Downloaded 61 times

















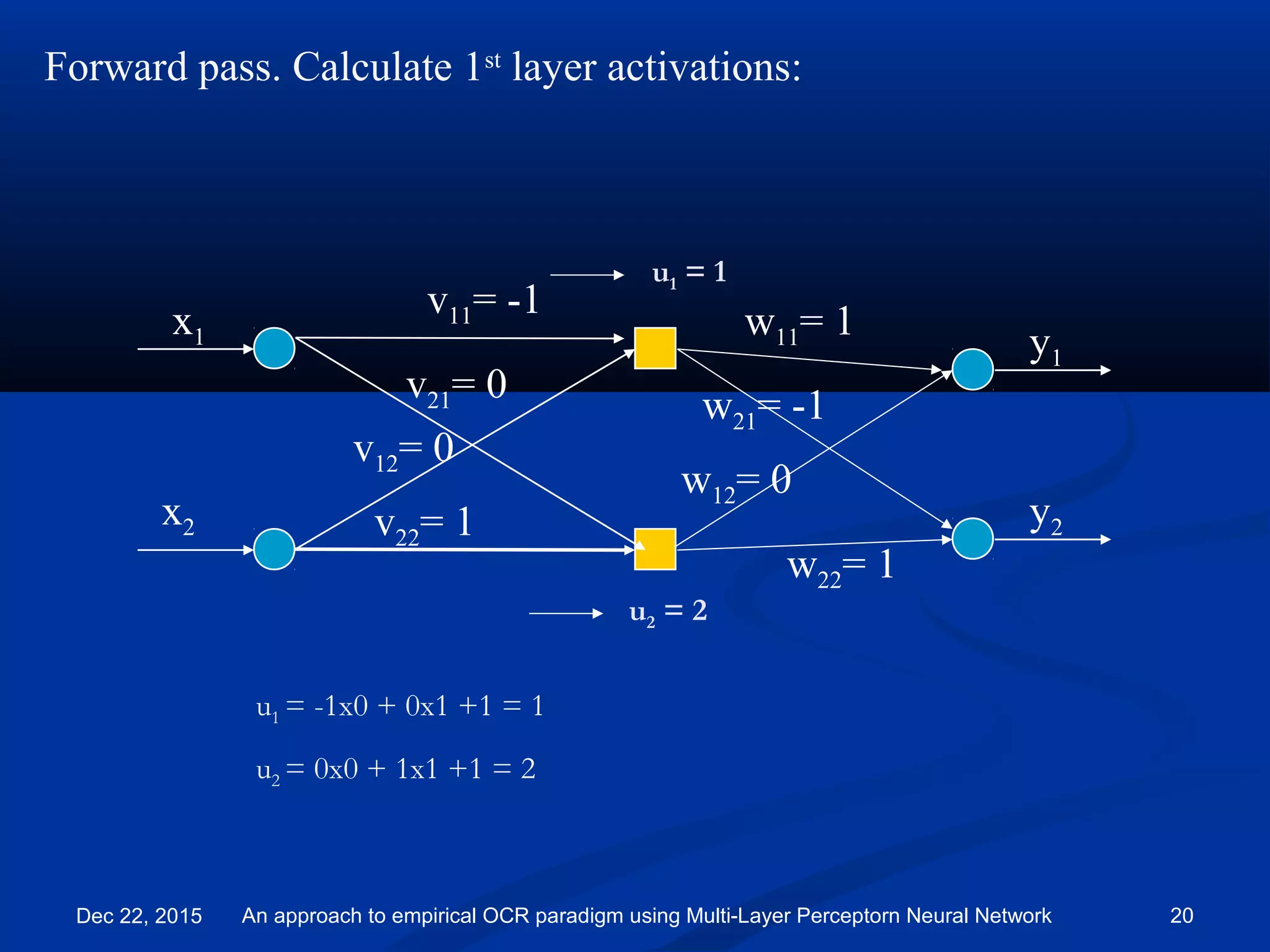
![All biases set to 1. Will not draw them for clarity.
