More Related Content
![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介 
PDF

PDF
ChatGPT 人間のフィードバックから強化学習した対話AI 
PDF

PPTX

PDF
0から理解するニューラルネットアーキテクチャサーチ(NAS) 
PDF

PDF
What's hot

PDF

PDF
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健 
PPT

PDF
20230105_TITECH_lecture_ishizaki_public.pdf 
PDF

PDF
Android/iOS端末におけるエッジ推論のチューニング 
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2 
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) 
PDF

PDF

PDF

PDF
BlackBox モデルの説明性・解釈性技術の実装 
PDF
perfを使ったPostgreSQLの解析(前編) 
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例 
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に) 
PDF

PDF

PDF
Viewers also liked

PDF

PDF
ディープラーニングフレームワーク とChainerの実装 
PDF

PDF
深層学習フレームワーク Chainer の開発と今後の展開 
PDF
Chainerチュートリアル -v1.5向け- ViEW2015 
PDF
Introduction to DEEPstation the GUI Deep learning environment for chainer Similar to PyOpenCLによるGPGPU入門

KEY
PyOpenCLによるGPGPU入門 Tokyo.SciPy#4 編 
KEY
NVIDIA Japan Seminar 2012 
PDF
PEZY-SC programming overview 
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング 
PDF
C base design methodology with s dx and xilinx ml 
PDF
Introduction to Chainer (LL Ring Recursive) 
PDF
Anaconda & NumbaPro 使ってみた 
PPTX

PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境 
PDF
Altera SDK for OpenCL解体新書 : ホストとデバイスの関係 
KEY

PDF

PDF
Introduction to OpenCL (Japanese, OpenCLの基礎) 
PDF
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境�(OpenCL) 
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10) 
PDF

PDF
1072: アプリケーション開発を加速するCUDAライブラリ 
PDF
Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp 
PDF

DOC
GPGPUによるパーソナルスーパーコンピュータの可能性 More from Yosuke Onoue

PDF

PDF
アニメーション(のためのパフォーマンス)の基礎知識 
PDF
AngularJSでデータビジュアライゼーションがしたい 
PDF
GDG DevFest Kobe Firebaseハンズオン勉強会 
PDF

