Download as PDF, PPTX


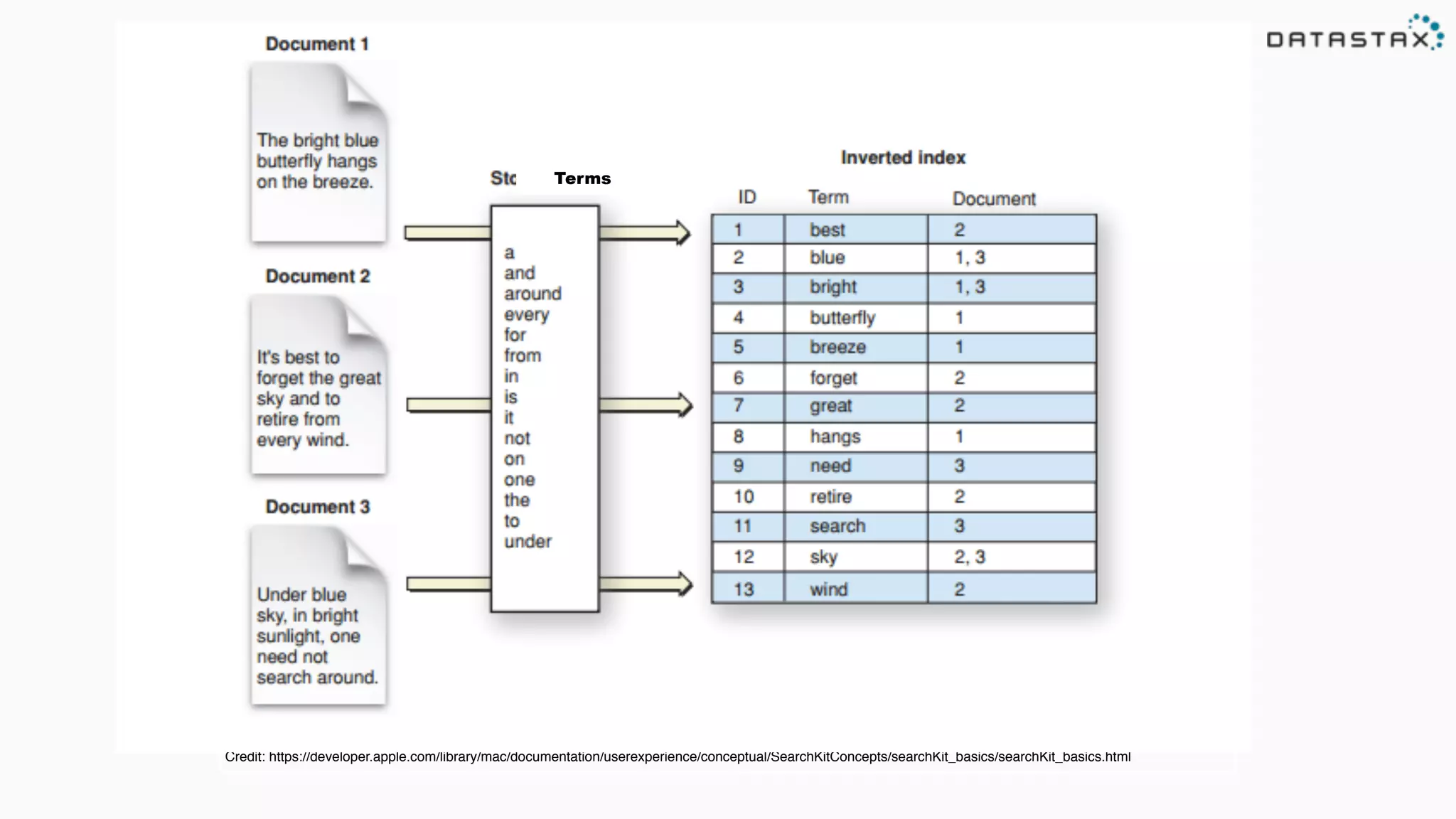
![The bright blue butterfly hangs on the breeze.
[the] [bright] [blue] [butterfly] [hangs] [on] [the] [breeze]
Tokens](https://image.slidesharecdn.com/lovetriangle-150626185939-lva1-app6892/75/Beyond-the-Query-A-Cassandra-Solr-Spark-Love-Triangle-Using-Datastax-Enterprise-English-5-2048.jpg)