Learning rate η = 0.1
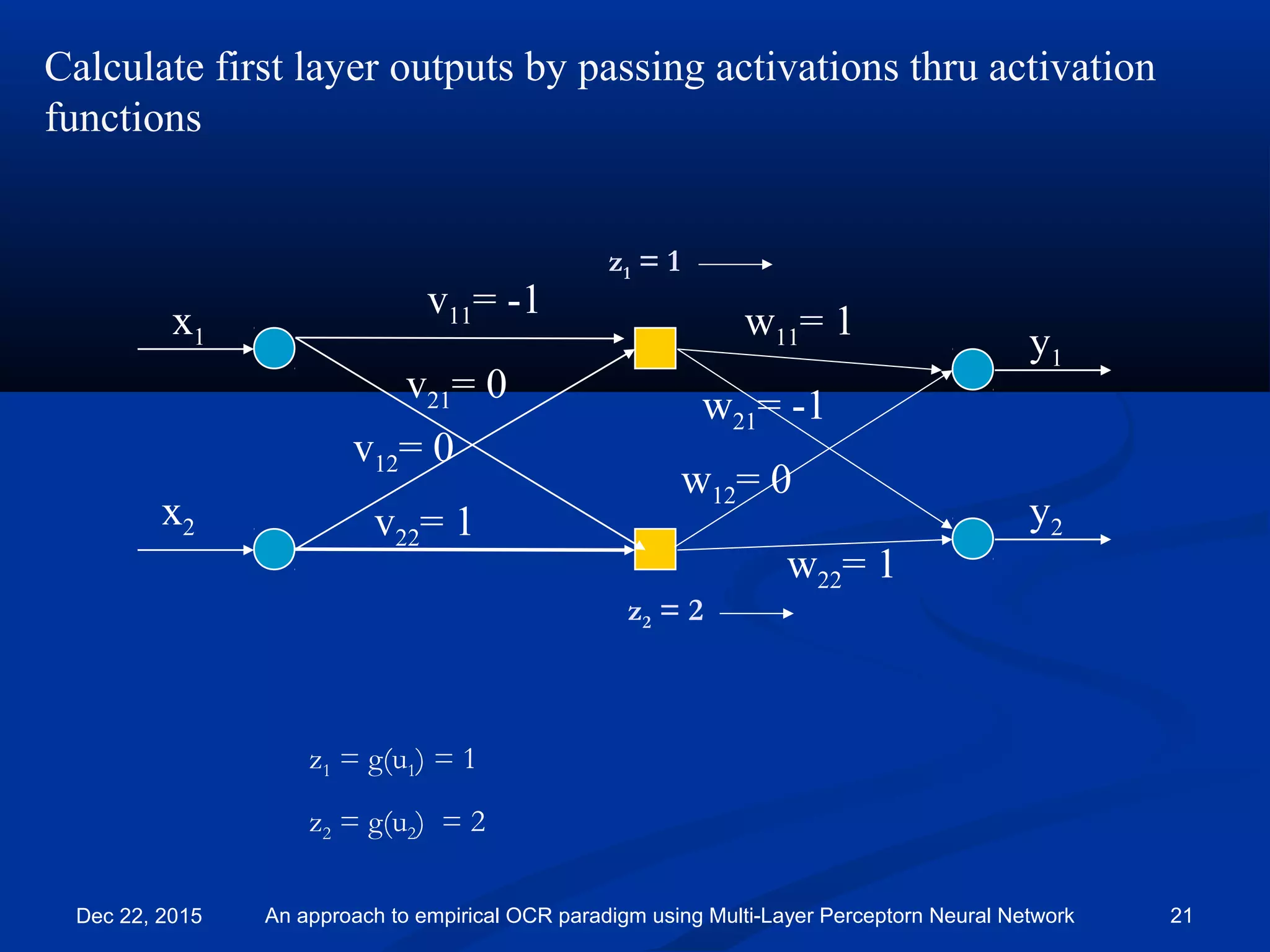
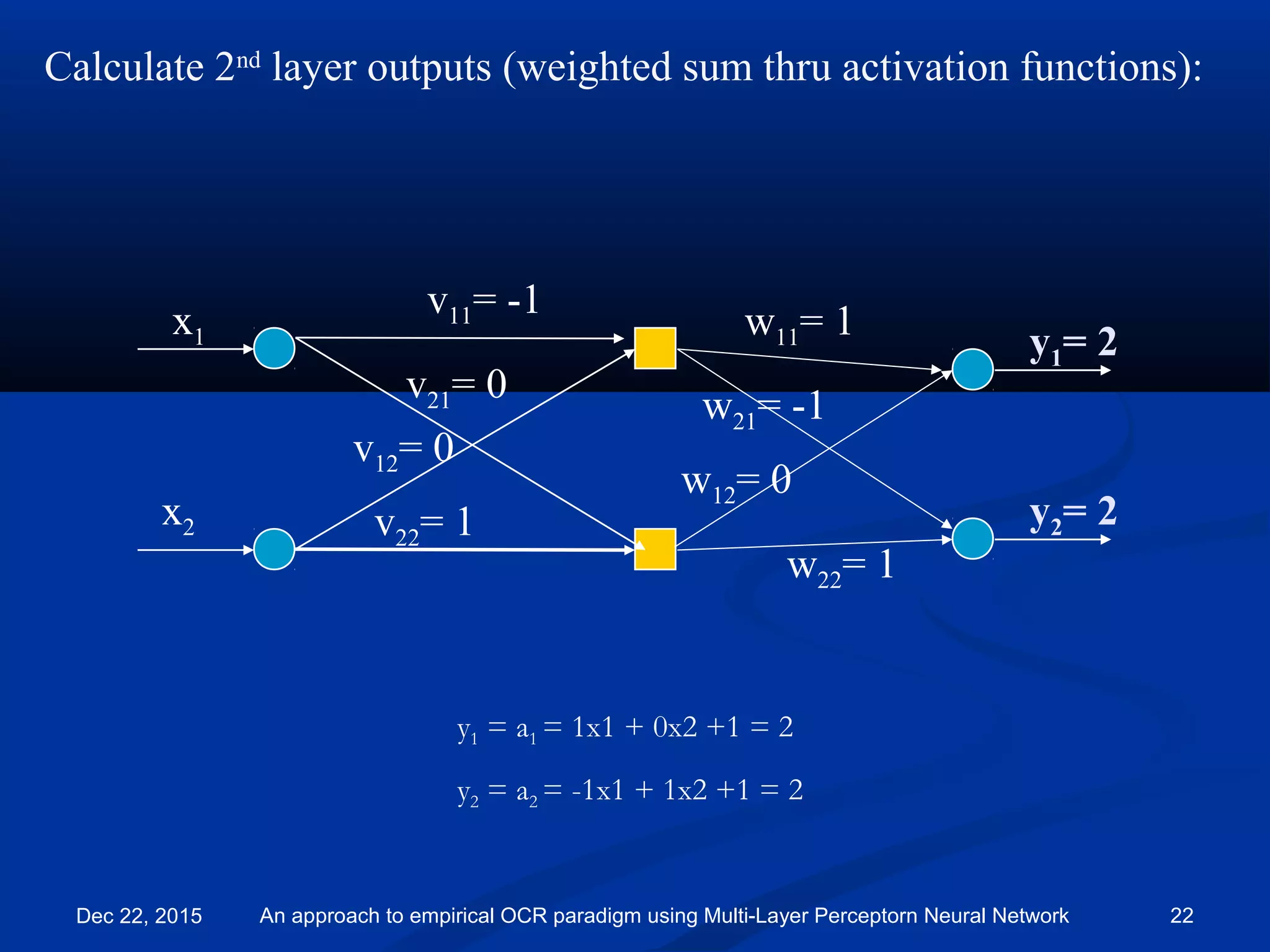
y1
y2
x1
x2
v11= -1
v21= 0
v12= 0
v22= 1
w11= 1
w21= -1
w12= 0
w22= 1
Have input [0 1] with target [1 0].
