More Related Content

PPTX

PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか) 
PDF

PPTX

PDF

PDF

PDF
サイバーエージェントにおけるMLOpsに関する取り組み at PyDataTokyo 23 
PDF
What's hot

KEY

PDF

KEY

PDF

PDF
「FPGA 開発入門:FPGA を用いたエッジ AI の高速化手法を学ぶ」 
PDF

PDF
Cloud TPU Driver API ソースコード解析 
PDF

PDF
Cuda fortranの利便性を高めるfortran言語の機能 
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング 
PPTX

PDF

PDF

PDF
Synthesijer fpgax 20150201 
PDF

PDF

PDF
1072: アプリケーション開発を加速するCUDAライブラリ 
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10) 
PDF

PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ) Similar to C base design methodology with s dx and xilinx ml

PDF
PEZY-SC programming overview 
PDF
Altera SDK for OpenCL解体新書 : ホストとデバイスの関係 
KEY
NVIDIA Japan Seminar 2012 
PDF
Introduction to OpenCL (Japanese, OpenCLの基礎) 
PDF
Maxwell と Java CUDAプログラミング 
PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境 
PDF

KEY
PyOpenCLによるGPGPU入門 Tokyo.SciPy#4 編 
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究 ![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理 
PDF

PPTX
もしも… Javaでヘテロジニアスコアが使えたら… 
PPTX
GPU-FPGA協調プログラミングを実現するコンパイラの開発 
PDF

PPTX

PDF

PDF

PDF

PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説 
PPTX
研究者のための Python による FPGA 入門 C base design methodology with s dx and xilinx ml
- 1.
© Copyright 2018Xilinx
Tools and Methodology Applications
Seiichi Kuroda
2018/8/25
SDxを用いたCベース設計、および
Xilinxの機械学習への取組みのご紹介
- 2.
© Copyright 2018Xilinx
本日の内容
˃FPGAを含むヘテロジニアス・デバイス
˃HW/SWランタイム実装ツール SDx
˃プログラミングモデルと設計フロー
˃汎用ライブラリの活用とスクラッチ設計
˃ディープラーニング推論モデルの実装
>> 2
- 3.
© Copyright 2018Xilinx
>> 3
CPUからヘテロジニアス・デバイスへの流れ
2007
OpenMP
(v1.0)
1997
CUDA
(v1.0)
1995
Pthread
(POSIX 1003.1c-1995)
2008
OpenCL
(v1.0)
2017
SDAccel
正式リリース
2015
SDSoC
正式リリース
ACAP
ACAP
Adaptive
Compute
Acceleration
Platform
• ヘテロジニアス化でムーア則の
限界を乗り越える.
• FPGAを含むことによる実装
ギャップはSDxが埋める.
次期ヘテロジニアス デバイス
- 4.
© Copyright 2018Xilinx
本日の内容
˃FPGAを含むヘテロジニアス・デバイス
˃HW/SWランタイム実装ツール SDx
˃プログラミングモデルと設計フロー
˃汎用ライブラリの活用とスクラッチ設計
˃ディープラーニング推論モデルの実装
>> 4
- 5.
© Copyright 2018Xilinx
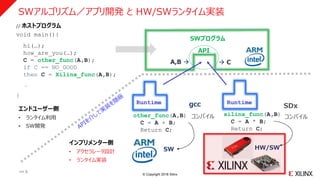
SWアルゴリズム/アプリ開発 と HW/SWランタイム実装
// ホストプログラム
void main(){
hi(…);
how_are_you(…);
C = other_func(A,B);
if C == NO_GOOD
then C = Xilinx_func(A,B);
…
}
SWプログラム
A,B C
API
Runtime
other_func(A,B)
C = A + B;
Return C;
SW
コンパイル
gcc
xilinx_func(A,B)
C = A * B;
Return C;
HW/SW
Runtime
SDx
コンパイル
エンドユーザー側
• ランタイム利用
• SW開発
インプリメンター側
• アクセラレータ設計
• ランタイム実装
>> 5
- 6.
© Copyright 2018Xilinx
>> 6
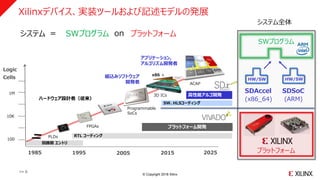
ハードウェア設計者(従来)
組込みソフトウェア
開発者
PLDs
1985 1995 20152005 2025
Logic
Cells
100
1M
10K
FPGAs
Programmable
SoCs
回路図 エントリ
RTL コーディング
高性能アルゴ開発
プラットフォーム開発
アプリケーション,
アルゴリズム開発者
3D ICs
x86 +
ACAP
SDAccel SDSoC
(x86_64) (ARM)
システム = SWプログ onシステム SWプログラム プラットフォーム
HW/SW HW/SW
>> 6
システム全体
プラットフォーム
SWプログラム
Xilinxデバイス、実装ツールおよび記述モデルの発展
SW、HLSコーディング
- 7.
© Copyright 2018Xilinx
>> 7
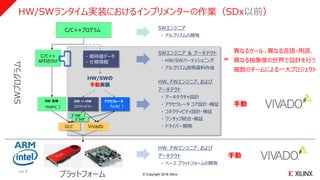
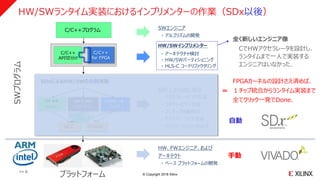
HW/SWランタイム実装におけるインプリメンターの作業(SDx以前)
HW、FWエンジニア、および
アーキテクト
・ ベース プラットフォームの開発
SWエンジニア
・ アルゴリズムの開発
手動
SW ⇔ HW
コネクティビティ
Vivado
アクセラレータ
funk( )
ドライバ
ドライバ
HW、FWエンジニア、および
アーキテクト
・ アーキテクチャ設計
・ アクセラレータ コア設計・検証
・ コネクティビティ設計・検証
・ ワンチップ統合・検証
・ ドライバー開発
HW/SWの
手動実装
・ 期待値データ
・ 仕様情報
SWエンジニア & アーキテクト
・ HW/SWパーティショニング
・ アルゴリズム説明資料作成
手動
プラットフォーム
SWプログラム
GCC
SW 全体
main( )
C/C++プログラム
C/C++
API切分け
異なるツール、異なる言語・用語、
異なる抽象度の世界で設計を行う
複数のチームによる一大プロジェクト
=
>> 7
- 8.
© Copyright 2018Xilinx
>> 8
HW/SWランタイム実装におけるインプリメンターの作業(SDx以後)
自動
C/C++
for FPGA
C/C++プログラム
SDxによるHW/SWの自動実装
SW ⇔ HW
コネクティビティ
GCC Vivado
SW 全体
main( )
アクセラレータ
funk( )
SDx / Vivado HLS
・ アクセラレータ コア生成
・ コネクティビティ生成
・ ワンチップ自動統合
・ ドライバー コード生成
・ アプリケーションへのリンク
HW/SWインプリメンター
・ アーキテクチャ検討
・ HW/SWパーティショニング
・ HLS-C コードリファクタリング
全く新しいエンジニア像
CでHWアクセラレータを設計し、
ランタイムまで一人で実装する
エンジニアはいなかった.
C/C++
API切分け
ドライバ
ドライバ
HW、FWエンジニア、および
アーキテクト
・ ベース プラットフォームの開発
手動
プラットフォーム
SWプログラム
SWエンジニア
・ アルゴリズムの開発
FPGAカーネルの設計さえ済めば、
1チップ統合からランタイム実装まで
全てクリック一発でDone.
=
>> 8
- 9.
© Copyright 2018Xilinx
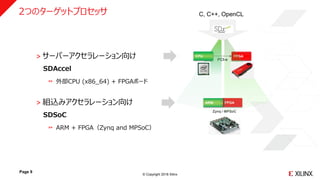
Page 9
˃ サーバーアクセラレーション向け
SDAccel
外部CPU (x86_64) + FPGAボード
˃ 組込みアクセラレーション向け
SDSoC
ARM + FPGA(Zynq and MPSoC)
FPGA
PCI-e
FPGAARM
Zynq / MPSoC
C, C++, OpenCL2つのターゲットプロセッサ
CPU
- 10.
© Copyright 2018Xilinx
本日の内容
˃FPGAを含むヘテロジニアス・デバイス
˃HW/SWランタイム実装ツール SDx
˃プログラミングモデルと設計フロー
˃汎用ライブラリの活用とスクラッチ設計
˃ディープラーニング推論モデルの実装
>> 10
- 11.
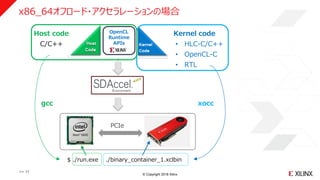
© Copyright 2018Xilinx
Kernel code
• HLC-C/C++
• OpenCL-C
• RTL
PCIe
Host code
C/C++
OpenCL
Runtime
APIs
$ ./run.exe ./binary_container_1.xclbin
gcc xocc
x86_64オフロード・アクセラレーションの場合
>> 11
- 12.
© Copyright 2018Xilinx
マルチノード MPIプログラムからの HW/SW実装例
˃ FPGAとCPUで同じ処理(512x512行列同士の内積)を実行し、解の一致を確認
˃ ノード数は2(Rank0:FPGAカーネル付きノード、Rank1:CPUコアのみのノード)
˃ 今回の分散処理の例では、ノード内並列(FPGA)とノード間並列(CPU)
˃ Intel MPI (compilers_and_libraries_2018.1.163)
˃ VCU1525ボード上のFPGAカーネルを OpenCLデバイスとして実装
DL380 Gen10
AP65 Gen9
Gigabit
vcu1525
Rank0 Rank1
>> 12
DL380 Gen10 and VCU1525
HPE: DL380 Gen10
Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz
HPE: AP6500 XL270d Gen9
Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz
256GB DDR4 2400Mhz
- 13.
© Copyright 2018Xilinx
プログラミングモデル(例題)
>> 13
1. SWアプリケーション
2. HW/SWランタイム
3. FPGAカーネル
- 14.
© Copyright 2018Xilinx
ホストプログラムからはハードウェアの制御を意識しない形でFPGAを活用したい.
#include <mpi.h>
#include “sdxfunc.h”
: :
main(int argc, char *argv[]) {
int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status stat;
<<配列の型定義とメモリーアロケーション>>
<<配列の初期化>>
MPI_Bcast(a_buf, DATA_SIZE, MPI_INT, 0, MPI_COMM_WORLD); //配列 a_buf を各ランクに転送
MPI_Bcast(b_buf, DATA_SIZE, MPI_INT, 0, MPI_COMM_WORLD); //配列 b_buf を各ランクに転送
if (rank == 0) {
xclInit(xclbin); //xclbin のロード
xclMmult(a_buf, b_buf, c_buf_hls); //カーネル実行
xclRelease(); //カーネルの解放
for (i = 1; i < size; i++) {
MPI_Recv(c_buf, DATA_SIZE, MPI_INT, i, i, MPI_COMM_WORLD, &stat); //各rankからの値を受信
}
} else { // その他の rank
cpuMmult(a_buf, b_buf, c_buf); //Rank-0以外のノードのCPUで同様の演算を実行
MPI_Send(c_buf, DATA_SIZE, MPI_INT, 0, rank, MPI_COMM_WORLD); //c_buf をRank-0に転送
}
MPI_Finalize();
}
MPI Host Code
(main.cpp) MPIプログラム
main
• FPGAとCPUで512x512行列同士の内積を実行し、
解の一致を確認した例.
• OpenCLランタイムAPIによるハードウェアの制御は主に
3つのフェーズに分かれる.
1. OpenCLリソースの初期化(xckInit)
2. カーネルによる機能処理(xclMmult)
3. OpenCLリソースの解放(xclRelease)
• ソフトウェアの一部をFPGAカーネルで置換える際には、
ハードウェア制御に関わるOpenCLホストコードをそれら
3つの観点でユーザーAPIに分け(分け方は任意)、
実装を隠蔽してライブラリ化することで、扱い易くなる.
>> 14
xclInit xclMmult xclRelease
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
ハードウェア制御プログラムを
関数に隠蔽してライブラリ化
- 15.
© Copyright 2018Xilinx
プログラミングモデル(例題)
>> 15
1. SWアプリケーション
2. HW/SWランタイム
3. FPGAカーネル
- 16.
© Copyright 2018Xilinx
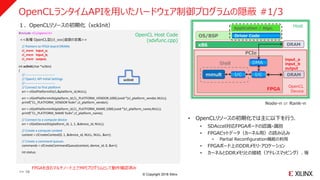
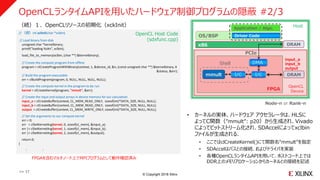
OpenCLランタイムAPIを用いたハードウェア制御プログラムの隠蔽 #1/3
#include <CL/opencl.h>
<<各種 OpenCL型(cl_xxx)変数の定義>>
// Pointers to FPGA board DRAMs
cl_mem input_a;
cl_mem input_b;
cl_mem output;
: :
int xclInit(char *xclbin)
{
//----------------------------
// OpenCL API Initial Settings
//----------------------------
// Connect to first platform
err = clGetPlatformIDs(1,&platform_id,NULL);
err = clGetPlatformInfo(platform_id,CL_PLATFORM_VENDOR,1000,(void *)cl_platform_vendor,NULL);
printf("CL_PLATFORM_VENDOR %s¥n",cl_platform_vendor);
err = clGetPlatformInfo(platform_id,CL_PLATFORM_NAME,1000,(void *)cl_platform_name,NULL);
printf("CL_PLATFORM_NAME %s¥n",cl_platform_name);
// Connect to a compute device
err = clGetDeviceIDs(platform_id, 1, 1, &device_id, NULL);
// Create a compute context
context = clCreateContext(0, 1, &device_id, NULL, NULL, &err);
// Create a command queues
commands = clCreateCommandQueue(context, device_id, 0, &err);
int status;
: :
xclInit
OS/BSP
x86
FPGA
Driver Code
Application / Algo.
DRAM
PCIe
DMA
I/C I/Cmmult
Host
Shell
Node-n or Rank-n
DRAM
OpenCL
Device
OpenCL Host Code
(sdxfunc.cpp)
• OpenCLリソースの初期化では主に以下を行う.
• SDAccel対応FPGAボードの認識・識別
• FPGAビットデータ(カーネル用)の読み込み
• Partial Reconfiguration機能の利用
• FPGAボード上のDDRメモリ・アロケーション
• カーネルとDDRメモリとの接続(アドレスマッピング)、等
1.OpenCLリソースの初期化(xckInit)
input_a
input_b
output
>> 16
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
- 17.
© Copyright 2018Xilinx
OpenCLランタイムAPIを用いたハードウェア制御プログラムの隠蔽 #2/3
// (続)int xclInit(char *xclbin)
// Load binary from disk
unsigned char *kernelbinary;
printf("loading %s¥n", xclbin);
load_file_to_memory(xclbin, (char **) &kernelbinary);
// Create the compute program from offline
program = clCreateProgramWithBinary(context, 1, &device_id, &n, (const unsigned char **) &kernelbinary, ¥
&status, &err);
// Build the program executable
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
// Create the compute kernel in the program to be run
kernel = clCreateKernel(program, "mmult", &err);
// Create the input and output arrays in device memory for our calculation
input_a = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int)*DATA_SIZE, NULL, NULL);
input_b = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int)*DATA_SIZE, NULL, NULL);
output = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(int)*DATA_SIZE, NULL, NULL);
// Set the arguments to our compute kernel
err = 0;
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &input_a);
err |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &input_b);
err |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &output);
return 0;
}
: :
OpenCL Host Code
(sdxfunc.cpp)
OS/BSP
x86
FPGA
Driver Code
Application / Algo.
DRAM
PCIe
DMA
I/C I/Cmmult
Host
Shell
Node-n or Rank-n
DRAM
OpenCL
Device
• カーネルの実体、ハードウェア アクセラレータは、HLSに
よってC関数(”mmult”: p20)から生成され、Vivado
によってビットストリーム化され、SDAccelによってxclbin
ファイルが生成される.
• ここではclCreateKernel()にて関数名“mmult”を指定
• SDAccelはバスとの接続、およびドライバを実装
• 各種OpenCLランタイムAPIを用いて、ホストコード上では
DDR上のメモリアロケーションからカーネルとの接続を記述
(続)1.OpenCLリソースの初期化(xckInit)
input_a
input_b
output
>> 17
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
- 18.
© Copyright 2018Xilinx
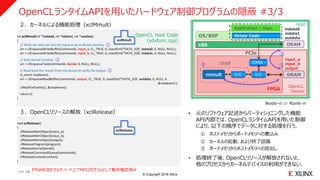
OpenCLランタイムAPIを用いたハードウェア制御プログラムの隠蔽 #3/3
: :
int xclMmult(int *indata0, int *indata1, int *outdata)
{
// Write our data set into the input array in device memory ①
