Downloaded 11 times

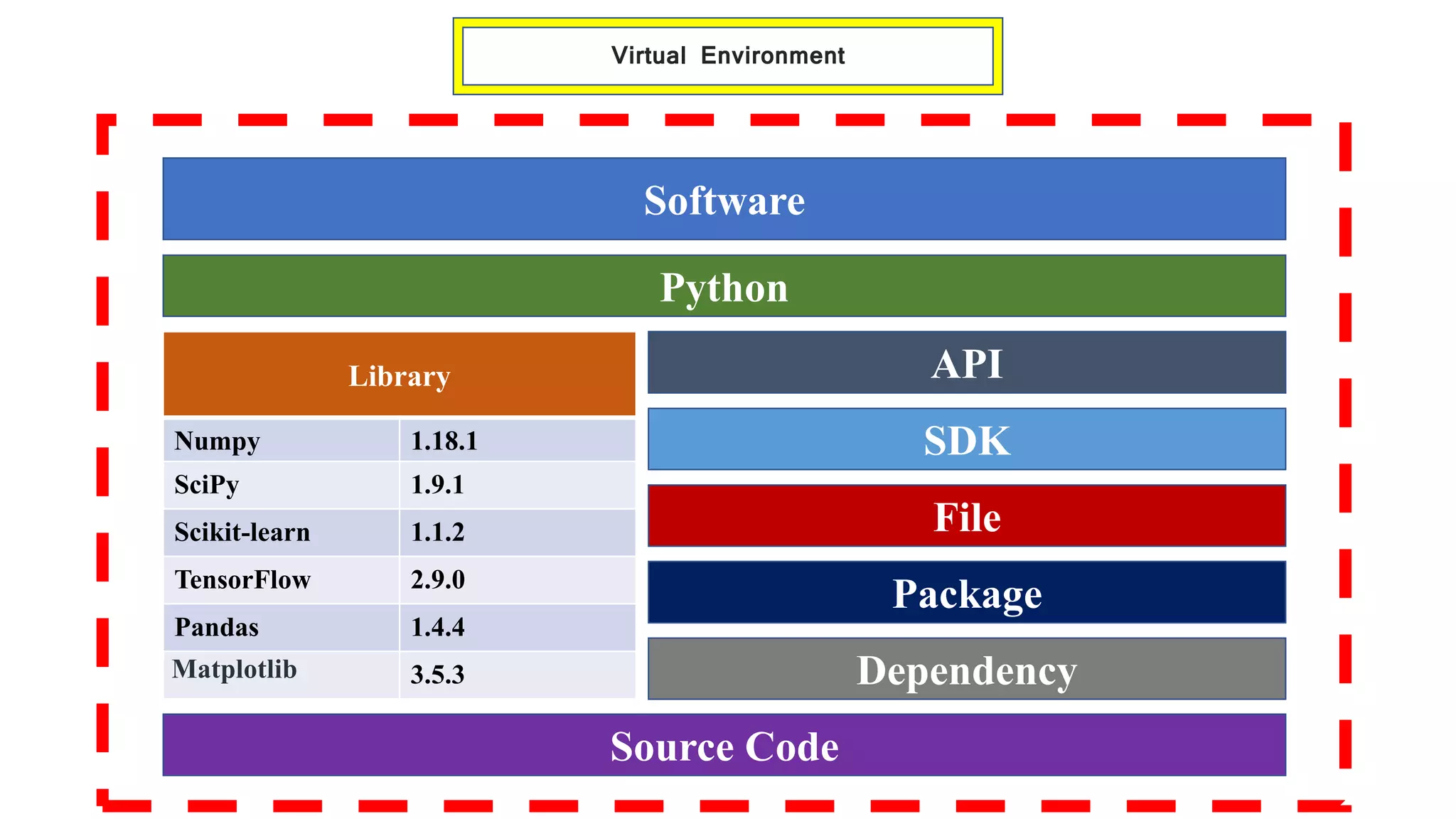


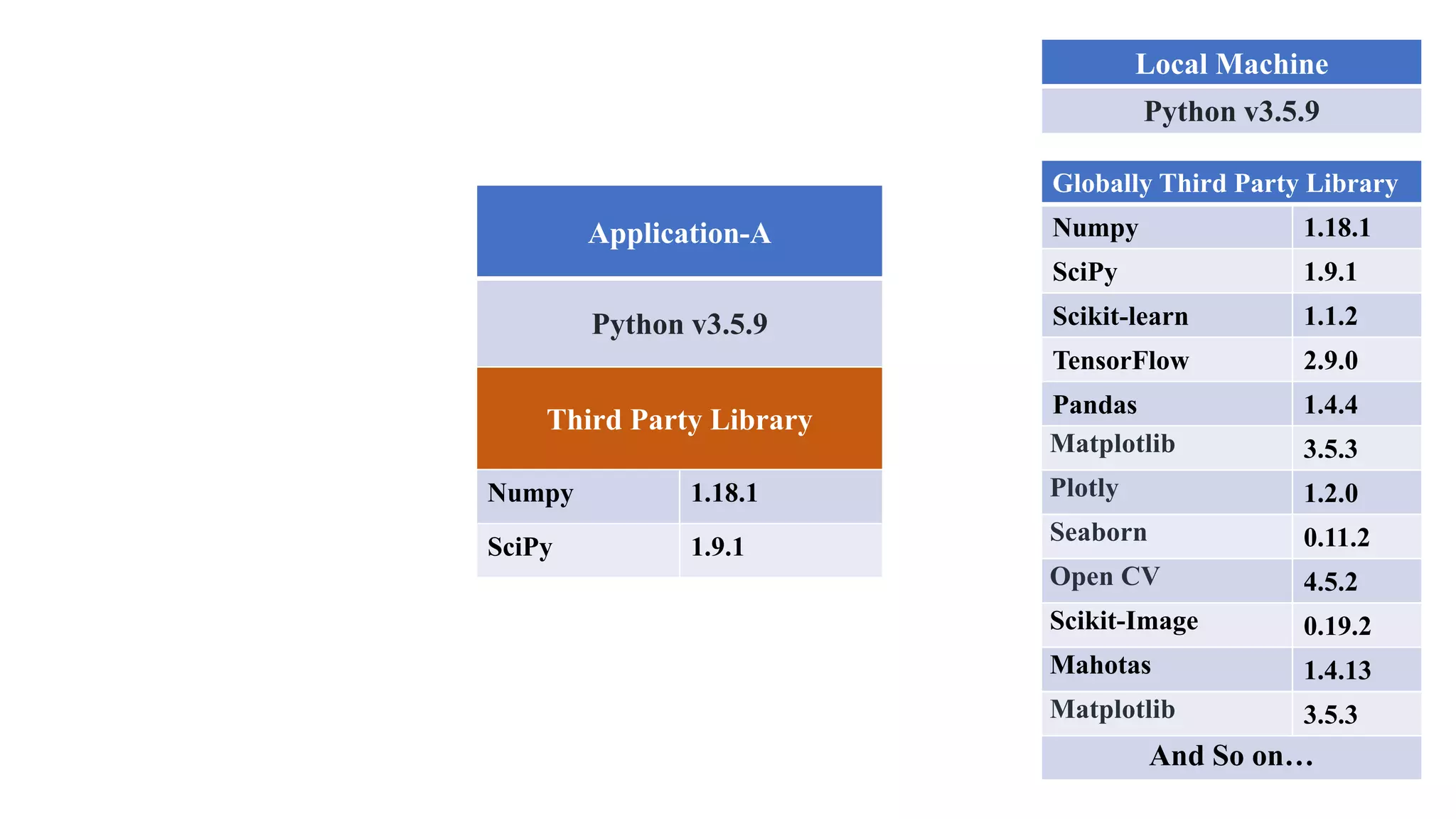
