Downloaded 131 times



![References
[1]www.scientificamerican.com/article/pavement-pounders-at-paris-marathon-generate-power/
[2] COMPARISON OF DIFFERENT BEAM SHAPES FOR PIEZOELECTRIC VIBRATION ENERGY HARVESTING [Maxime Defosseux1*,
Marjolaine Allain, Skandar Basrour, TIMA, UJF-CNRS-Grenoble INP, Grenoble, France]
[3]www.dailymail.co.uk/sciencetech/article-1027362/Britains-eco-nightclub-powered-pounding-feet-opens-doors.html
[4] Pataky TC, Bosch K, Mu T, Keijsers NLW, Segers V, Rosenbaum D, Goulermas JY (2011). An anatomically unbiased foot template for inter-
subject plantar pressure evaluation. Gait and Posture 33(3): 418-422.
[5] Kiran Boby, Aleena Paul K, Anumol.C.V, Josnie Ann Thomas, Nimisha K.K
“Footstep Power Generation Using Piezo Electric Transducers” International Journal of Engineering and Innovative Technology (IJEIT) Volume 3,
Issue 10, April 2014
[6] Landt, Jerry. "Shrouds of Time: The history of RFID," AIM, Inc., 31 May 2006
[7] National Instruments Vision Assistant Manual
[8] D. Klatt, “Review of Text-to-Speech Conversion for English,” Journal of the Acoustical Society of America, JASA vol. 82 (3), pp.737-793, 1987.
