Download as PDF, PPTX

























![RDD Operations
•Transformations - Similar to scala collections API
•Produce new RDDs
•filter, flatmap, map, distinct, groupBy, union, zip,
reduceByKey, subtract
•Actions
•Require materialization of the records to generate a value
•collect: Array[T], count, fold, reduce..](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-44-2048.jpg)

![Collections and Files To RDD
scala> val distData = sc.parallelize(Seq(1,2,3,4,5)
distData: spark.RDD[Int] = spark.ParallelCollection@10d13e3e
val distFile: RDD[String] = sc.textFile(“directory/*.txt”)
val distFile = sc.textFile(“hdfs://namenode:9000/path/file”)
val distFile = sc.sequenceFile(“hdfs://namenode:9000/path/file”)](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-47-2048.jpg)






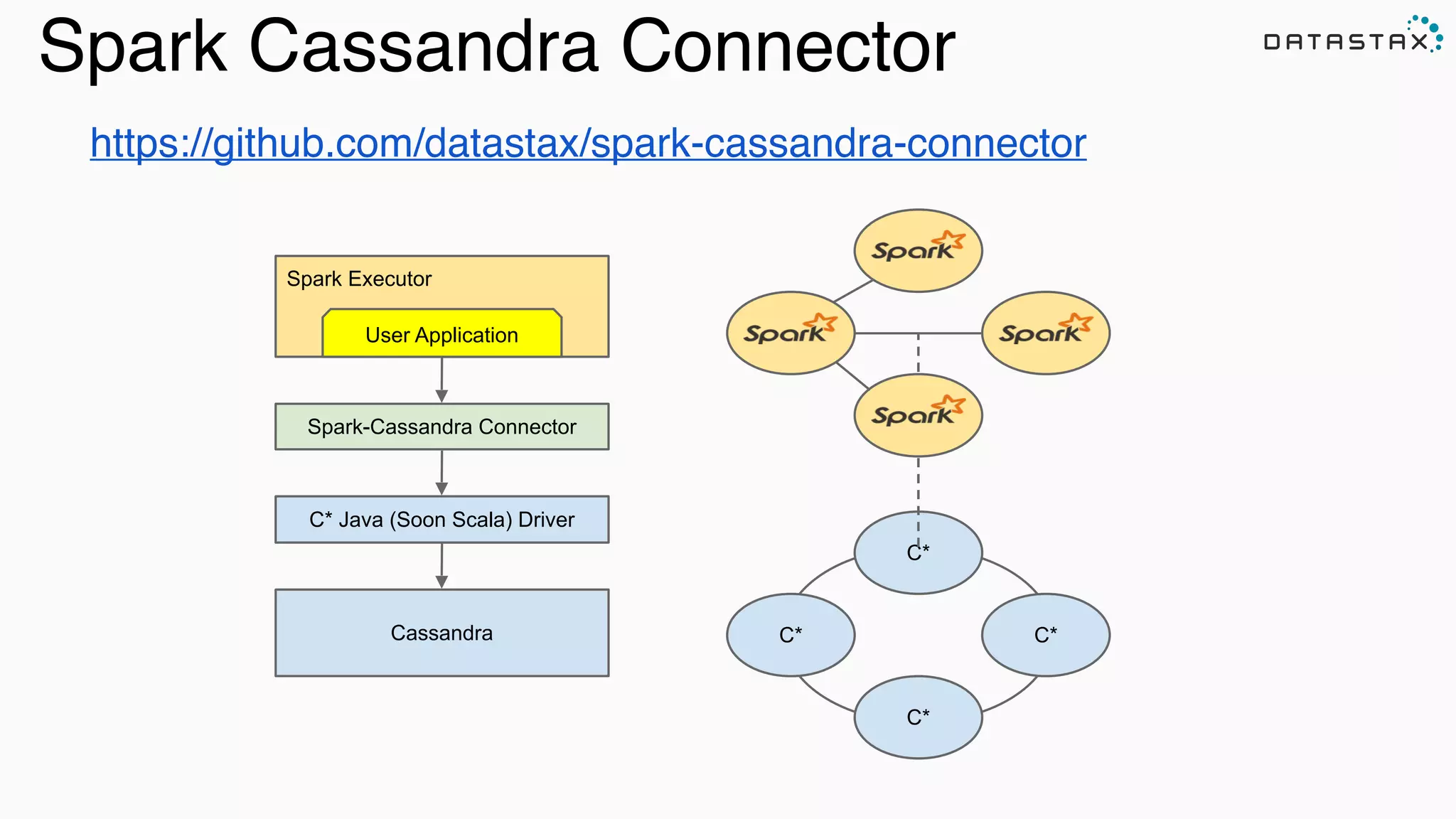
![Spark Cassandra Example