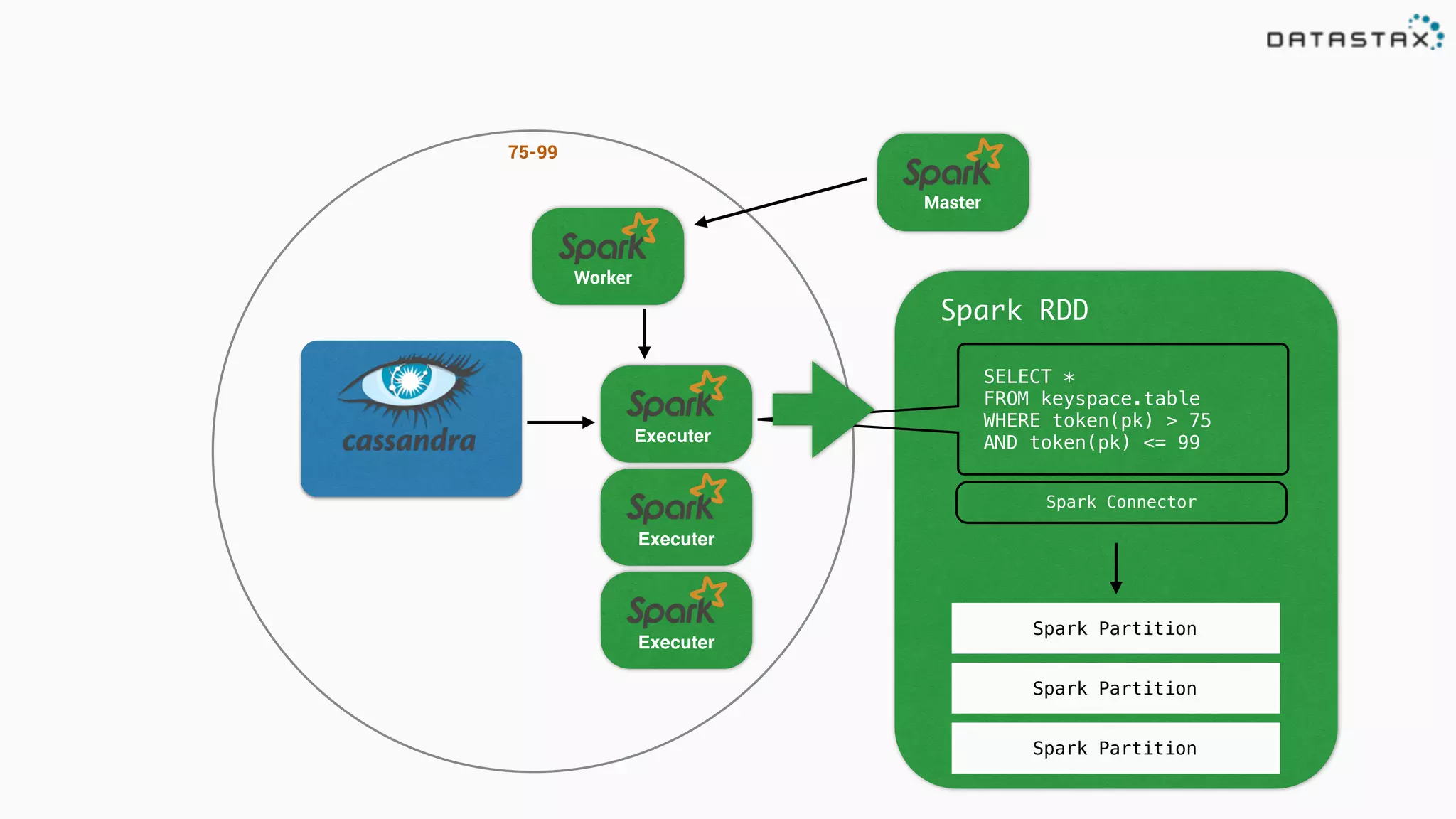
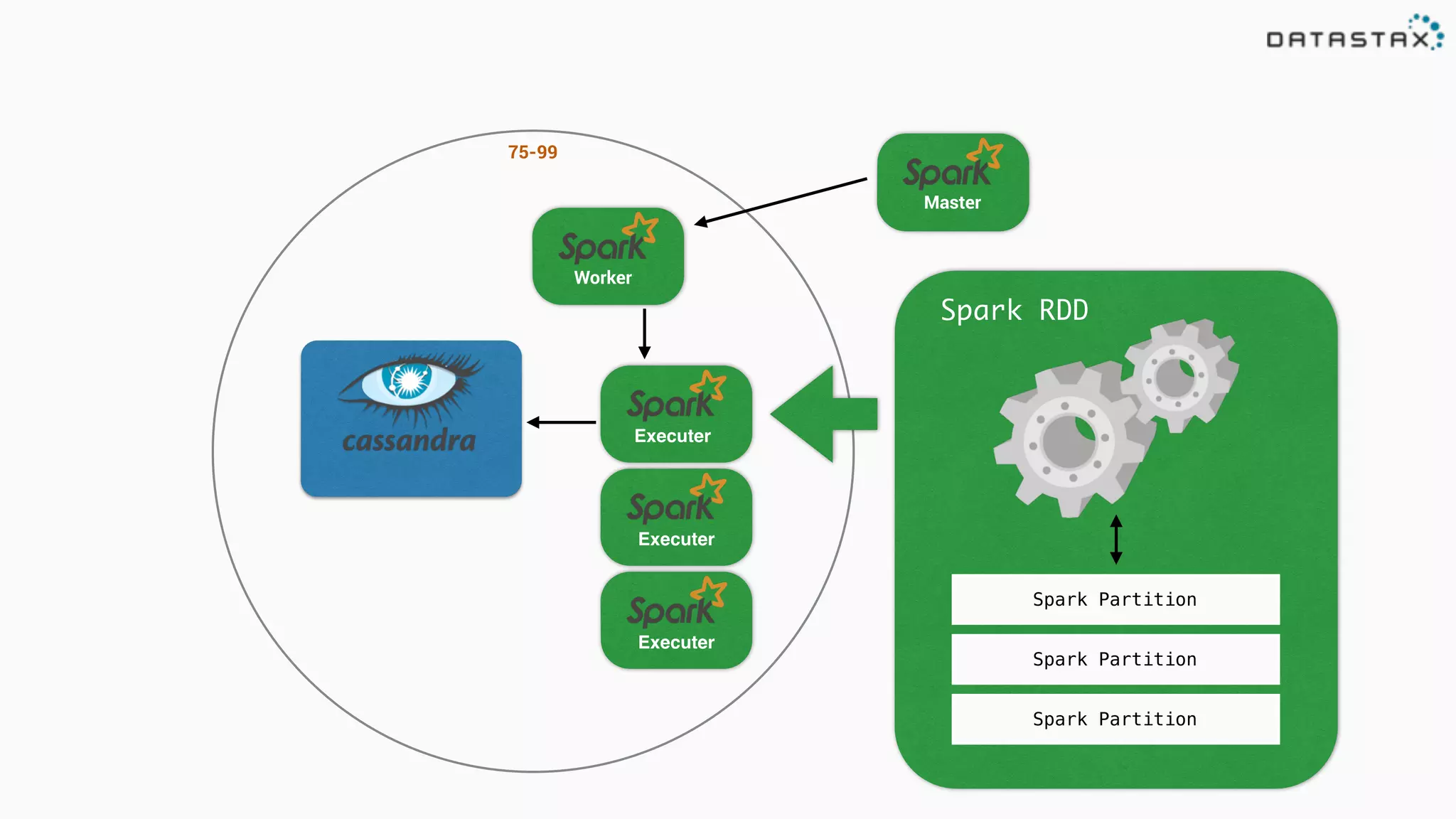

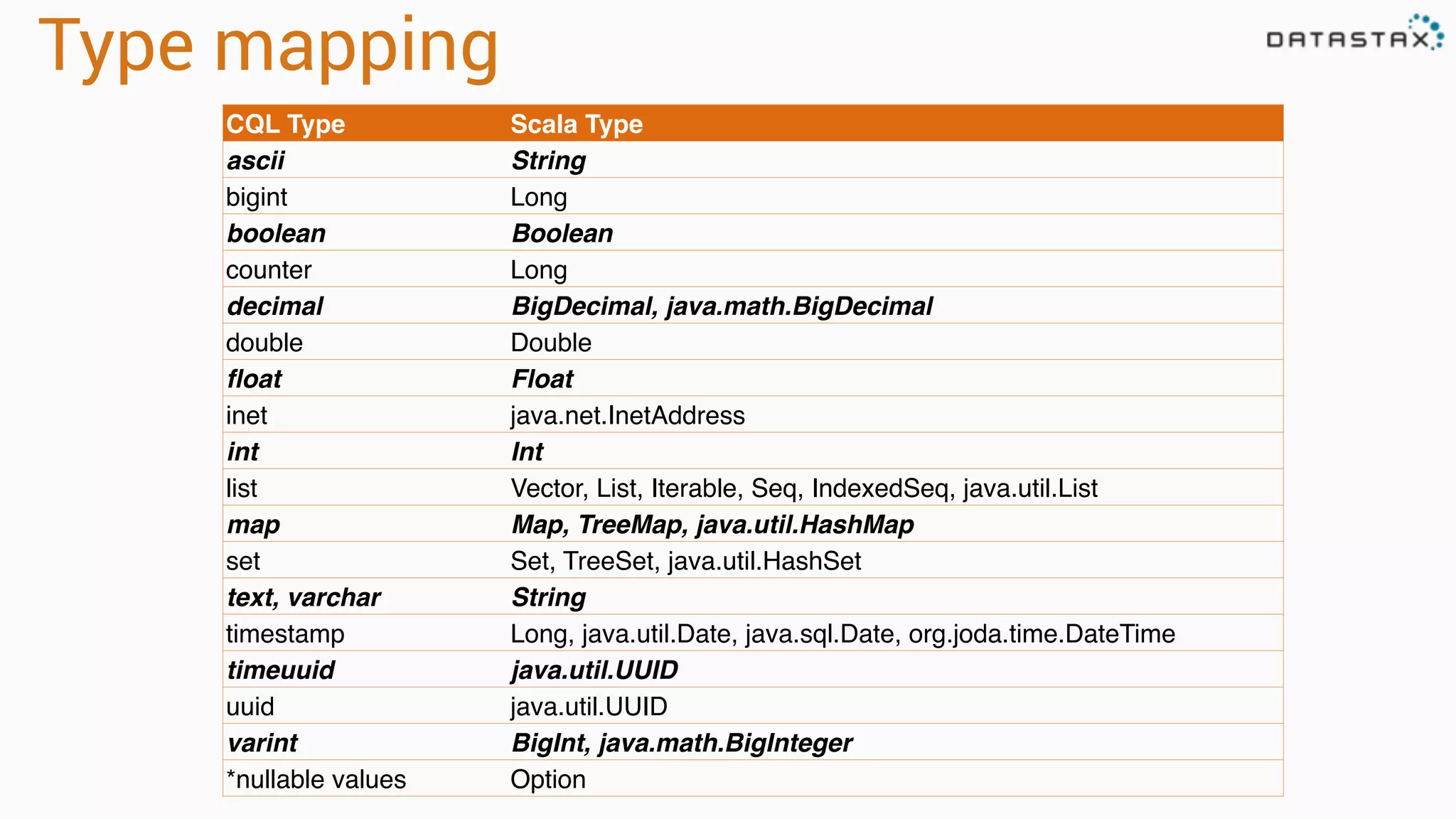





![Attaching to Spark and Cassandra
// Import Cassandra-specific functions on SparkContext and RDD objects
import org.apache.spark.{SparkContext, SparkConf}
import com.datastax.spark.connector._