err = clEnqueueWriteBuffer(commands, input_a, CL_TRUE, 0, sizeof(int)*DATA_SIZE, indata0, 0, NULL, NULL);
err = clEnqueueWriteBuffer(commands, input_b, CL_TRUE, 0, sizeof(int)*DATA_SIZE, indata1, 0, NULL, NULL);
// Start Kernel Function ②
err = clEnqueueTask(commands, kernel, 0, NULL, NULL);
// Read back the results from the device to verify the output ③
cl_event readevent;
err = clEnqueueReadBuffer(commands, output, CL_TRUE, 0, sizeof(int)*DATA_SIZE, outdata, 0, NULL, ¥
&readevent );
clWaitForEvents(1, &readevent);
return 0;
}
: :
void xclRelease()
{
clReleaseMemObject(input_a);
clReleaseMemObject(input_b);
clReleaseMemObject(output);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(commands);
clReleaseContext(context);
}
xclMmult
xclRelease
OS/BSP
x86
FPGA
Driver Code
Application / Algo.
DRAM
PCIe
DMA
I/C I/Cmmult
Host
①②
③
Shell
Node-n or Rank-n
DRAM
OpenCL
Device
OpenCL Host Code
(sdxfunc.cpp)
2.カーネルによる機能処理(xclMmult)
3.OpenCLリソースの解放(xclRelease) • 元のソフトウェア記述からパーティショニングした機能
API内部では、OpenCLランタイムAPIを用いた制御
により、以下の順序でデータに対する処理を行う.
① ホストメモリからボードメモリへの書込み
② カーネルの起動、および終了認識
③ ボードメモリからホストメモリへの読出し
• 処理終了後、OpenCLリソースが解放されないと、
他のプロセスからカーネルデバイスの利用ができない.
input_a
input_b
output
indata0
indata1
outdata
>> 18 FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
- 19.
© Copyright 2018Xilinx
プログラミングモデル(例題)
>> 19
1. SWアプリケーション
2. HW/SWランタイム
3. FPGAカーネル
- 20.
© Copyright 2018Xilinx
FPGAカーネルを C で記述(高位合成に入力し、ハードウェアを生成)
void mmult(int *a, int *b, int *c)
{
#pragma HLS INTERFACE m_axi port=a offset=slave bundle=gmem_a
#pragma HLS INTERFACE m_axi port=b offset=slave bundle=gmem_b
#pragma HLS INTERFACE m_axi port=c offset=slave bundle=gmem_c
#pragma HLS INTERFACE s_axilite port=a bundle=control
#pragma HLS INTERFACE s_axilite port=b bundle=control
#pragma HLS INTERFACE s_axilite port=c bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
int bufa[512][512];
int bufb[512][512];
#pragma HLS array_partition variable=bufa block factor=512 dim=2
#pragma HLS array_partition variable=bufb block factor=512 dim=1
for (int row=0;row<512;row++) {
for (int col=0;col<512;col++) {
#pragma HLS PIPELINE
bufa[row][col] = a[512*row + col];
bufb[row][col] = b[512*row + col];
}
}
for (int row=0;row<512;row++) {
for (int col=0;col<512;col++) {
#pragma HLS PIPELINE
int inner_product = 0;
for (int index=0; index<512; index++) {
inner_product += bufa[row][index] * bufb[index][col];
}
c[row*512 + col] = inner_product;
}
}
HLS の対象
(mmult.cpp)
mmult
• 今回FPGAカーネル化の対象:512x512行列の内積.
• 今回はハードウェアアクセラレータをHLS-Cで記述.
• ハードウェア化の時だけ必要(ハードウェア記述言語)
• サポート言語:C/C++、OpenCL-C、RTL
• フラットな記述による単体タスクの例
• プラグマによるマイクロアーキテクチャ設計指示
• 引数:メモリI/F化 および レジスタI/F化
• 配列:Block RAMの分割(並列化のため)
• ループ:インストラクションのパイプライン化
PIPELINE下のループは暗黙的に全並列化
(内積のループが全て並列展開)
• 今回のアーキテクチャ
• Block RAMにマッピングされたローカルの配列に
DDRから行列データをバーストでコピー
• Block RAMを物理的に512枚に分割実装
• 512個の配列データへの並列アクセスが可能に
• 1回の内積に必要な512回の積和ループを展開
• 一回の内積を1cycle/clockのスループットで実現
>> 20
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
- 21.
- 22.
© Copyright 2018Xilinx
mpirun実行ログ
[user1@abc123-1]$ mpirun -np 2 -machinefile hosts -genv I_MPI_DEBUG=2 ./run.exe binary_container_1.xclbin
[0] MPI startup(): Multi-threaded optimized library
[0] DAPL startup: RLIMIT_MEMLOCK too small
[1] DAPL startup: RLIMIT_MEMLOCK too small
[0] MPI startup(): cannot load default tmi provider
[1] MPI startup(): cannot load default tmi provider
[0] MPI startup(): RLIMIT_MEMLOCK too small
[0] MPI startup(): tcp data transfer mode
[1] MPI startup(): tcp data transfer mode
Linux:3.10.0-514.el7.x86_64:#1 SMP Tue Nov 22 16:42:41 UTC 2016:x86_64
Distribution: CentOS Linux release 7.3.1611 (Core)
GLIBC: 2.17
---
XILINX_OPENCL="/opt/dsa/xilinx_vcu1525_dynamic_5_1/xbinst"
LD_LIBRARY_PATH="/opt/dsa/xilinx_vcu1525_dynamic_5_1/xbinst/runtime/lib/x86_64:/opt/intel/compilers_and_libraries_2018.1.163/linux/compiler/lib
/intel64:/opt/intel/compilers_and_libraries_2018.1.163/linux/compiler/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/intel64/li
b:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/mic/lib:/opt/intel/compilers_and_libraries_2018.1.163/linux/ipp/lib/intel64:/opt/intel/compil
ers_and_libraries_2018.1.163/linux/compiler/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/mkl/lib/intel64_lin:/opt/intel/compilers
_and_libraries_2018.1.163/linux/tbb/lib/intel64/gcc4.7:/opt/intel/compilers_and_libraries_2018.1.163/linux/tbb/lib/intel64/gcc4.7:/opt/intel/compilers_
and_libraries_2018.1.163/linux/daal/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/daal/../tbb/lib/intel64_lin/gcc4.4:/opt/intel/com
pilers_and_libraries_2018.1.163/linux/mpi/intel64/lib:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/mic/lib"
---
CL_PLATFORM_VENDOR Xilinx
CL_PLATFORM_NAME Xilinx
loading binary_container_1.xclbin
FPGA Time is 7.006104 [ms]
CPU Time is 1047.626972 [ms] CPUについては実装を最適化していないため、あくまで参考値として掲載
VCU1525ボードによる処理
>> 22
- 23.
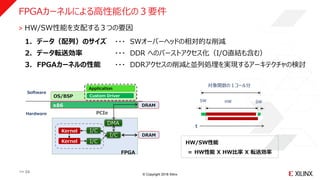
- 24.
© Copyright 2018Xilinx
PS
Software
Hardware
OS/BSP
x86
FPGA
Custom Driver
Application
˃ HW/SW性能を支配する3つの要因
