The document provides an overview of machine learning concepts including:
- Defining machine learning as computer algorithms that improve with experience and data
- Describing examples like speech recognition, medical diagnosis, and game playing
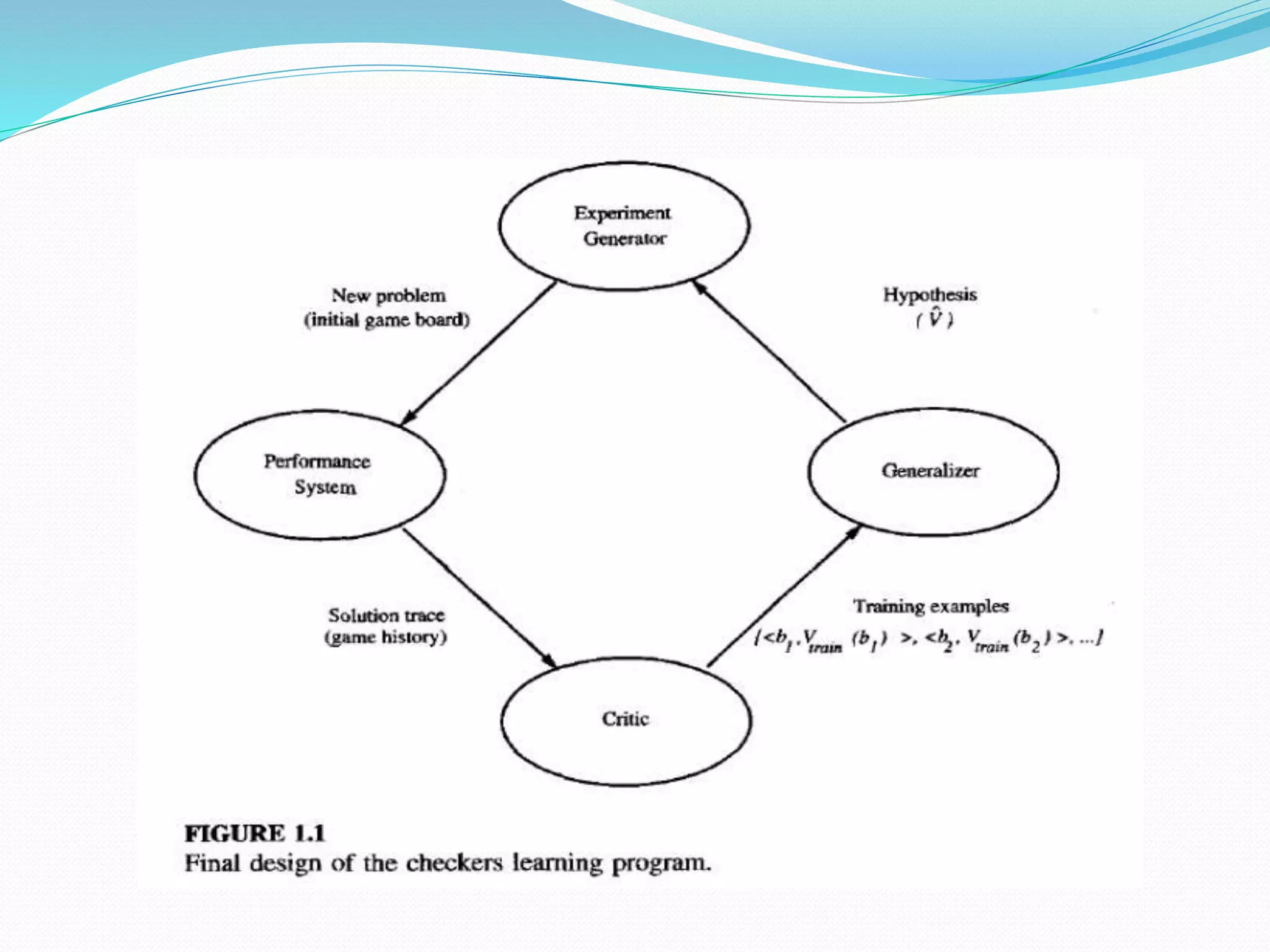
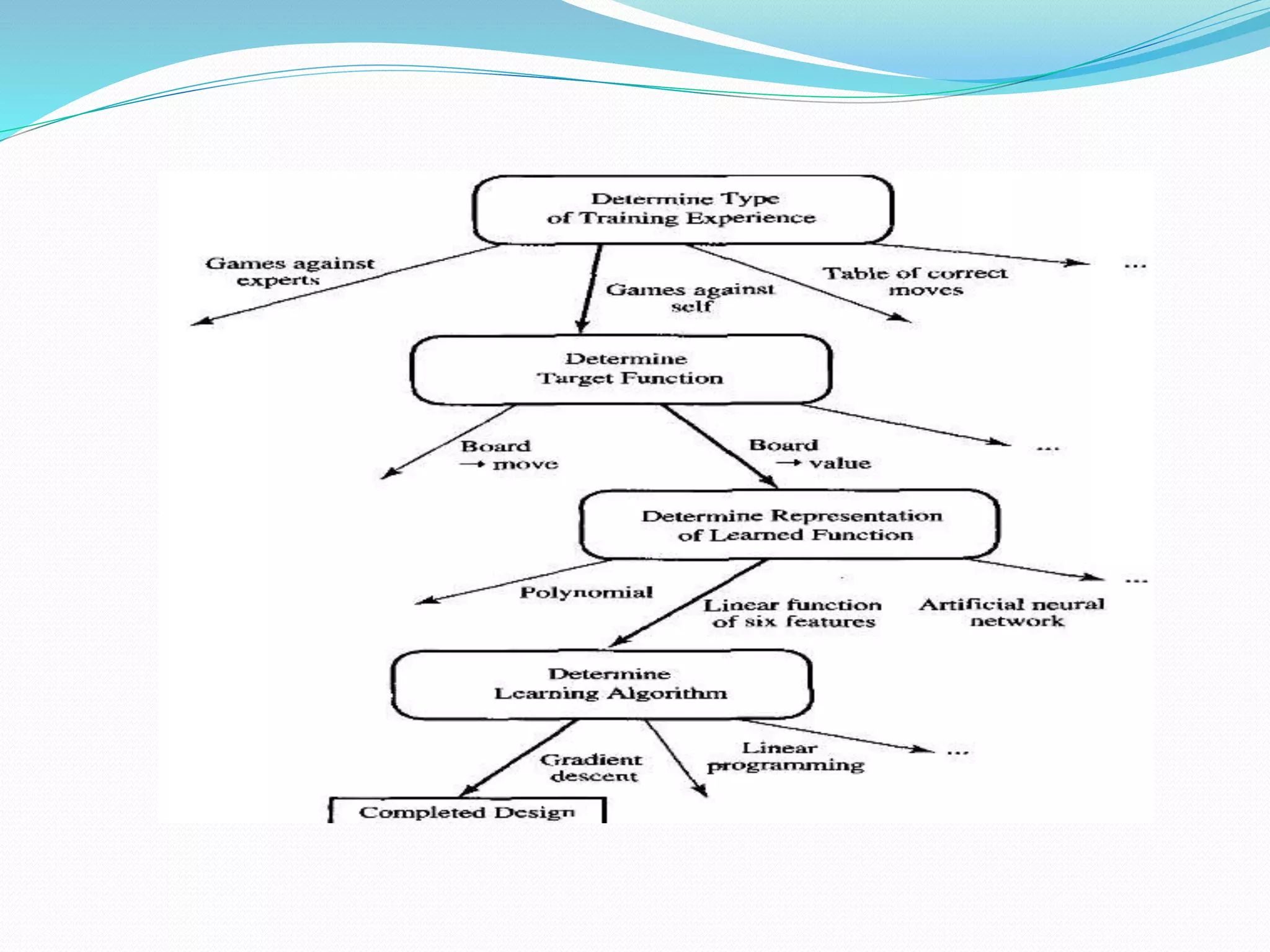
- Outlining the components of designing a machine learning system like choosing the target function, representation, and learning algorithm
- Explaining concepts like version spaces, decision trees, and neural networks that are used in machine learning applications









![A robot driving learning problem:
Learning to classify new astronomical structures.
Machine learning methods have been applied to a variety of large databases
to learn general regularities implicit in the data. For example, decision tree
learning algorithms have been used by NASA to learn how to classify
celestial objects from the second Palomar Observatory Sky Survey (Fayyad
et al. 1995). This system is now used to automatically classify all objects in
the Sky Survey, which consists of three terabytes of image data.