/** The setMaster("local") lets us run & test the job right in our IDE */
val conf = new SparkConf(true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster(“local[*]")
.setAppName(getClass.getName)
// Optionally
.set("cassandra.username", "cassandra")
.set("cassandra.password", “cassandra")
val sc = new SparkContext(conf)](https://image.slidesharecdn.com/lovetriangle-150626185939-lva1-app6892/75/Beyond-the-Query-A-Cassandra-Solr-Spark-Love-Triangle-Using-Datastax-Enterprise-English-46-2048.jpg)


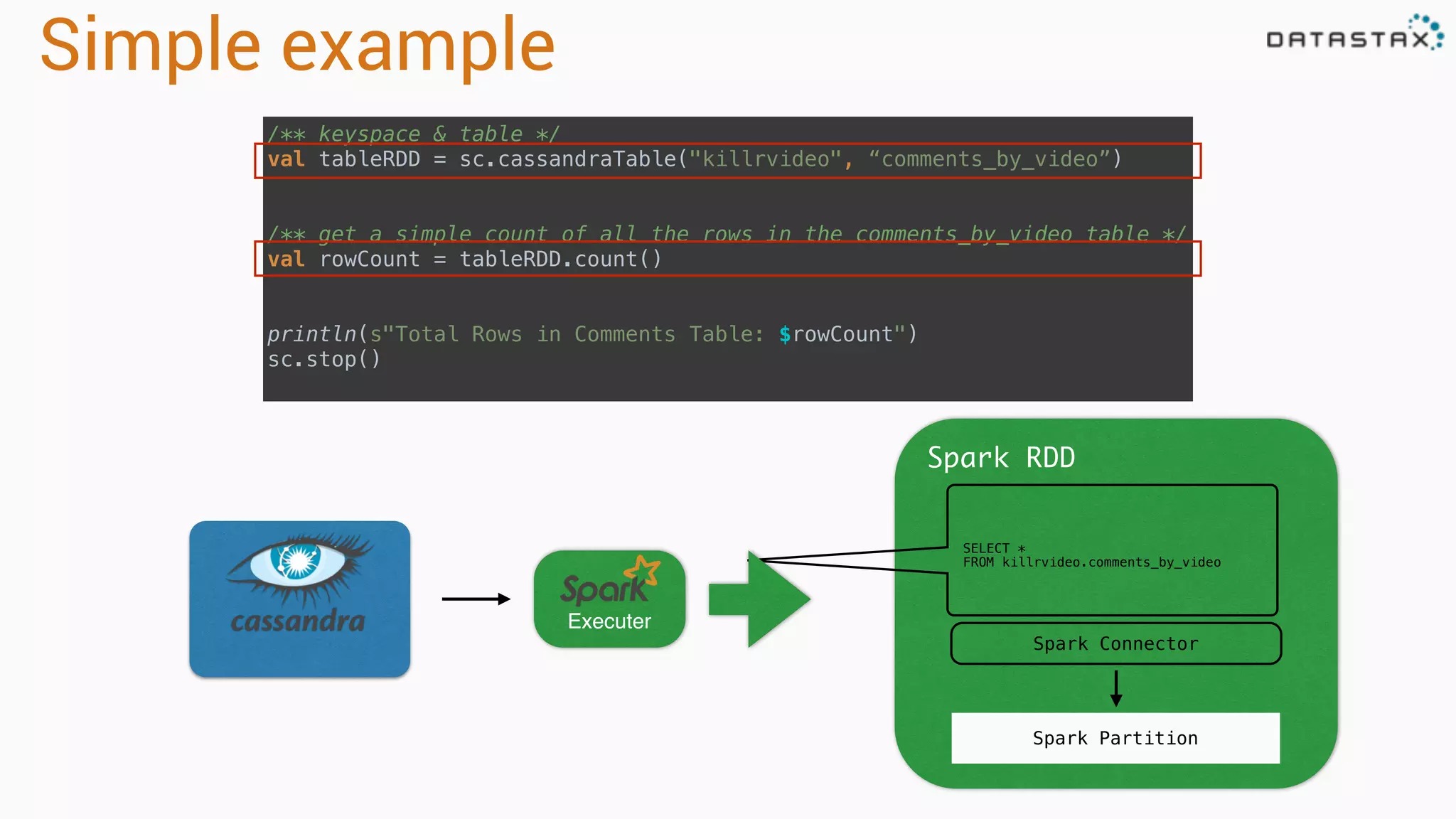
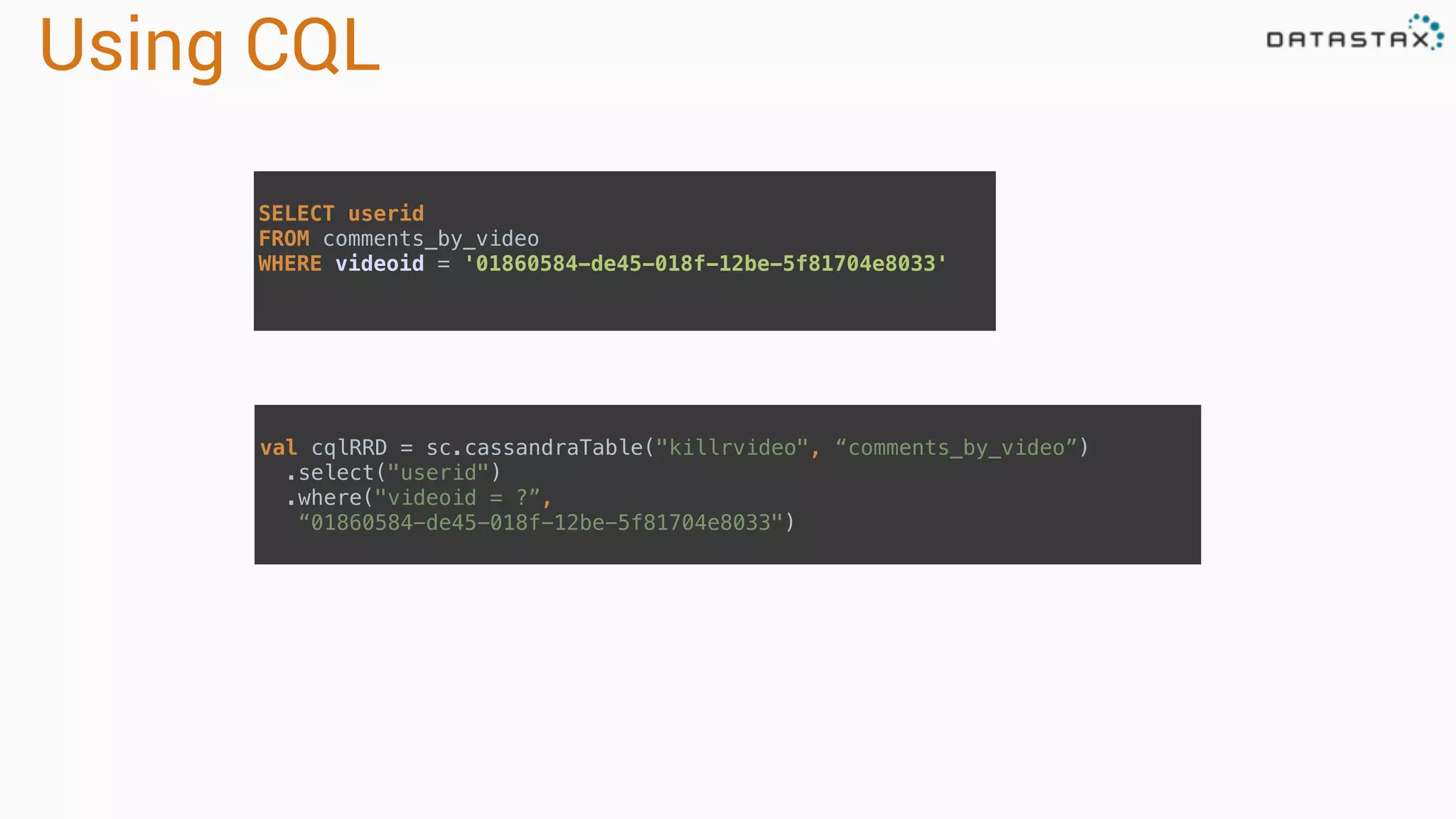
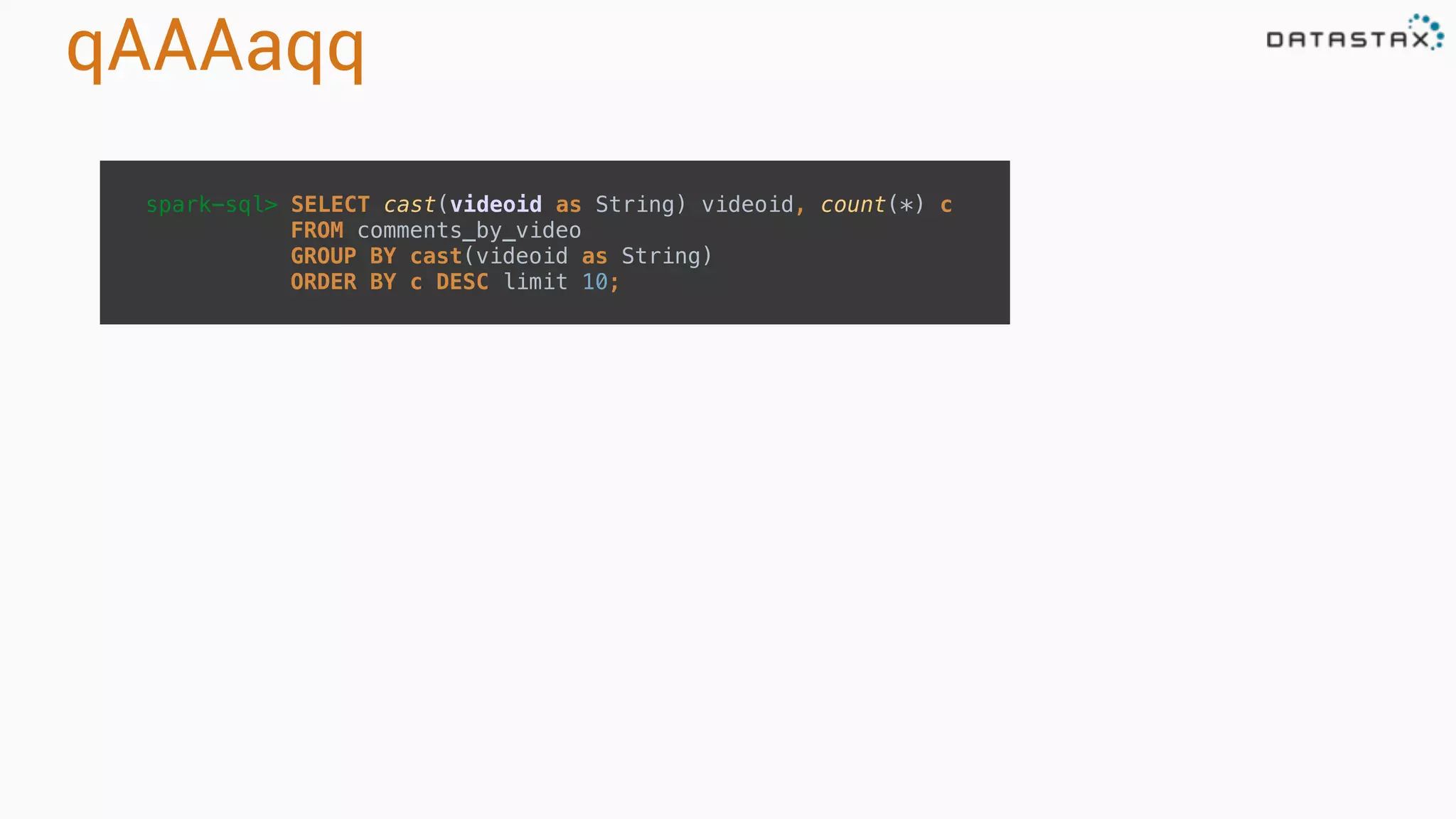

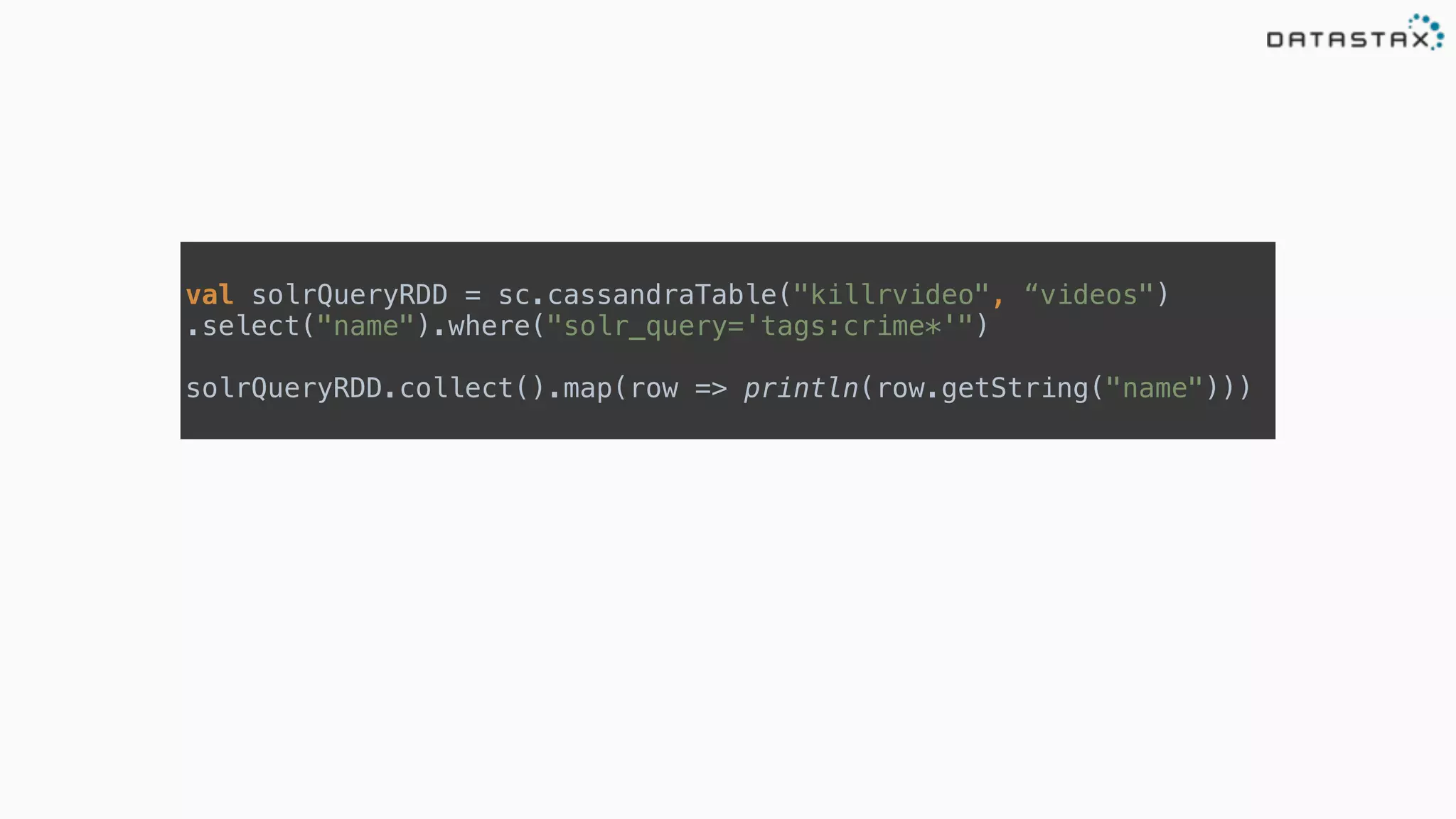



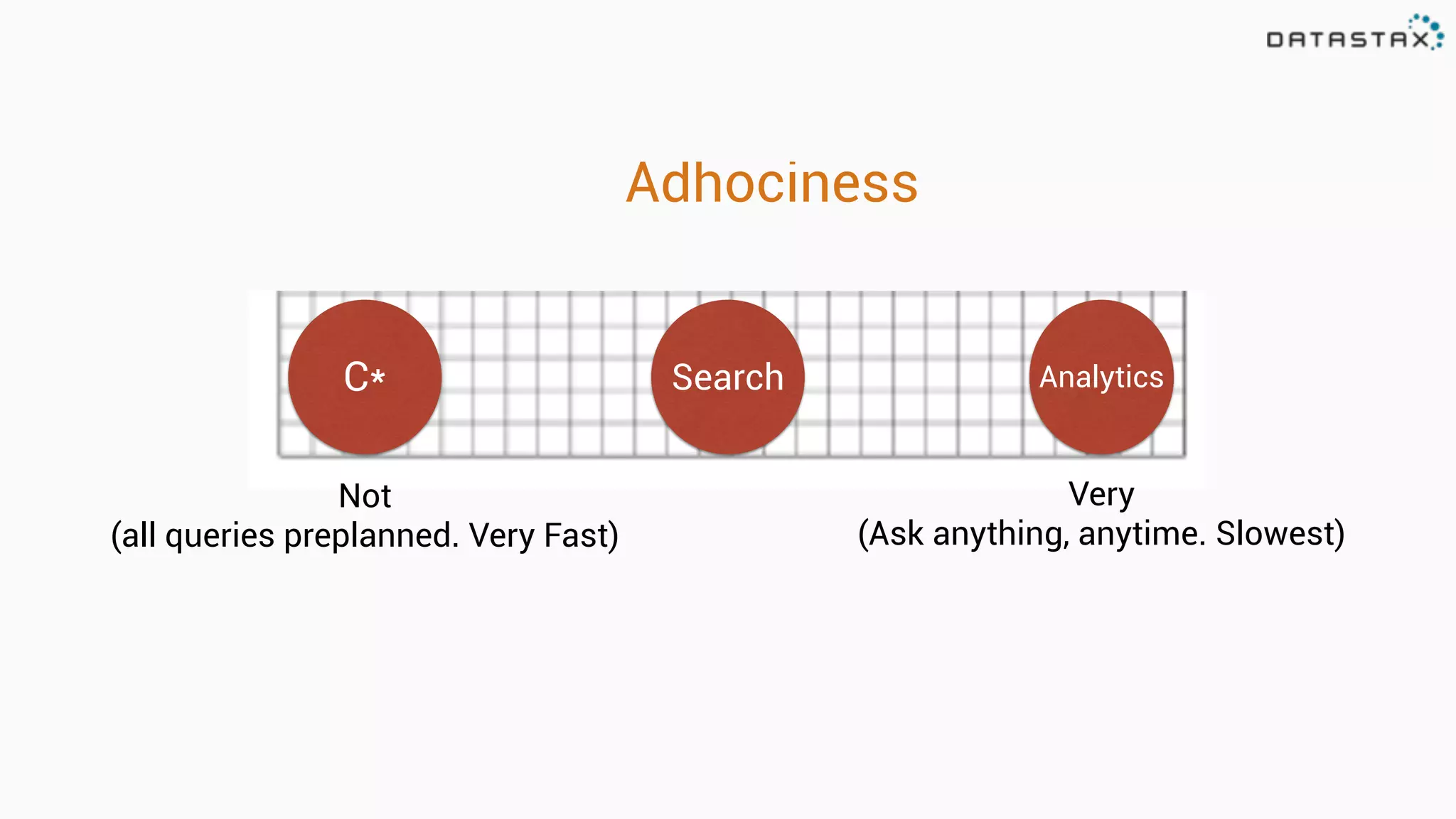
