Downloaded 91 times


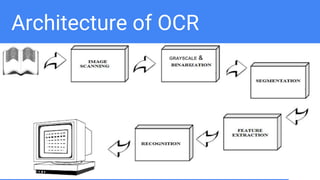


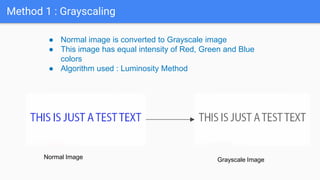


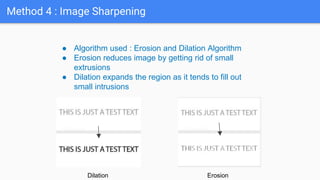



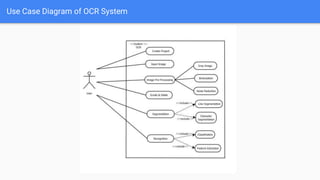
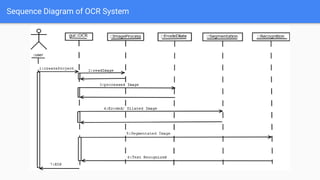
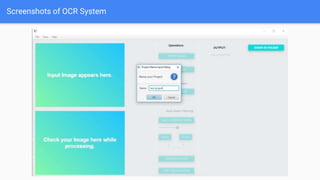
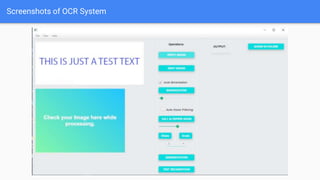
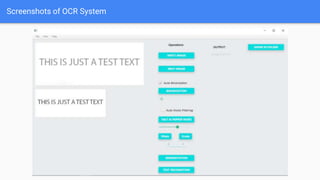




Optical Character Recognition (OCR) is a technology that converts non-digital text into editable formats. It works by recognizing printed or written characters using computer vision techniques. The document describes the architecture and objectives of an OCR system, including converting documents to text, speeding up processing, and embedding in applications. It outlines common OCR methods such as grayscaling, binarization, noise removal, sharpening, segmentation, feature extraction, and recognition to identify characters. Diagrams show the system architecture and workflow. Screenshots demonstrate the developed OCR system in use. The conclusion discusses automatic data entry and future areas like recognizing handwriting.













![Text reader [OCR]](https://cdn.slidesharecdn.com/ss_thumbnails/textreaderocr-191031162423-thumbnail.jpg?width=640&height=640&fit=bounds)





















