1. データ(配列)のサイズ ・・・ SWオーバーヘッドの相対的な削減
2. データ転送効率 ・・・ DDR へのバーストアクセス化(I/O直結も含む)
3. FPGAカーネルの性能 ・・・ DDRアクセスの削減と並列処理を実現するアーキテクチャの検討
DRAM
t
SW SWHW
対象関数の1コール分
HW/SW性能
= HW性能 X HW比率 X 転送効率
DRAM
PCIe
DMA
I/C
I/C
I/C
Kernel
Kernel
FPGAカーネルによる高性能化の3要件
>> 24
- 25.
© Copyright 2018Xilinx
データ転送効率最大化の検討 [要件2]
>> 25
˃ 鉄則)引数配列に対するランダムかつ冗長アクセスは、FPGA内にキャッシュした上で行う
2Dフィルタの例
: :
Image Frame (DRAM)
Image Frame (DRAM)
Line Buffers
Sliding Window
(同時・並列参照)
Sliding Window
(逐次参照)
同じピクセル(DRAM) への
ランダムかつ重複なアクセス
DRAMへのアクセスを
逐次でかつ一回で済ます
ランダムRead,Write を
1 cycle/clockで行える
同時・並列に参照
(Register)
RD・WR 同時
1 cycle/clock
(Block RAM)
void func (int src[], int dst[])
DRAM側
Ref
モデル
HLS
モデル
NG) アクセラレータがストール
してしまい意味が無くなる
OK) DRAMには一括バースト
アクセス、アクセラレータは
フル稼働FPGA側
- 26.
© Copyright 2018Xilinx
2つの粒度において並列性を検討 [要件3]
>> 26
検討前(全てSW / 逐次処理)
タスク間の並列化(粗粒度レベル)
タスク内の並列化(細粒度レベル)
A
B
C
A
B
C
A
B
C
A
B
C
(A、B、C はタスク)A ~ B ~ C(べた書き) A ~ B ~ C
汎用
- - - - -
ライブラリ
を利用
特殊
- - - - -
スクラッチ
の取組み
難易度
<
例)OpenCV対応
HLSライブラリ
※ タスク = 配列処理の最小単位
N N + 1
N N + 1
N N + 1
各タスクのハードウェア
アクセラレータ化
@3GHz
@300MHz
- 27.
- 28.
© Copyright 2018Xilinx
アクセラレータ設計の全体像(HLSの例)
>> 28
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
アルゴリズムの
リファレンス記述
・ 機能記述
・ 実装未考慮
・ 各種ライブラリ
・ べた書き、etc.
逐次処理
記述要素
+プラグマ
並列処理
HW/SW
要素
並列処理
HW/SW
要素
並列処理
HW/SW
要素
並列処理
HW/SW
要素
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
プロファイリング
タスク分割
タスク単体
性能検討
限界性能 目標アーキテクチャ
C/C++ HW/SW
C/C++
高位合成
[変換/実装]
[記述]
[解析]
[設計]
実装上のギャップ
[参照]
データ転送
効率の検討
Step 1
Step 2
リファクタリング
HW/SW分割
Step 3
=
HW/SW
SW
Step 1
プロファイリング
限界性能および
アーキテクチャ検討
Step 2
カーネルのコーディング
(アーキテクチャの記述)
Step 3
HLS/SDxツールフロー
- 29.
© Copyright 2018Xilinx
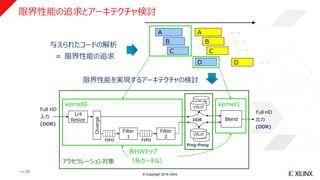
限界性能の追求とアーキテクチャ検討
VBuff
VBuff
Filter
1
Full HD
入力
(DDR)
VBuff
FIFO
Ping-Pong
kernel0 kernel1
Diverge
各HWトップ
(各カーネル)
Blend
アクセラレーション対象
VBuff
FIFO
Filter
2
1/4
Resize
Full HD
出力
(DDR)
DDR
B
C
D
与えられたコードの解析
= 限界性能の追求
限界性能を実現するアーキテクチャの検討
..
..
..
A
B
C
A
D
..
>> 29
- 30.
© Copyright 2018Xilinx
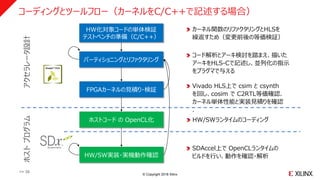
コーディングとツールフロー(カーネルをC/C++で記述する場合)
>> 30
HW化対象コードの単体検証
テストベンチの準備(C/C++)
パーティショニングとリファクタリング
FPGAカーネルの見積り・検証
HW/SW実装・実機動作確認
SDAccel上で OpenCLランタイムの
ビルドを行い、動作を確認・解析
コード解析とアーキ検討を踏まえ、描いた
アーキをHLS-Cで記述し、並列化の指示
をプラグマで与える
カーネル関数のリファクタリングとHLSを
繰返すため(変更前後の等価検証)
ホストコード の OpenCL化 HW/SWランタイムのコーディング
Vivado HLS上で csim と csynth
を回し、cosim で C2RTL等価確認.
カーネル単体性能と実装見積りを確認
.
アクセラレータ設計ホストプログラム
- 31.
© Copyright 2018Xilinx
本日の内容
˃FPGAを含むヘテロジニアス・デバイス
˃HW/SWランタイム実装ツール SDx
˃プログラミングモデルと設計フロー
˃汎用ライブラリの活用とスクラッチ設計
˃ディープラーニング推論モデルの実装
>> 31
- 32.
© Copyright 2018Xilinx
˃ ビット精度、データ型
ap_int, ap_fixed, half, complex, etc.
˃ 初等関数
hls_math.h (math.h)
˃ 線形代数
Inverse (qr, cholesky), svd, etc.
˃ 信号処理
fft, fir, qam_mod/demod, vitabi_decoder, etc.
˃ 画像処理
LineBuffer, Window, 各種 OpenCV, etc.
Page 32
カスタムアクセラレータ化向けの各種HLSライブラリ (UG902)
そもそも、
すべてをスクラッチで設計するのか?
すべてがカスタムアクセラレータなのか?
- 33.
© Copyright 2018Xilinx
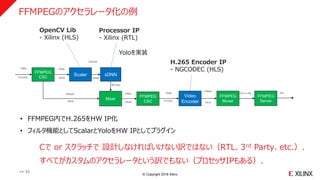
FFMPEGのアクセラレータ化の例
>> 33
Scaler xDNN
Mixer
Video
Encoder
FFMPEG
Muxer
FFMPEG
CSCYUVJ422 0RGB GBRpl
0RGB YUV420
1080p 1080p
224x224
1080p30 1080p
BB Data
FFMPEG
CSC
1080p
0RGB HEVC
8 Mbps
FFMPEG
Server
Ffm on http rtsp
OpenCV Lib
- Xilinx (HLS)
Processor IP
- Xilinx (RTL)
H.265 Encoder IP
- NGCODEC (HLS)
Yoloを実装
• FFMPEG内でH.265をHW IP化
• フィルタ機能としてScalarとYoloをHW IPとしてプラグイン
Cで or スクラッチで 設計しなければいけない訳ではない(RTL、3rd Party、etc.).
すべてがカスタムのアクセラレータという訳でもない(プロセッサIPもある).
- 34.
© Copyright 2018Xilinx
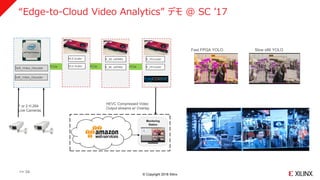
“Edge-to-Cloud Video Analytics” デモ @ SC ’17
>> 34
Soft_Video_Decoder
HEVC Compressed Video
Output streams w/ Overlay
1080p30
Decode
Soft_Video_Decoder
K_ML (xfDNN)
K_ML (xfDNN)
K_VEncoder
K_VEncoder
HLS Scaler
HLS ScalerPCIe
1 or 2 H.264
Live Cameras
Fast FPGA YOLO Slow x86 YOLO
PCIe PCIe
SC17 Demo
- 35.
© Copyright 2018Xilinx
本日の内容
˃FPGAを含むヘテロジニアス・デバイス
˃HW/SWランタイム実装ツール SDx
˃プログラミングモデルと設計フロー
˃汎用ライブラリの活用とスクラッチ設計
˃ディープラーニング推論モデルの実装
>> 35
- 36.
© Copyright 2018Xilinx
ターゲット別のプロセッサIP
>> 36
1. サーバー向け
2. 組込み向け
--- Xilinx製
--- DeePhi製
- 37.
© Copyright 2018Xilinx
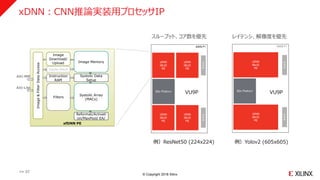
xDNN:CNN推論実装用プロセッサIP
>> 37
スループット、コア数を優先 レイテンシ、解像度を優先
例)ResNet50 (224x224) 例)Yolov2 (605x605)
VU9PVU9P
- 38.
© Copyright 2018Xilinx
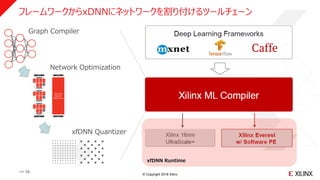
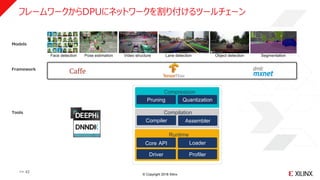
フレームワークからxDNNにネットワークを割り付けるツールチェーン
>> 38
xfDNN Runtime
Graph Compiler
Network Optimization
xfDNN Quantizer
- 39.
© Copyright 2018Xilinx
ターゲット別のプロセッサIP
>> 39
1. サーバー向け
2. 組込み向け
--- Xilinx製
--- DeePhi製
- 40.
© Copyright 2018Xilinx
Xilinx Acquires DeePhi Tech
One of the hottest AI startups in the World
>> 40
- 41.
© Copyright 2018Xilinx
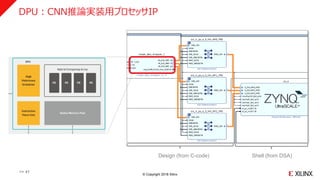
DPU:CNN推論実装用プロセッサIP
>> 41
Shell (from DSA)Design (from C-code)
- 42.
© Copyright 2018Xilinx
フレームワークからDPUにネットワークを割り付けるツールチェーン
>> 42
Core API
Driver
Runtime
Loader
Profiler
Models
Framework
Tools
Compression
Pruning Quantization
Compilation
Compiler Assembler
Face detection Pose estimation Video structure Lane detection Object detection Segmentation
- 43.