A robot driving learning problem:
Task T: driving on public four-lane highways using vision sensors
Performance measure P: average distance traveled before an error (as
judged by human overseer)
Training experience E: a sequence of images and steering commands
recorded while observing a human driver
NOTE: For more examples refer textbook[2].](https://image.slidesharecdn.com/mlunit-1-210401092349/75/ML_-Unit_1_PART_A-11-2048.jpg)

















![References
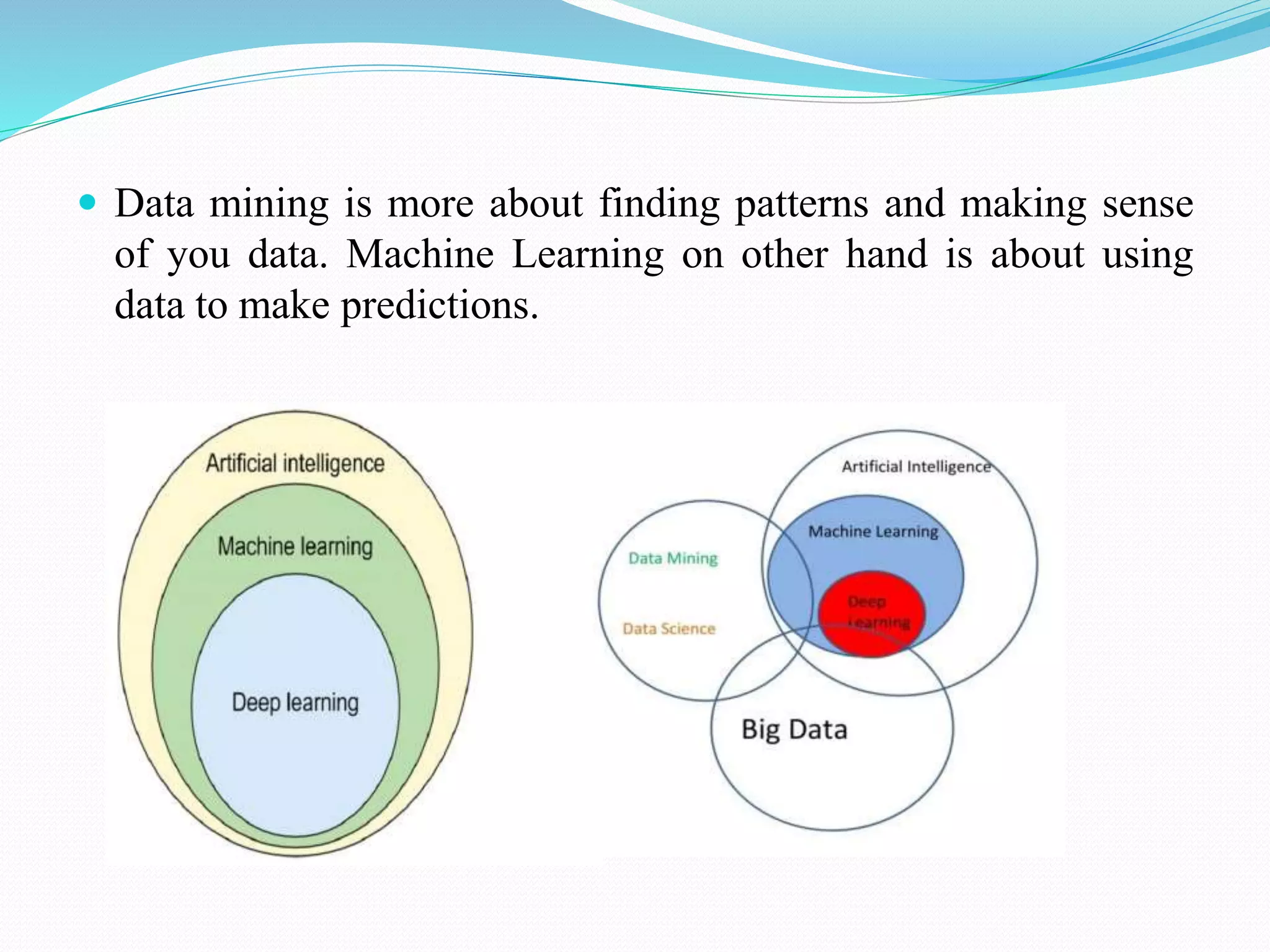
[1] https://dimensionless.in/what-is-the-difference-between-data-science-data-mining-and-machine-learning/
[2] https://www.cin.ufpe.br/~cavmj/Machine%20-%20Learning%20-%20Tom%20Mitchell.pdf
[3] https://en.wikipedia.org/wiki/File:Fig-X_All_ML_as_a_subfield_of_AI.jpg](https://image.slidesharecdn.com/mlunit-1-210401092349/75/ML_-Unit_1_PART_A-31-2048.jpg)








































![UNIT 1 Machine Learning [KCS-055] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit1machinelearningkcs-0551-230208173320-a2f4e13a-thumbnail.jpg?width=640&height=640&fit=bounds)




