PDF
asm.jsとWebAssemblyって実際なんなの? 
PDF

PDF
AngularJSとD3.jsによるインタラクティブデータビジュアライゼーション 
PDF

PDF

PDF

KEY
What's New In Python 3.3をざっと眺める 
PPTX

PPTX

PPTX

PPT
PyOpenCLによるGPGPU入門
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
Agenda
1. 概要
2. GPGPUの基礎
3. PyOpenCLによるGPGPU入門
4. PyOpenCLのArray
5. PythonによるOpenCLアプリケーション開発
- 10.
- 11.
- 12.
- 13.
GPUのメモリ階層
SP毎 SM毎 全体
高速 Register Shared Memory Constant Memory
低速 Local Memory Global Memory
- 14.
- 15.
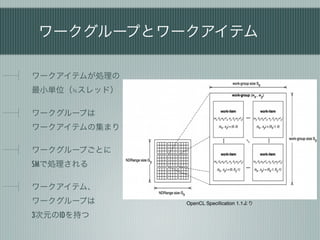
高速なGPU処理のために
データ並列 スレッド間の同期を減
らす
メモリ転送を減らす
条件分岐を減らす
グローバルメモリアク
セスを減らす …
アクセスが高速なメモ
リを使う 処理特性の理解が重要
- 16.
- 17.
- 18.
プラットフォームとデバイス
各社から提供される NVIDIA OpenCL
OpenCLプラットフォームは
GPU 1
1台のマシンに同居可能
GPU 2
各プラットフォームには
1個以上のデバイス Intel OpenCL
実行時にプラットフォームと CPU
デバイスを選択 GPU
- 19.
インストール
1. OpenCL環境のインストール
NVIDIA、AMD、Intel、Apple…
2. 依存ライブラリのインストール
$ easy_install numpy
$ easy_install mako
3. PyOpenCLのインストール
$ easy_install pyopencl
- 20.
OpenCLプログラムの登場人物
Context
Context
CommandQueue Host
デバイスの制御 Command Queue
Buffer GPU上のメモリ
GPU
Kernel GPUで実行されるプログラム Program
Buffer
Program Kernelの集まり Kernel
- 21.
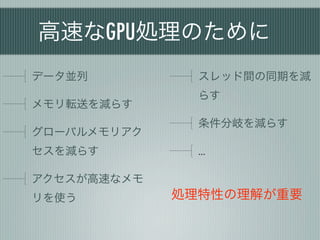
基本手順
1. Context、CommandQueue、
Programの作成
Host GPU
2. GPUのメモリ確保
CPU SM
3. GPUへのデータ転送 PCIe
Memory Memory
4. GPUでの計算
5. GPUからのデータ転送
- 22.
Contextの作成
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
create_some_context() 4
5
import pyopencl as cl
import numpy
実行時にデバイスと 6
7 # Contextの作成
プラットフォームを 8 ctx = cl.create_some_context()
9
選択 10 # CommandQueueの作成
11 queue = cl.CommandQueue(ctx)
[onoue@localhost test]$ python sample.py
Choose device(s):
[0] <pyopencl.Device 'Tesla C2050' on 'NVIDIA CUDA' at 0xfd4000>
[1] <pyopencl.Device 'GeForce GT 240' on 'NVIDIA CUDA' at 0xc85df0>
Choice, comma-separated [0]:0
- 23.
Programの作成
13 # Programの作成
カーネル関数は 14 prg = cl.Program(ctx, """//CL//
15 __kernel void sum(
OpenCL C言語で実装 16 __global const float *a,
17 __global const float *b,
18 __global float *c
Pythonソース内に 19
20
)
{
21 int gid = get_global_id(0);
カーネル関数を 22 c[gid] = a[gid] + b[gid];
23 }
文字列で埋め込む 24 """).build()
- 24.
デバイス側メモリの確保
ホストとデバイス 26 #ホスト側メモリ確保
それぞれでメモリ
27 a = numpy.random.rand(50000).astype(numpy.float32)
28 b = numpy.random.rand(50000).astype(numpy.float32)
29 a_plus_b = numpy.empty_like(a)
30
領域を確保 31 # デバイス側メモリ確保
32 mf = cl.mem_flags
33 size = a.nbytes
34 a_buf = cl.Buffer(ctx, mf.READ_ONLY, size)
ホスト側には 35
36
b_buf = cl.Buffer(ctx, mf.READ_ONLY, size)
dest_buf = cl.Buffer(ctx, mf.WRITE_ONLY, size)
numpy.ndarrayを使用
- 25.
メモリ転送とカーネル呼び出し
ホストのメモリはデバイスから直接操作不可
デバイスのメモリはホストから直接操作不可
カーネル関数呼び出し時に
ワークアイテム、ワークグループのサイズを指定
38 #デバイスへのメモリ転送
39 cl.enqueue_copy(queue, a_buf, a)
40 cl.enqueue_copy(queue, b_buf, b)
41
42 # カーネル呼び出し
43 prg.sum(queue, a.shape, None, a_buf, b_buf, dest_buf)
44
45 # デバイスからのメモリ転送
46 cl.enqueue_copy(queue, a_plus_b, dest_buf)
- 26.
- 27.
- 28.
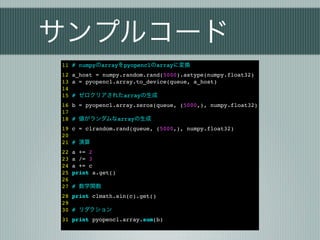
サンプルコード
11 # numpyのarrayをpyopenclのarrayに変換
12a_host = numpy.random.rand(5000).astype(numpy.float32)
13 a = pyopencl.array.to_device(queue, a_host)
14
15 # ゼロクリアされたarrayの生成
16 b = pyopencl.array.zeros(queue, (5000,), numpy.float32)
17
18 # 値がランダムなarrayの生成
19 c = clrandom.rand(queue, (5000,), numpy.float32)
20
21 # 演算
22 a += 2
23 a /= 3
24 a += c
25 print a.get()
26
27 # 数学関数
28 print clmath.sin(c).get()
29
30 # リダクション
31 print pyopencl.array.sum(b)
- 29.
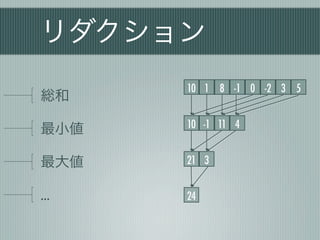
リダクション
10 1 8 -1 0 -2 3 5
総和
10 -1 11 4
最小値
最大値 21 3
… 24
- 30.
- 31.
カスタムリダクション
チューニングされたカーネルを必要な部分
の実装のみで利用可能
9 sum_square_expr = '+'.join('x{0}[i] * x{0}[i]'.format(i) for i in range(n))
10 arguments = ', '.join('__global float* x{0}'.format(i) for i in range(n))
11 kernel = ReductionKernel(
12 context,
13 numpy.int32,
14 neutral='0',
15 reduce_expr='a + b',
16 map_expr='({0} <= 1.f) ? 1 : 0'.format(sum_square_expr),
17 arguments=arguments)
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.



