val conf = new SparkConf(loadDefaults = true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster("spark://127.0.0.1:7077")
val sc = new SparkContext(conf)
val table: CassandraRDD[CassandraRow] = sc.cassandraTable("keyspace", "tweets")
val ssc = new StreamingContext(sc, Seconds(30))
val stream = KafkaUtils.createStream[String, String, StringDecoder,
StringDecoder](
ssc, kafka.kafkaParams, Map(topic -> 1), StorageLevel.MEMORY_ONLY)
stream.map(_._2).countByValue().saveToCassandra("demo", "wordcount")
ssc.start()
ssc.awaitTermination()
Initialization
Transformations
and Action
CassandraRDD
Stream Initialization](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-60-2048.jpg)


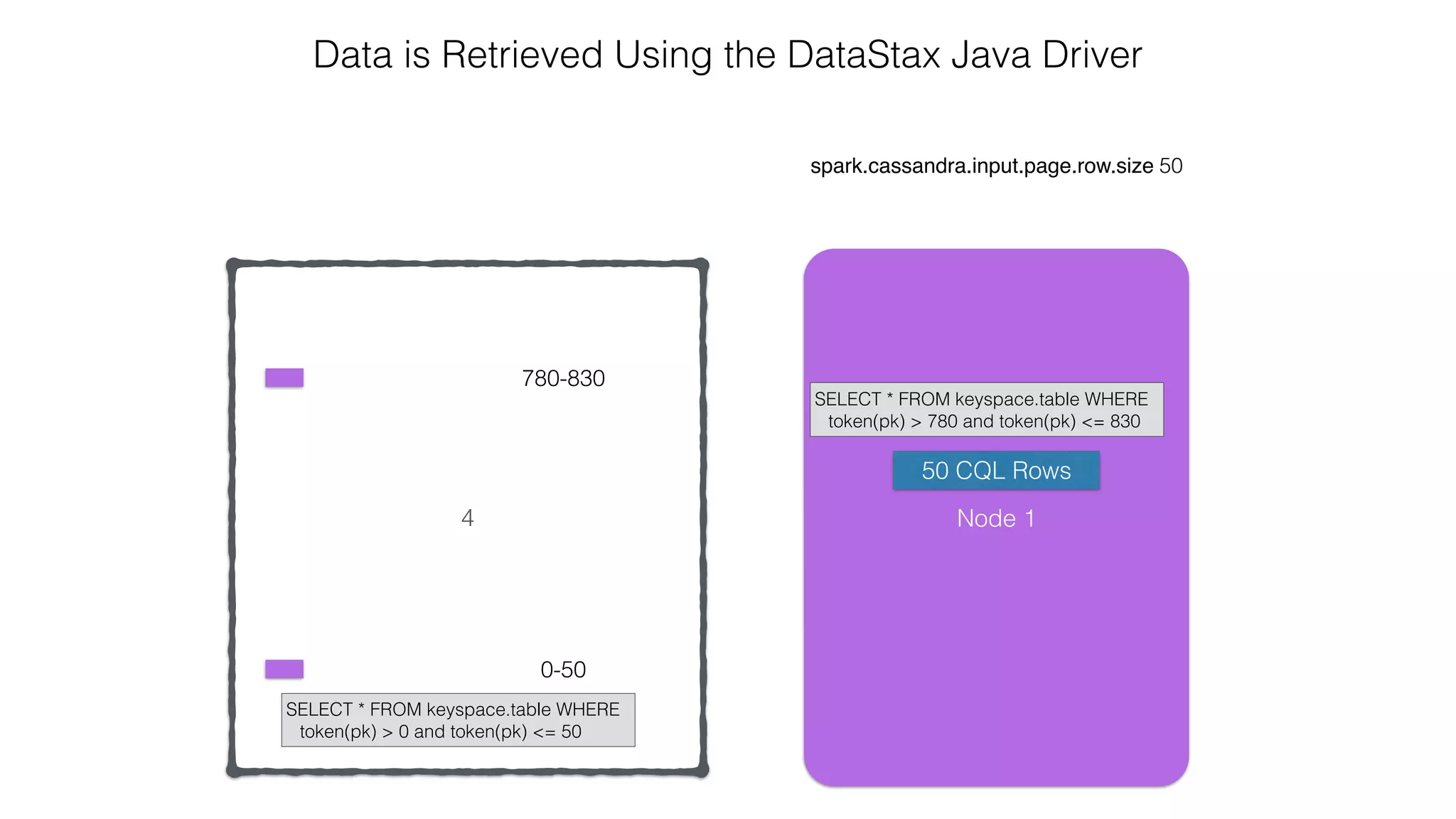
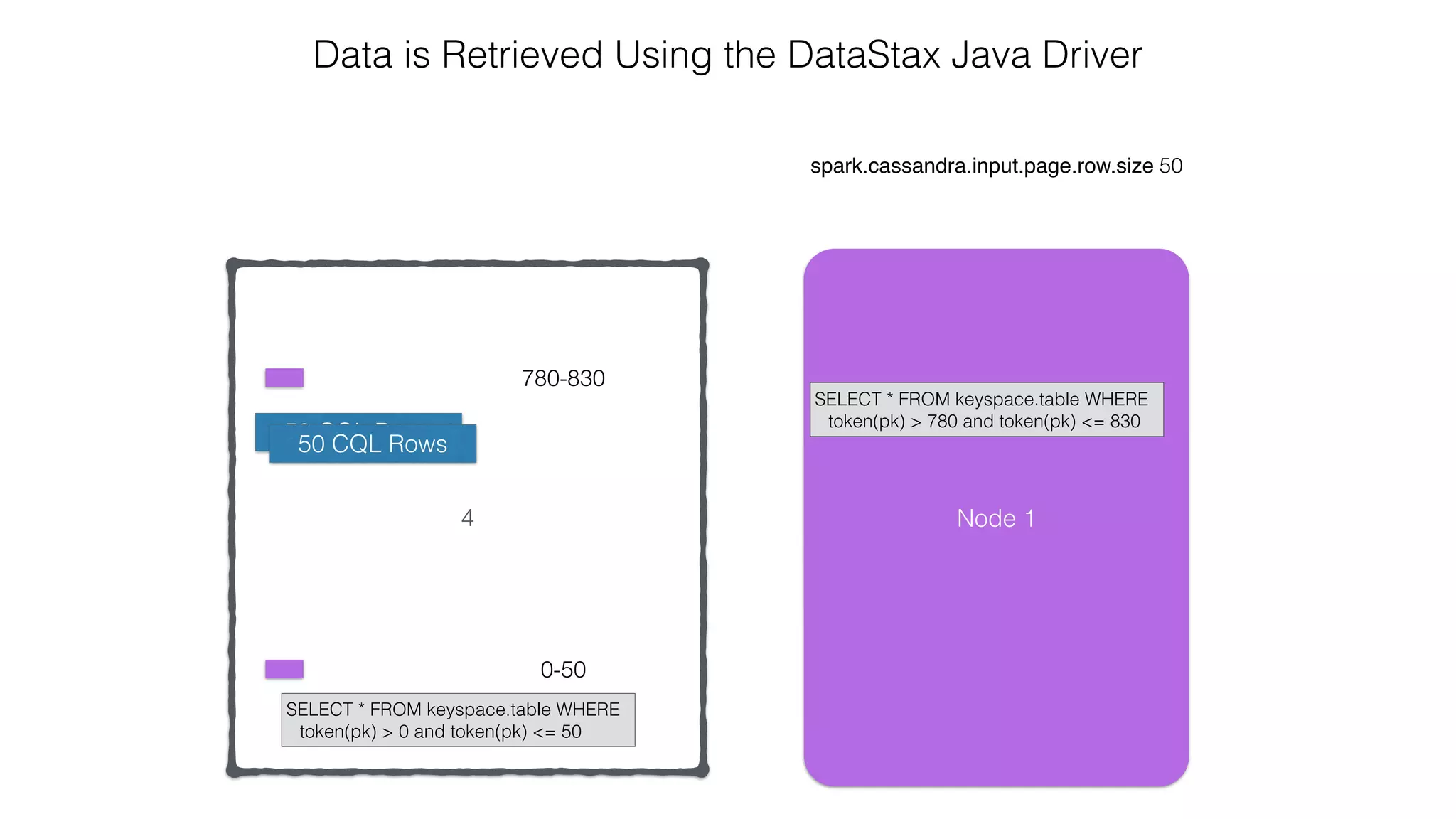
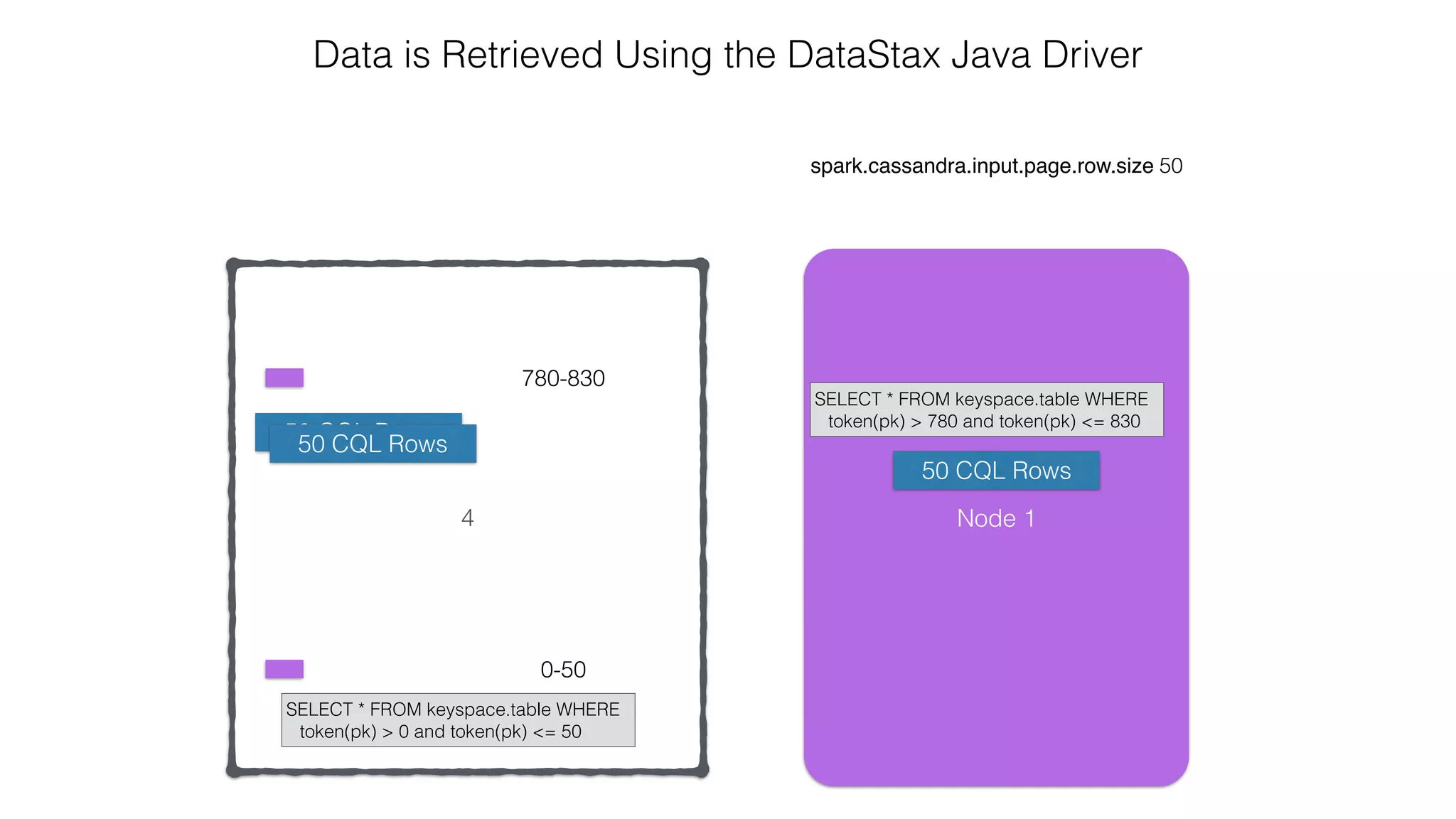
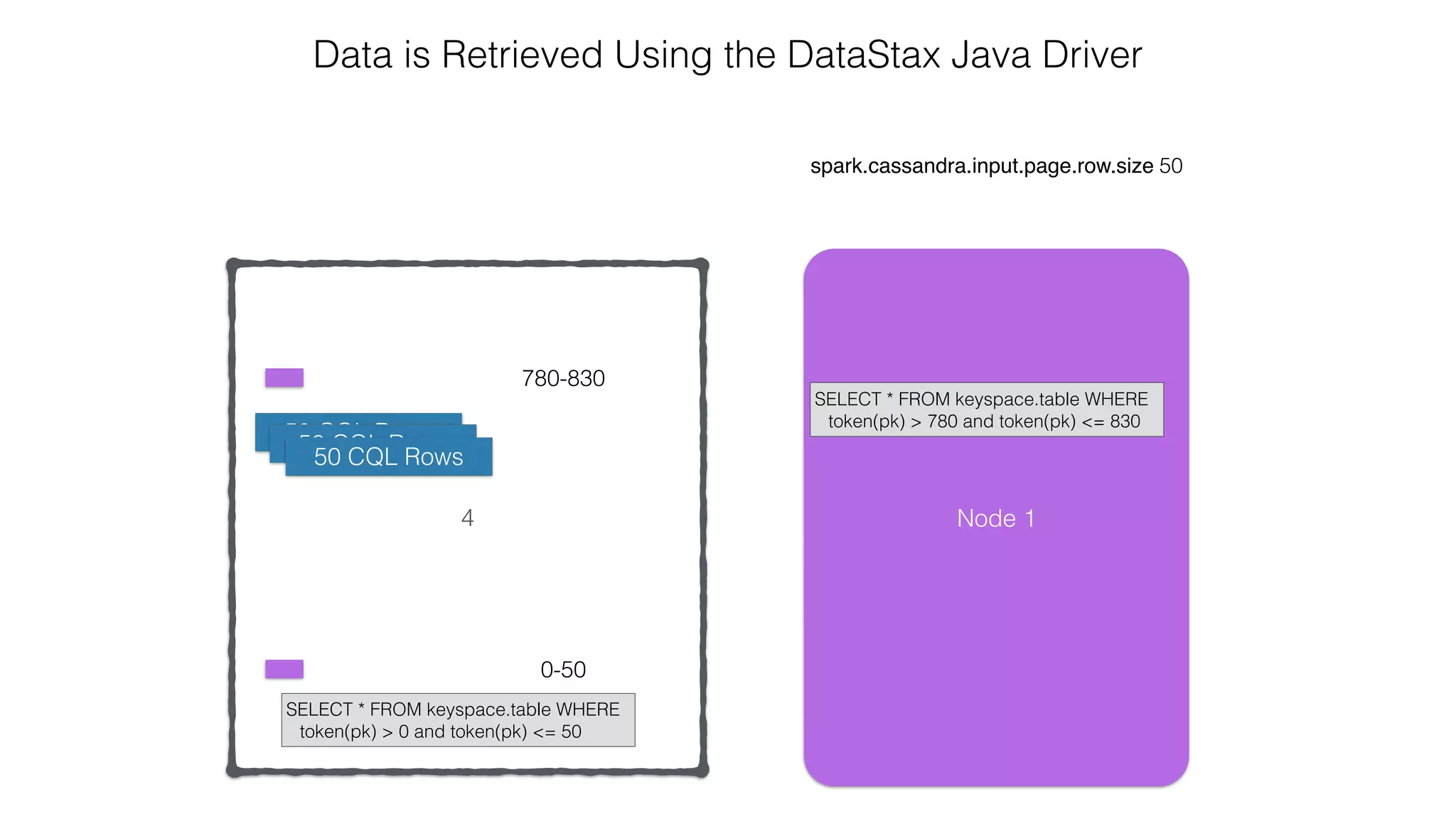
.select("user_name", "message")