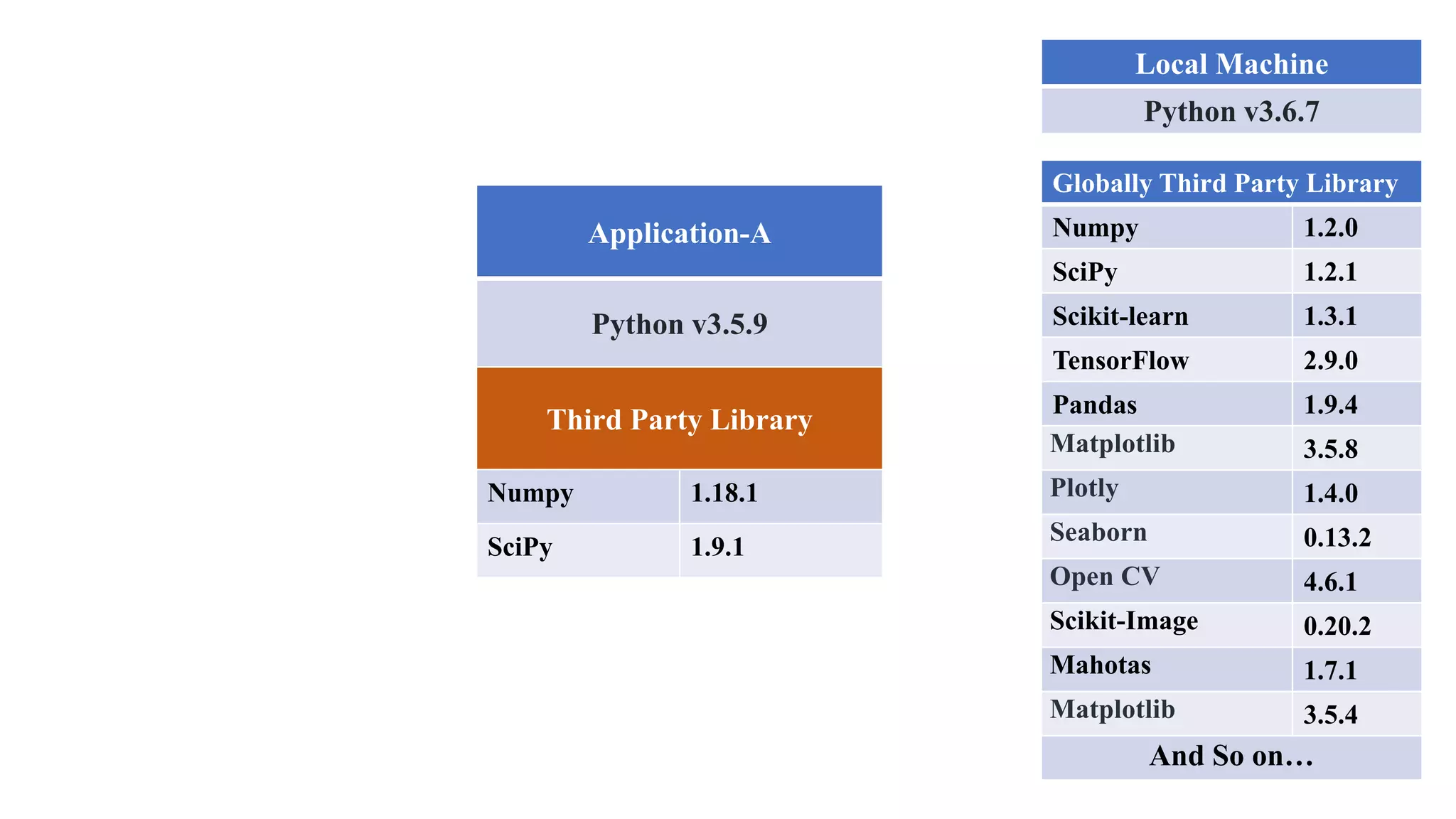
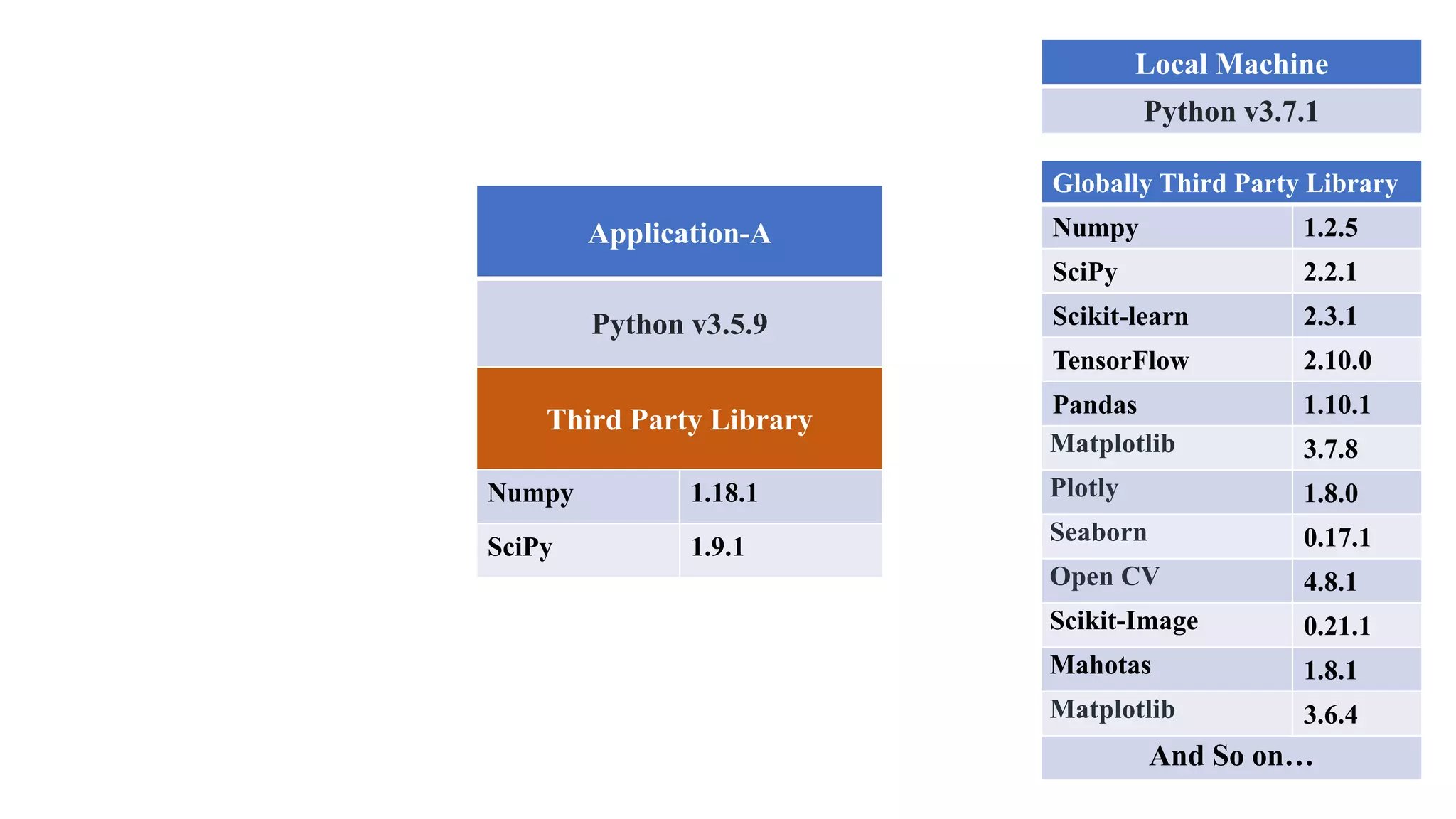
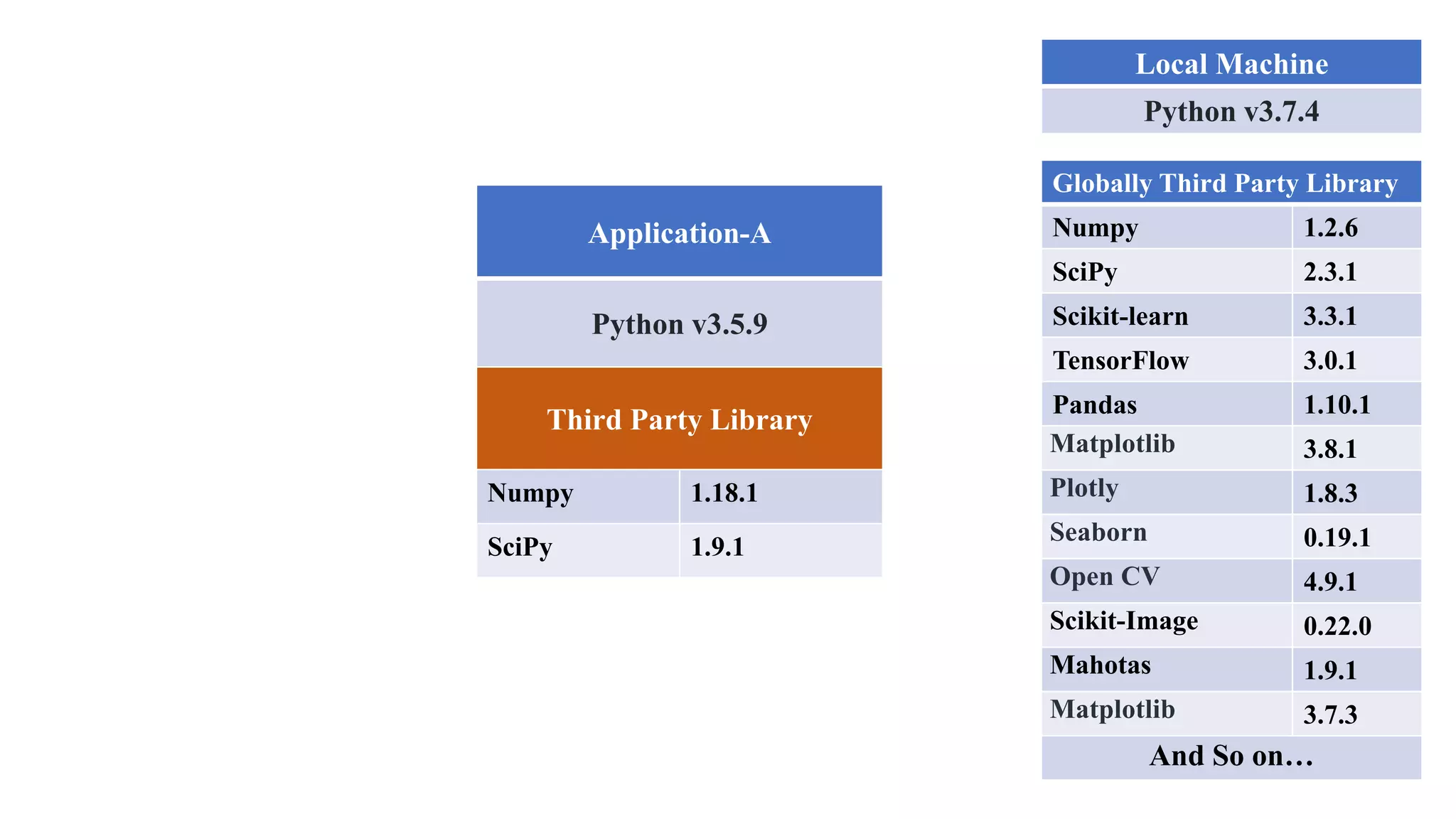