x1= 0
x2= 1
Dec 22, 2015 An approach to empirical OCR paradigm using Multi-Layer Perceptorn Neural Network 19](https://image.slidesharecdn.com/082iccit-2015-151222130557/75/An-approach-to-empirical-Optical-Character-recognition-paradigm-using-Multi-Layer-Perceptorn-Neural-Network-19-2048.jpg)
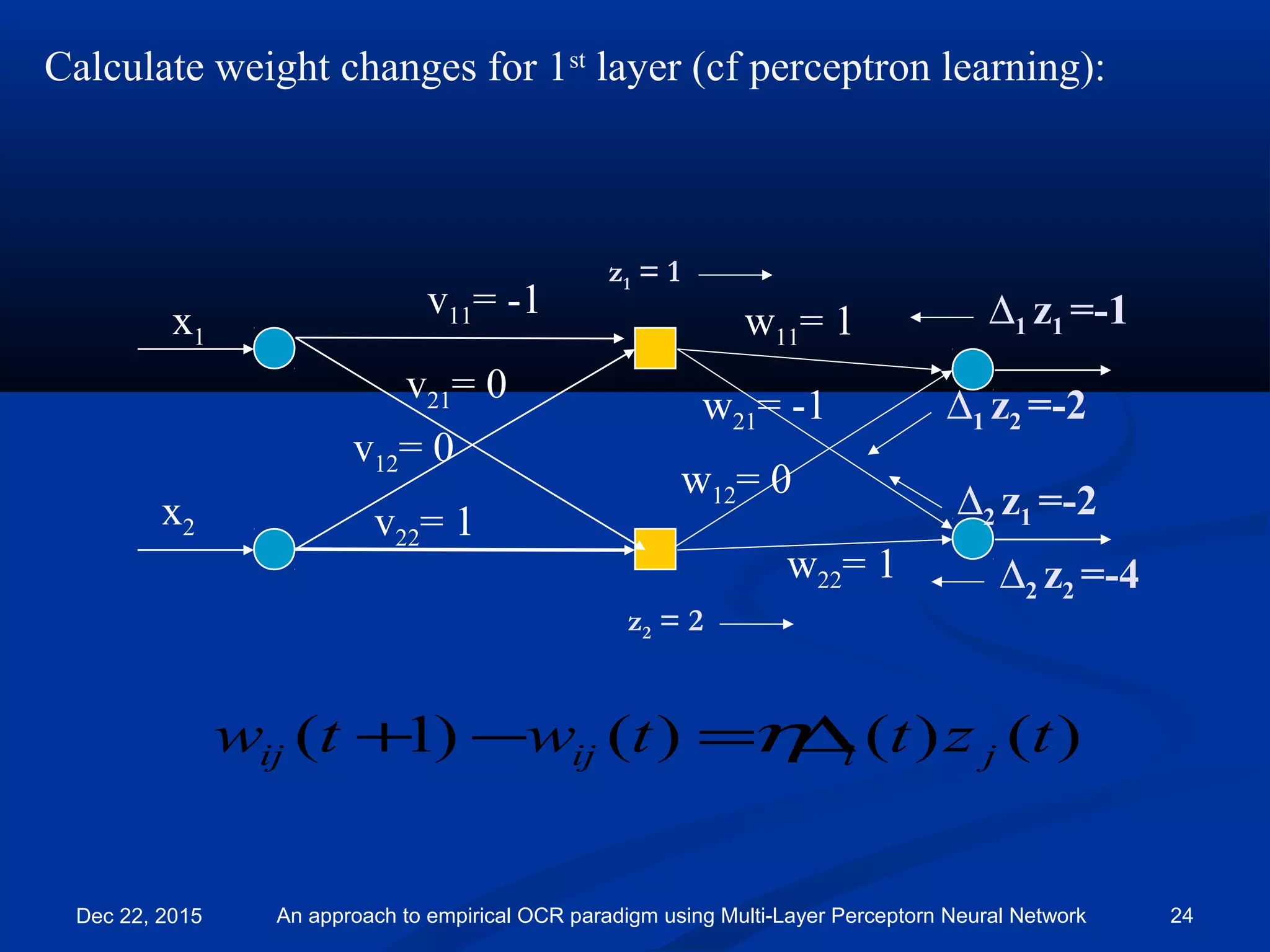
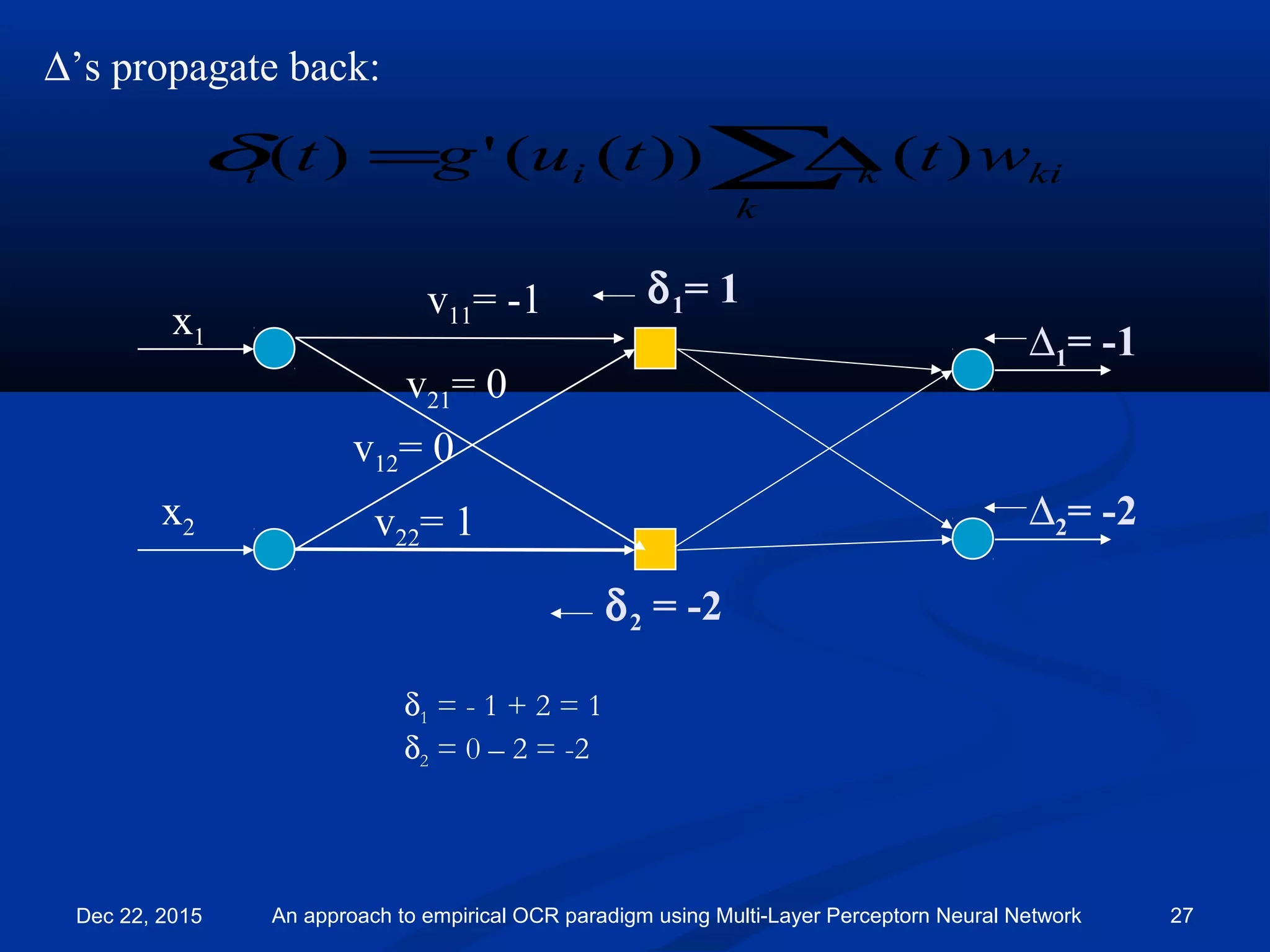
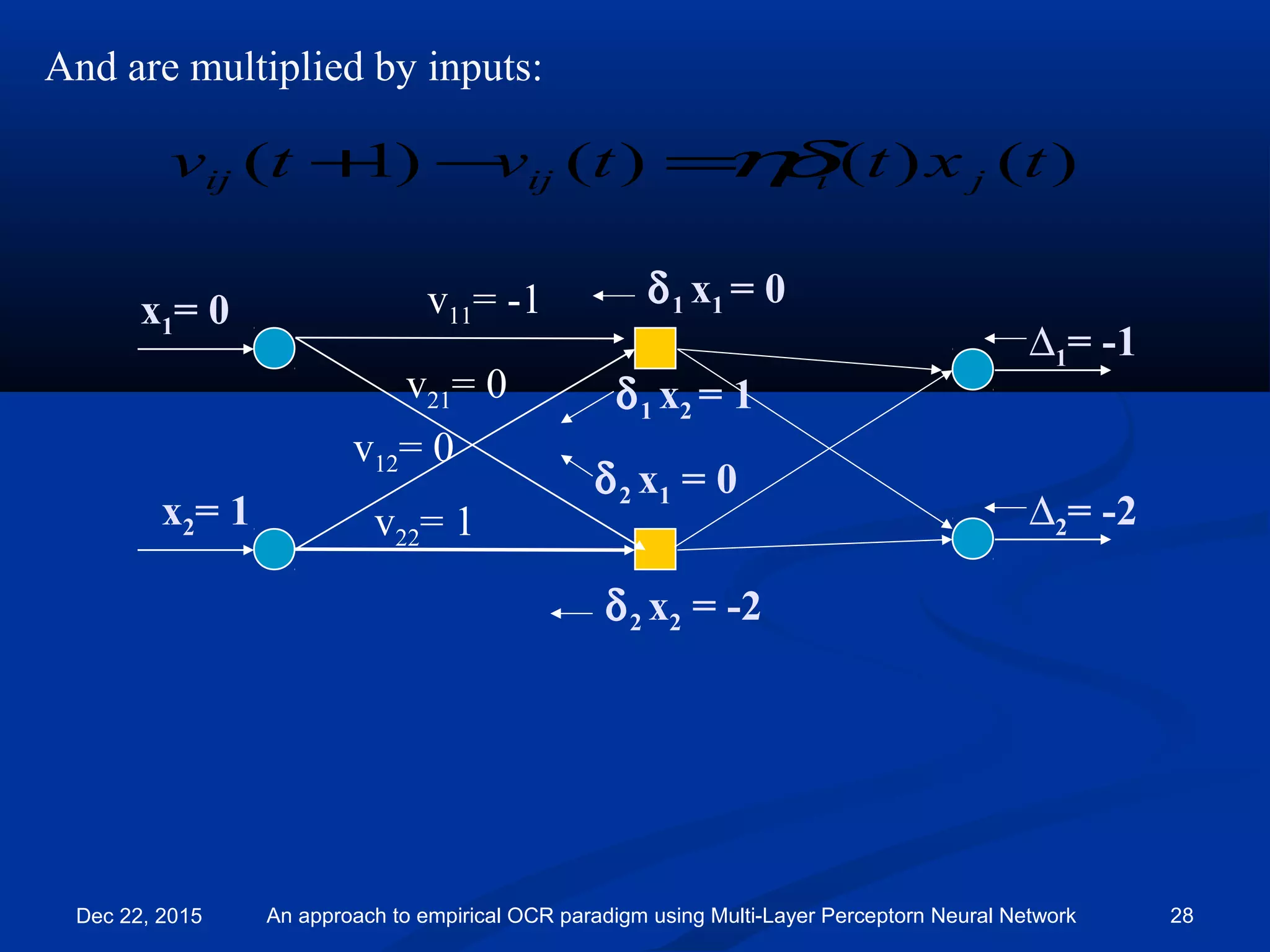
![Backward pass:
∆1= -1
∆2= -2
x1
x2
v11= -1
v21= 0
v12= 0
v22= 1
w11= 1
w21= -1
w12= 0
w22= 1
)())(('))()((
)()()()1(
tztagtytd
tzttwtw
jiii
jiijij
−=
∆=−+
η
η
Target =[1, 0] so d1 = 1 and d2 = 0
So:
∆1 = (d1 - y1 )= 1 – 2 = -1
∆2 = (d2 - y2 )= 0 – 2 = -2
Dec 22, 2015 An approach to empirical OCR paradigm using Multi-Layer Perceptorn Neural Network 23](https://image.slidesharecdn.com/082iccit-2015-151222130557/75/An-approach-to-empirical-Optical-Character-recognition-paradigm-using-Multi-Layer-Perceptorn-Neural-Network-23-2048.jpg)



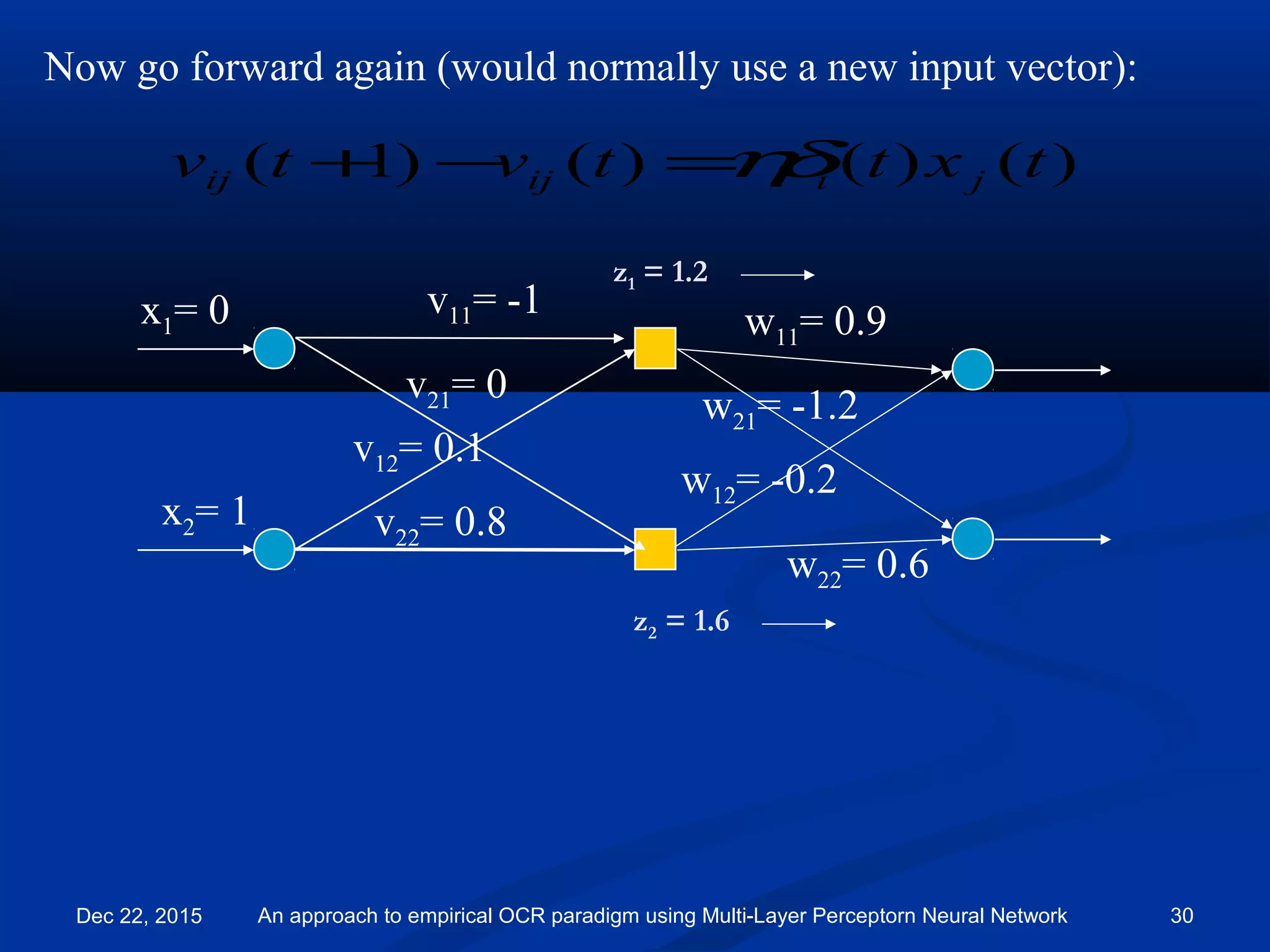
![Now go forward again (would normally use a new input vector):
v11= -1
v21= 0
v12= 0.1
v22= 0.8
)()()()1( txttvtv jiijij ηδ=−+
x2= 1
x1= 0 w11= 0.9
w21= -1.2
w12= -0.2
w22= 0.6
y2 = 0.32
y1 = 1.66
Outputs now closer to target value [1, 0]