.where("user_name = ?", "ewa")
row
representation keyspace table
server side
column and row
selection
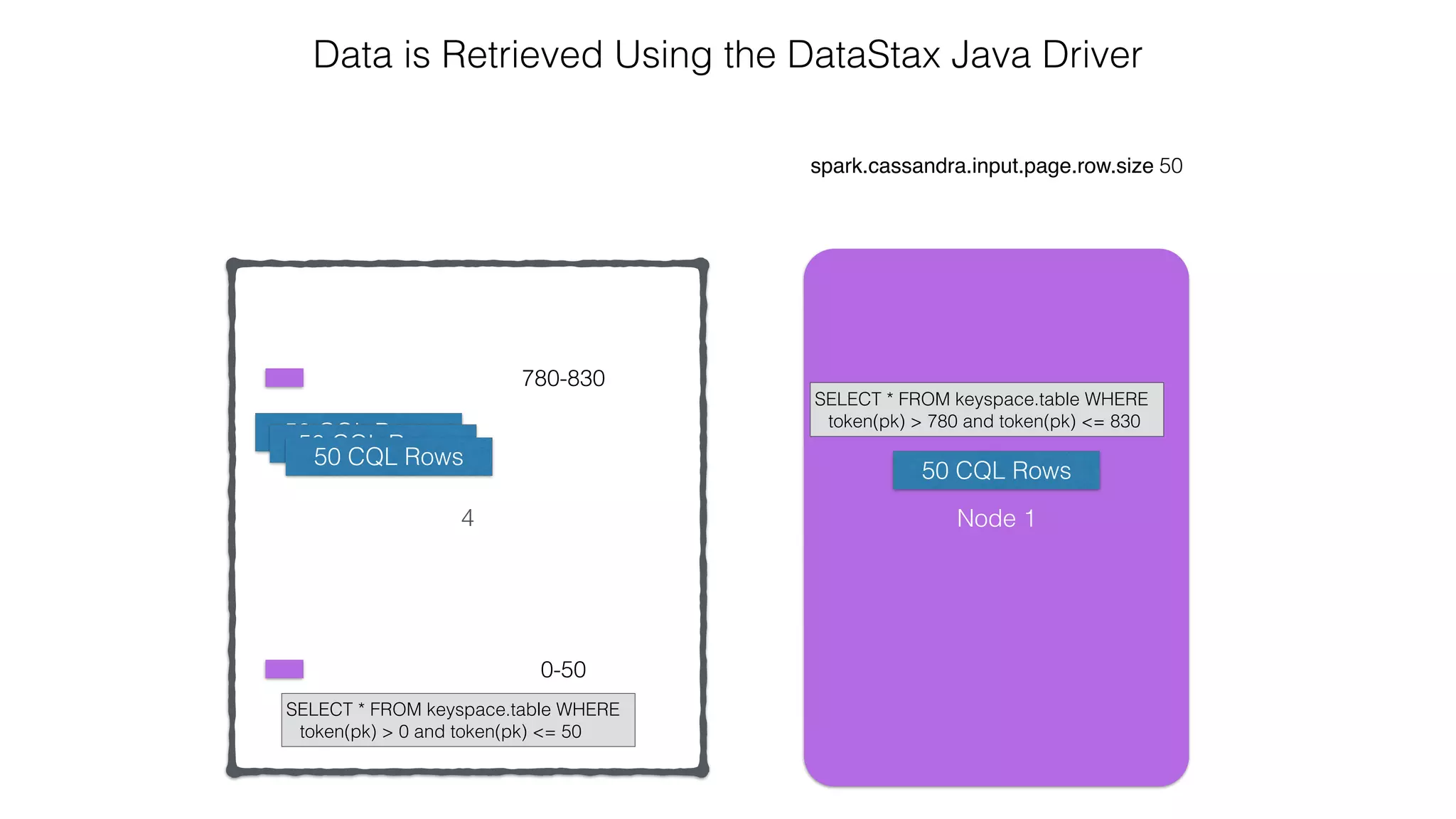
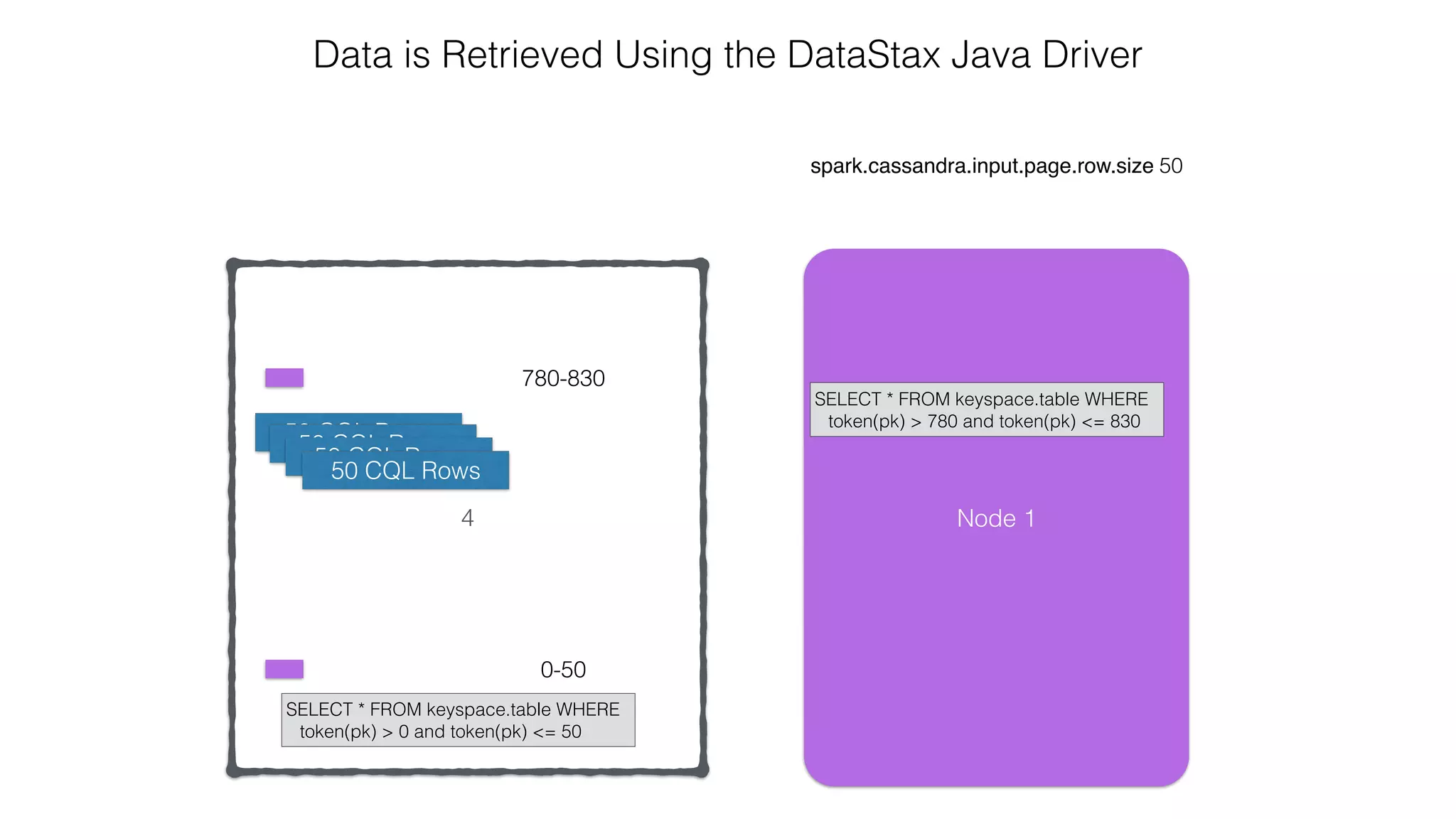
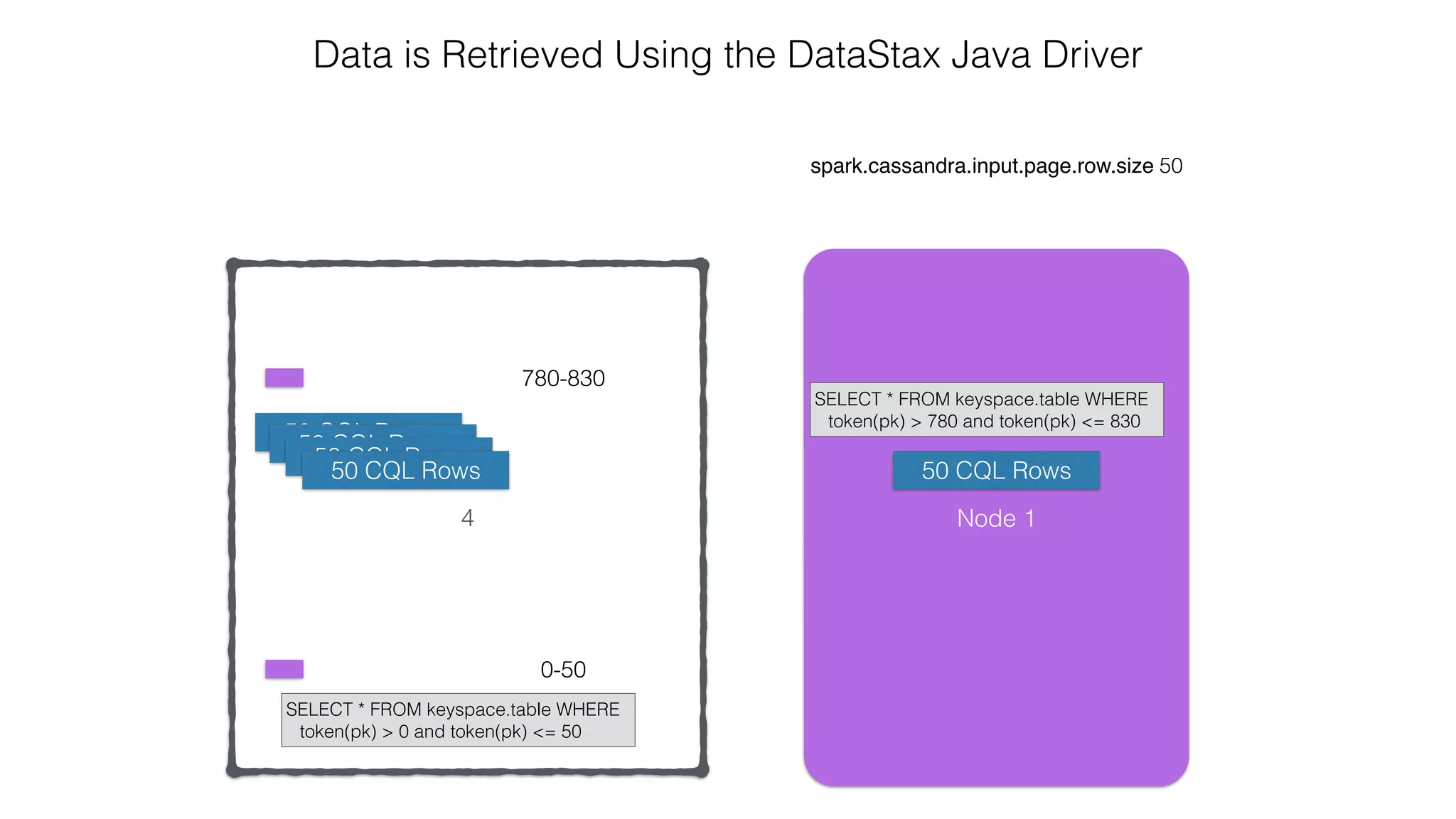
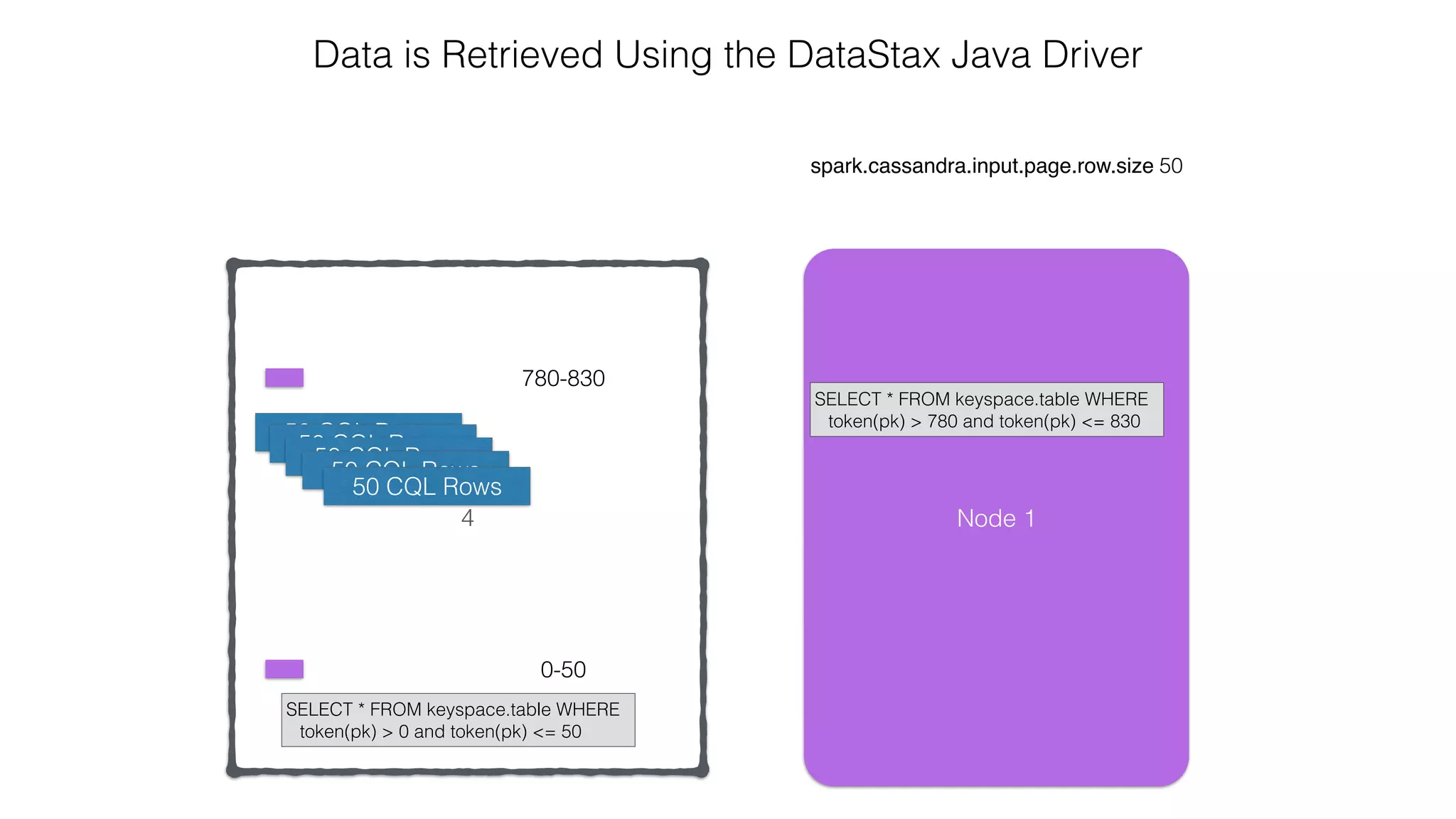
