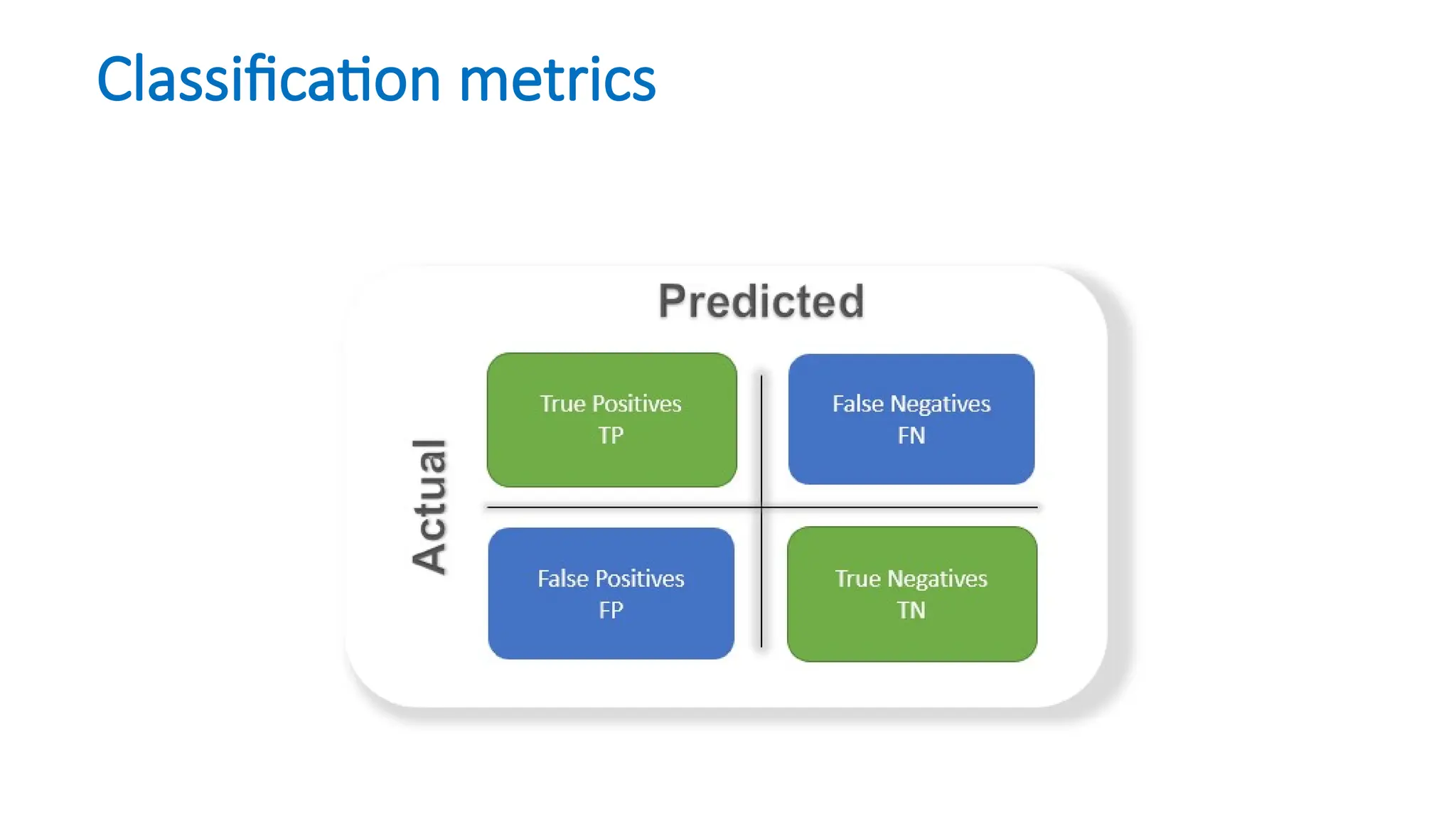
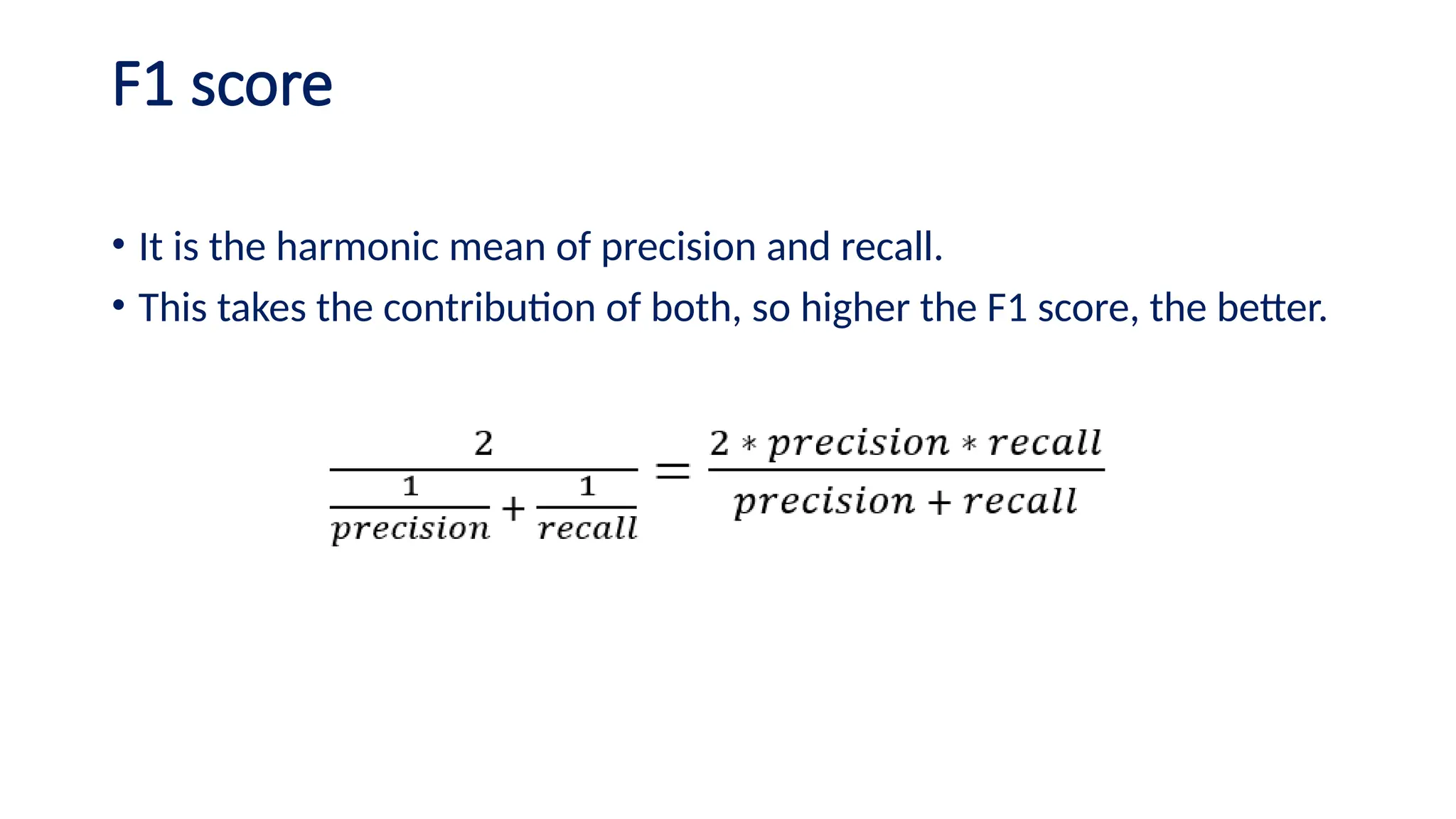
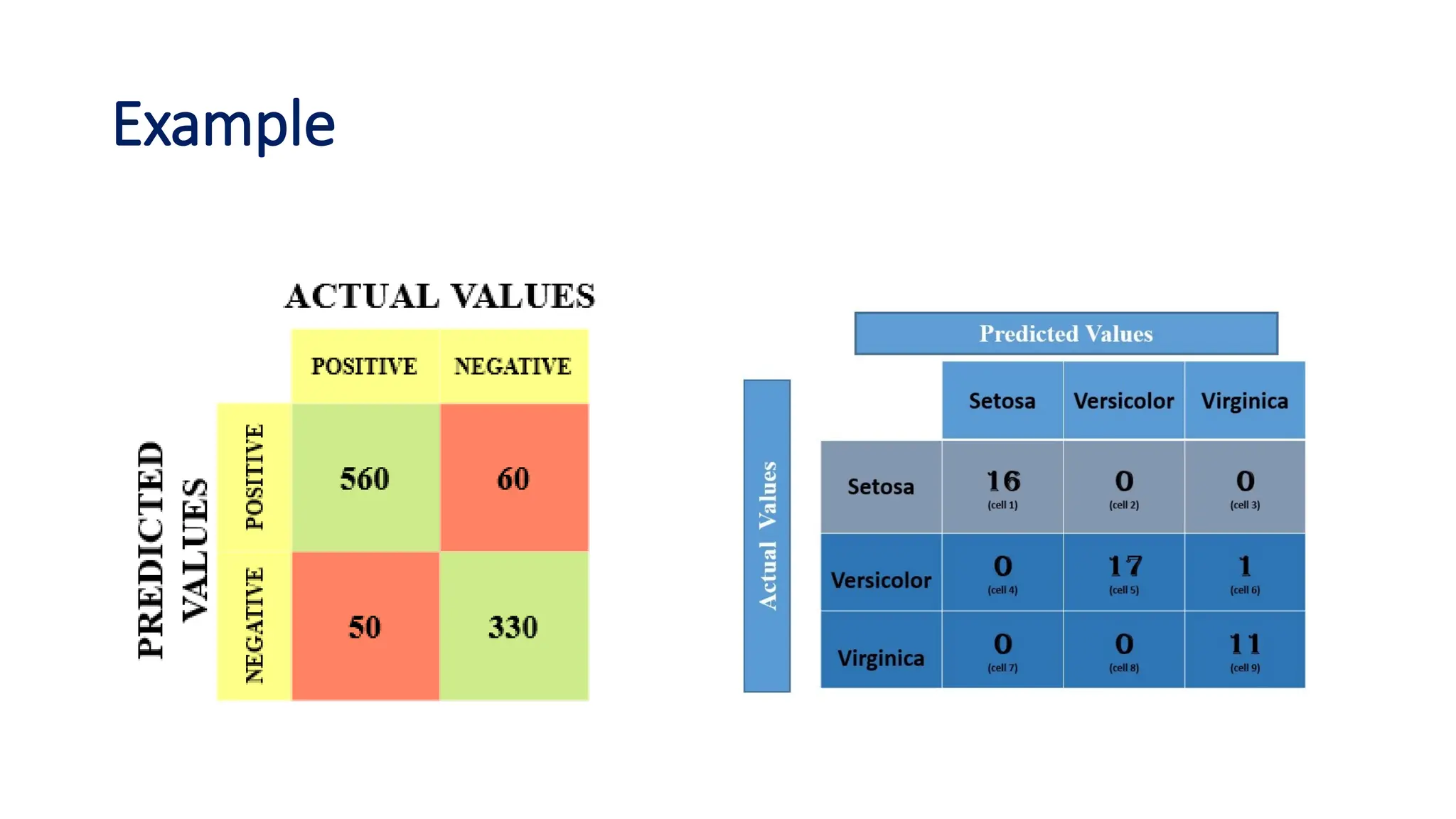
