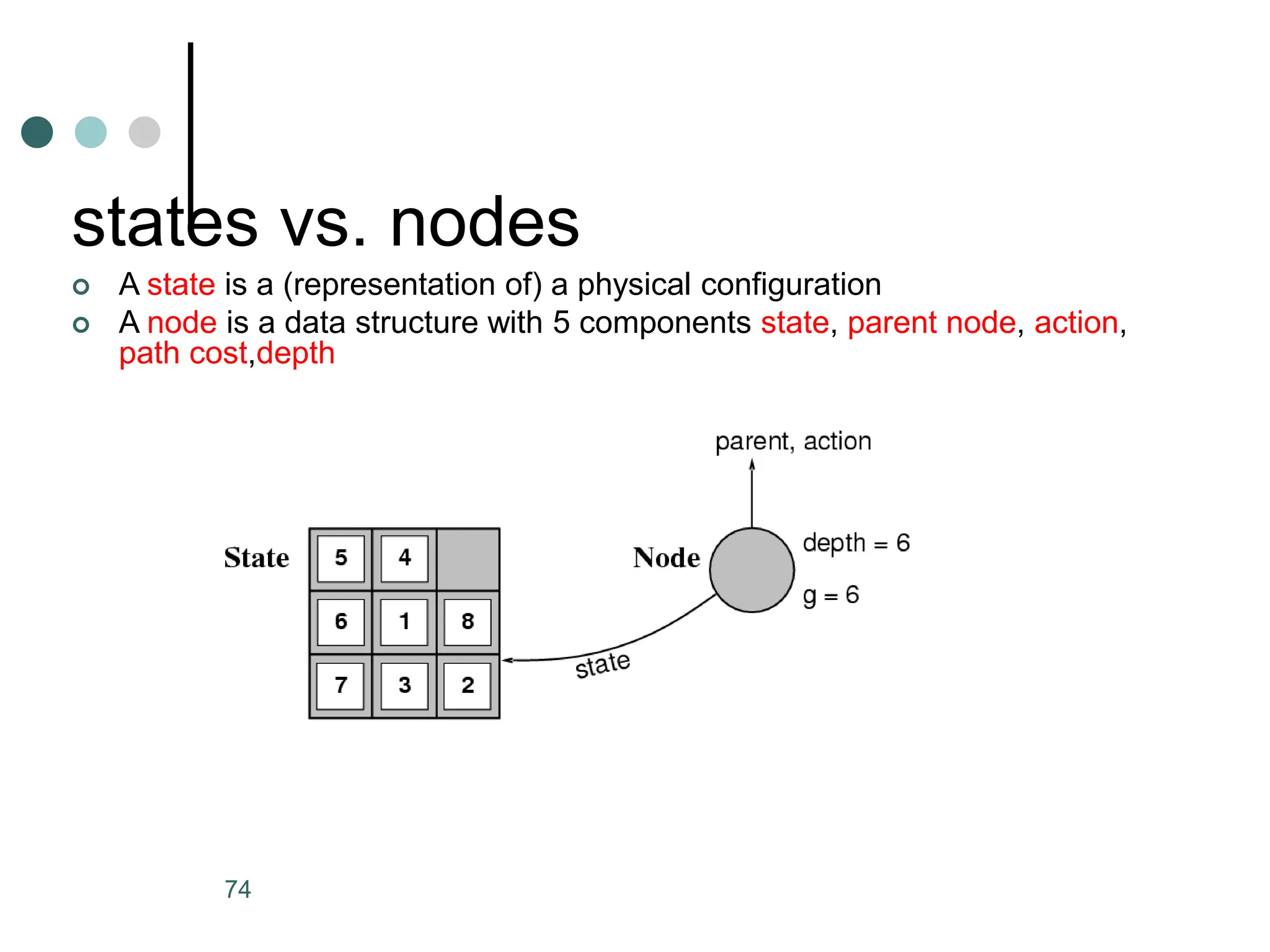
![ The agent function maps from percept histories to
actions:[f: P* A].The agent function is an
abstract mathematical description.
The agent function will be implemented by an agent
program.The agent program is a concrete
implementation running on the agent
architecture .](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-24-2048.jpg)
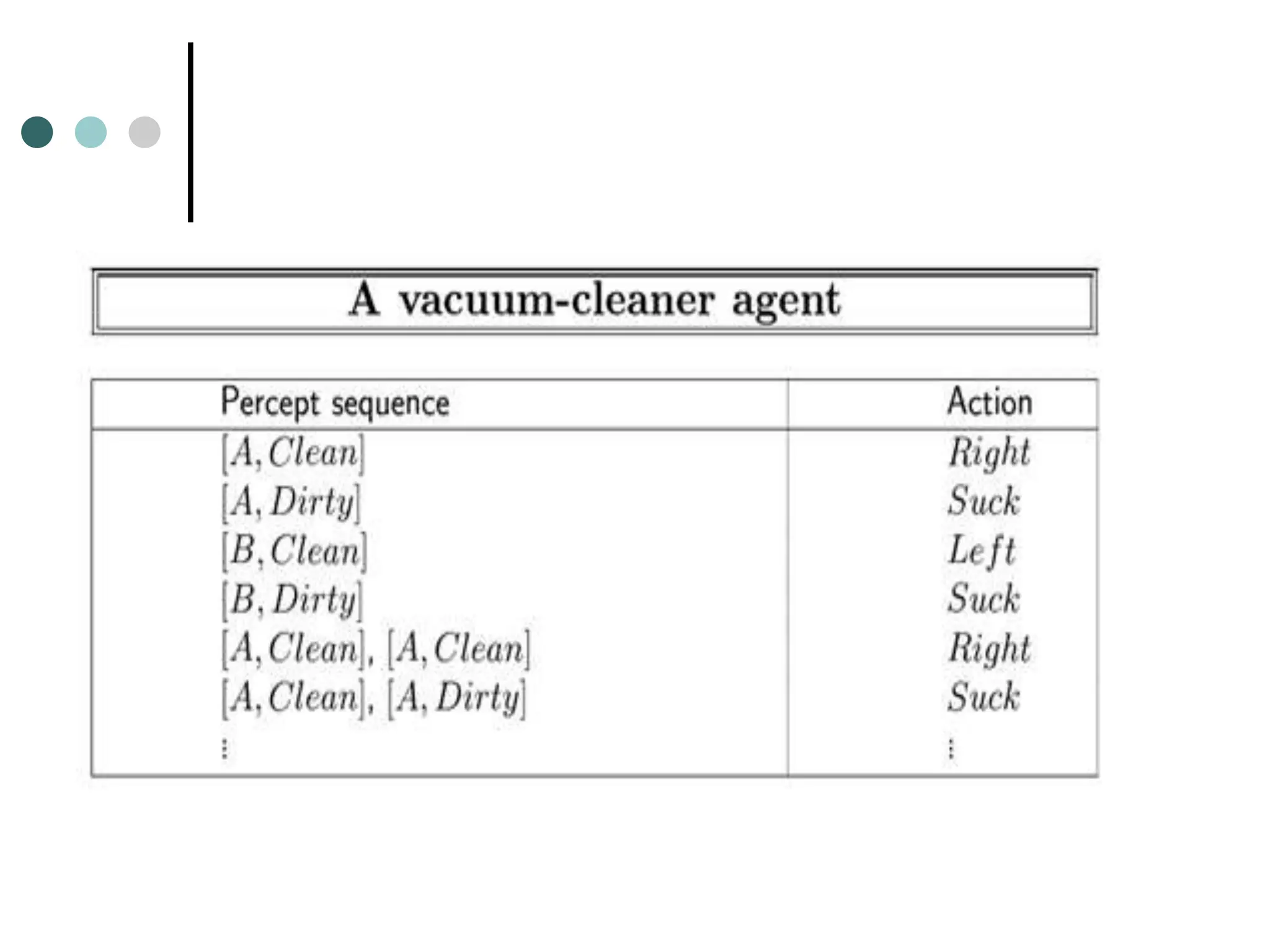
