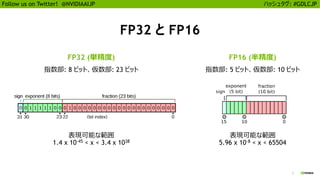
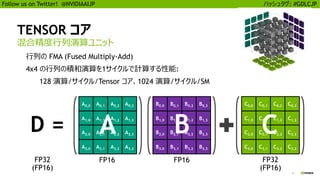
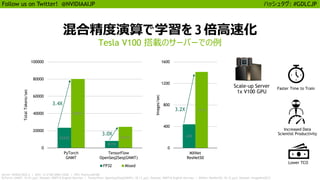
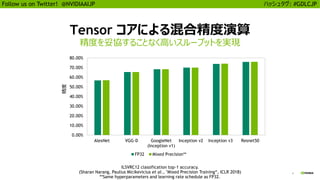
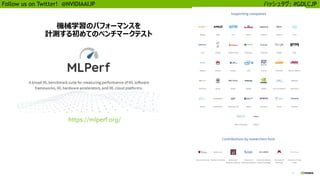
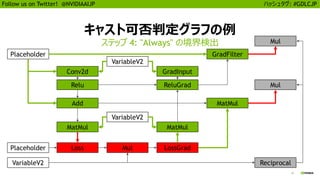
25
Follow us onTwitter! @NVIDIAAIJP ハッシュタグ: #GDLCJP
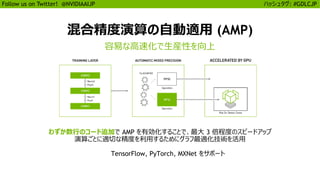
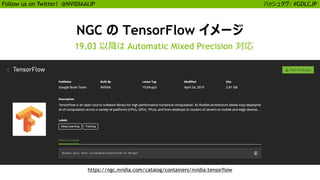
自動混合精度演算の有効化
わずか数行の追加で最大 3 倍の高速化
More details: https://developer.nvidia.com/automatic-mixed-precision
TensorFlow
PyTorch
MXNet
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
amp.init()
amp.init_trainer(trainer)
with amp.scale_loss(loss, trainer) as scaled_loss:
autograd.backward(scaled_loss)
model, optimizer = amp.initialize(model, optimizer)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
OR
export TF_ENABLE_AUTO_MIXED_PRECISION=1
GA Available Since Q2 2018
GA Coming Soon
GA GTC 19







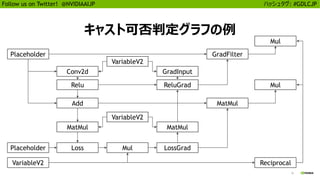
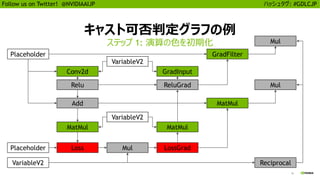
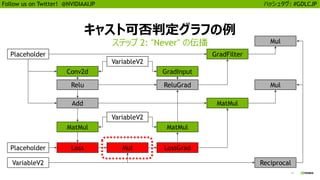
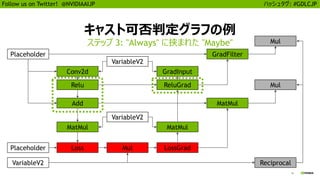




![25
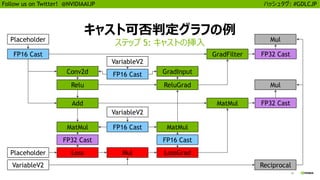
Follow us on Twitter! @NVIDIAAIJP ハッシュタグ: #GDLCJP
自動混合精度演算の有効化
わずか数行の追加で最大 3 倍の高速化
More details: https://developer.nvidia.com/automatic-mixed-precision
TensorFlow
PyTorch
MXNet
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
amp.init()
amp.init_trainer(trainer)
with amp.scale_loss(loss, trainer) as scaled_loss:
autograd.backward(scaled_loss)
model, optimizer = amp.initialize(model, optimizer)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
OR
export TF_ENABLE_AUTO_MIXED_PRECISION=1
GA Available Since Q2 2018
GA Coming Soon
GA GTC 19](https://image.slidesharecdn.com/20190516gdlcjp-11nvidiaksasaki-190517054630/85/Automatic-Mixed-Precision-25-320.jpg)



![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)





