![© Copyright 2018 Xilinx
ホストプログラムからはハードウェアの制御を意識しない形でFPGAを活用したい.
#include <mpi.h>
#include “sdxfunc.h”
: :
main(int argc, char *argv[]) {
int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status stat;
<<配列の型定義とメモリーアロケーション>>
<<配列の初期化>>
MPI_Bcast(a_buf, DATA_SIZE, MPI_INT, 0, MPI_COMM_WORLD); //配列 a_buf を各ランクに転送
MPI_Bcast(b_buf, DATA_SIZE, MPI_INT, 0, MPI_COMM_WORLD); //配列 b_buf を各ランクに転送
if (rank == 0) {
xclInit(xclbin); //xclbin のロード
xclMmult(a_buf, b_buf, c_buf_hls); //カーネル実行
xclRelease(); //カーネルの解放
for (i = 1; i < size; i++) {
MPI_Recv(c_buf, DATA_SIZE, MPI_INT, i, i, MPI_COMM_WORLD, &stat); //各rankからの値を受信
}
} else { // その他の rank
cpuMmult(a_buf, b_buf, c_buf); //Rank-0以外のノードのCPUで同様の演算を実行
MPI_Send(c_buf, DATA_SIZE, MPI_INT, 0, rank, MPI_COMM_WORLD); //c_buf をRank-0に転送
}
MPI_Finalize();
}
MPI Host Code
(main.cpp) MPIプログラム
main
• FPGAとCPUで512x512行列同士の内積を実行し、
解の一致を確認した例.
• OpenCLランタイムAPIによるハードウェアの制御は主に
3つのフェーズに分かれる.
1. OpenCLリソースの初期化(xckInit)
2. カーネルによる機能処理(xclMmult)
3. OpenCLリソースの解放(xclRelease)
• ソフトウェアの一部をFPGAカーネルで置換える際には、
ハードウェア制御に関わるOpenCLホストコードをそれら
3つの観点でユーザーAPIに分け(分け方は任意)、
実装を隠蔽してライブラリ化することで、扱い易くなる.
>> 14
xclInit xclMmult xclRelease
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み
ハードウェア制御プログラムを
関数に隠蔽してライブラリ化](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-14-320.jpg)