![Vacuum-cleaner world
Percepts:
Location and status,
e.g., [A,Dirty]
Actions:
Left, Right, Suck, NoOp
Example vacuum agent program:
function Vacuum-Agent([location,status]) returns an action
if status = Dirty then return Suck
else if location = A then return Right
else if location = B then return Left](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-25-2048.jpg)















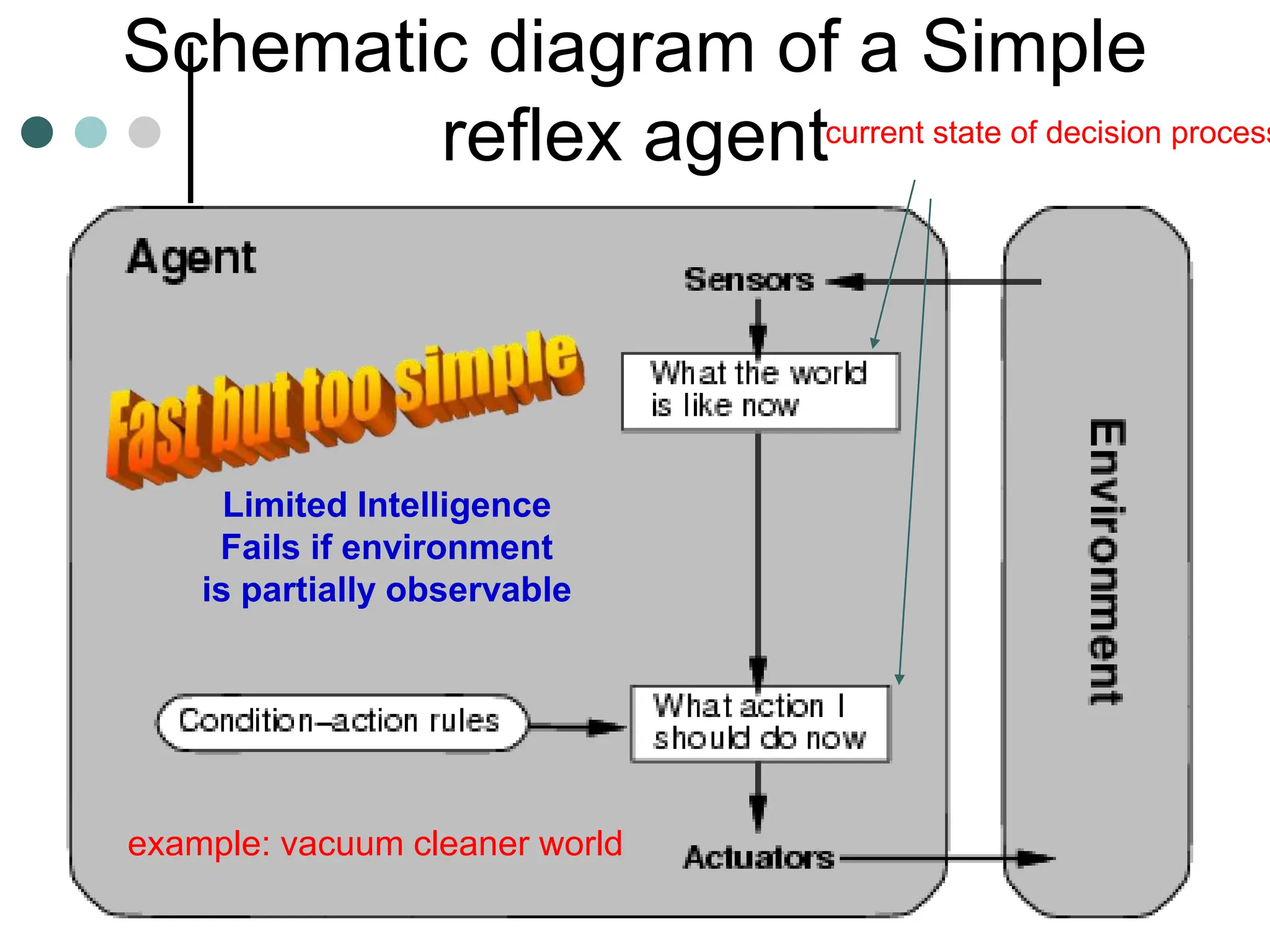