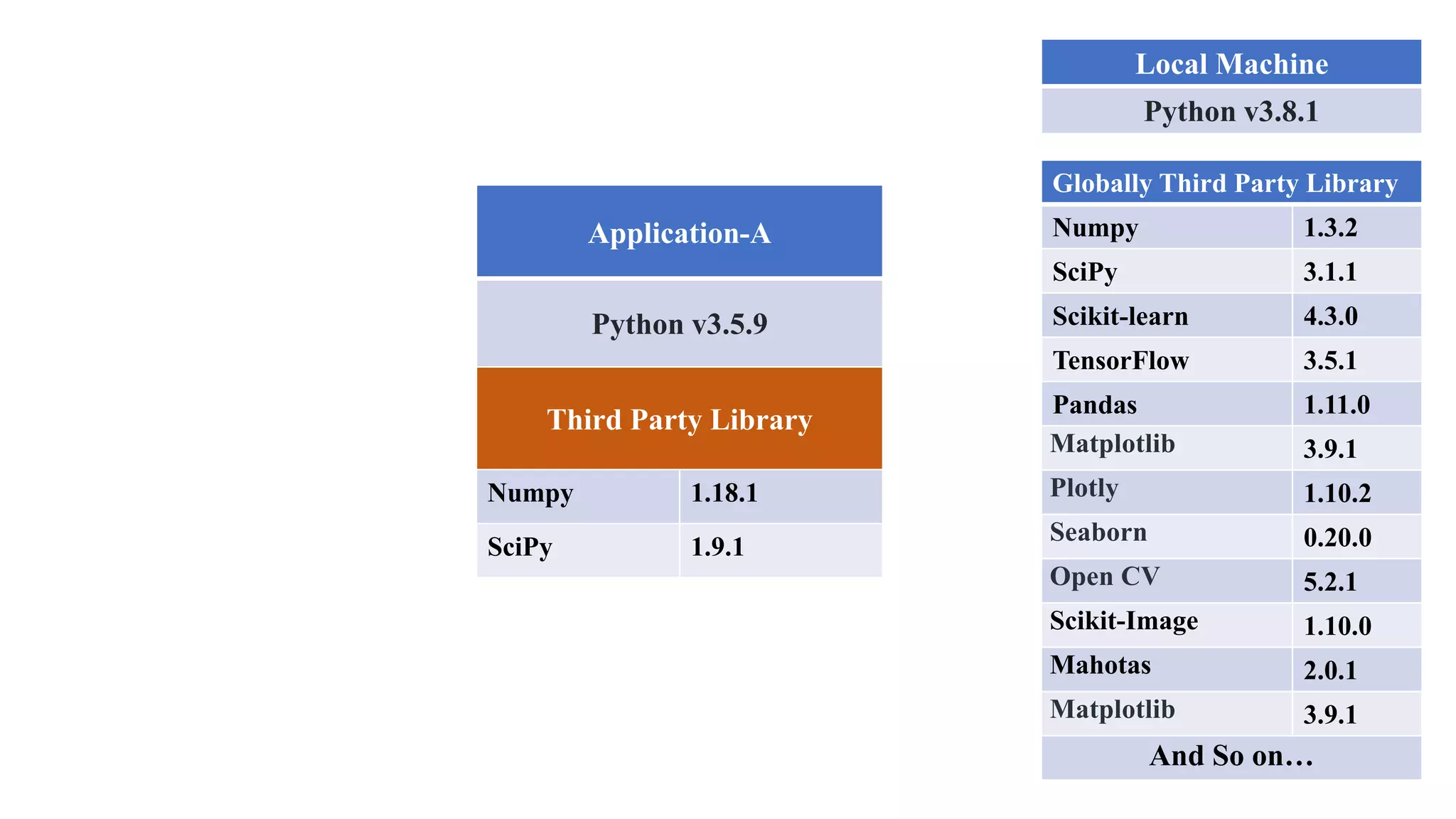
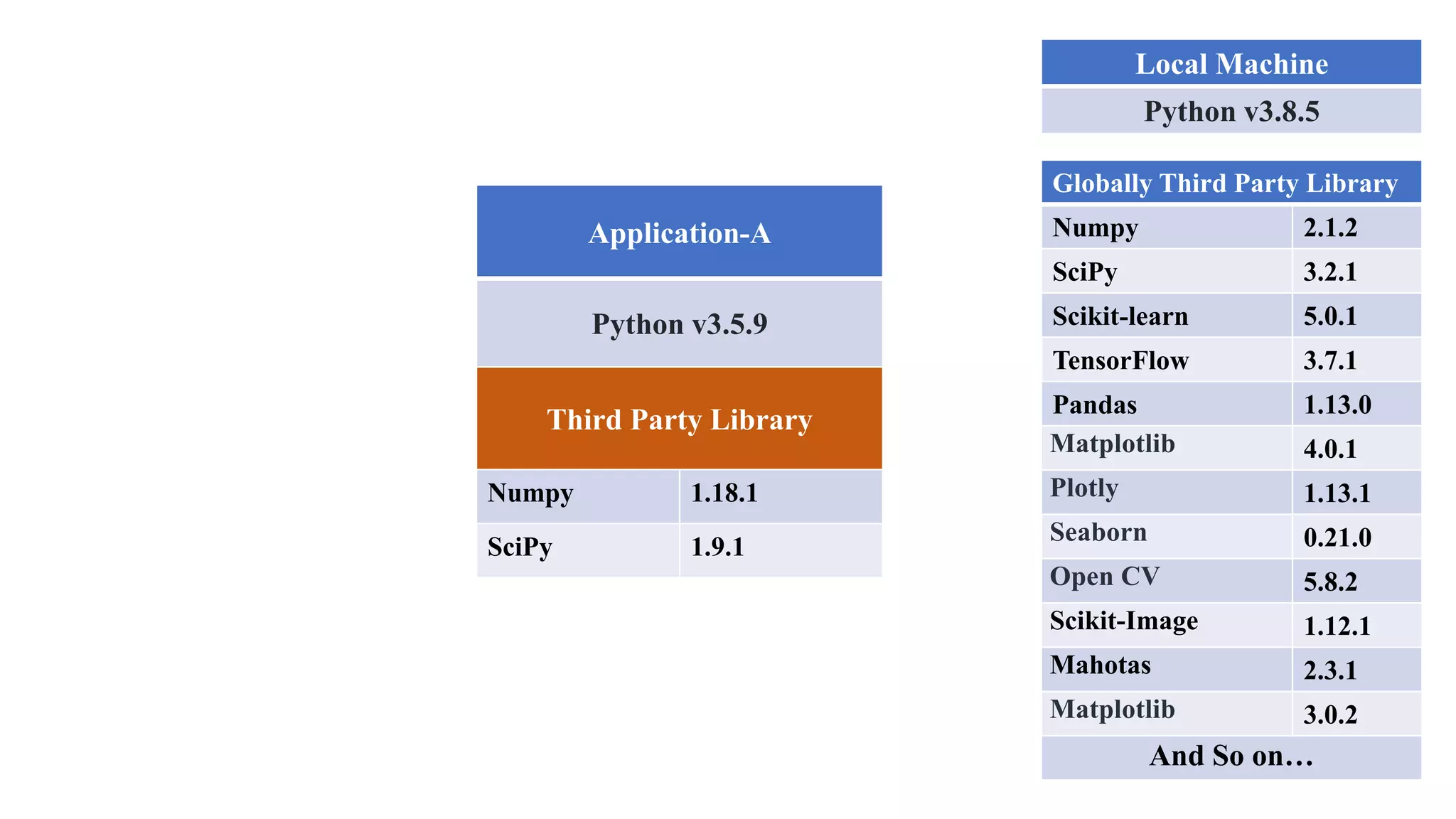