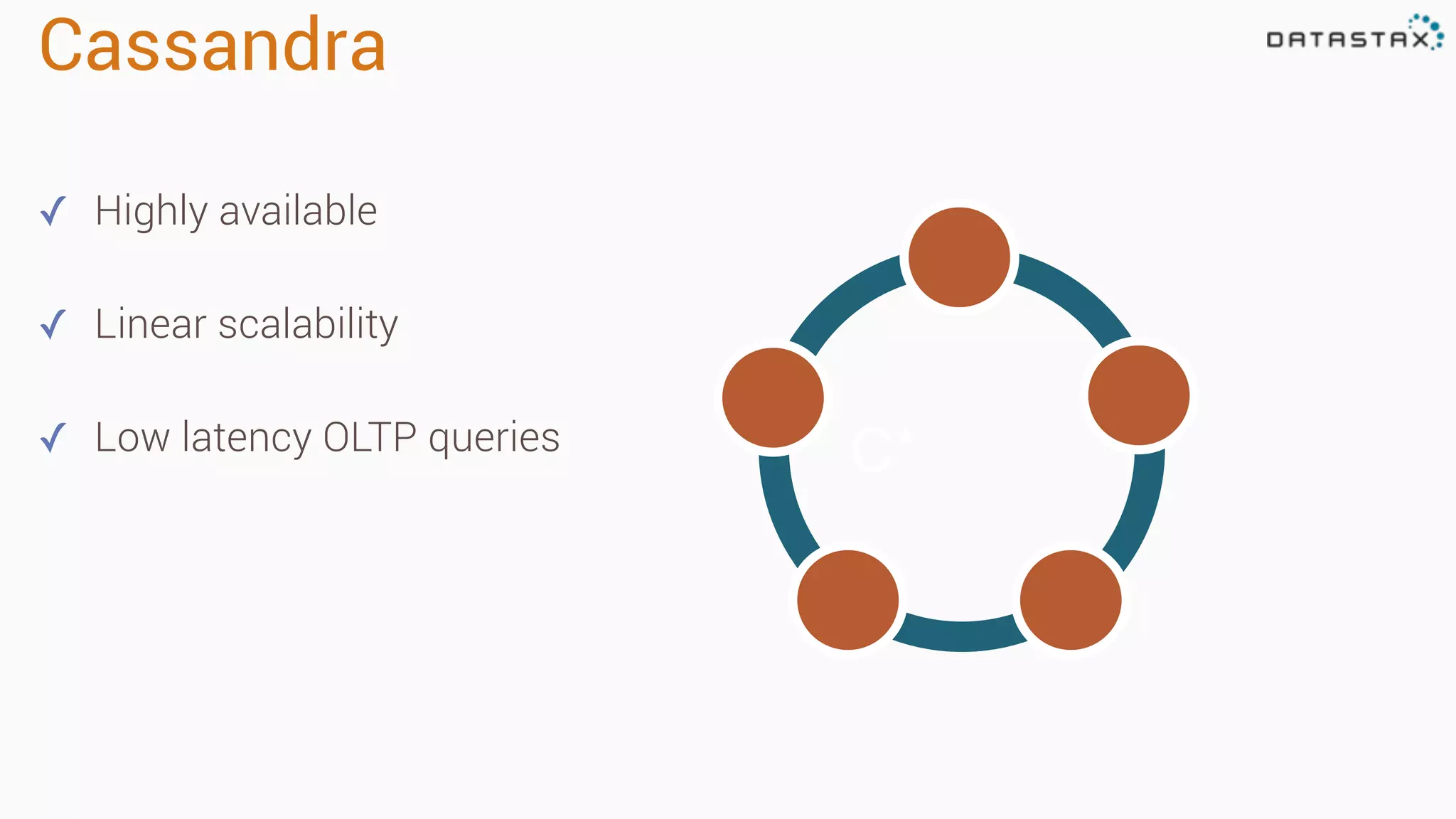
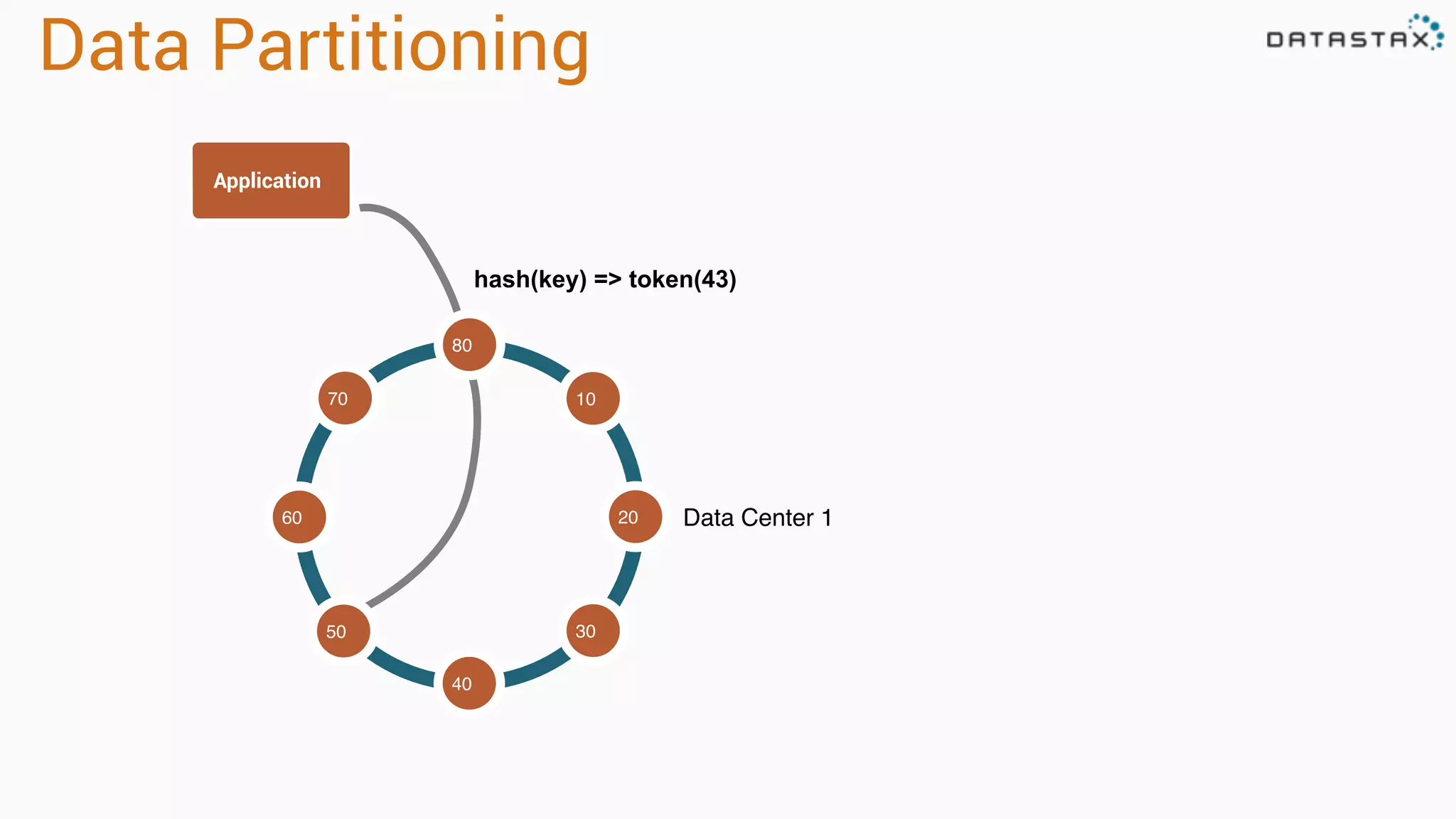
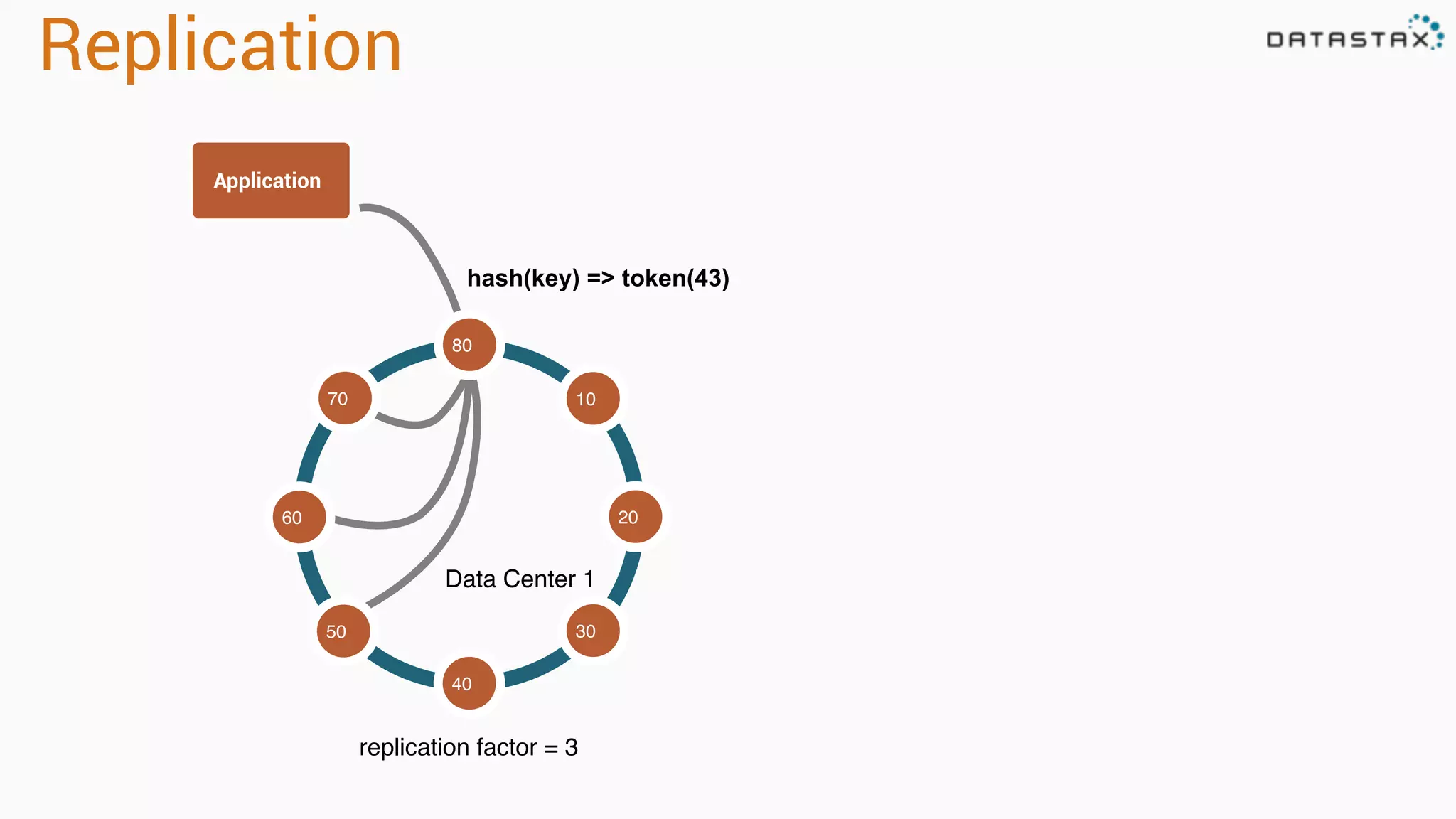
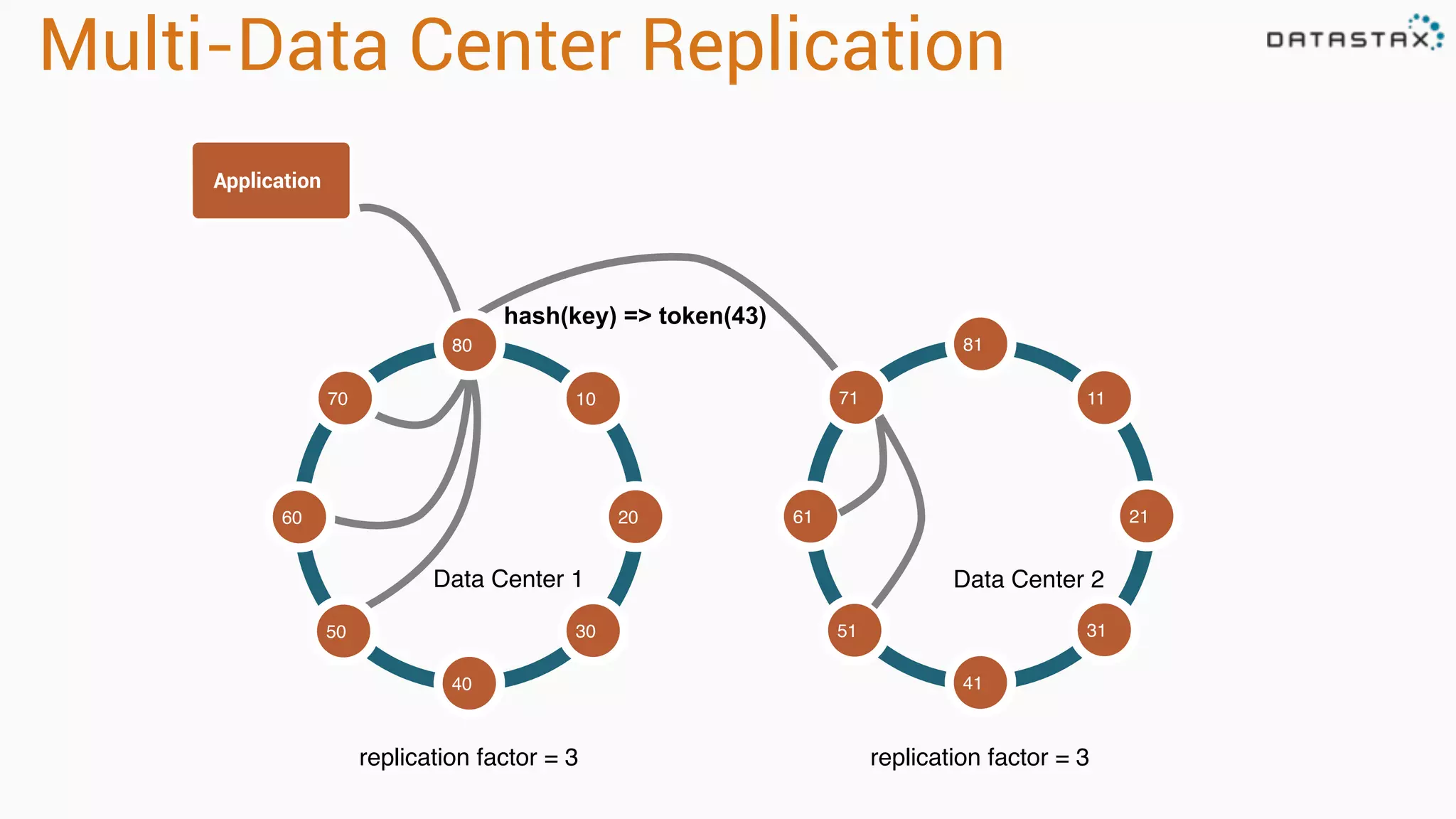
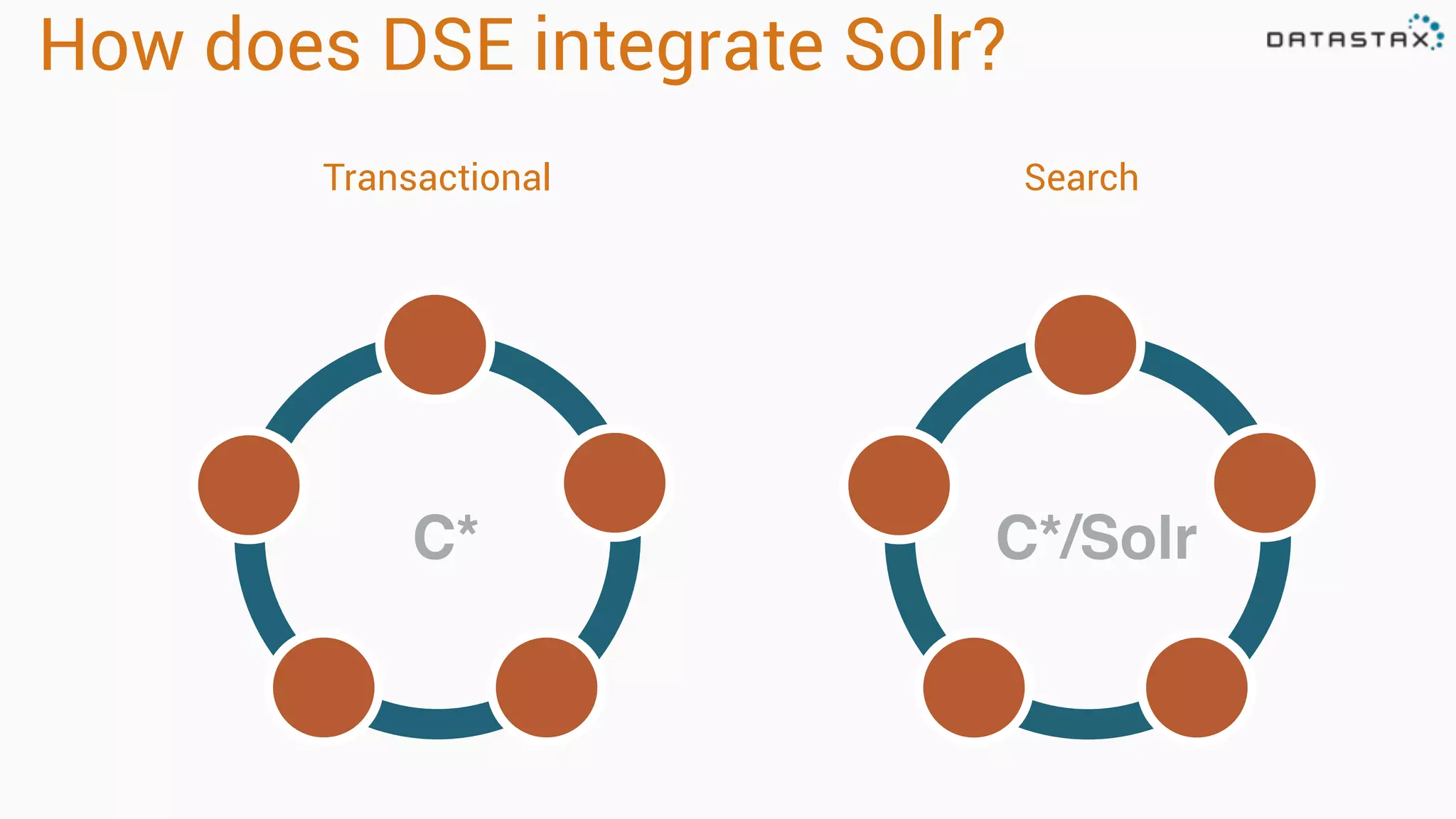
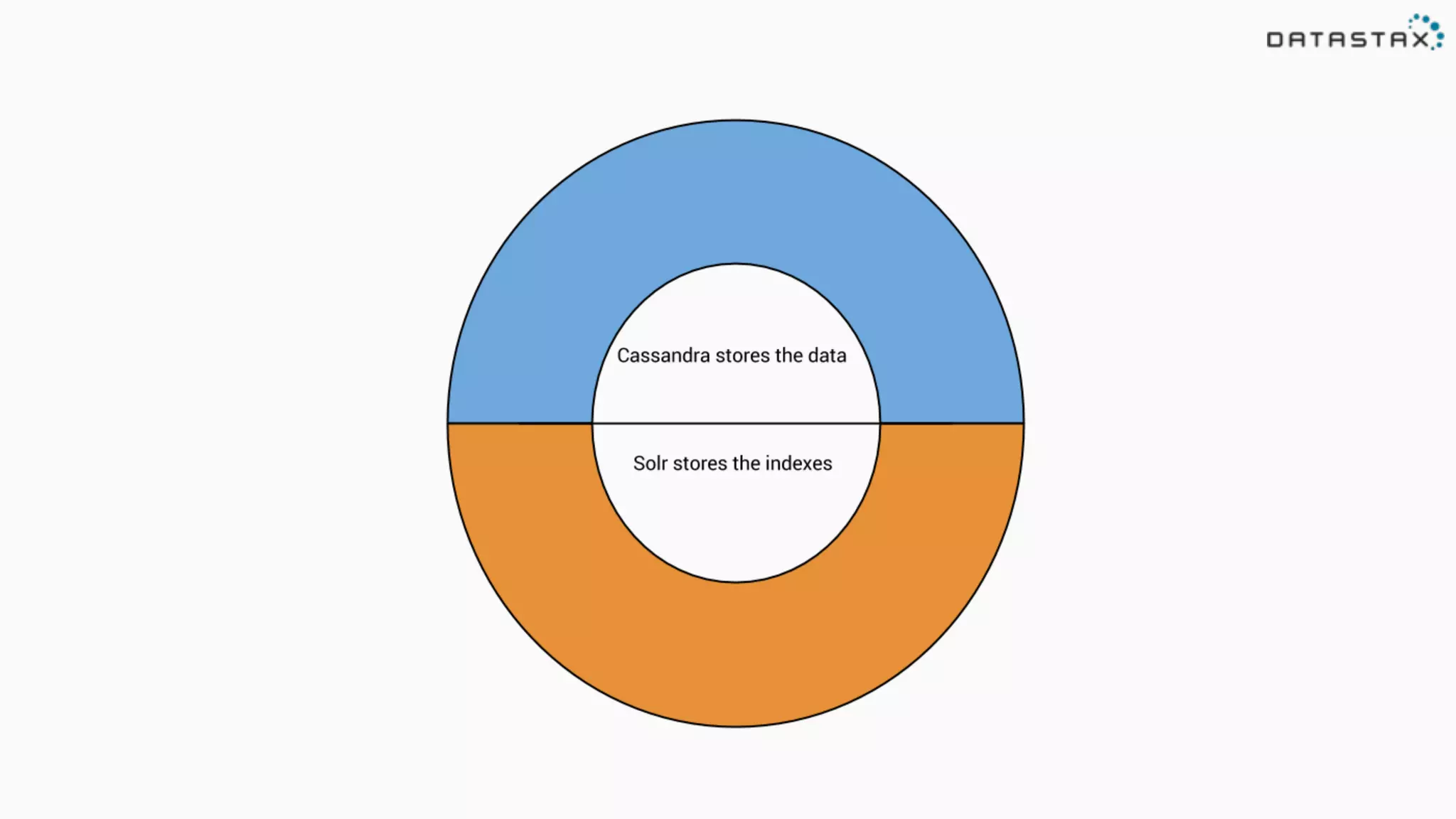
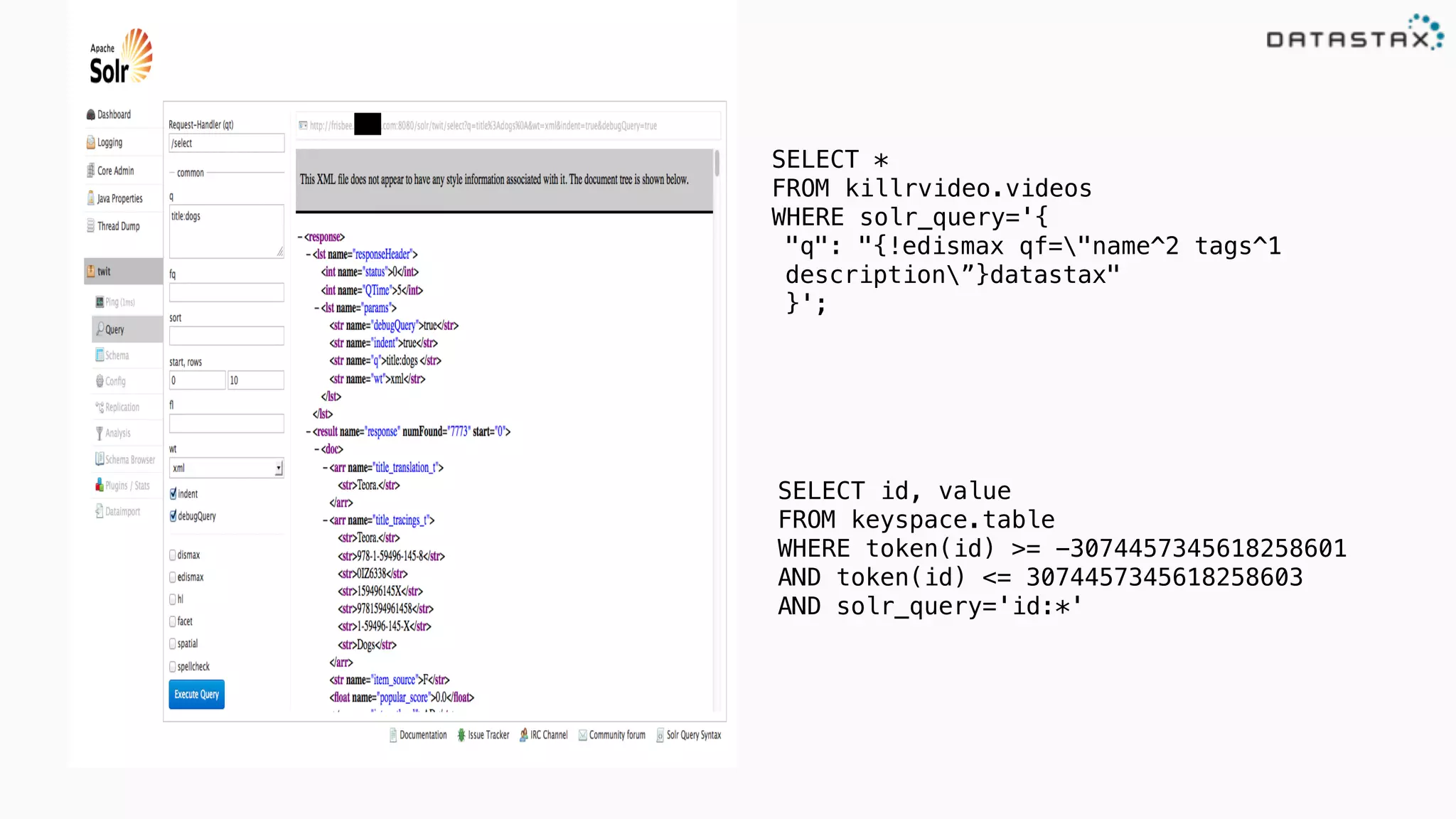
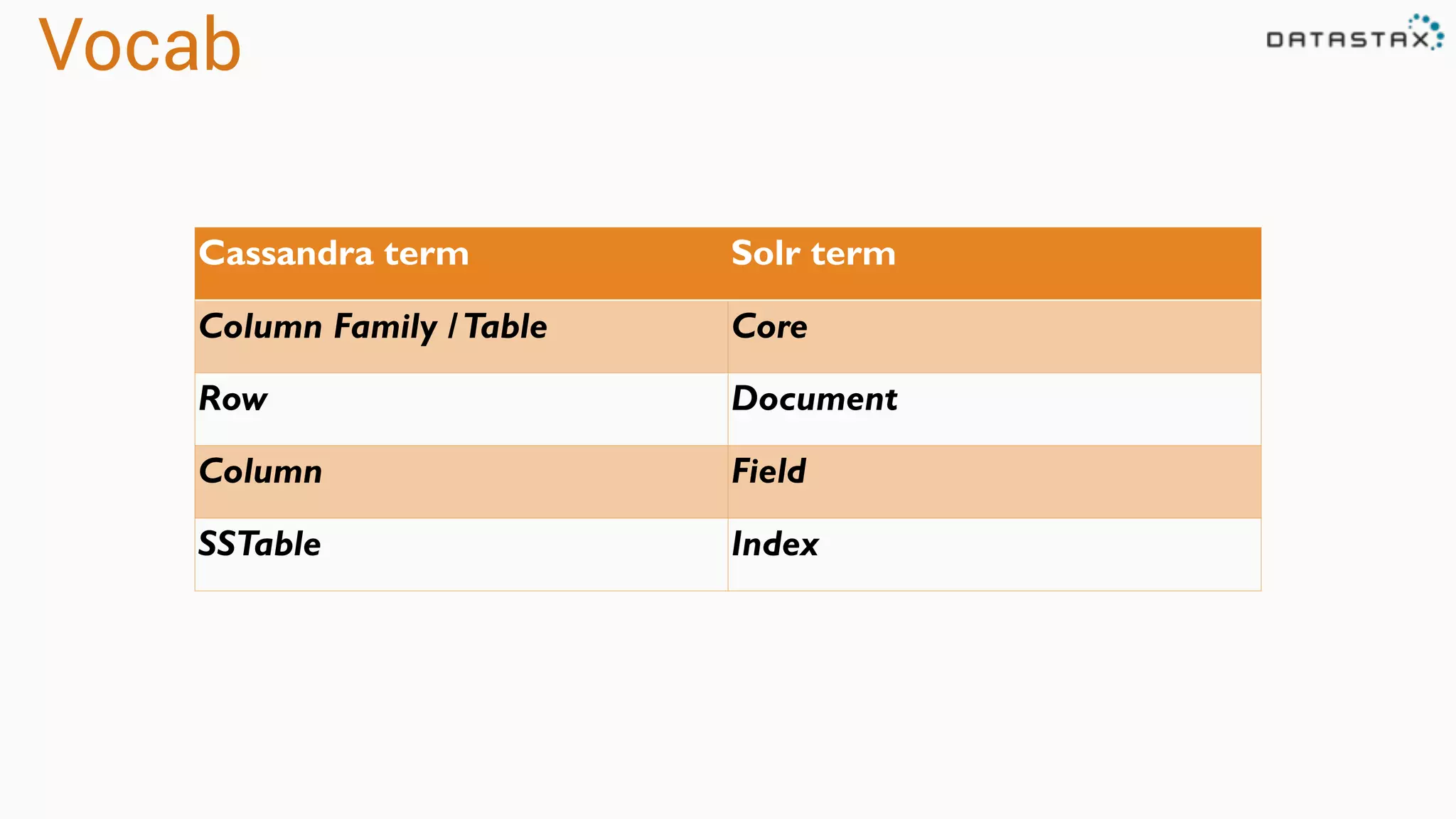