![Simple reflex agent Program
Function Simple-Reflex-Agent(percept)
Static: rules, set of condition-actions rules;
state <- Interpret-Input(percept)
Rule <- Rule-Match(state, rules)
action <- Rule-Action[Rule]
return action
A simple reflex agent. It acts according to rule whose condition matches the
current state, as defined by the percept.](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-43-2048.jpg)


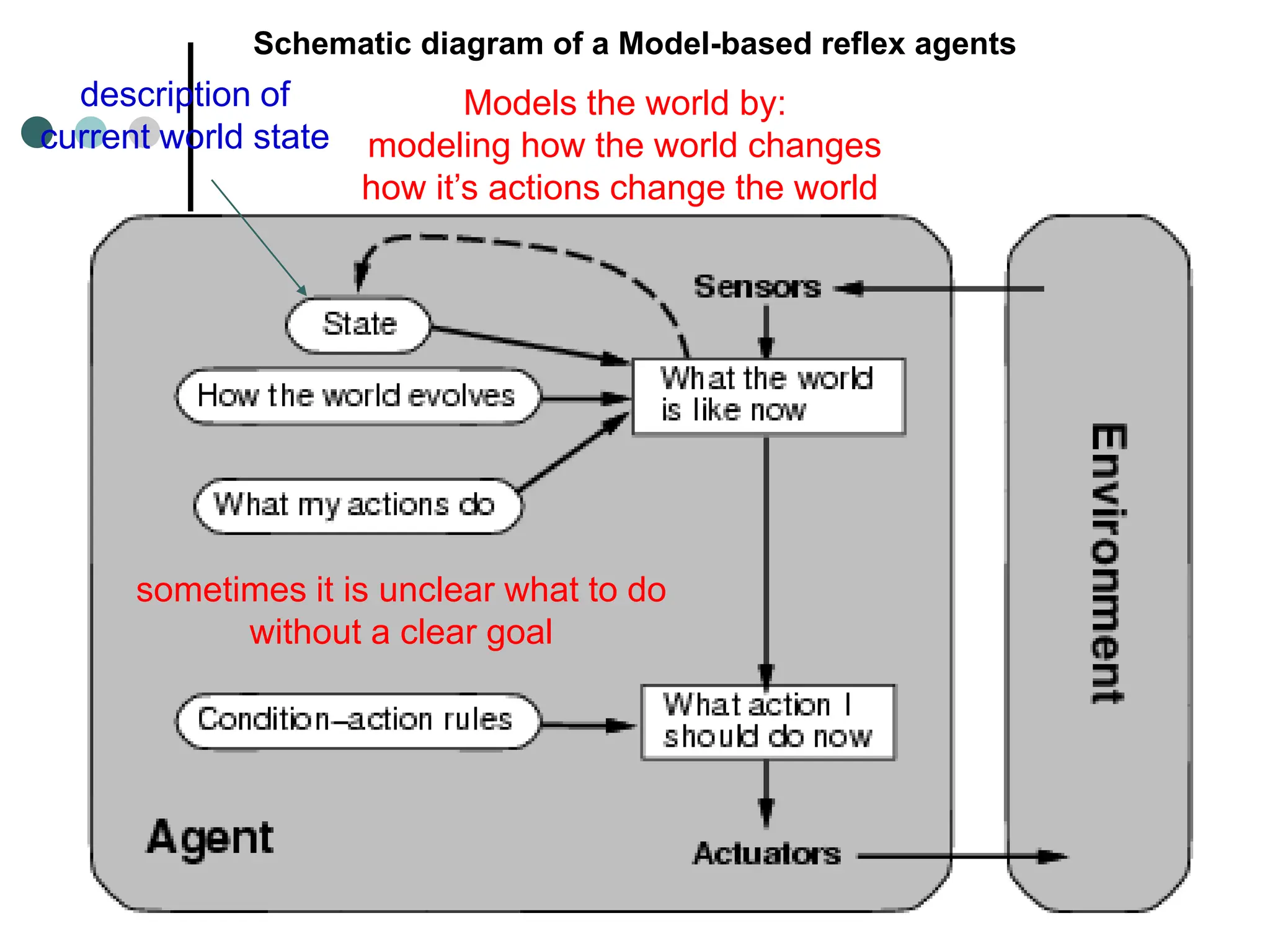
![Model-based reflex agents
Function Model-based-Reflex-Agent(percept)
Static: state, a description of the current world state
rules, set of condition-actions rules;
actions, the most recent action, initially none
State<-Update-State(oldInternalState,LastAction,percept)
rule<- Rule-Match(State, rules)
action <- Rule-Action[rule]
return action