![© Copyright 2018 Xilinx
FPGAカーネルを C で記述(高位合成に入力し、ハードウェアを生成)
void mmult(int *a, int *b, int *c)
{
#pragma HLS INTERFACE m_axi port=a offset=slave bundle=gmem_a
#pragma HLS INTERFACE m_axi port=b offset=slave bundle=gmem_b
#pragma HLS INTERFACE m_axi port=c offset=slave bundle=gmem_c
#pragma HLS INTERFACE s_axilite port=a bundle=control
#pragma HLS INTERFACE s_axilite port=b bundle=control
#pragma HLS INTERFACE s_axilite port=c bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
int bufa[512][512];
int bufb[512][512];
#pragma HLS array_partition variable=bufa block factor=512 dim=2
#pragma HLS array_partition variable=bufb block factor=512 dim=1
for (int row=0;row<512;row++) {
for (int col=0;col<512;col++) {
#pragma HLS PIPELINE
bufa[row][col] = a[512*row + col];
bufb[row][col] = b[512*row + col];
}
}
for (int row=0;row<512;row++) {
for (int col=0;col<512;col++) {
#pragma HLS PIPELINE
int inner_product = 0;
for (int index=0; index<512; index++) {
inner_product += bufa[row][index] * bufb[index][col];
}
c[row*512 + col] = inner_product;
}
}
HLS の対象
(mmult.cpp)
mmult
• 今回FPGAカーネル化の対象:512x512行列の内積.
• 今回はハードウェアアクセラレータをHLS-Cで記述.
• ハードウェア化の時だけ必要(ハードウェア記述言語)
• サポート言語:C/C++、OpenCL-C、RTL
• フラットな記述による単体タスクの例
• プラグマによるマイクロアーキテクチャ設計指示
• 引数:メモリI/F化 および レジスタI/F化
• 配列:Block RAMの分割(並列化のため)
• ループ:インストラクションのパイプライン化
PIPELINE下のループは暗黙的に全並列化
(内積のループが全て並列展開)
• 今回のアーキテクチャ
• Block RAMにマッピングされたローカルの配列に
DDRから行列データをバーストでコピー
• Block RAMを物理的に512枚に分割実装
• 512個の配列データへの並列アクセスが可能に
• 1回の内積に必要な512回の積和ループを展開
• 一回の内積を1cycle/clockのスループットで実現
>> 20
FPGAを含むマルチノード上でMPIプログラムとして動作確認済み](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-20-320.jpg)