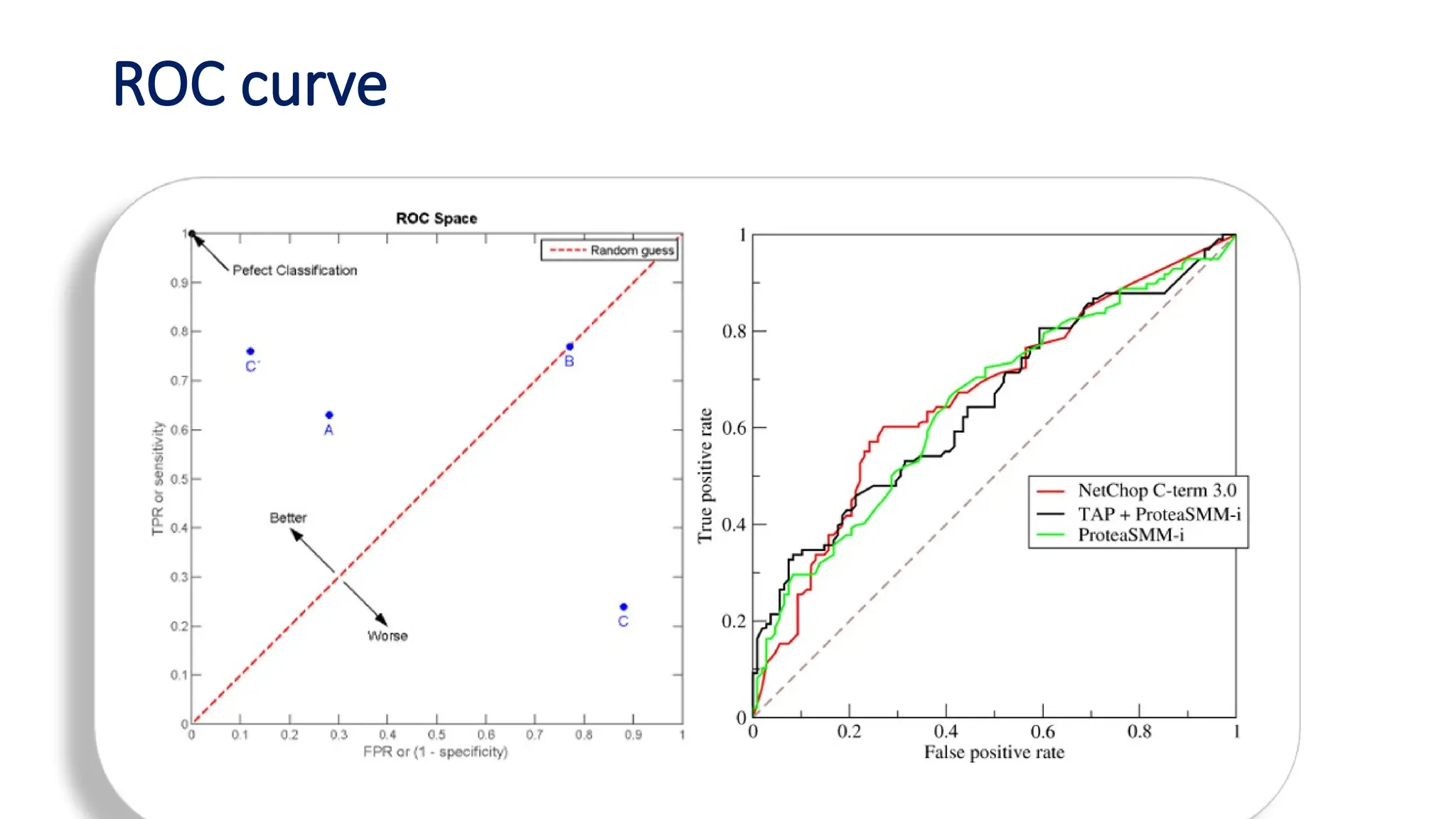
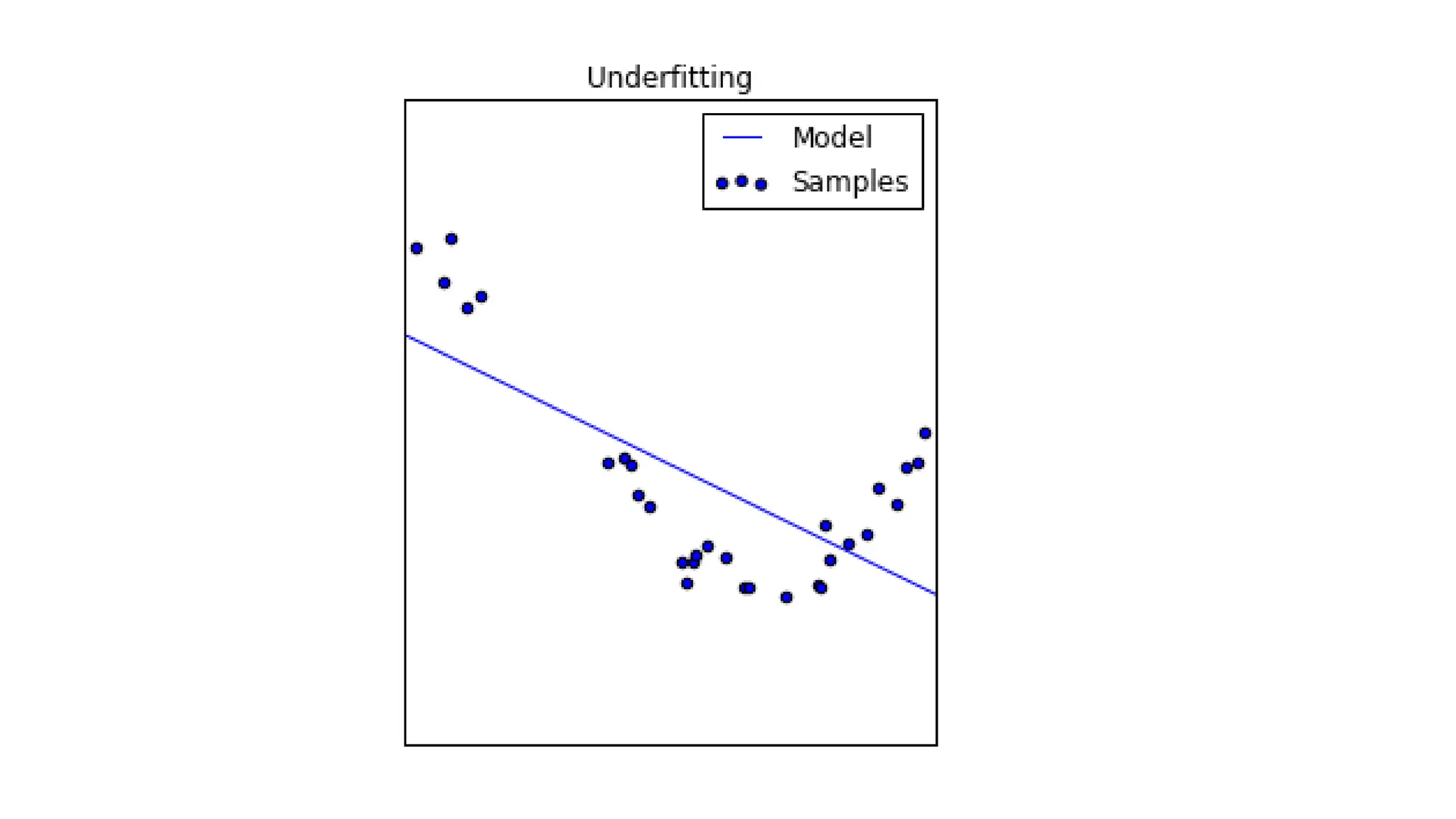
