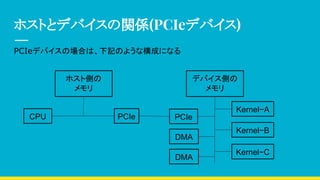
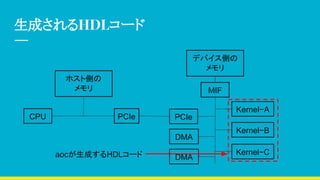
デバイス側のOpenCLコード
const char *kernelSource=
#pragma OPENCL EXTENSION cl_khr_fp64 : enable
_kernel void vecAdd(__global double *a, __global double *b,
__global double *c, const unsigned int n)
{
//Get our global thread ID
int id = get_global_id(0);
//Make sure we do not go out of bounds
if (id < n)
c[id] = a[id] + b[id];
}


![例題:vector addition
https://www.olcf.ornl.gov/tutorials/opencl-vector-addition/
double a[N], b[N], c[N];
vector_add( a, b, c, N );
void vector_add( double* a, double* b, double* c,
const unsigned int n )
{
for( unsigned int i=0 ; i<n ; i++ )
c[i] = a[i] + b[i];
}](https://image.slidesharecdn.com/aocl-160612025507/85/Altera-SDK-for-OpenCL-5-320.jpg)
![デバイス側のOpenCLコード
const char *kernelSource =
#pragma OPENCL EXTENSION cl_khr_fp64 : enable
_kernel void vecAdd(__global double *a, __global double *b,
__global double *c, const unsigned int n)
{
//Get our global thread ID
int id = get_global_id(0);
//Make sure we do not go out of bounds
if (id < n)
c[id] = a[id] + b[id];
}](https://image.slidesharecdn.com/aocl-160612025507/85/Altera-SDK-for-OpenCL-6-320.jpg)






































![[Track4-3] AI・ディープラーニングを駆使して、「G検定合格者アンケートのフリーコメント欄」を分析してみた](https://cdn.slidesharecdn.com/ss_thumbnails/43dllab20200801isid-200807101606-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)




