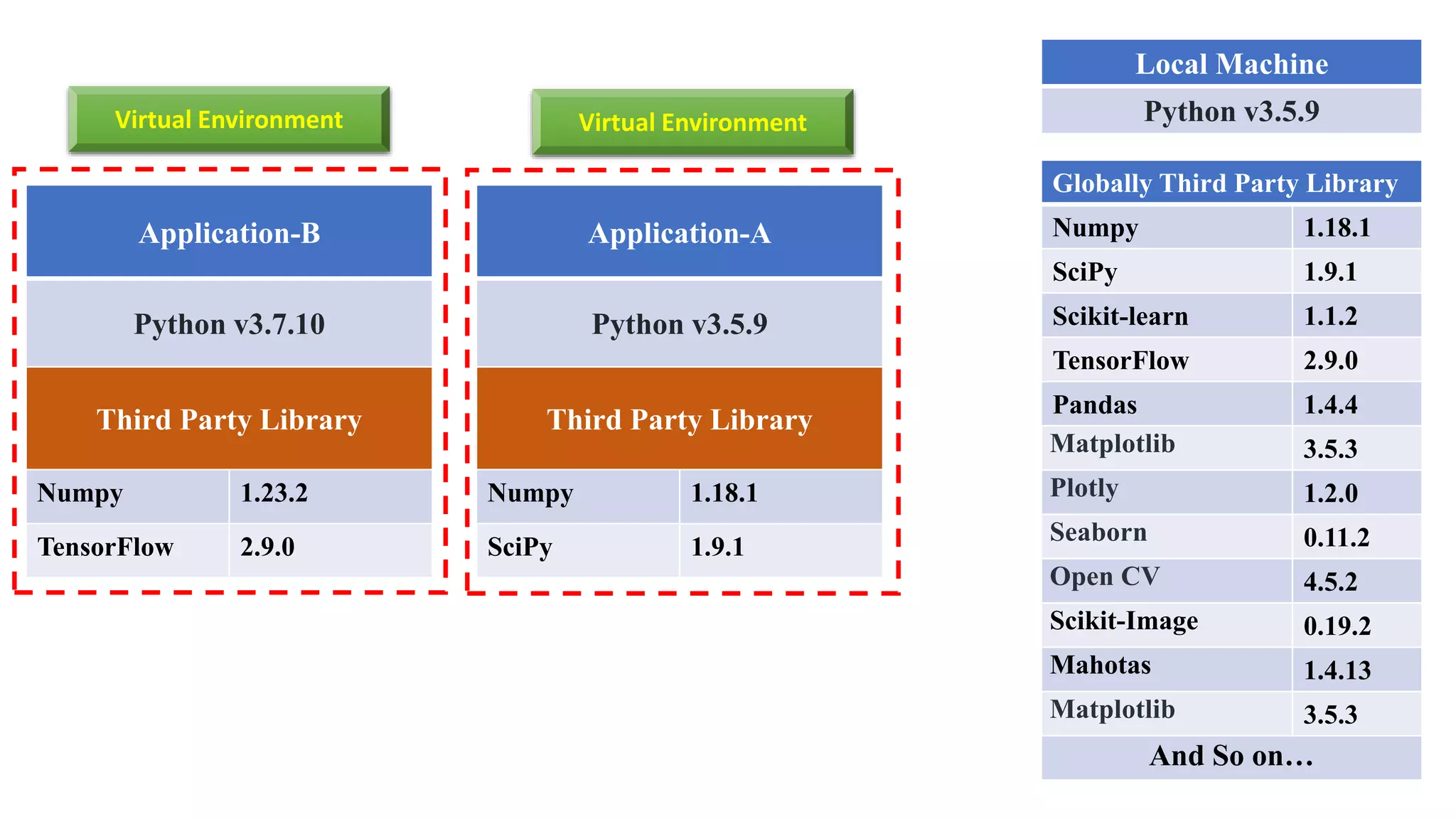


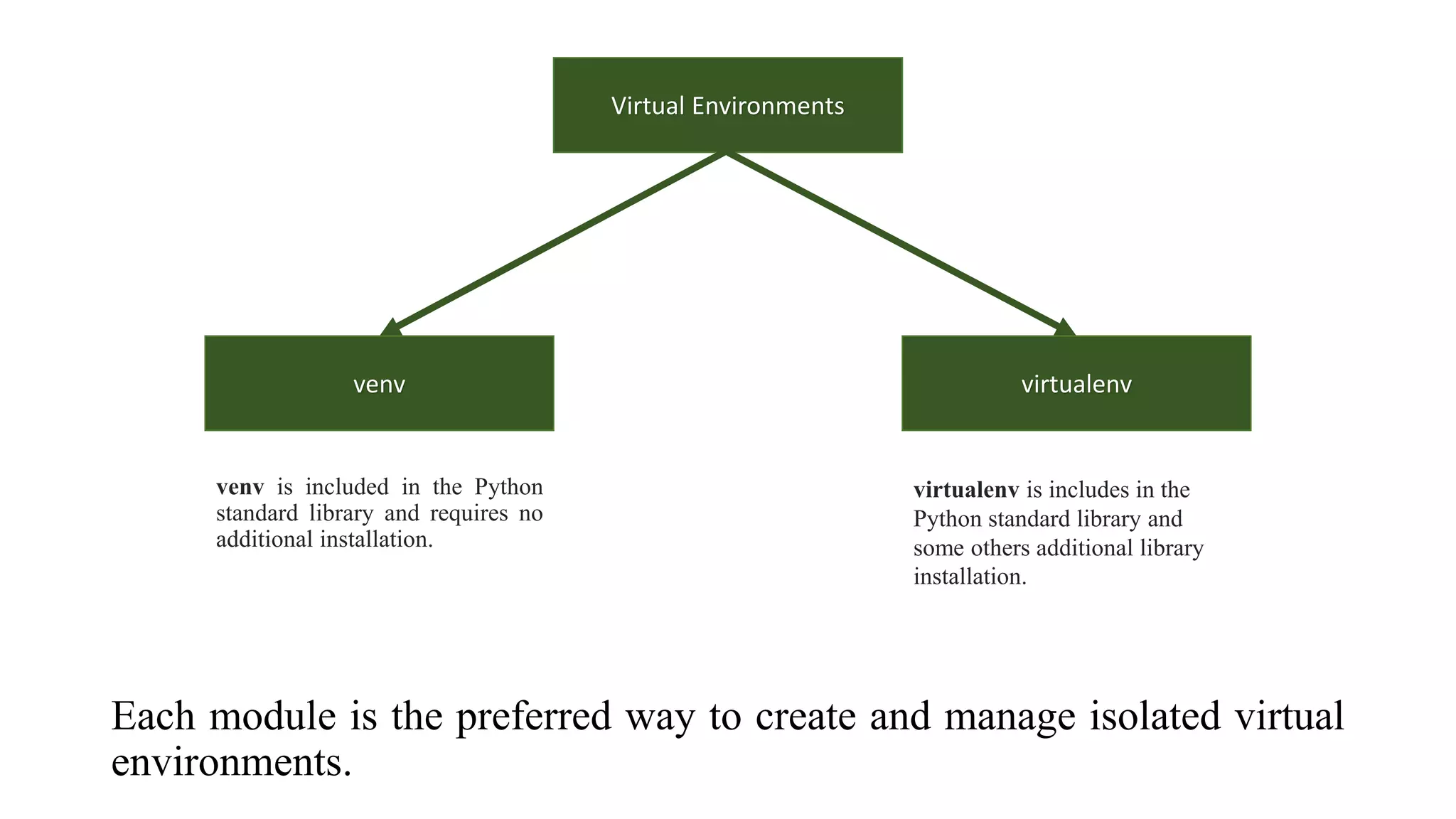

The document outlines various Python libraries and their versions used in different applications, such as numpy, scipy, and tensorflow, across multiple Python environments. It also describes the concept of virtual environments, emphasizing their role in isolating Python development projects to ensure reproducibility and control over dependencies. Additionally, it mentions 'venv' and 'virtualenv' as preferred tools for managing isolated virtual environments.