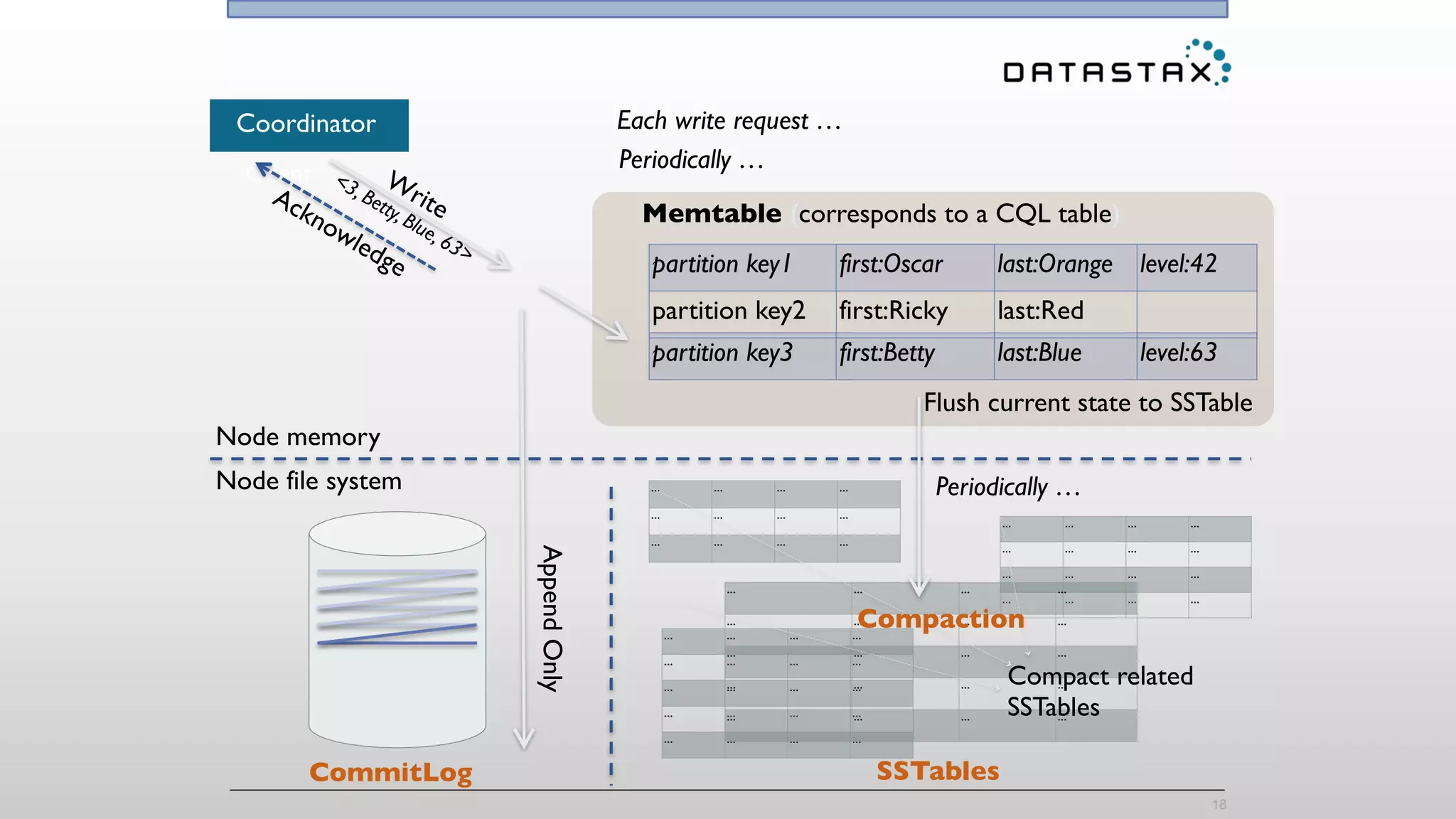
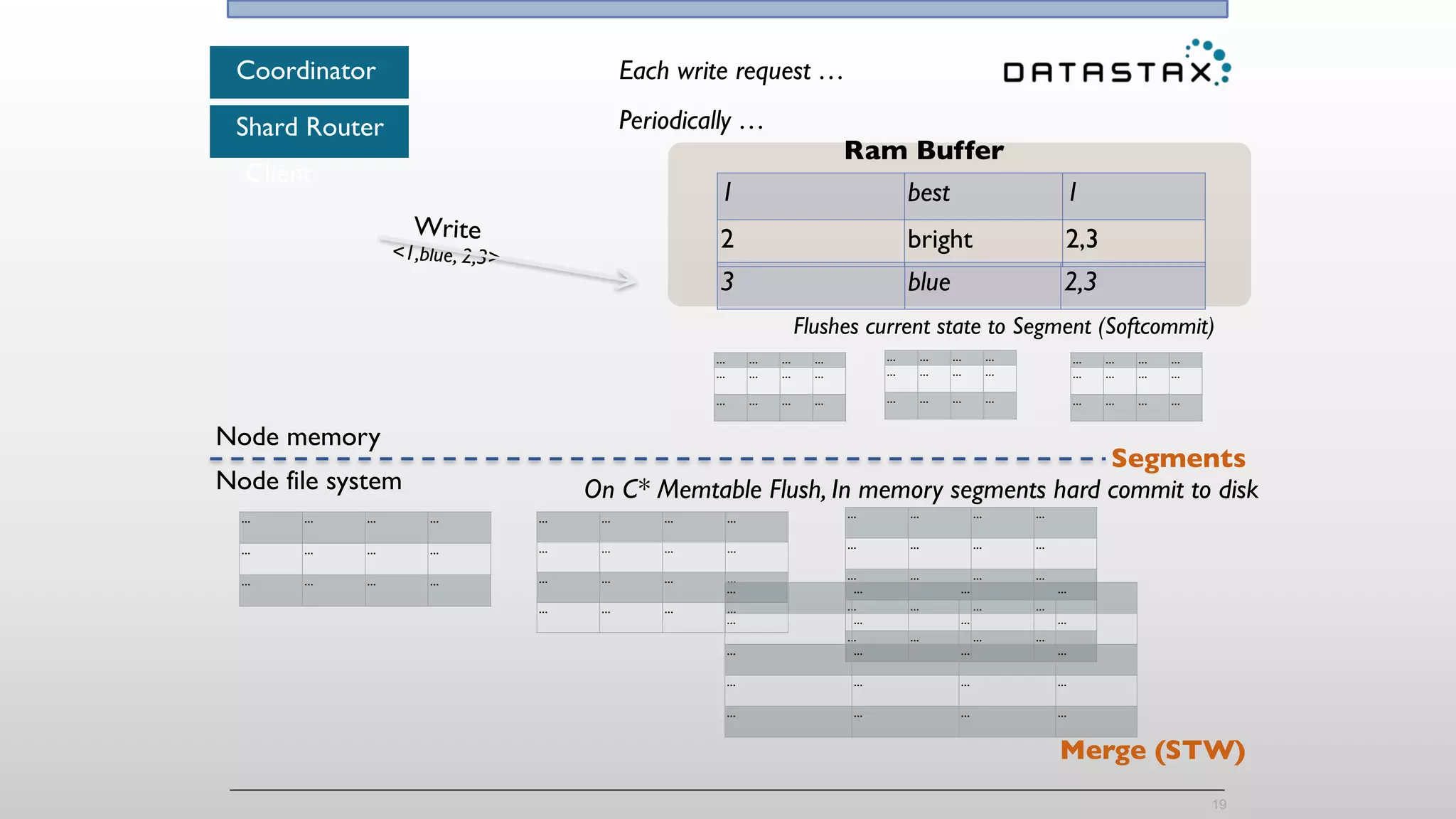
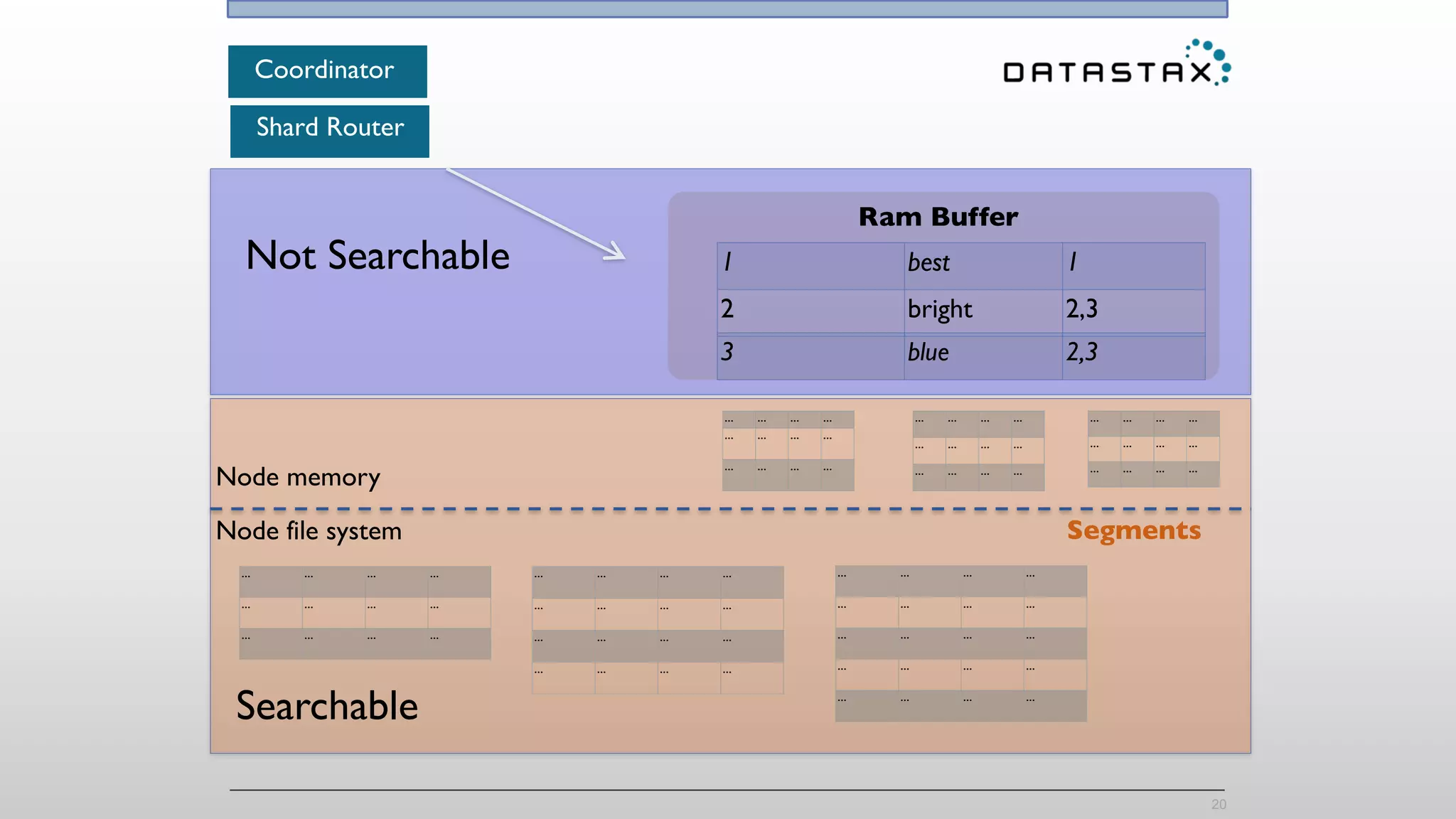
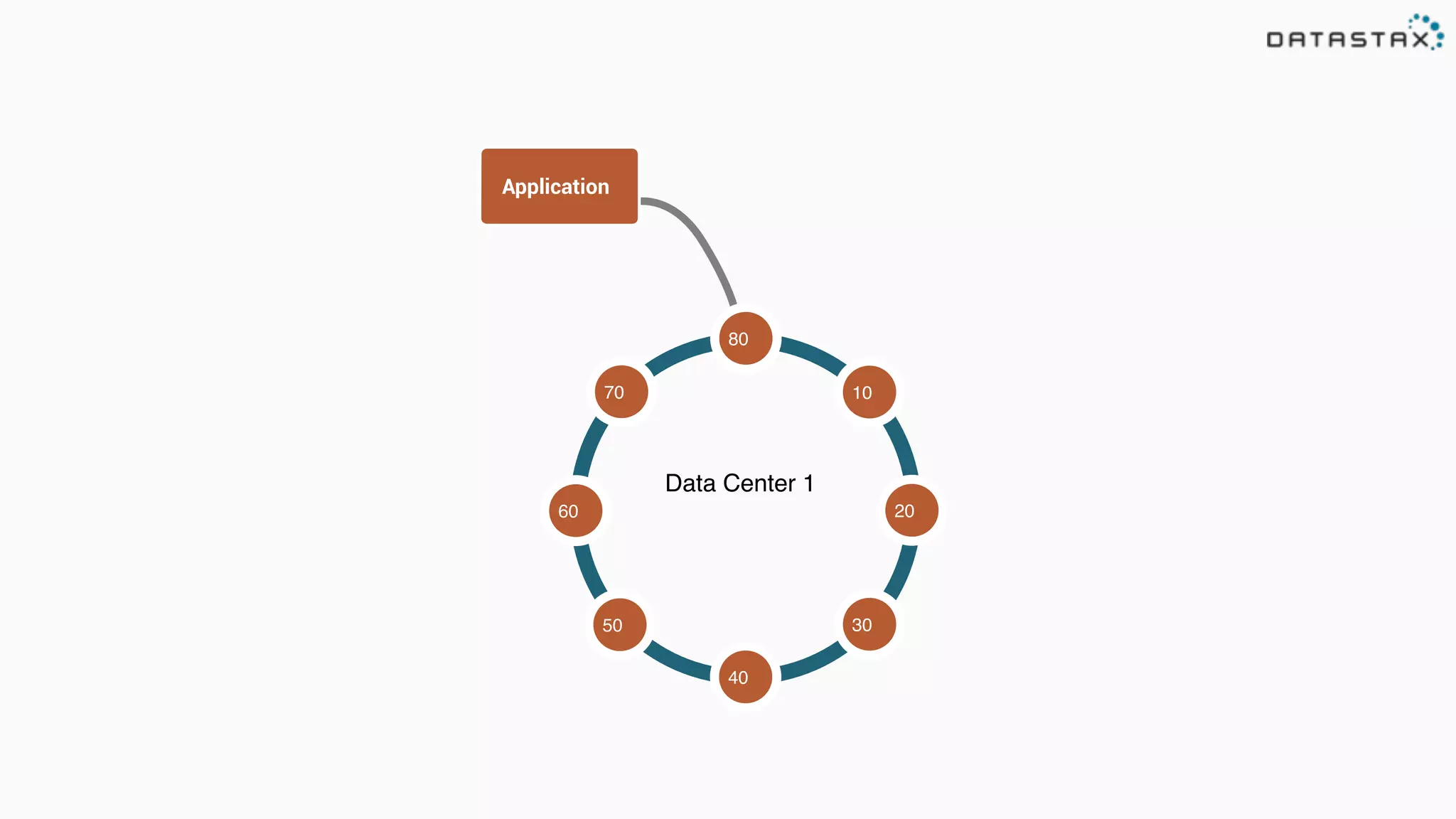
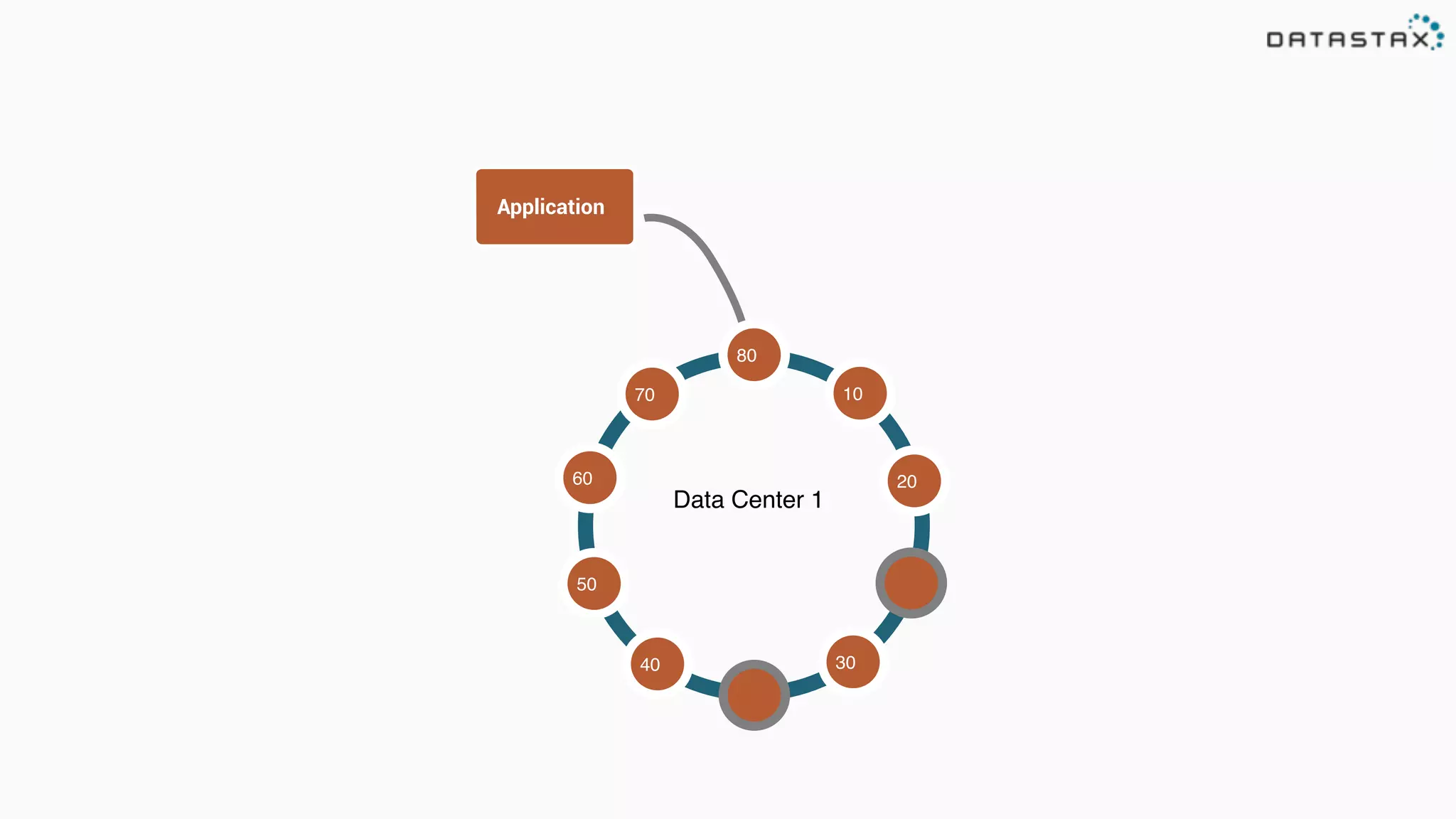
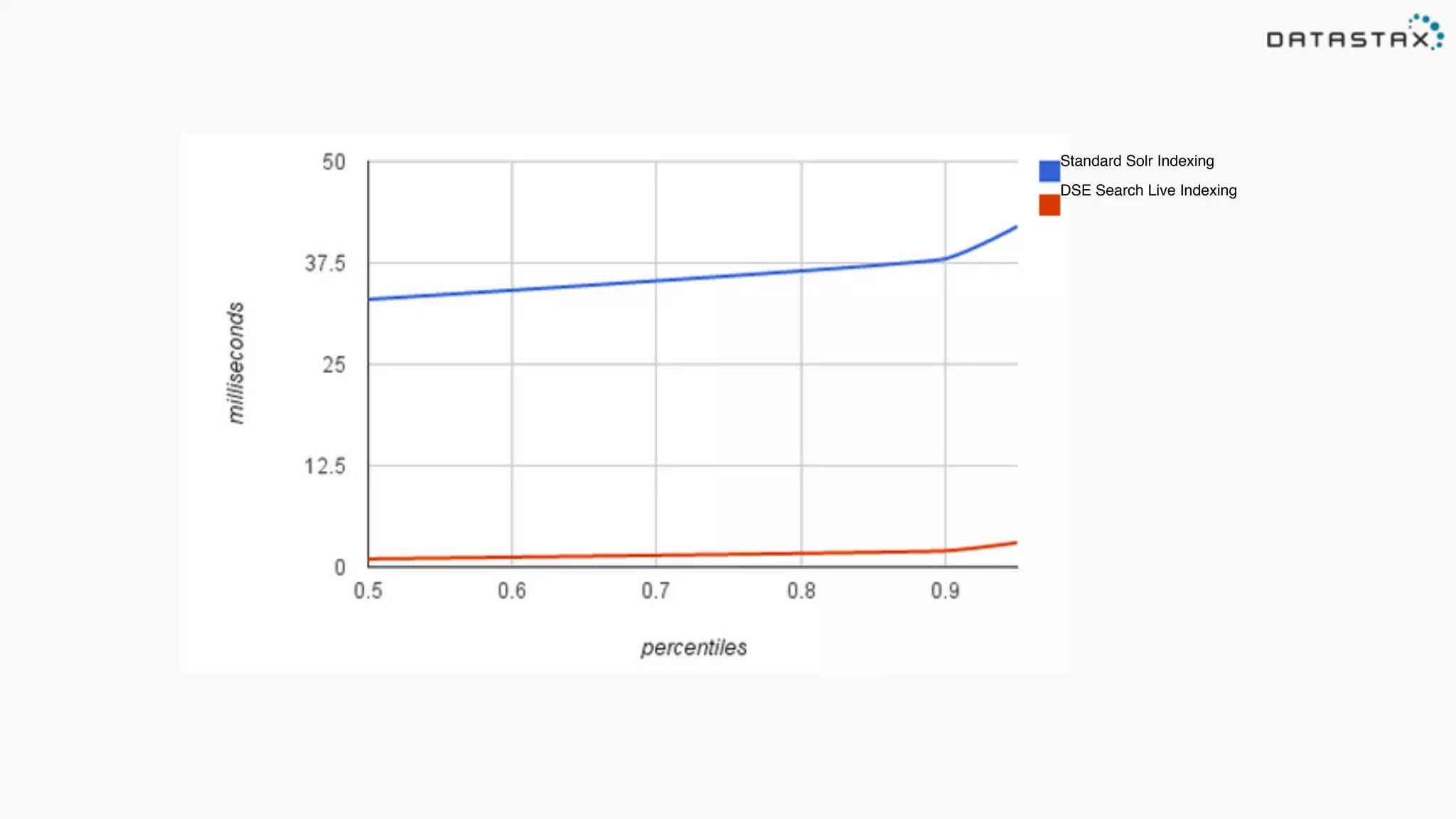
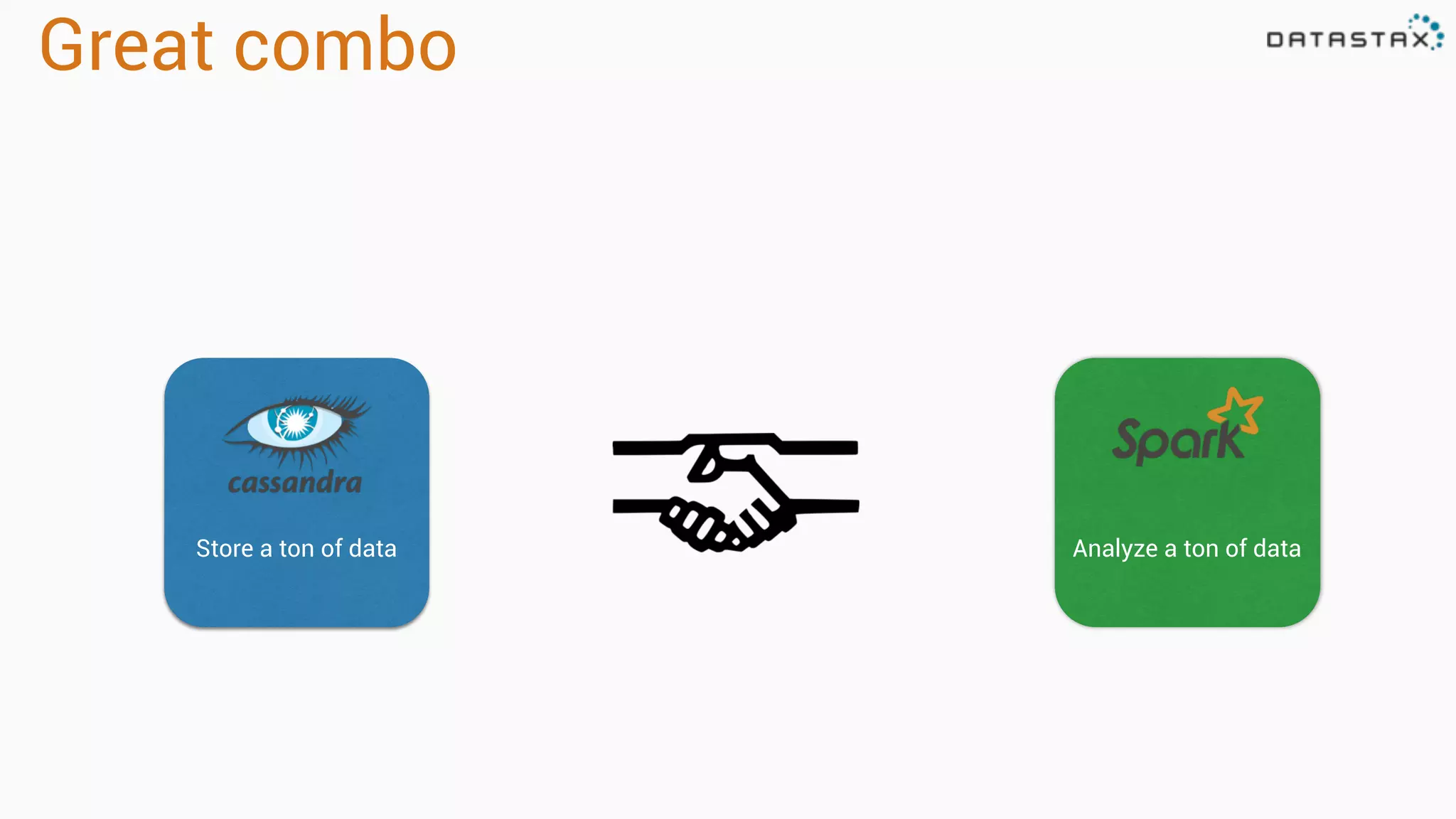
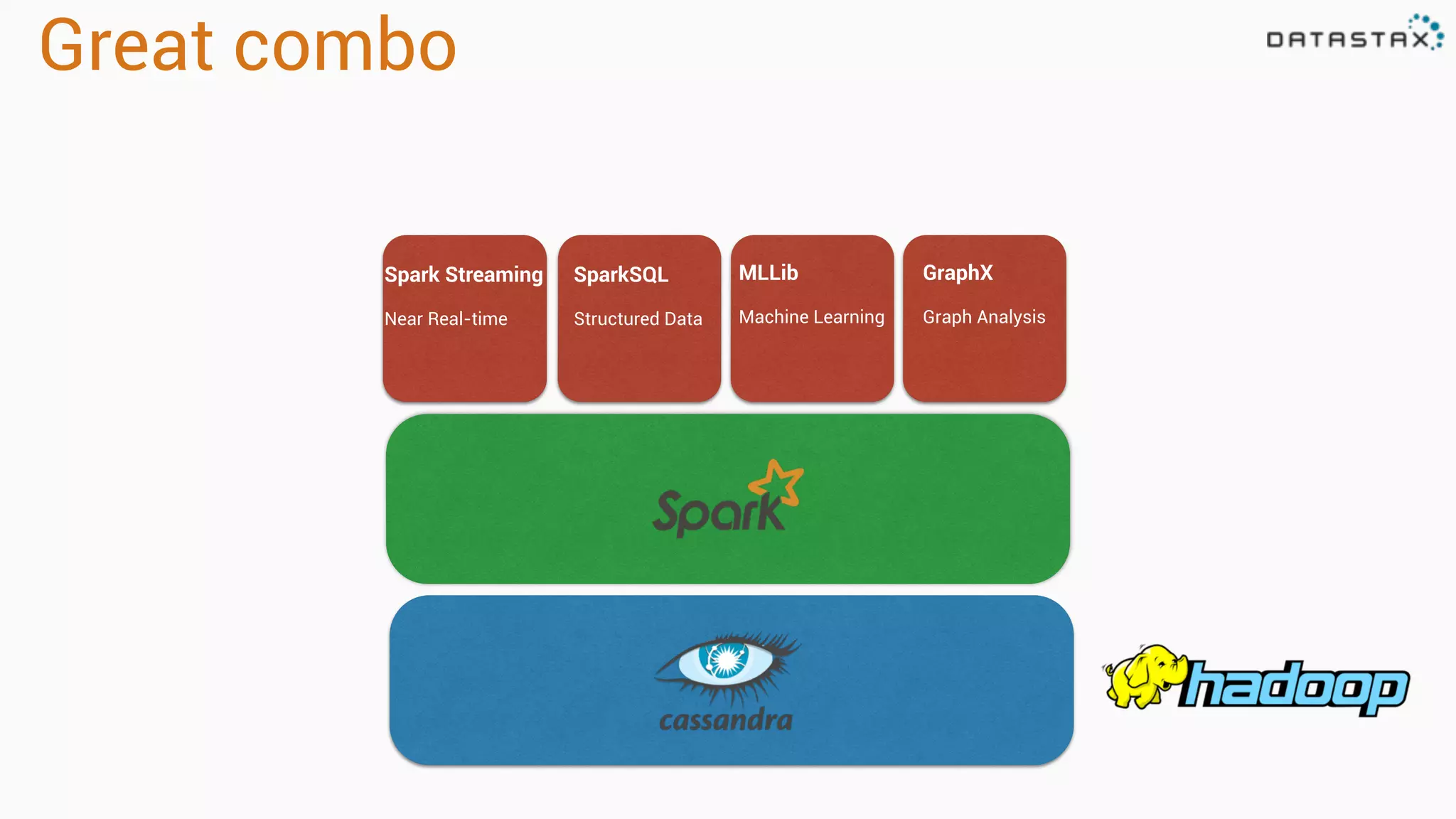
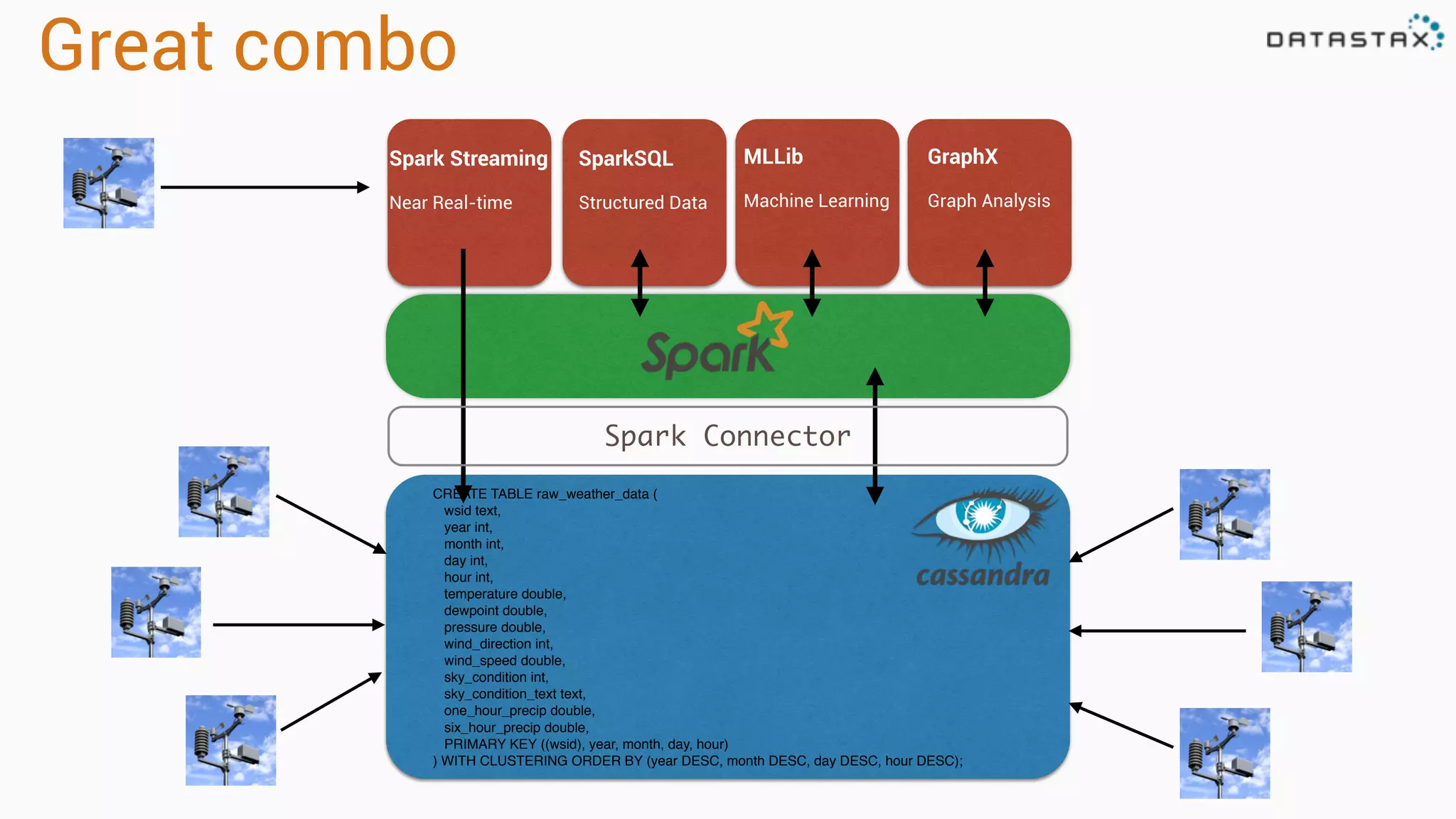