![© Copyright 2018 Xilinx
mpirun実行ログ
[user1@abc123-1]$ mpirun -np 2 -machinefile hosts -genv I_MPI_DEBUG=2 ./run.exe binary_container_1.xclbin
[0] MPI startup(): Multi-threaded optimized library
[0] DAPL startup: RLIMIT_MEMLOCK too small
[1] DAPL startup: RLIMIT_MEMLOCK too small
[0] MPI startup(): cannot load default tmi provider
[1] MPI startup(): cannot load default tmi provider
[0] MPI startup(): RLIMIT_MEMLOCK too small
[0] MPI startup(): tcp data transfer mode
[1] MPI startup(): tcp data transfer mode
Linux:3.10.0-514.el7.x86_64:#1 SMP Tue Nov 22 16:42:41 UTC 2016:x86_64
Distribution: CentOS Linux release 7.3.1611 (Core)
GLIBC: 2.17
---
XILINX_OPENCL="/opt/dsa/xilinx_vcu1525_dynamic_5_1/xbinst"
LD_LIBRARY_PATH="/opt/dsa/xilinx_vcu1525_dynamic_5_1/xbinst/runtime/lib/x86_64:/opt/intel/compilers_and_libraries_2018.1.163/linux/compiler/lib
/intel64:/opt/intel/compilers_and_libraries_2018.1.163/linux/compiler/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/intel64/li
b:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/mic/lib:/opt/intel/compilers_and_libraries_2018.1.163/linux/ipp/lib/intel64:/opt/intel/compil
ers_and_libraries_2018.1.163/linux/compiler/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/mkl/lib/intel64_lin:/opt/intel/compilers
_and_libraries_2018.1.163/linux/tbb/lib/intel64/gcc4.7:/opt/intel/compilers_and_libraries_2018.1.163/linux/tbb/lib/intel64/gcc4.7:/opt/intel/compilers_
and_libraries_2018.1.163/linux/daal/lib/intel64_lin:/opt/intel/compilers_and_libraries_2018.1.163/linux/daal/../tbb/lib/intel64_lin/gcc4.4:/opt/intel/com
pilers_and_libraries_2018.1.163/linux/mpi/intel64/lib:/opt/intel/compilers_and_libraries_2018.1.163/linux/mpi/mic/lib"
---
CL_PLATFORM_VENDOR Xilinx
CL_PLATFORM_NAME Xilinx
loading binary_container_1.xclbin
FPGA Time is 7.006104 [ms]
CPU Time is 1047.626972 [ms] CPUについては実装を最適化していないため、あくまで参考値として掲載
VCU1525ボードによる処理
>> 22](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-22-320.jpg)