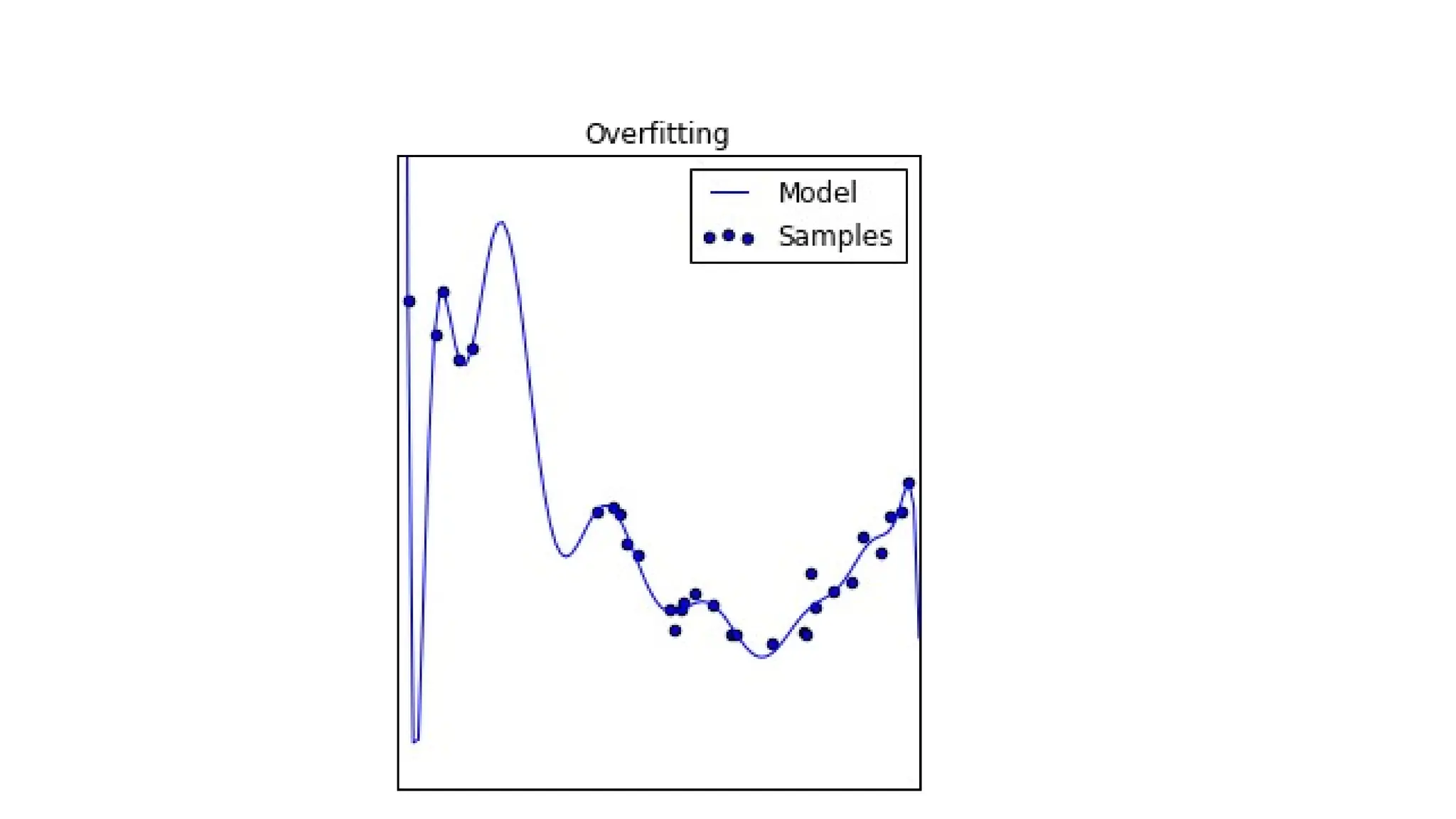
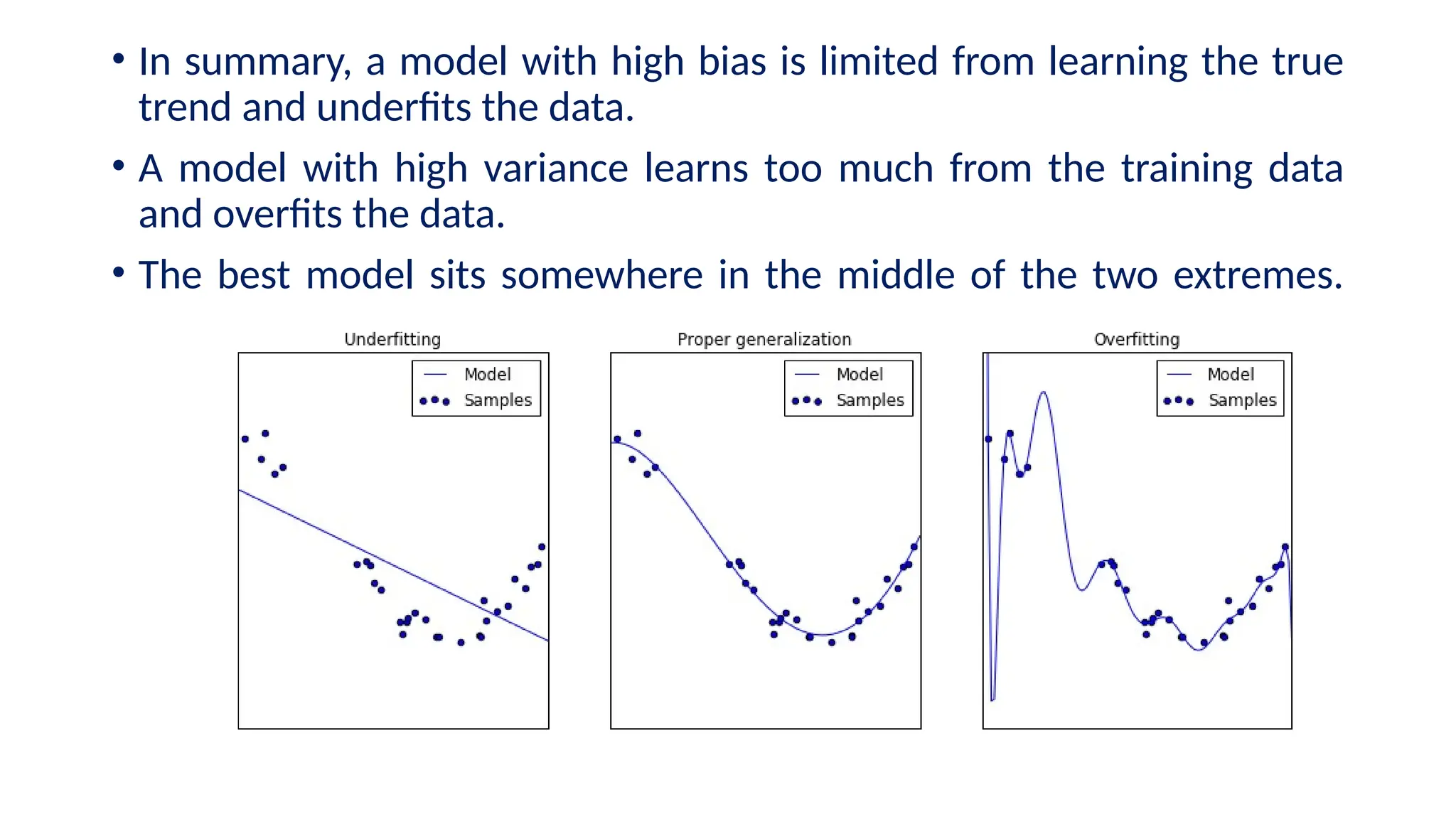
The document discusses evaluation measures for machine learning models, focusing on metrics for classification such as accuracy, precision, recall, and F1 score. It explains the concepts of bias and variance, highlighting the importance of finding a balance between the two for optimal model performance. Additionally, it introduces the ROC curve as a tool for assessing model predictions and understanding the trade-offs between true positive and false positive rates.