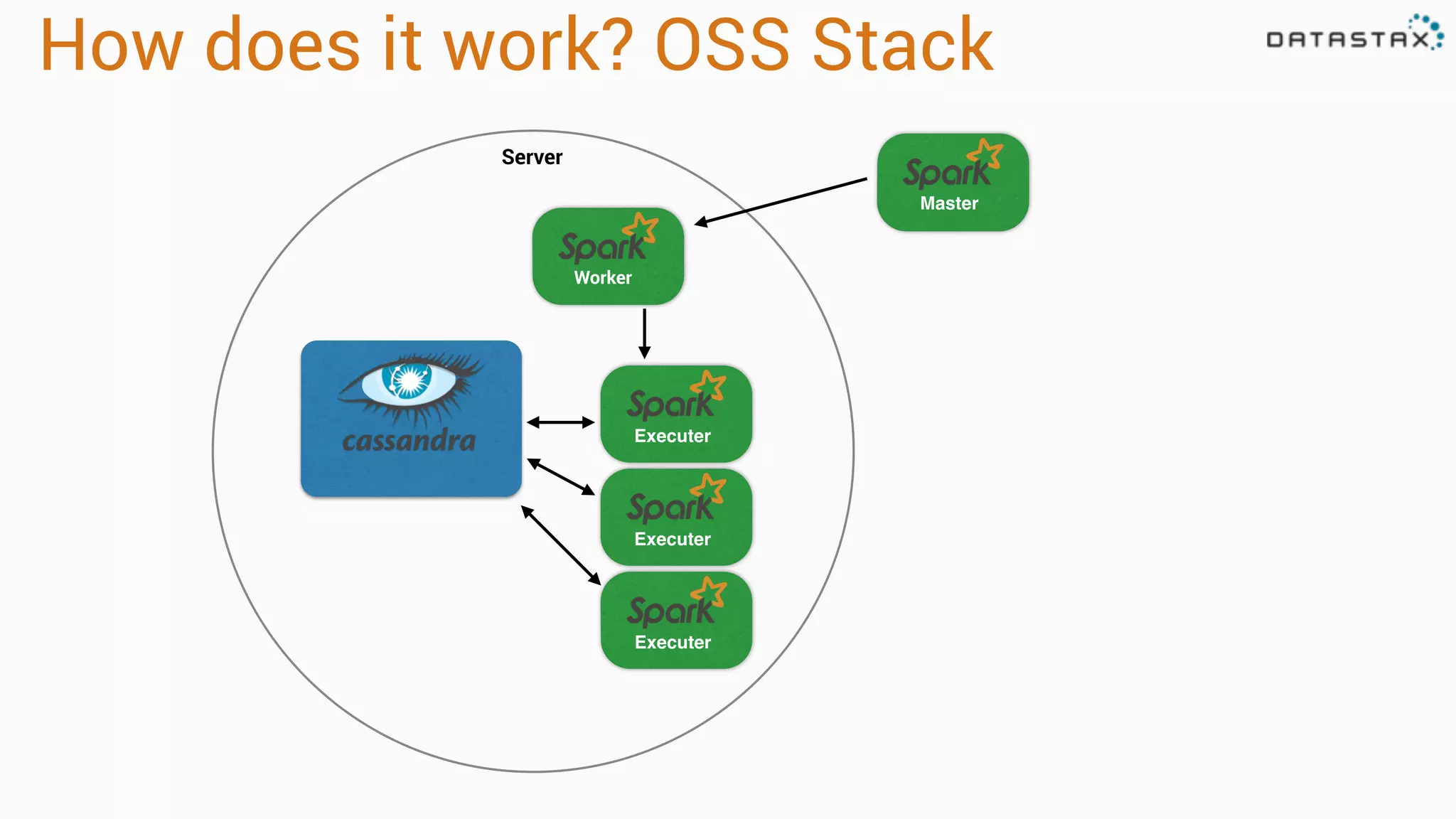
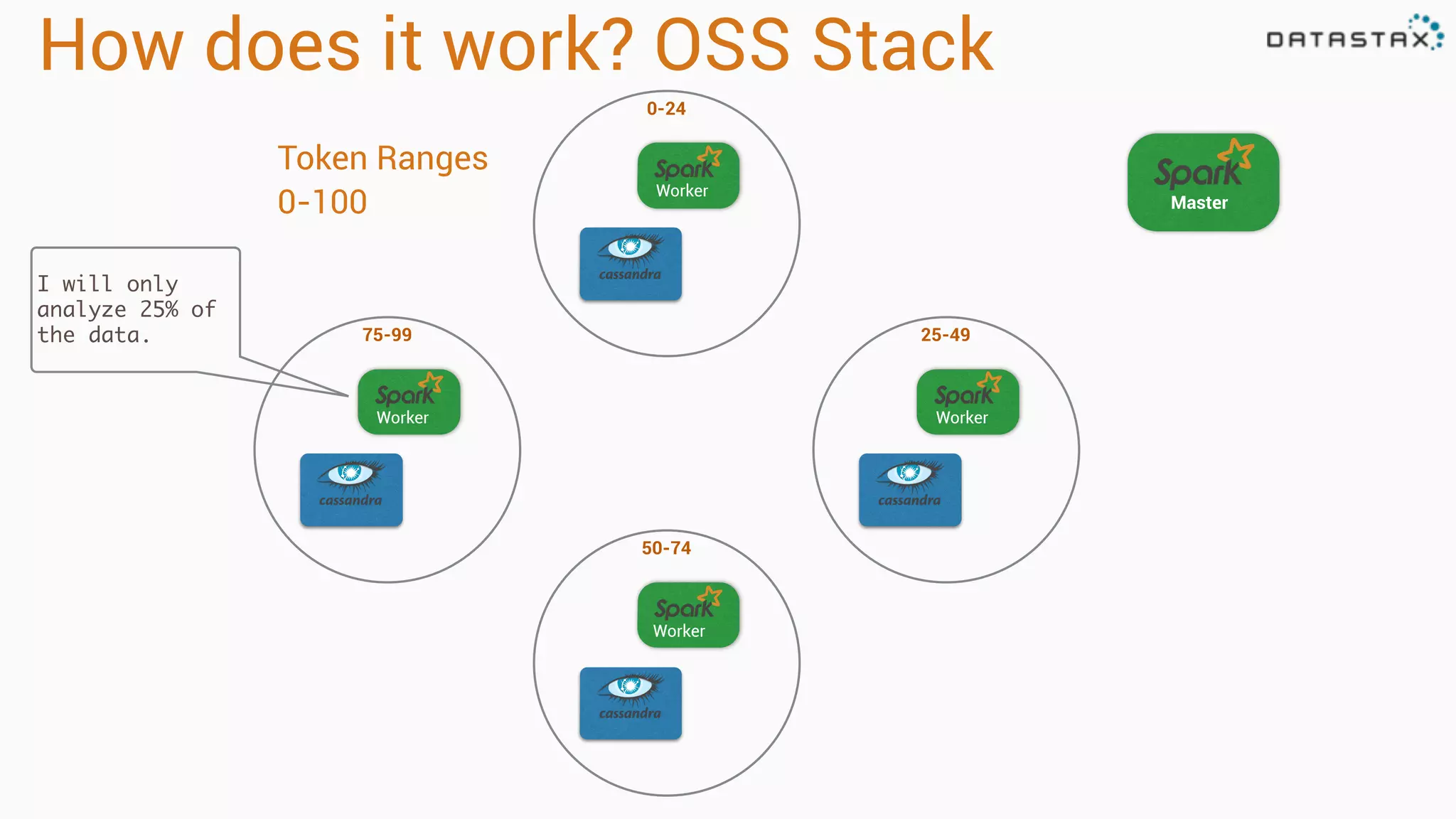
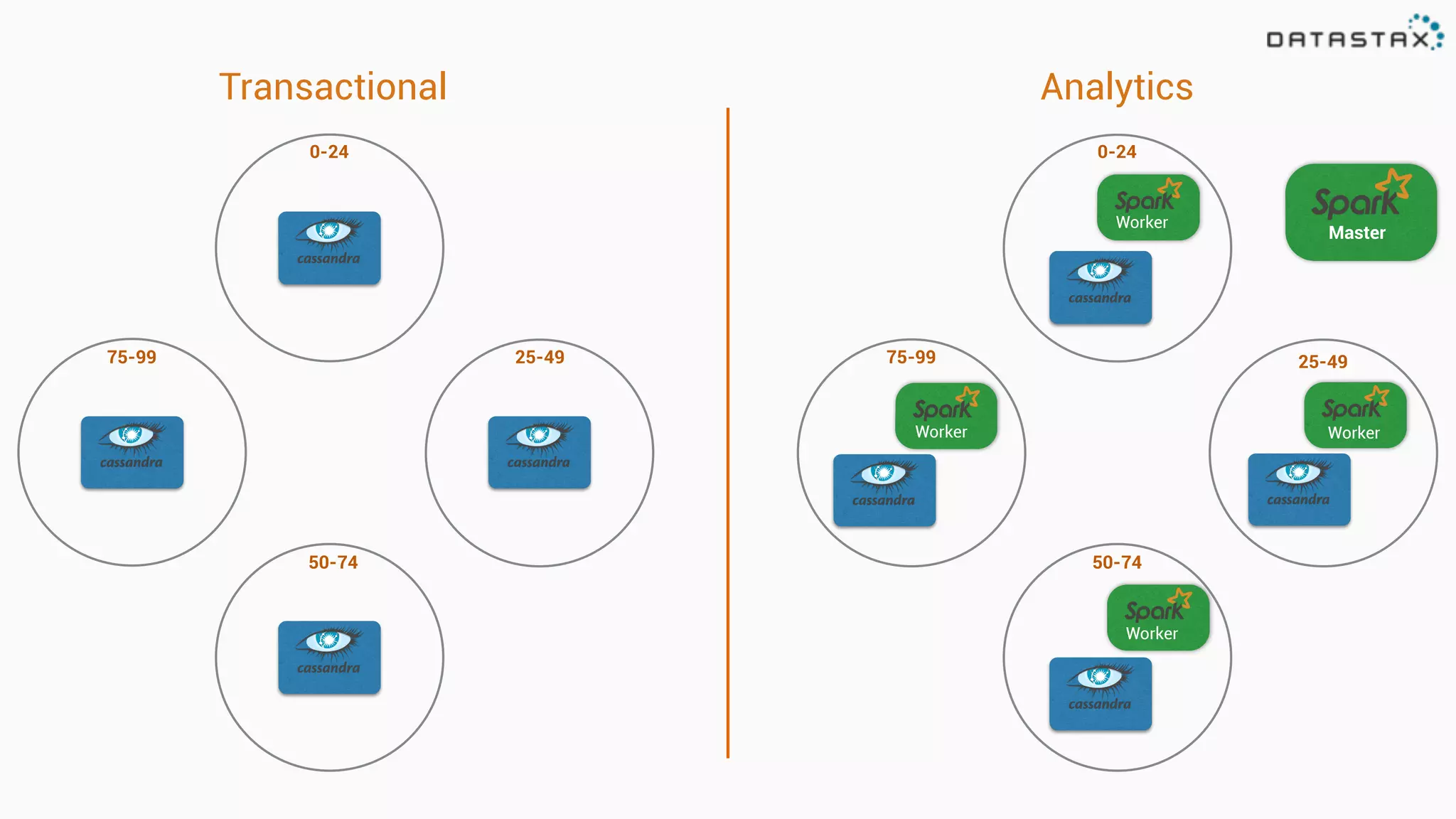
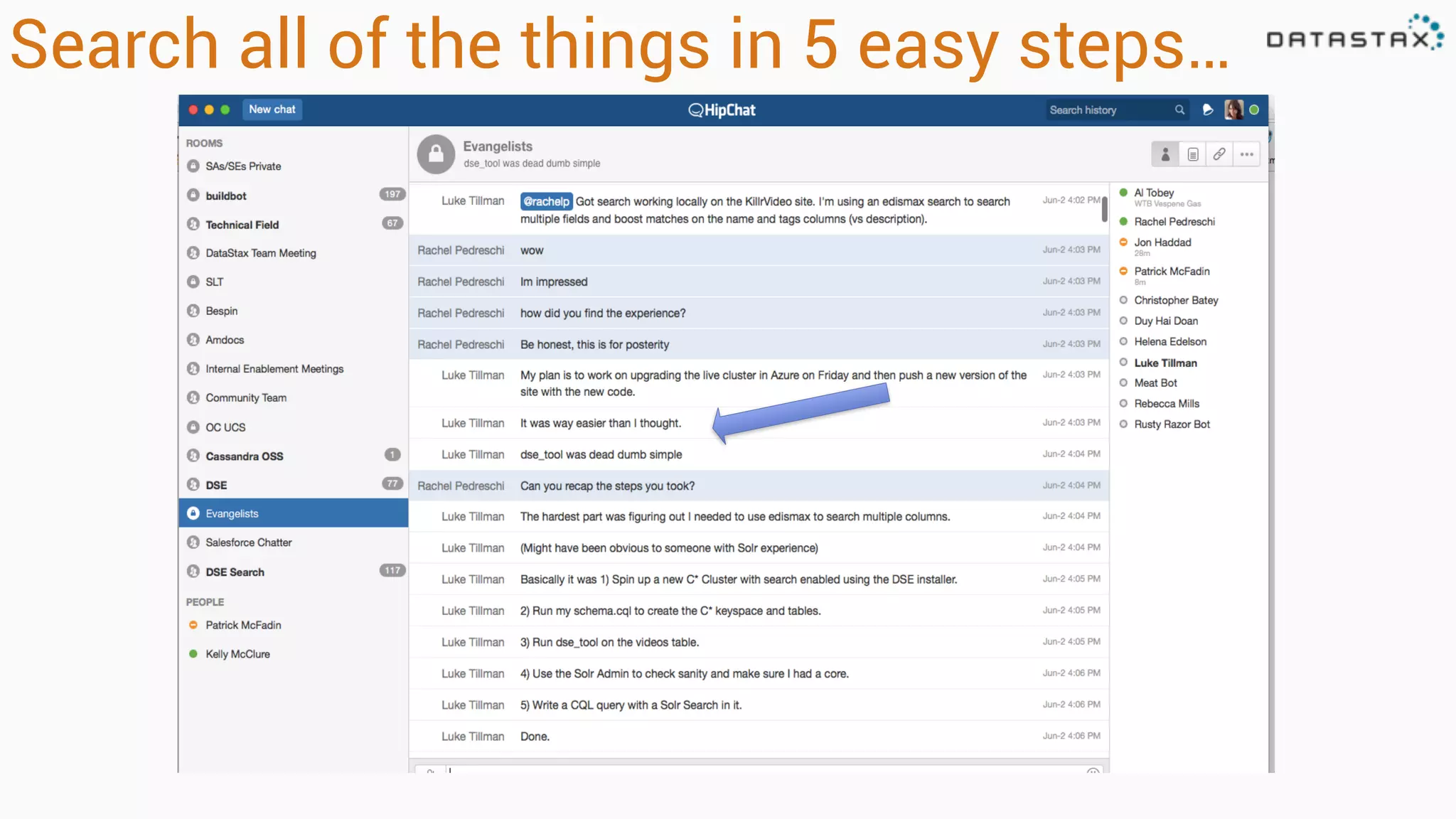
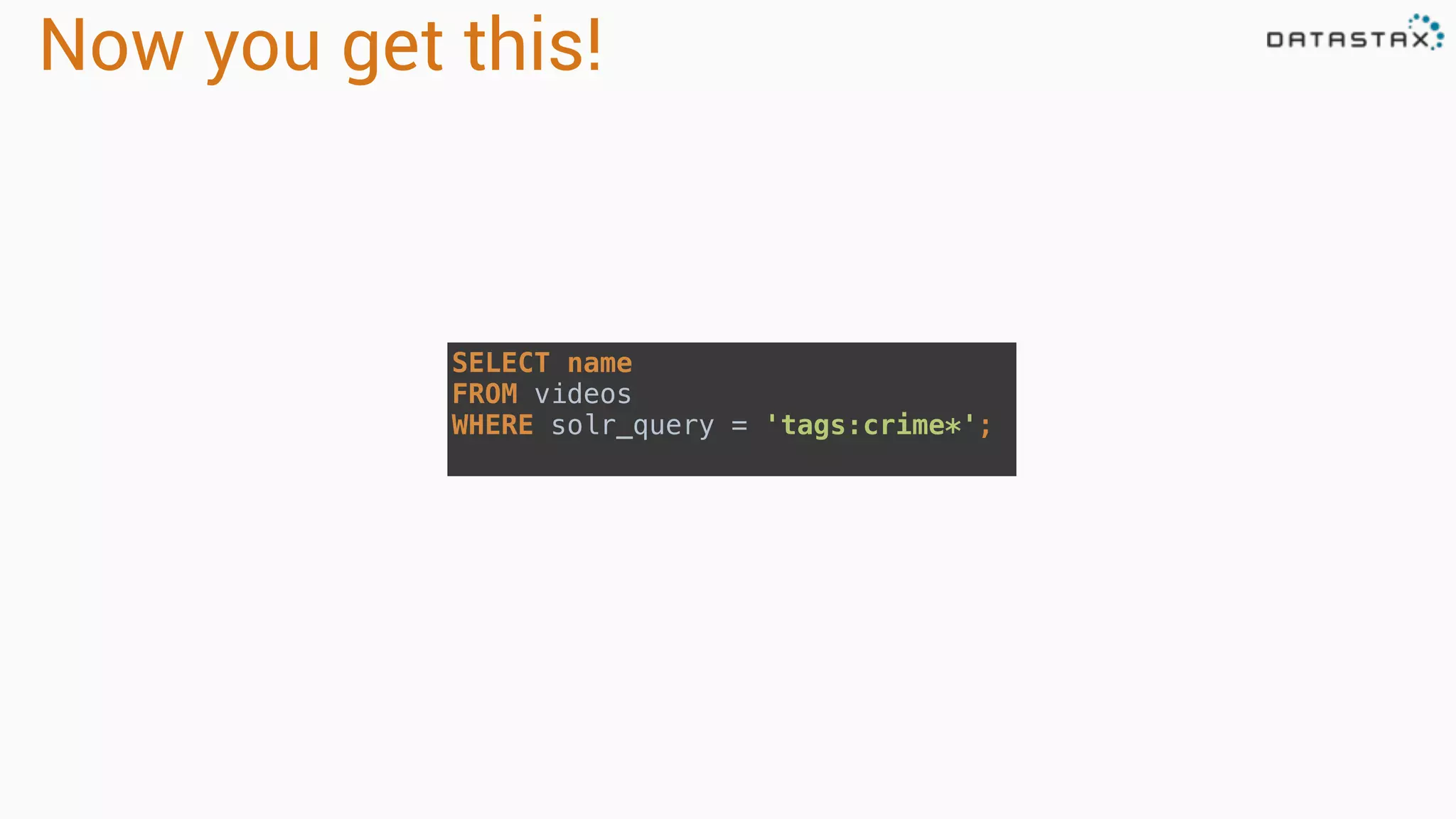
The document provides an overview of a technology stack that integrates Cassandra, Solr, and Spark for search and analytics applications. It explains how data is managed in a distributed system with a focus on high availability, scalability, and low latency queries. Additionally, it includes practical examples and code snippets demonstrating the setup and usage of this stack for handling large datasets and real-time processing.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