![© Copyright 2018 Xilinx
データ転送効率最大化の検討 [要件2]
>> 25
˃ 鉄則)引数配列に対するランダムかつ冗長アクセスは、FPGA内にキャッシュした上で行う
2Dフィルタの例
: :
Image Frame (DRAM)
Image Frame (DRAM)
Line Buffers
Sliding Window
(同時・並列参照)
Sliding Window
(逐次参照)
同じピクセル(DRAM) への
ランダムかつ重複なアクセス
DRAMへのアクセスを
逐次でかつ一回で済ます
ランダムRead,Write を
1 cycle/clockで行える
同時・並列に参照
(Register)
RD・WR 同時
1 cycle/clock
(Block RAM)
void func (int src[], int dst[])
DRAM側
Ref
モデル
HLS
モデル
NG) アクセラレータがストール
してしまい意味が無くなる
OK) DRAMには一括バースト
アクセス、アクセラレータは
フル稼働FPGA側](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-25-320.jpg)
![© Copyright 2018 Xilinx
2つの粒度において並列性を検討 [要件3]
>> 26
検討前(全てSW / 逐次処理)
タスク間の並列化(粗粒度レベル)
タスク内の並列化(細粒度レベル)
A
B
C
A
B
C
A
B
C
A
B
C
(A、B、C はタスク)A ~ B ~ C(べた書き) A ~ B ~ C
汎用
- - - - -
ライブラリ
を利用
特殊
- - - - -
スクラッチ
の取組み
難易度
<
例)OpenCV対応
HLSライブラリ
※ タスク = 配列処理の最小単位
N N + 1
N N + 1
N N + 1
各タスクのハードウェア
アクセラレータ化
@3GHz
@300MHz](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-26-320.jpg)

![© Copyright 2018 Xilinx
アクセラレータ設計の全体像(HLSの例)
>> 28
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
アルゴリズムの
リファレンス記述
・ 機能記述
・ 実装未考慮
・ 各種ライブラリ
・ べた書き、etc.
逐次処理
記述要素
+プラグマ
並列処理
HW/SW
要素
並列処理
HW/SW
要素
並列処理
HW/SW
要素
並列処理
HW/SW
要素
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
逐次処理
記述要素
+プラグマ
プロファイリング
タスク分割
タスク単体
性能検討
限界性能 目標アーキテクチャ
C/C++ HW/SW
C/C++
高位合成
[変換/実装]
[記述]
[解析]
[設計]
実装上のギャップ
[参照]
データ転送
効率の検討
Step 1
Step 2
リファクタリング
HW/SW分割
Step 3
=
HW/SW
SW
Step 1
プロファイリング
限界性能および
アーキテクチャ検討
Step 2
カーネルのコーディング
(アーキテクチャの記述)
Step 3
HLS/SDxツールフロー](https://image.slidesharecdn.com/c-basedesignmethodologywithsdxandxilinxml-181107121756/85/C-base-design-methodology-with-s-dx-and-xilinx-ml-28-320.jpg)