[9] ] E. Nunes; E. Abreu; J.C. Metrolho; N. Cardoso; M. Costa; E. Lopes, "Flour quality control using image processing," Industrial Electronics,
2003. ISIE '03. 2003 IEEE International Symposium on , vol.1, no., pp. 594-597 vol. 1, 9-11 June 2003
[10] Van Santen, J. (April 1994). "Assignment of segmental duration in text-to-speech synthesis". Computer Speech & Language 8 (2): 95–128.
doi:10.1006/csla.1994.1005.](https://image.slidesharecdn.com/dic-160603172047/75/OCR-speech-using-Labview-14-2048.jpg)


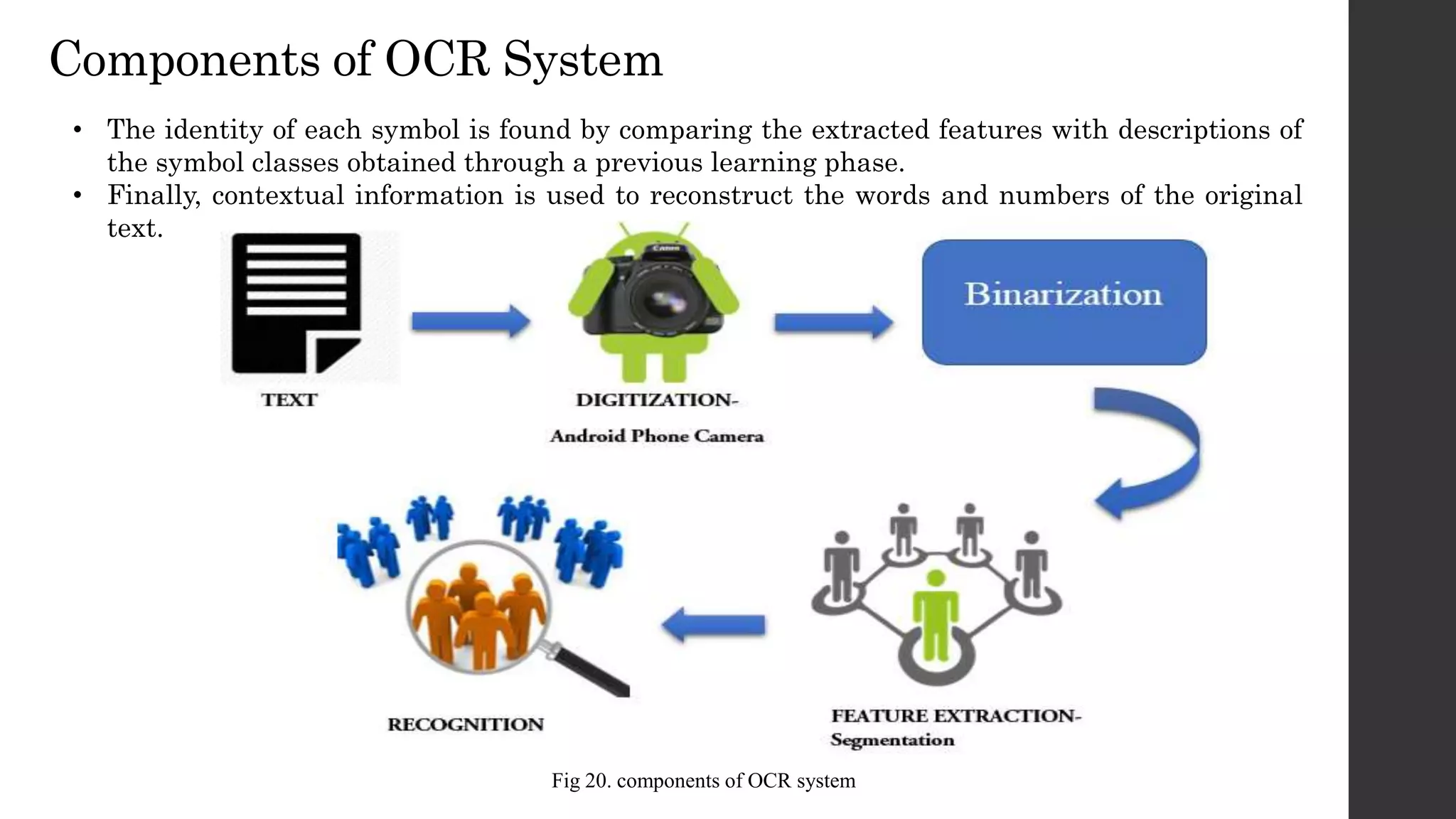
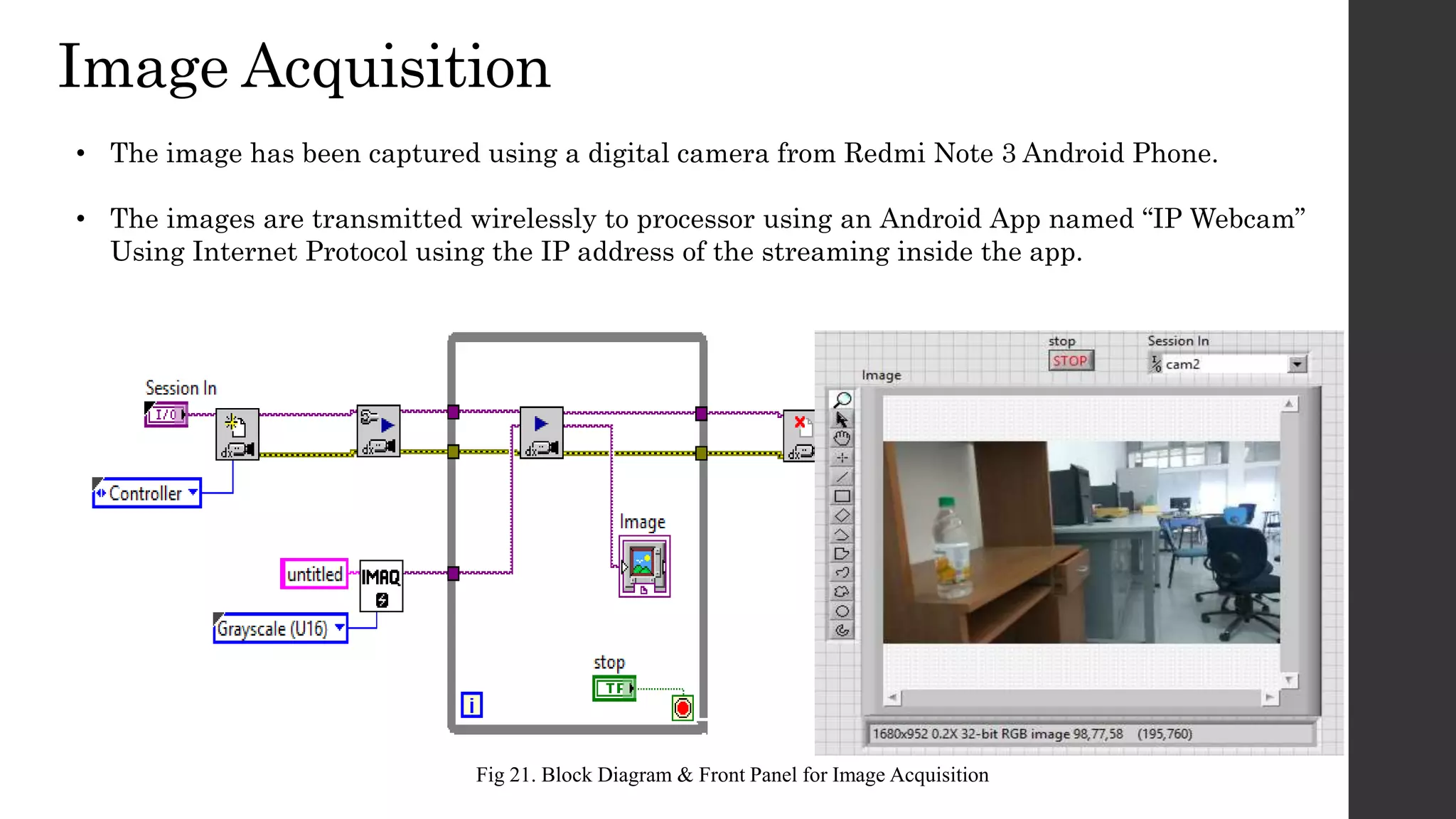
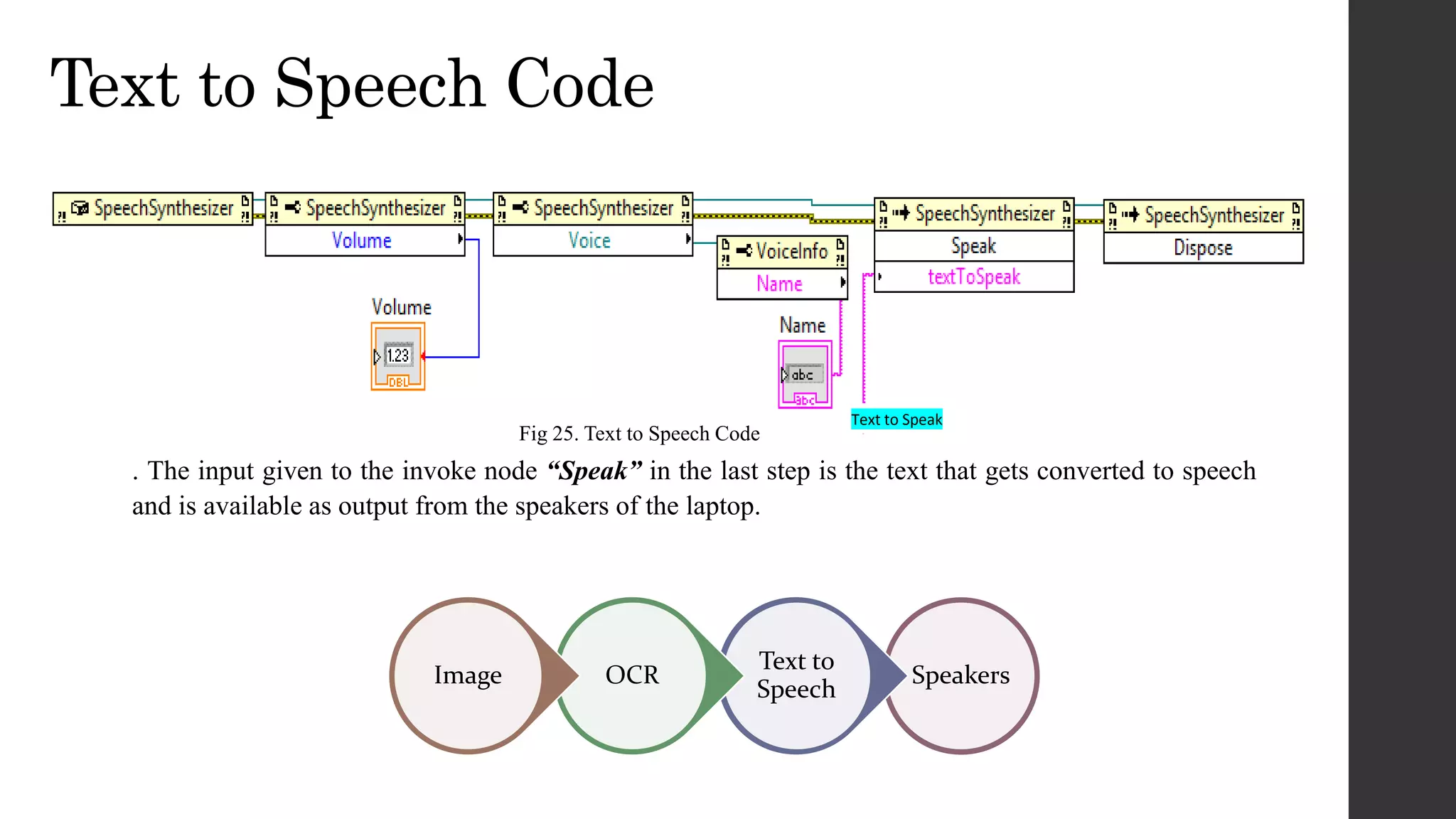
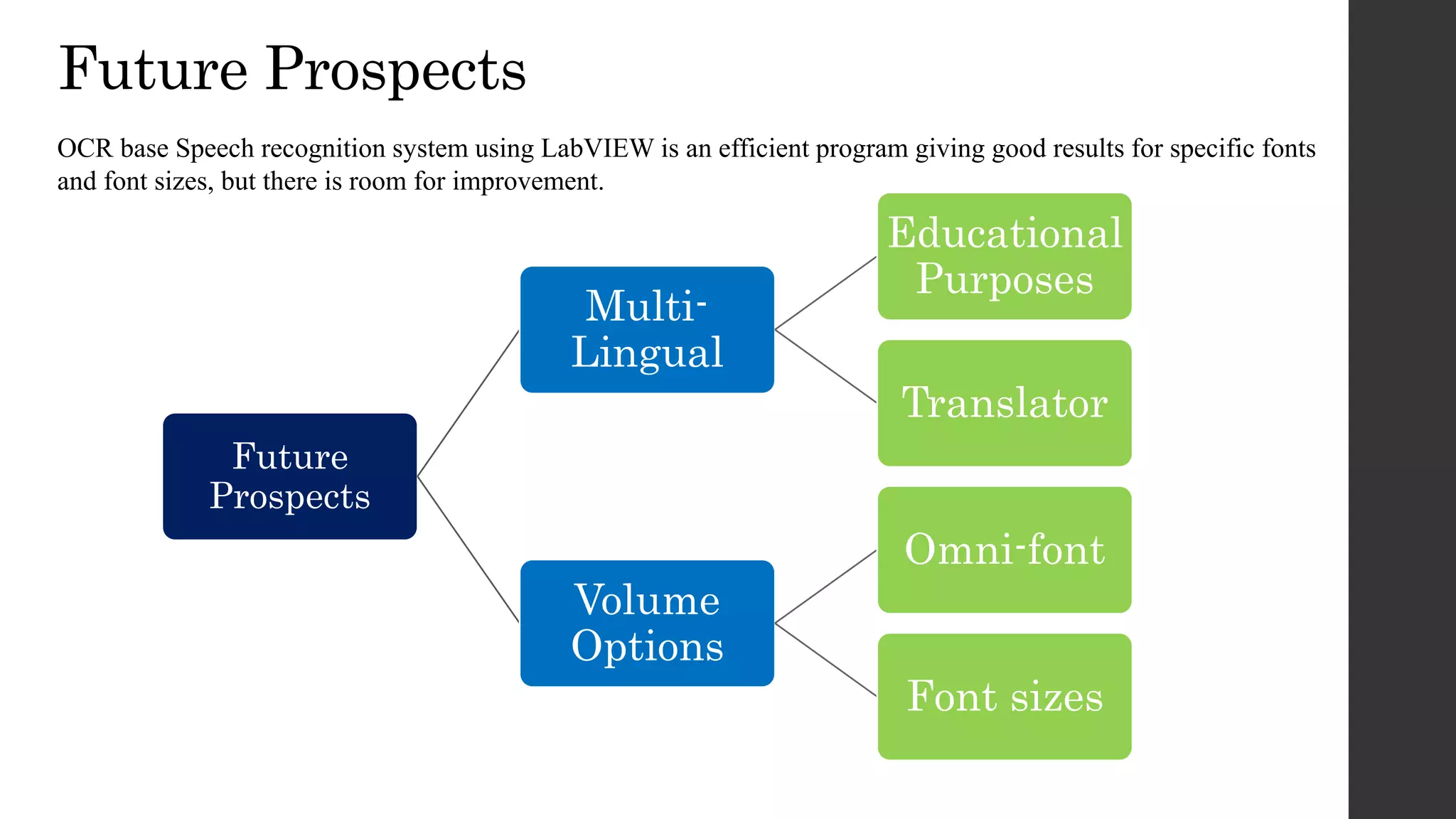
This document discusses an OCR-based speech synthesis system developed using LabVIEW 2013. The system has two main parts: optical character recognition and text-to-speech conversion. It uses a digital camera to capture images, performs preprocessing like binarization, then matches characters to a template for recognition. The recognized text is converted to speech using text-to-speech synthesis for audio output. The system achieves 75-80% accuracy but could be improved with support for more fonts and font sizes.









































