Dec 22, 2015 An approach to empirical OCR paradigm using Multi-Layer Perceptorn Neural Network 31](https://image.slidesharecdn.com/082iccit-2015-151222130557/75/An-approach-to-empirical-Optical-Character-recognition-paradigm-using-Multi-Layer-Perceptorn-Neural-Network-31-2048.jpg)





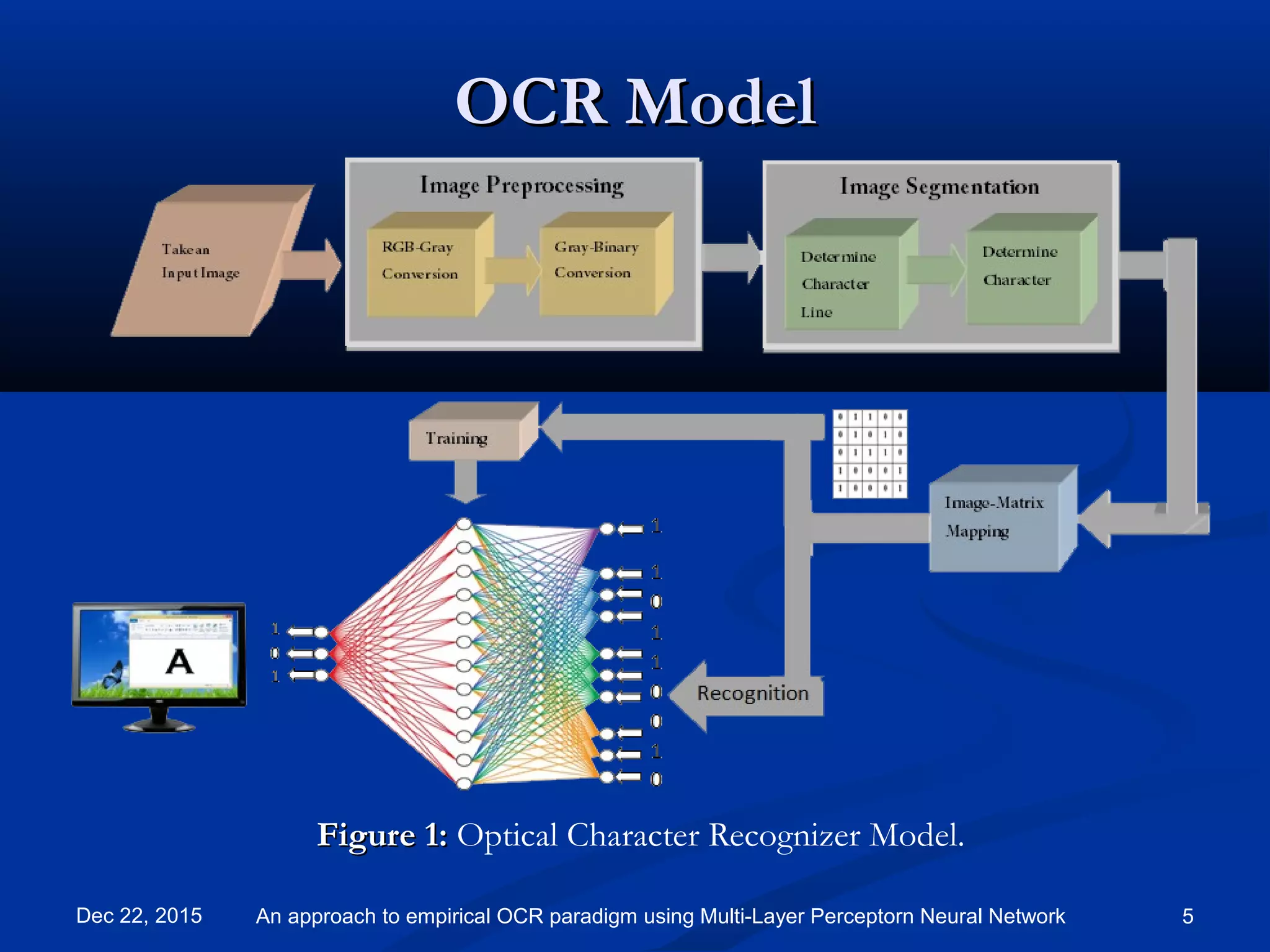
An artificial neural network approach to optical character recognition (OCR) is presented using a multi-layer perceptron model. The model acquires an image, preprocesses it through steps like grayscale conversion and segmentation, extracts features by mapping characters to matrices, then trains a neural network to classify characters. Experimental results show 91.53% accuracy for isolated characters and 80.65% for characters in sentences.





















![Text reader [OCR]](https://cdn.slidesharecdn.com/ss_thumbnails/textreaderocr-191031162423-thumbnail.jpg?width=640&height=640&fit=bounds)