Downloaded 119 times

![Introduction:
Optical character recognition (optical character reader, OCR) is
the mechanical or electronic conversion of images of typed, handwritten or
printed text into machine-encoded text, whether from a scanned document, a
photo of a document, a scene-photo (for example the text on signs and
billboards in a landscape photo) or from subtitle text superimposed on an image
(for example from a television broadcast). It is widely used as a form of data
entry from printed paper data records, whether passport documents, invoices,
bank statements, computerised receipts, business cards, mail, printouts of static-
data, or any suitable documentation. It is a common method of digitising printed
texts so that they can be electronically edited, searched, stored more compactly,
displayed on-line, and used in machine processes such as cognitive
computing, machine translation, (extracted) text-to-speech, key data and text
mining. OCR is a field of research in pattern recognition, artificial
intelligence and computer vision.
Early versions needed to be trained with images of each character, and worked
on one font at a time. Advanced systems capable of producing a high degree of
recognition accuracy for most fonts are now common, and with support for a
variety of digital image file format inputs.[2] Some systems are capable of
reproducing formatted output that closely approximates the original page
including images, columns, and other non-textual components.
Description:
Optical Character Recognition software does is optically recognize and
represent each character in a scanned document, or, in other words, it translates
an image of each character in a scanned document into an electronically
designated character.
Character recognition process is very complex and requires that the OCR
program matches each image letter to an electronic version that corresponds to
it. The program has to recognize the font that is used in order to be able to
recreate the document. In many cases the scanned copies of a document are of
low quality, blurred, with unrecognizable characters, especially if the original
paper copy was of poor quality, crumpled, faded, etc. In these cases it is really
difficult for the OCR software to perform accurately and that’s when errors
occur.
Until now they haven’t invented a completely error-free OCR software.
However, advancements are continually made in this direction. Today we have](https://image.slidesharecdn.com/opticalcharacterrecognition-160828105246/75/Optical-character-recognition-IEEE-Paper-Study-2-2048.jpg)

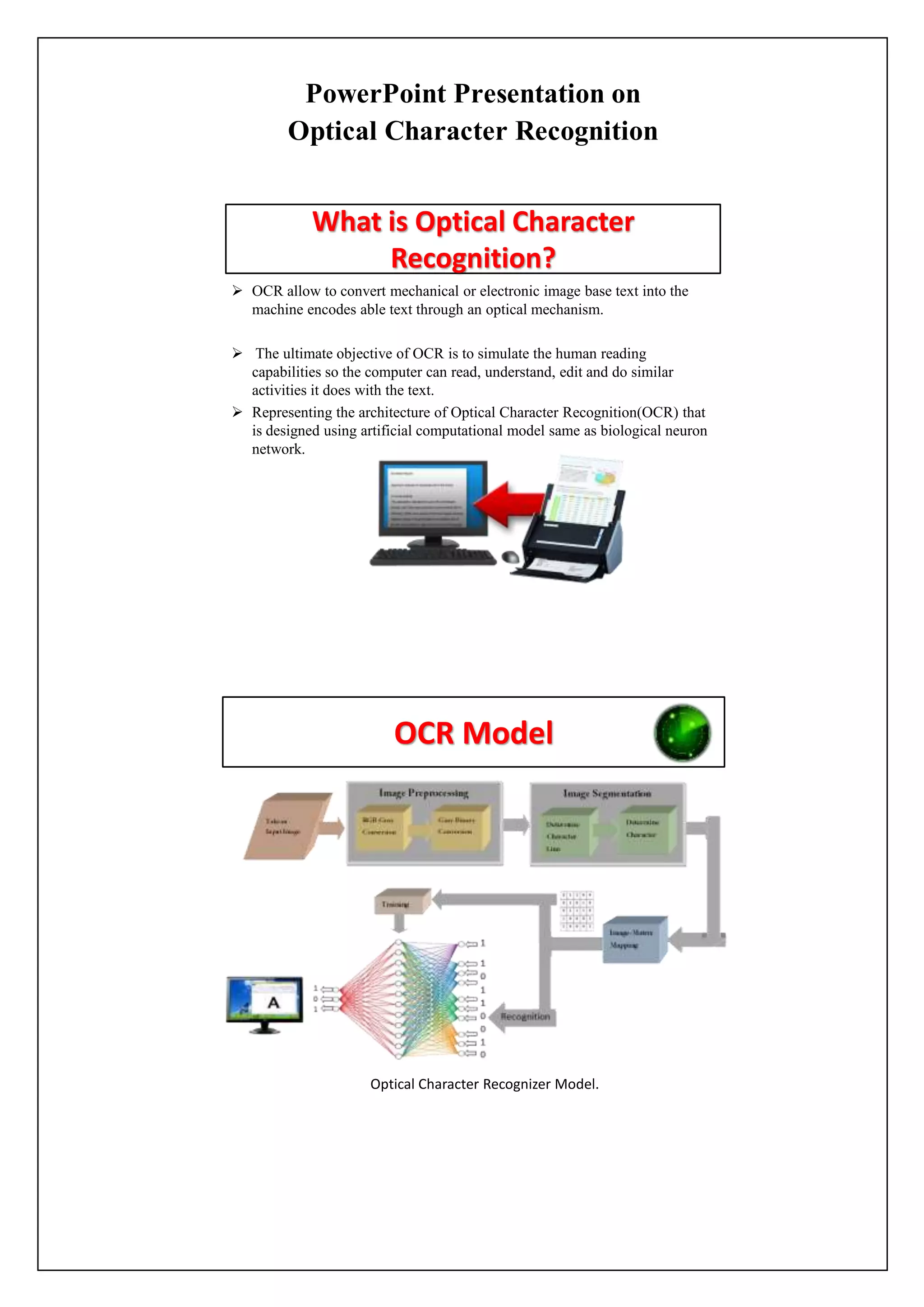





Optical character recognition (OCR) is a technology that converts images of typed, handwritten or printed text into machine-encoded text. The document describes the OCR process which includes image pre-processing, segmentation, feature extraction and recognition using a multi-layer perceptron neural network. It discusses advantages such as increased efficiency and ability to instantly search text. Disadvantages include issues with low quality documents. Applications include data entry for business documents and making printed documents searchable.










![Text reader [OCR]](https://cdn.slidesharecdn.com/ss_thumbnails/textreaderocr-191031162423-thumbnail.jpg?width=640&height=640&fit=bounds)















































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)










![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)