![Contextの作成
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
create_some_context() 4
5
import pyopencl as cl
import numpy
実行時にデバイスと 6
7 # Contextの作成
プラットフォームを 8 ctx = cl.create_some_context()
9
選択 10 # CommandQueueの作成
11 queue = cl.CommandQueue(ctx)
[onoue@localhost test]$ python sample.py
Choose device(s):
[0] <pyopencl.Device 'Tesla C2050' on 'NVIDIA CUDA' at 0xfd4000>
[1] <pyopencl.Device 'GeForce GT 240' on 'NVIDIA CUDA' at 0xc85df0>
Choice, comma-separated [0]:0](https://image.slidesharecdn.com/gpgpu201205python-120526014831-phpapp01/85/PyOpenCL-GPGPU-22-320.jpg)
![Programの作成
13 # Programの作成
カーネル関数は 14 prg = cl.Program(ctx, """//CL//
15 __kernel void sum(
OpenCL C言語で実装 16 __global const float *a,
17 __global const float *b,
18 __global float *c
Pythonソース内に 19
20
)
{
21 int gid = get_global_id(0);
カーネル関数を 22 c[gid] = a[gid] + b[gid];
23 }
文字列で埋め込む 24 """).build()](https://image.slidesharecdn.com/gpgpu201205python-120526014831-phpapp01/85/PyOpenCL-GPGPU-23-320.jpg)





![カスタムリダクション
チューニングされたカーネルを必要な部分
の実装のみで利用可能
9 sum_square_expr = '+'.join('x{0}[i] * x{0}[i]'.format(i) for i in range(n))
10 arguments = ', '.join('__global float* x{0}'.format(i) for i in range(n))
11 kernel = ReductionKernel(
12 context,
13 numpy.int32,
14 neutral='0',
15 reduce_expr='a + b',
16 map_expr='({0} <= 1.f) ? 1 : 0'.format(sum_square_expr),
17 arguments=arguments)](https://image.slidesharecdn.com/gpgpu201205python-120526014831-phpapp01/85/PyOpenCL-GPGPU-31-320.jpg)







![参考資料
CUDA プログラミング入門(白山工業 森野編)
http://www.youtube.com/user/NVIDIAJapan
はじめてのCUDAプログラミング
ー脅威の開発環境[GPU+CUDA]を使いこなす!
http://www.amazon.co.jp/dp/4777514773
PyCUDAの紹介 - PythonとAWSですぐ始めるGPUコンピューティング
http://www.slideshare.net/likr/pycuda](https://image.slidesharecdn.com/gpgpu201205python-120526014831-phpapp01/85/PyOpenCL-GPGPU-39-320.jpg)