A model-based reflex agent. It keep track of the current state of the world using
an internal model. It then chooses an action in the same way as the reflect agent.](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-48-2048.jpg)

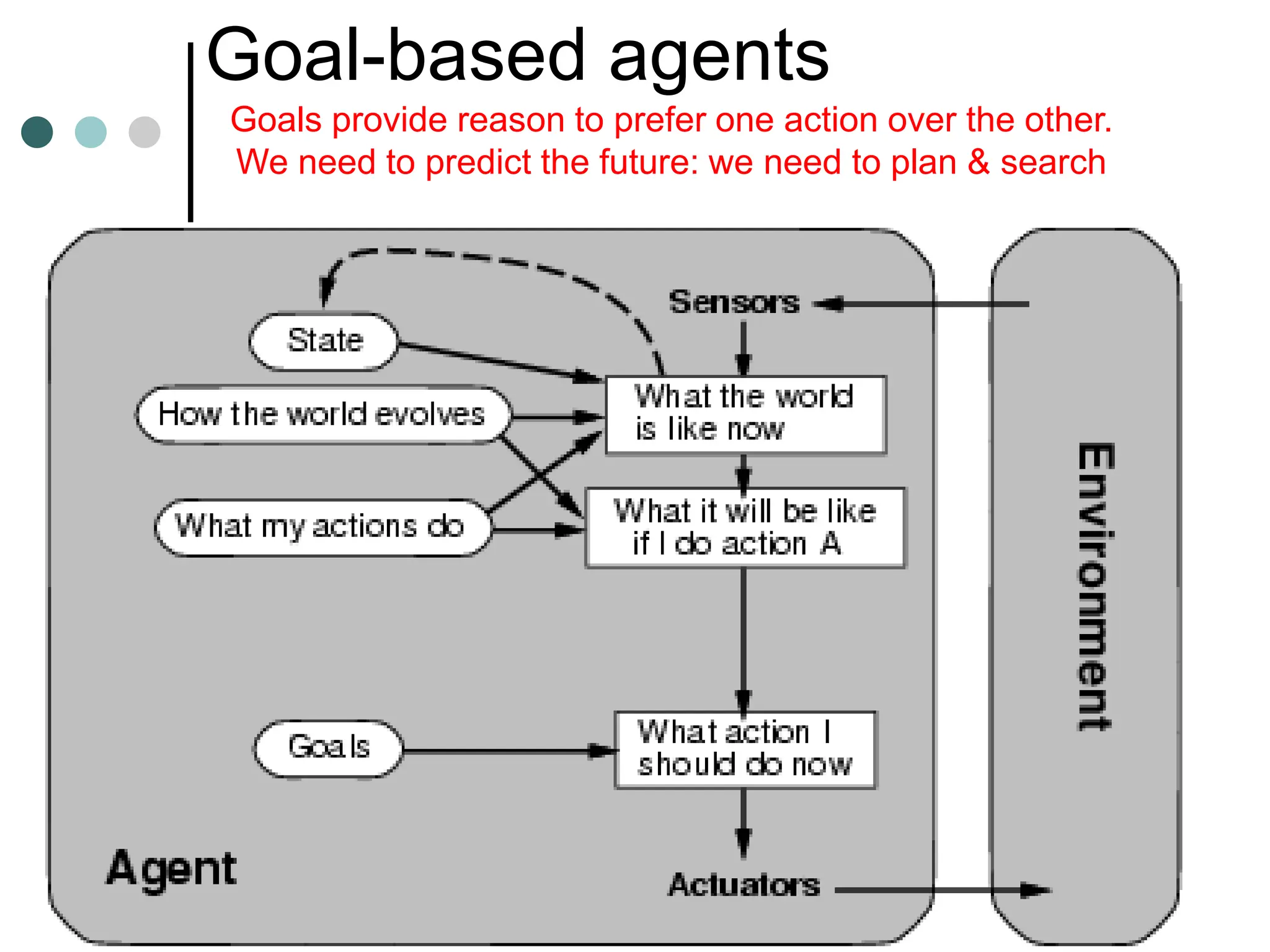


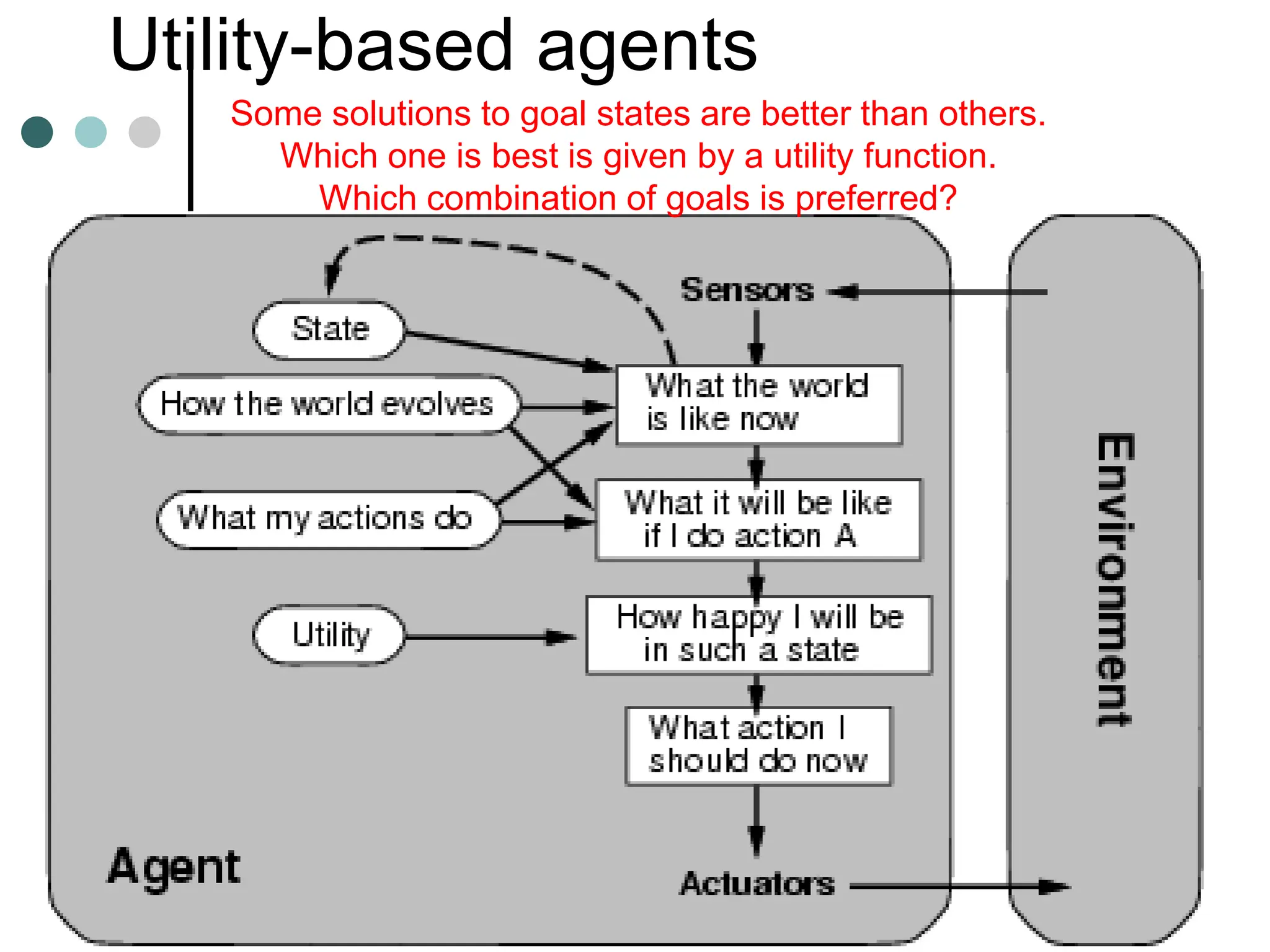
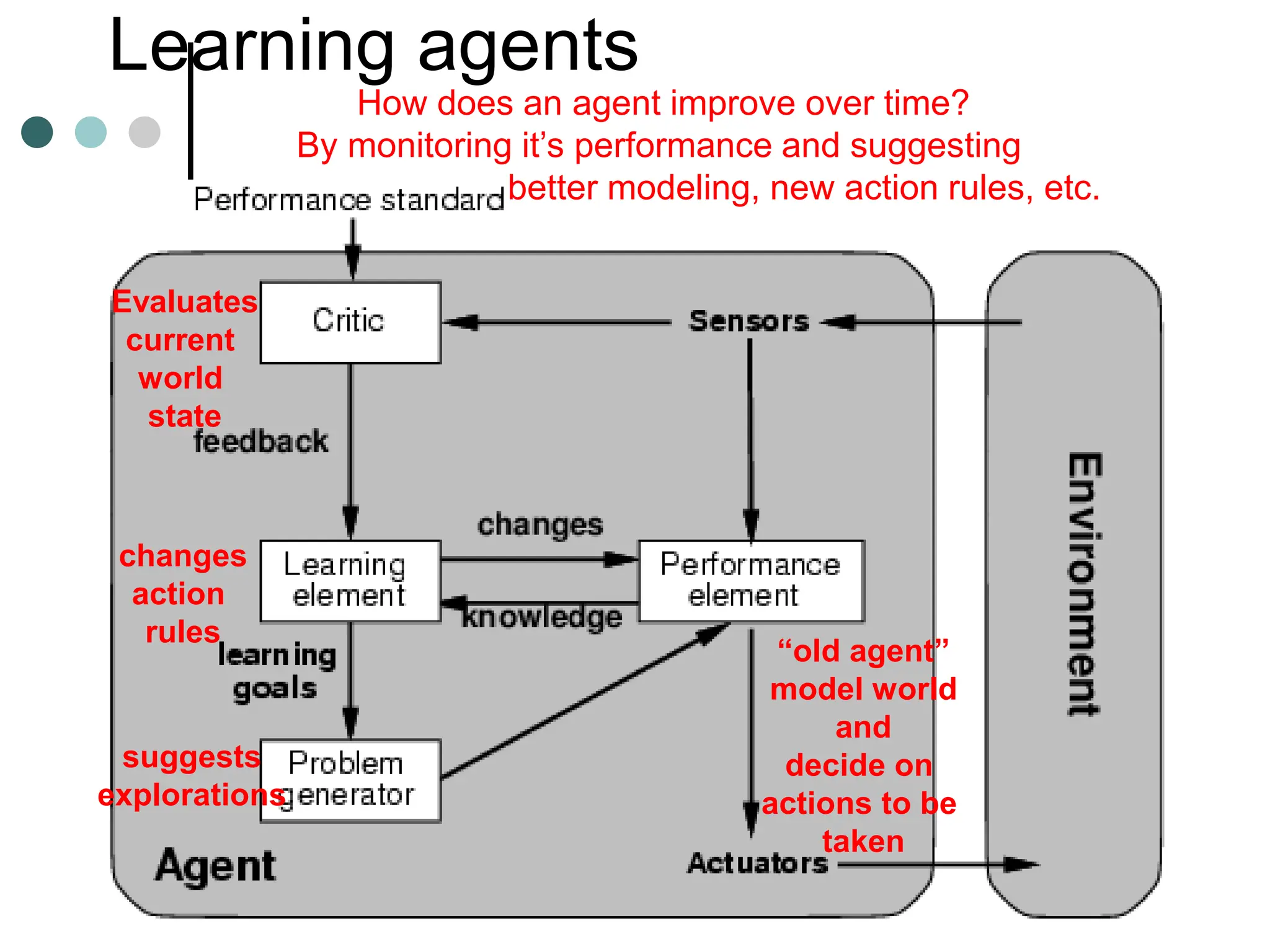




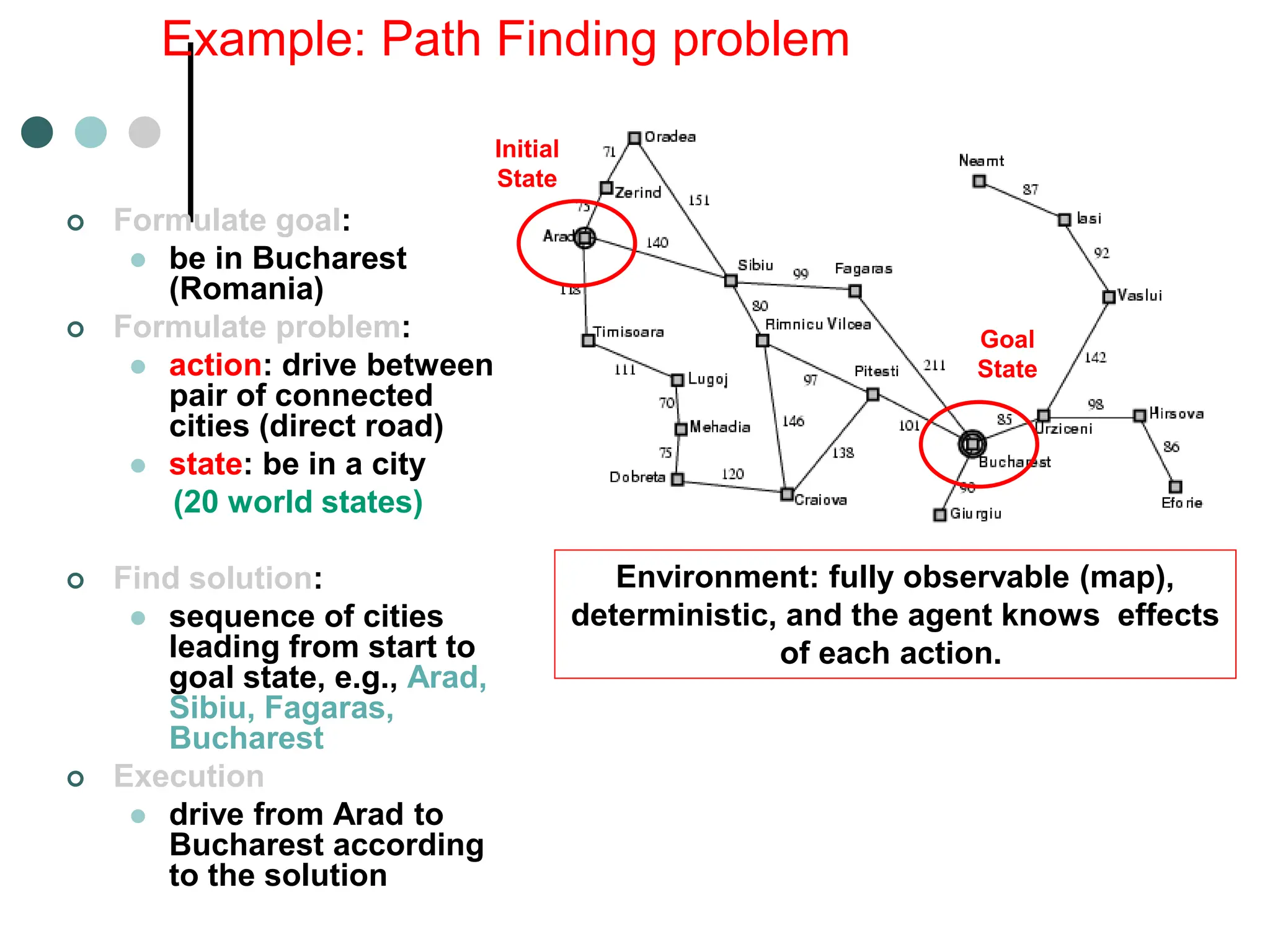



![The 8-puzzle
