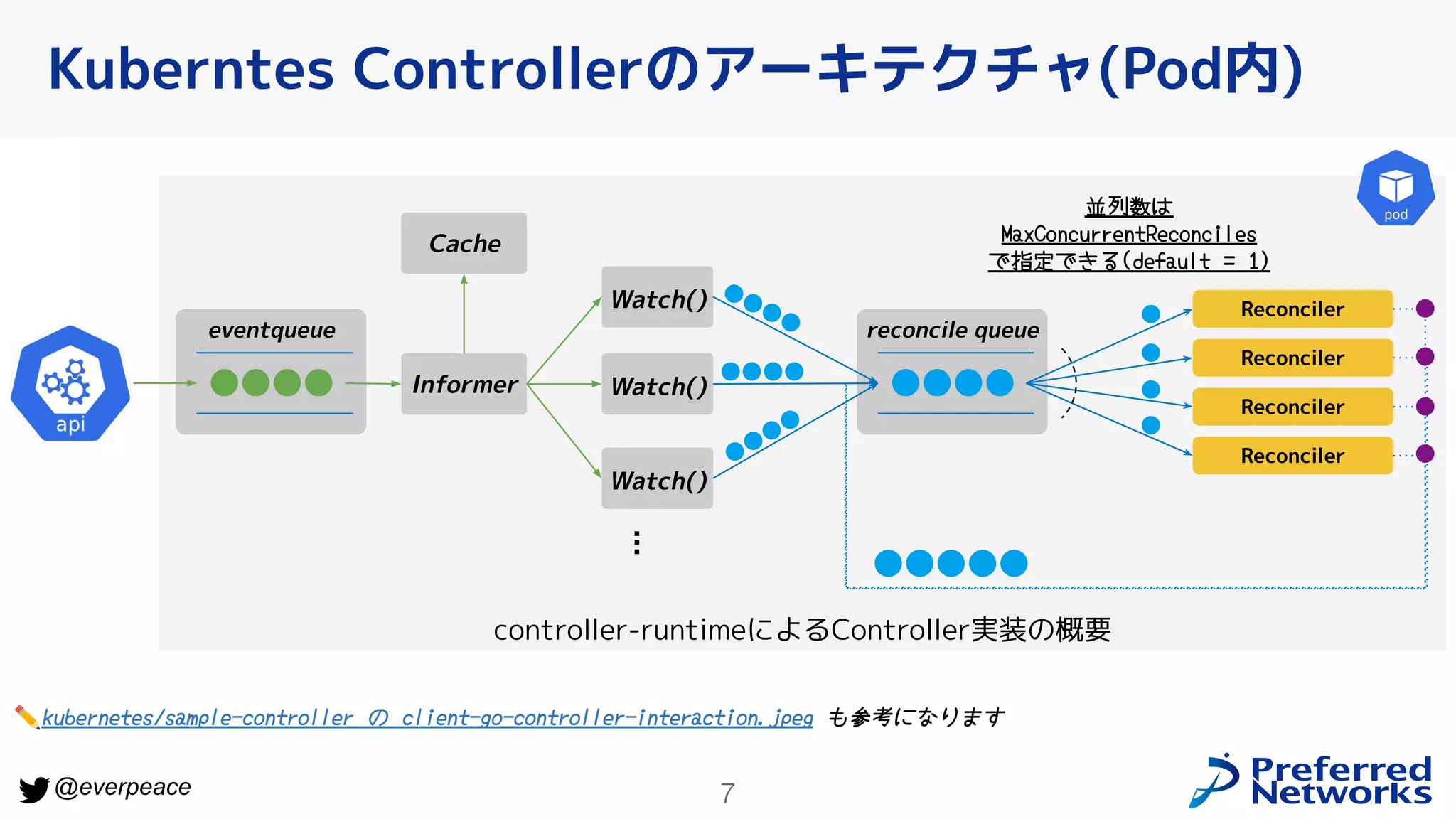
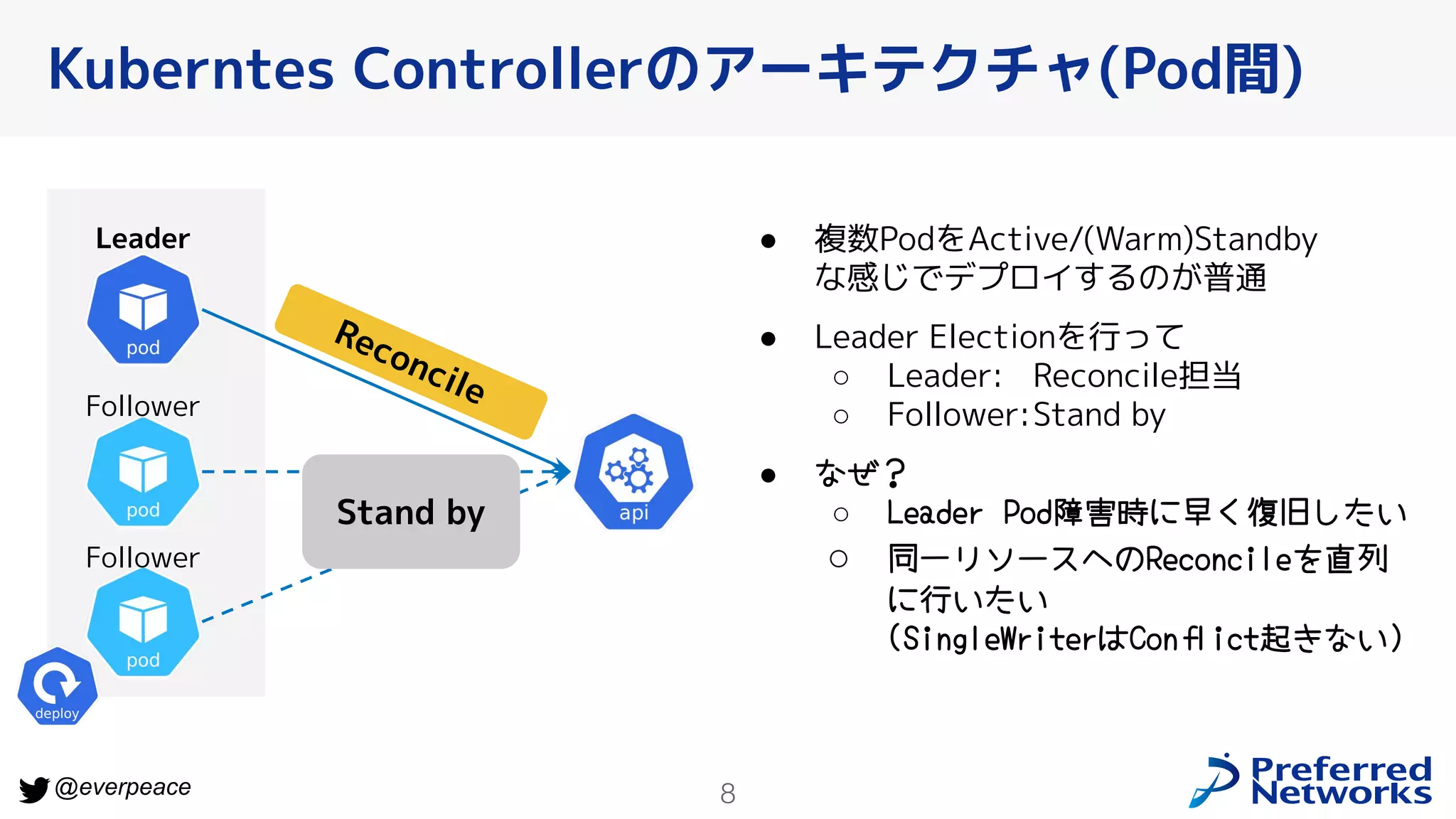
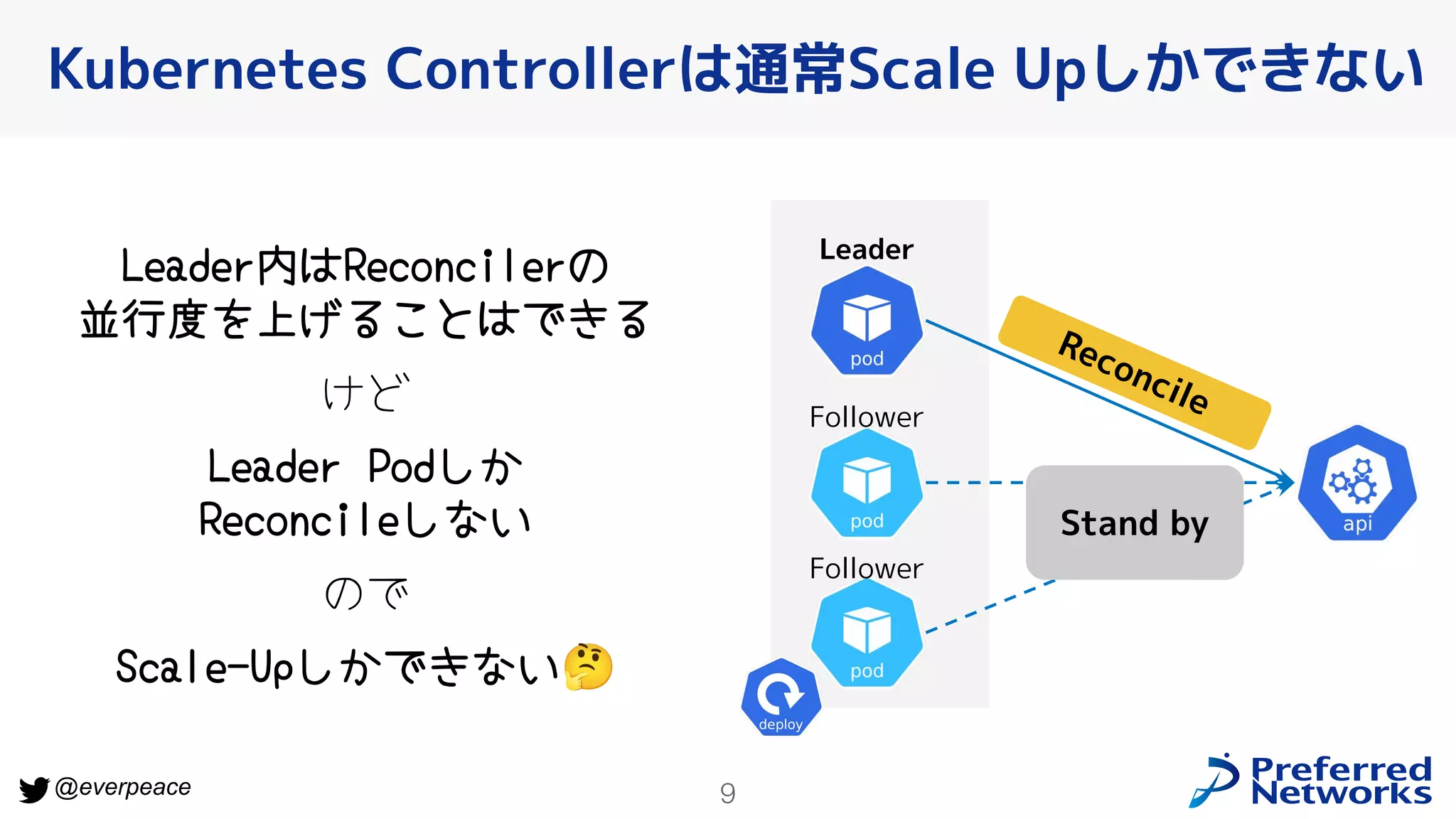
6
@everpeace
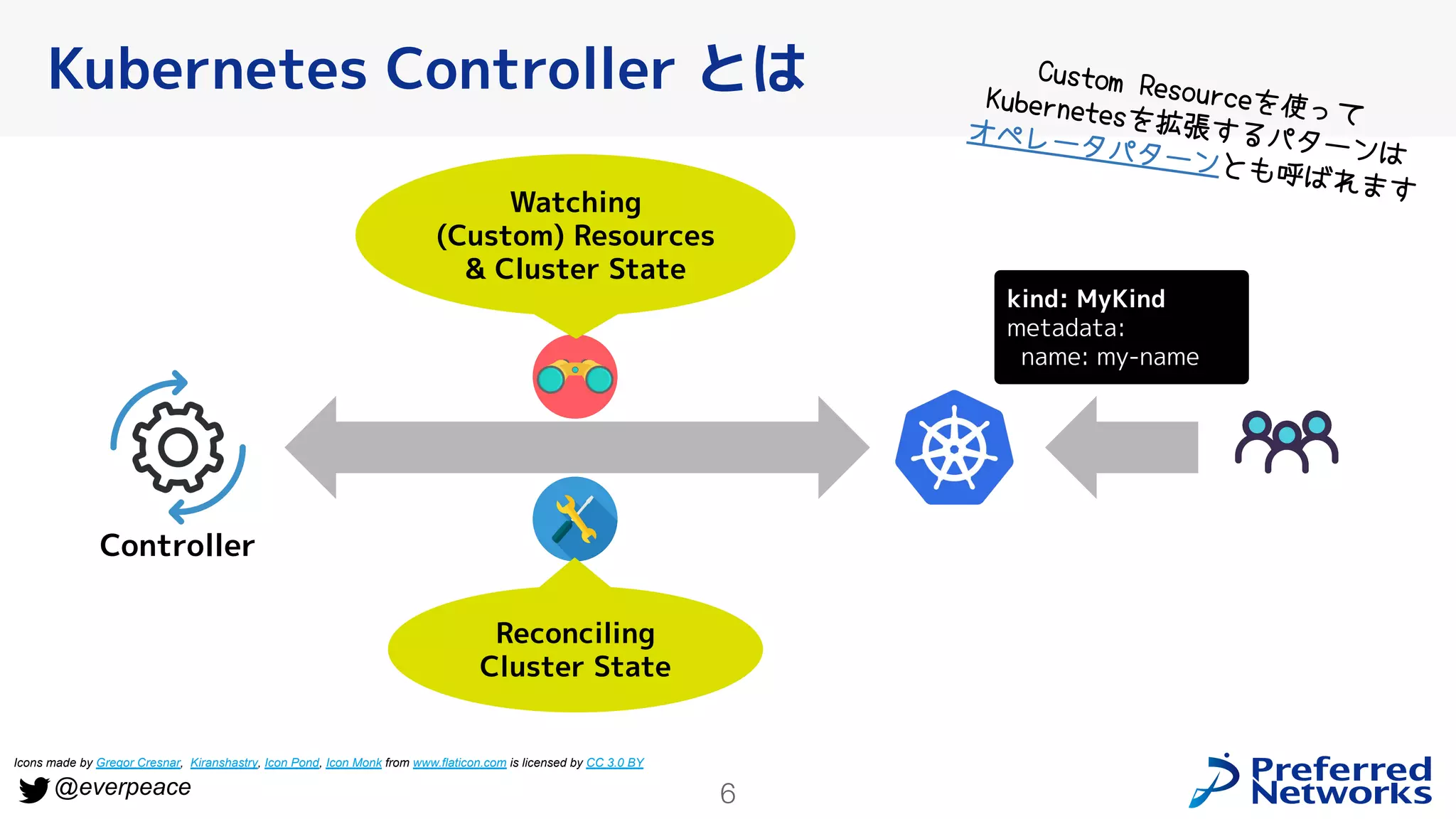
Kubernetes Controller とは
Iconsmade by Gregor Cresnar, Kiranshastry, Icon Pond, Icon Monk from www.flaticon.com is licensed by CC 3.0 BY
kind: MyKind
metadata:
name: my-name
Watching
(Custom) Resources
& Cluster State
Reconciling
Cluster State
Controller
Custom Resourceを使って
Kubernetesを拡張するパターンは
オペレータパターンとも呼ばれます
32
@everpeace
Kubernetes自体のScalability限界に注意
● Considerations forlarge clusters | Kubernetes に上限値の明記あり
○ No more than 110 pods per node
○ No more than 5000 nodes
○ No more than 150000 total pods
○ No more than 300000 total containers
● etcd 自体がすべての書き込みは直列処理する
➔ つまり更新はScale-Outしない
(--etcd-servers-overridesでgroup/resource単位でetcd更新負荷をOffload/分離可)
➔ せっかくController Scale-Outしても意味ない!?😇
eventだけ別etcd
とか見かけますよね



































![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Kubernetes on Mesos Deep Dive [Japanese]](https://cdn.slidesharecdn.com/ss_thumbnails/k8sonmesos-180626063613-thumbnail.jpg?width=640&height=640&fit=bounds)































