Downloaded 142 times


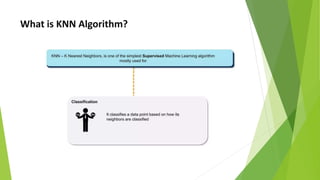

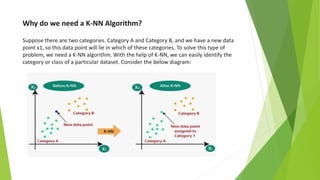


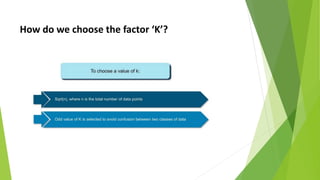
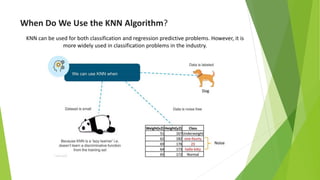


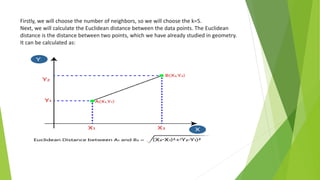
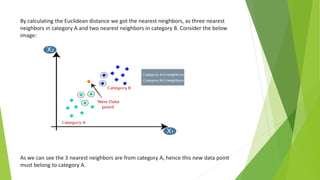


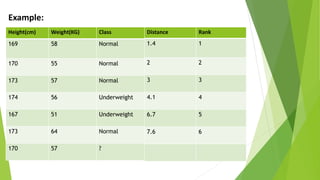






The k-nearest neighbors (k-NN) algorithm is a non-parametric, lazy learner method used for classification and regression by categorizing a new data point based on its similarity to existing data points. Choosing the correct value of 'k' is crucial for accuracy, and the algorithm operates by calculating the Euclidean distance between points to determine the nearest neighbors. Applications of k-NN include banking for loan approval predictions and calculating credit ratings.




























![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