[Note: optimal solution of n-Puzzle family is NP-hard]](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-63-2048.jpg)

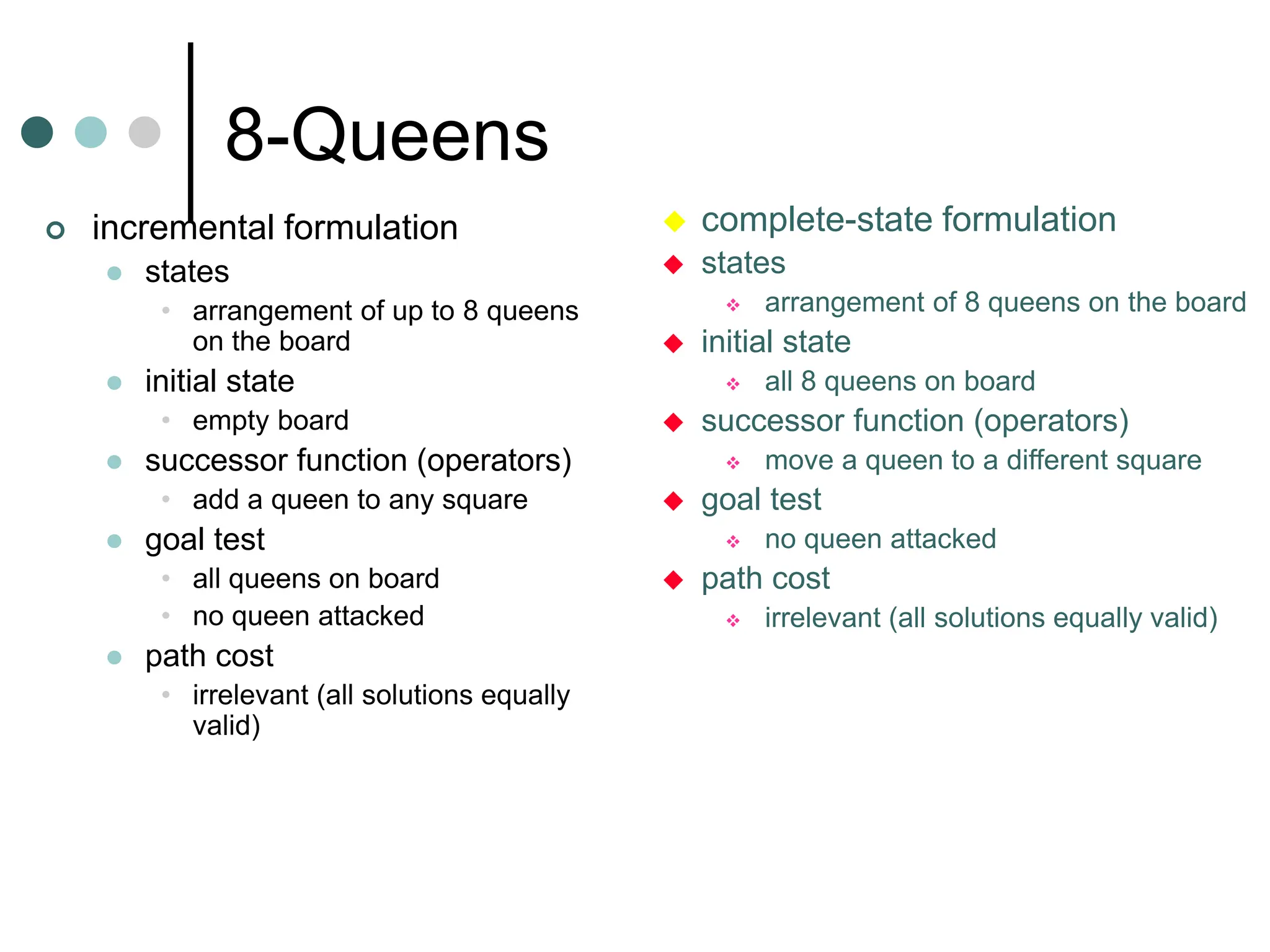




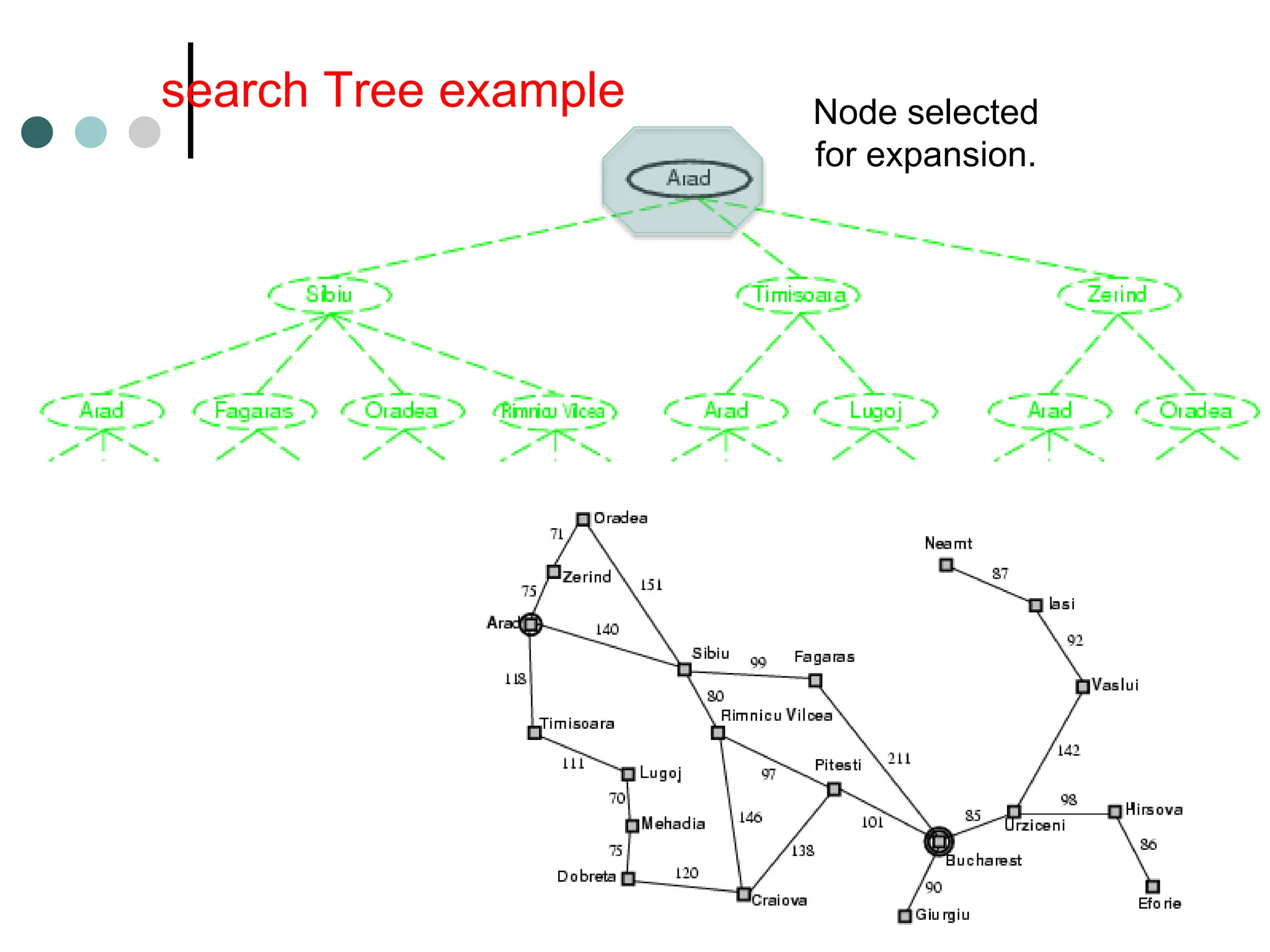
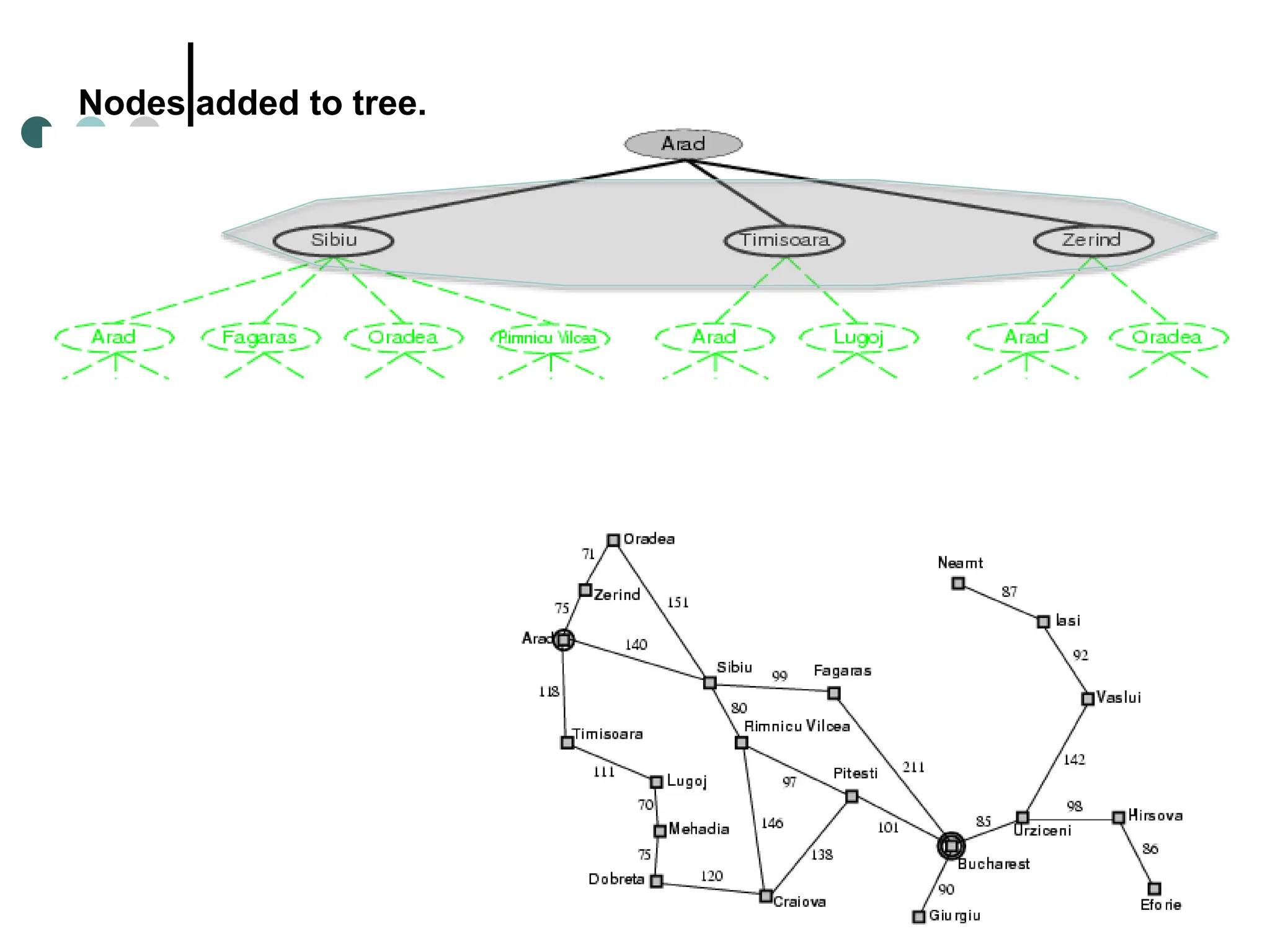
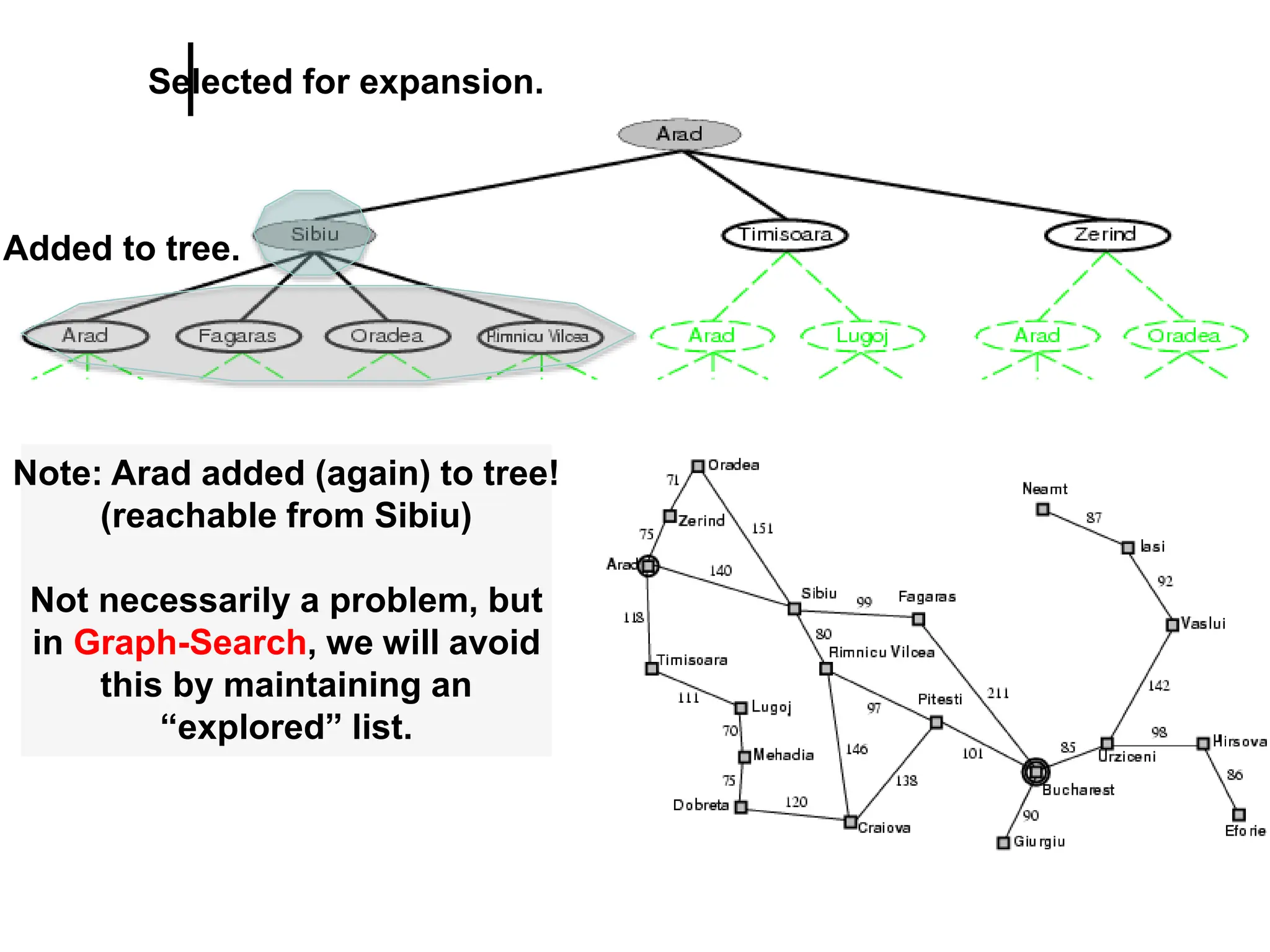

![General Tree Search Algorithm
function TREE-SEARCH(problem, fringe) returns solution
fringe := INSERT(MAKE-NODE(INITIAL-STATE[problem]), fringe)
loop do
if EMPTY?(fringe) then return failure
node := REMOVE-FIRST(fringe)
if GOAL-TEST[problem] applied to STATE[node] succeeds
then return SOLUTION(node)
fringe := INSERT-ALL(EXPAND(node, problem), fringe)
generate the node from the initial state of the problem
repeat
return failure if there are no more nodes in the fringe
examine the current node; if it’s a goal, return the solution
expand the current node, and add the new nodes to the fringe](https://image.slidesharecdn.com/artificialintelligenceunit1ppt1-240209054441-aa7f6f7b/75/artificial-Intelligence-unit1-ppt-1-ppt-75-2048.jpg)


























































![Unit-3-Part-1 [Autosaved].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/unit-3-part-1autosaved-230216062941-16596250-thumbnail.jpg?width=640&height=640&fit=bounds)





