Reading: From C* To Spark](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-62-2048.jpg)

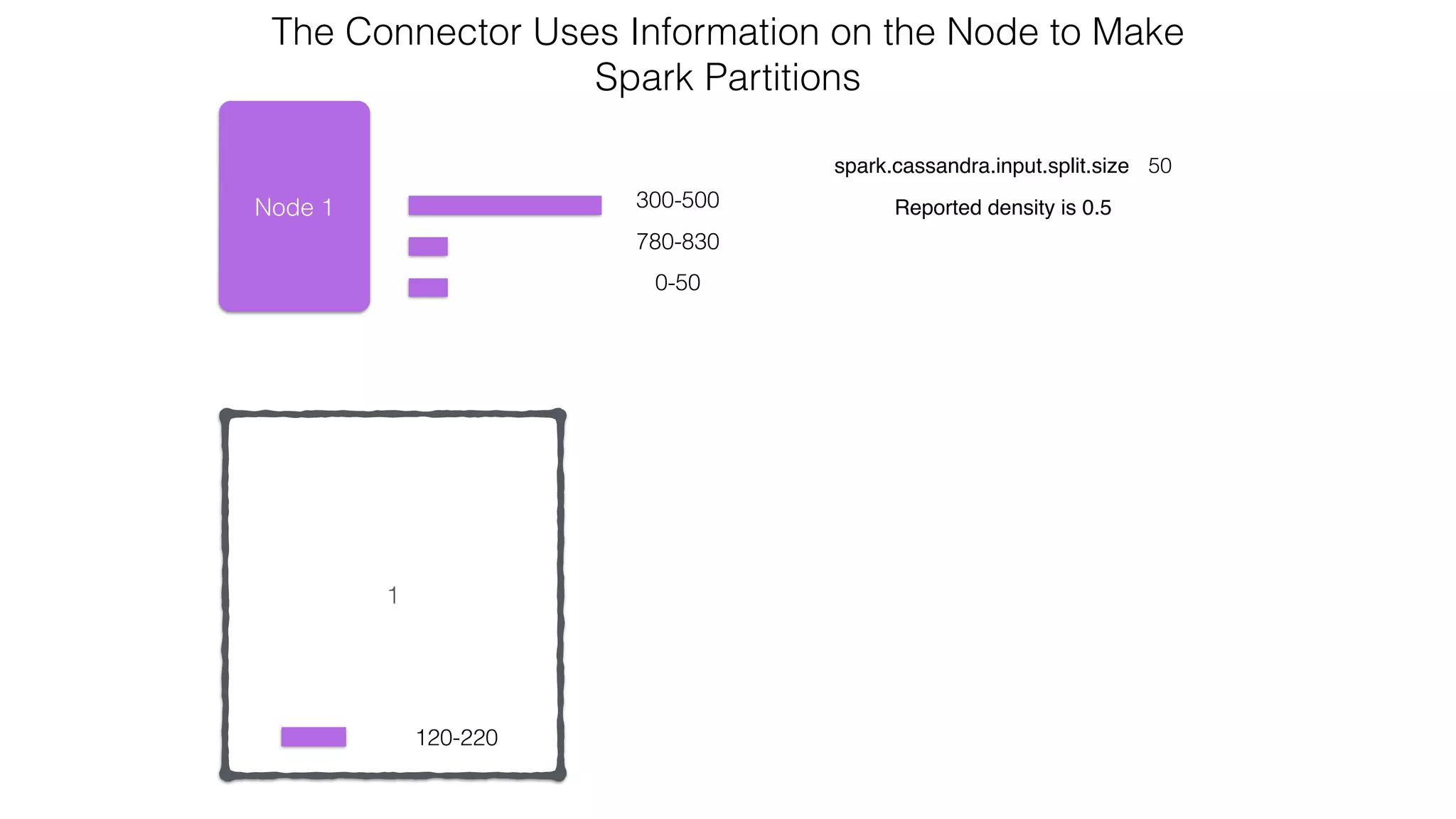
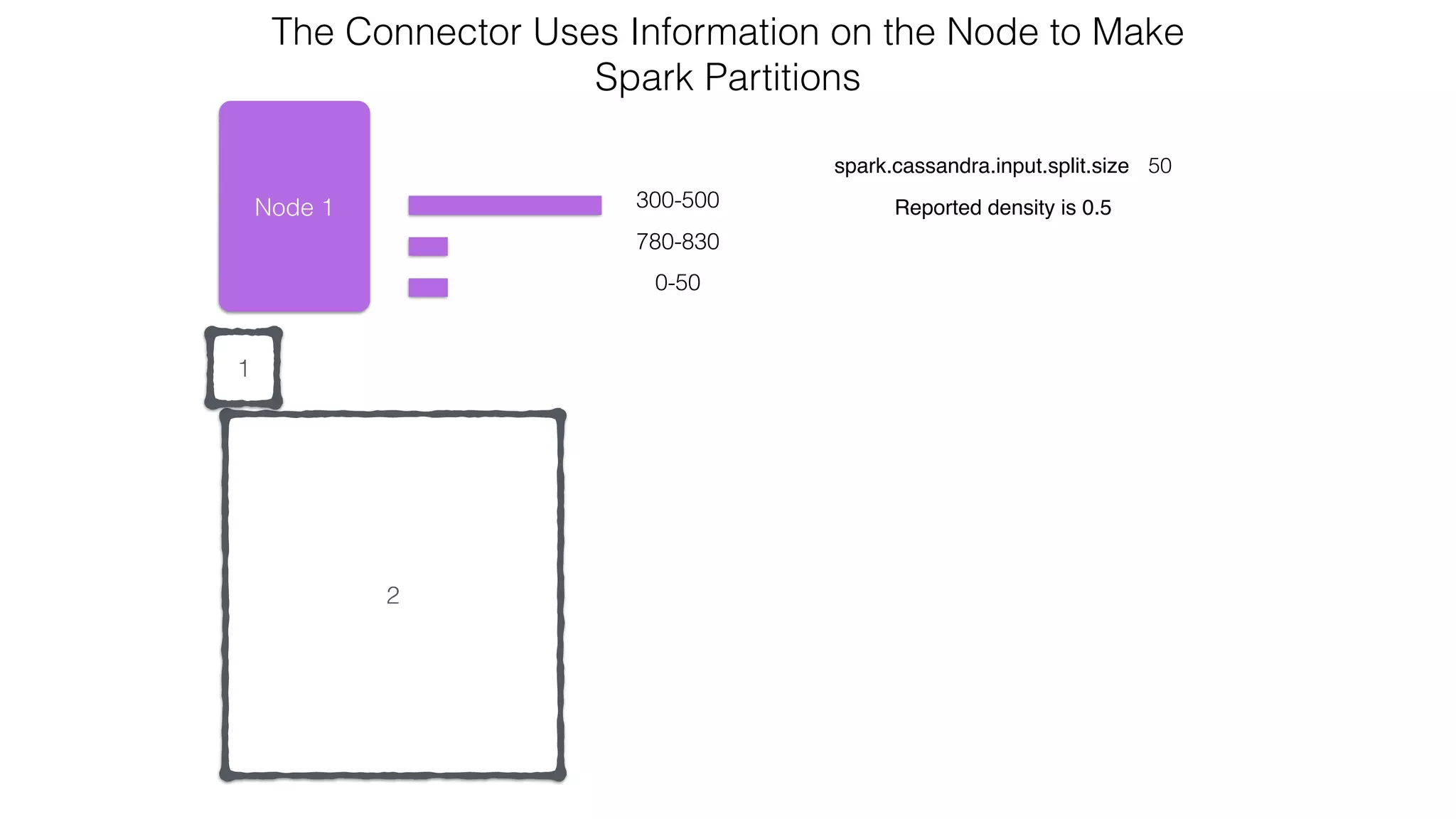
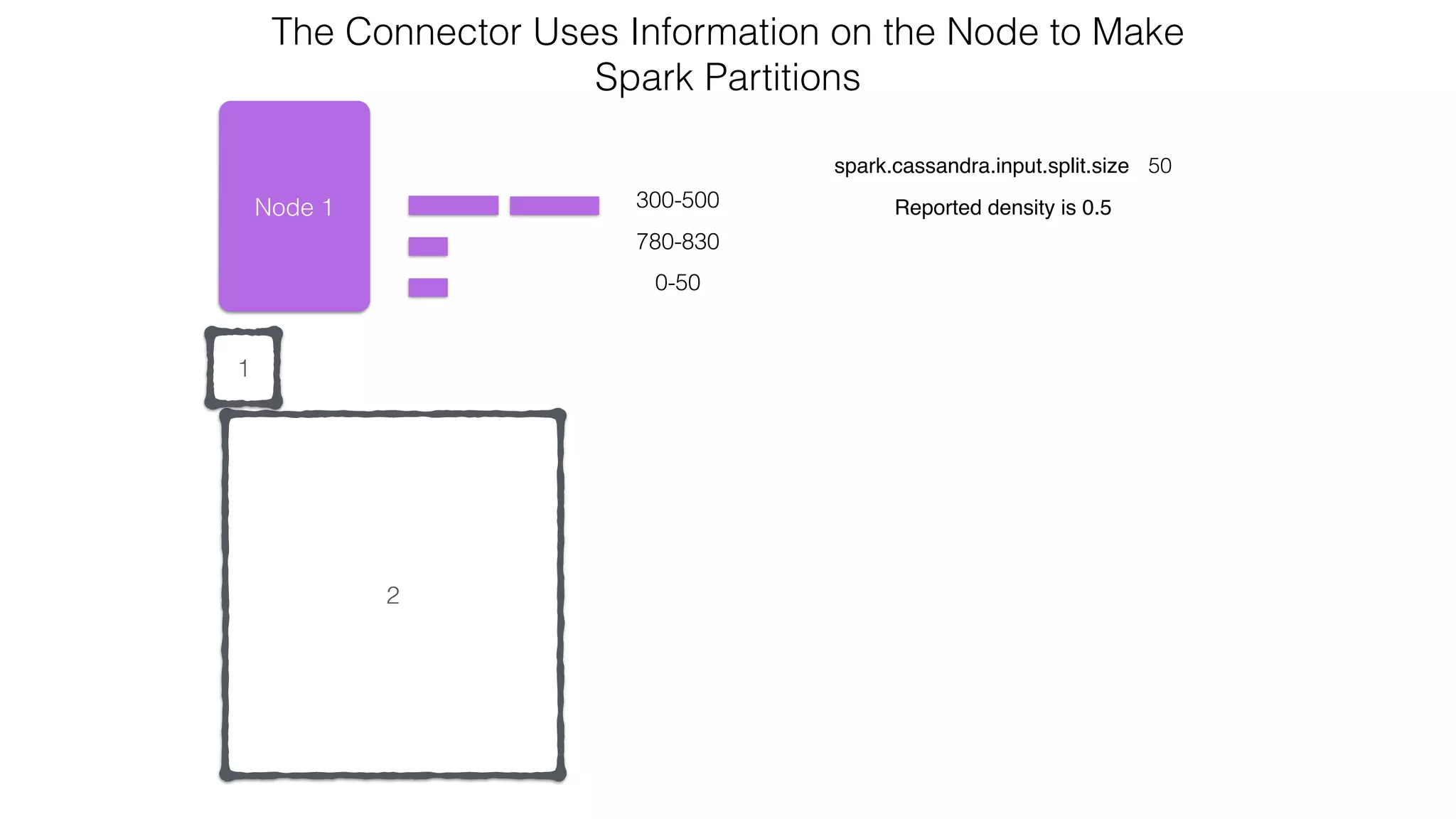
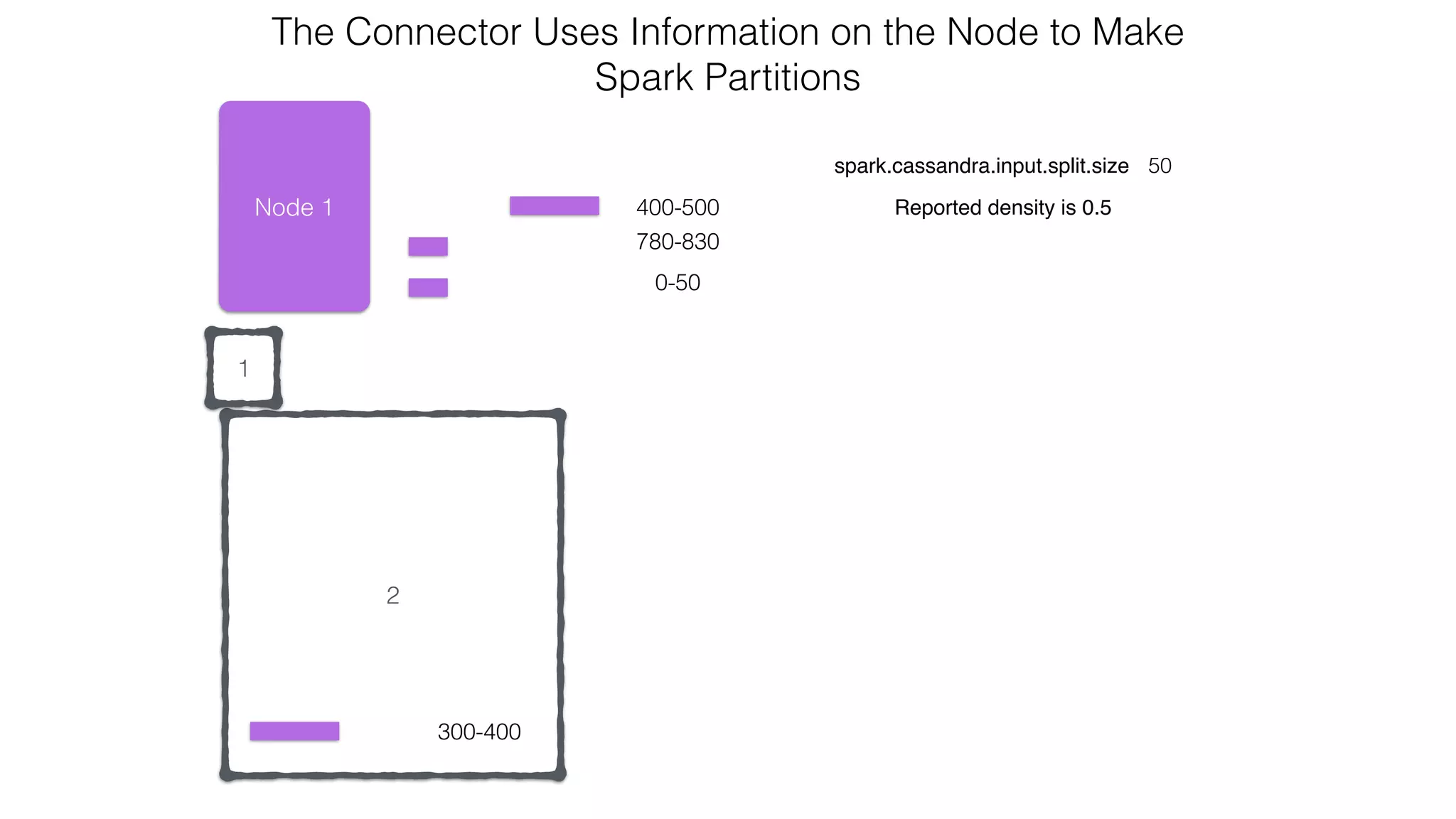
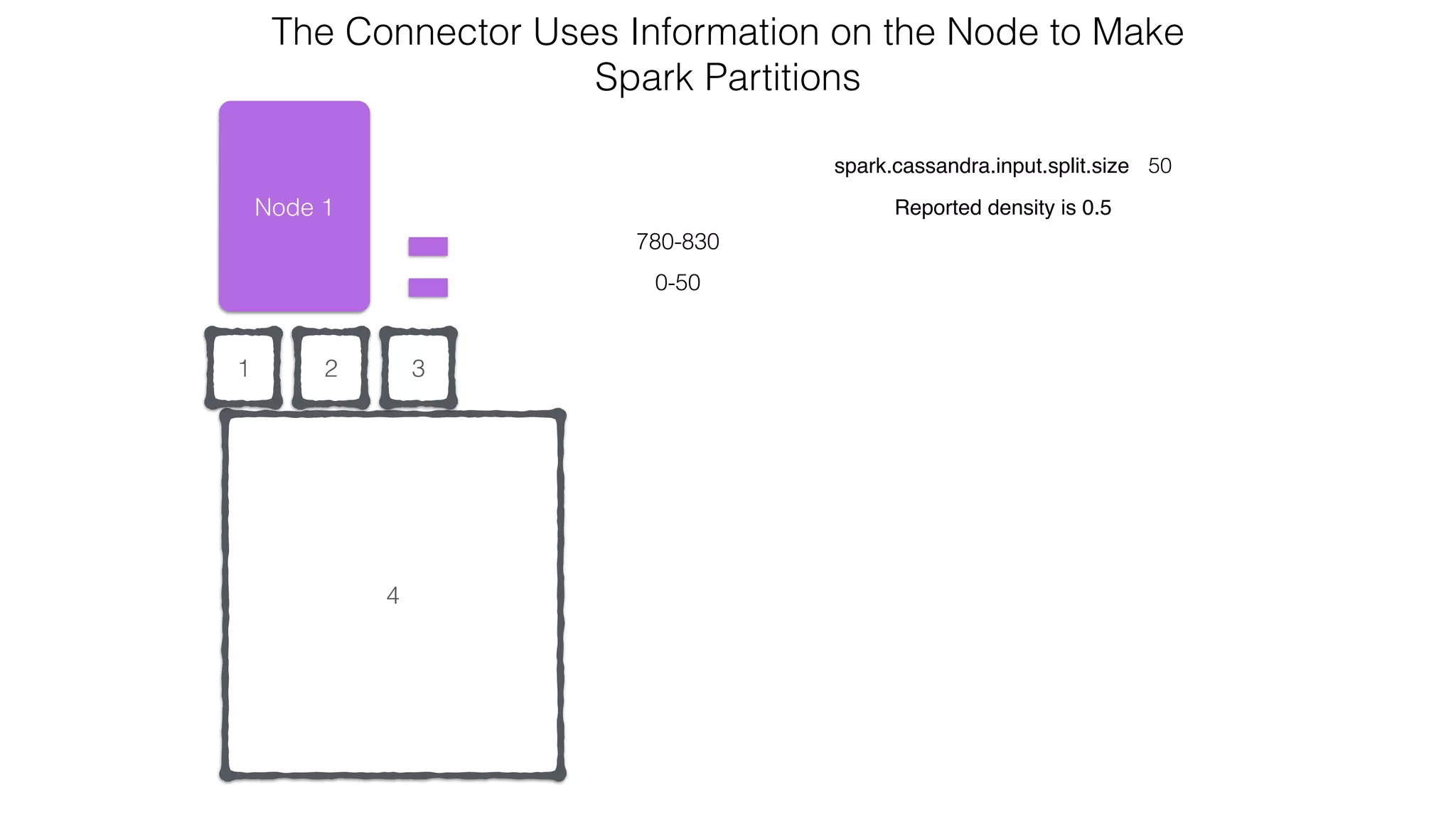
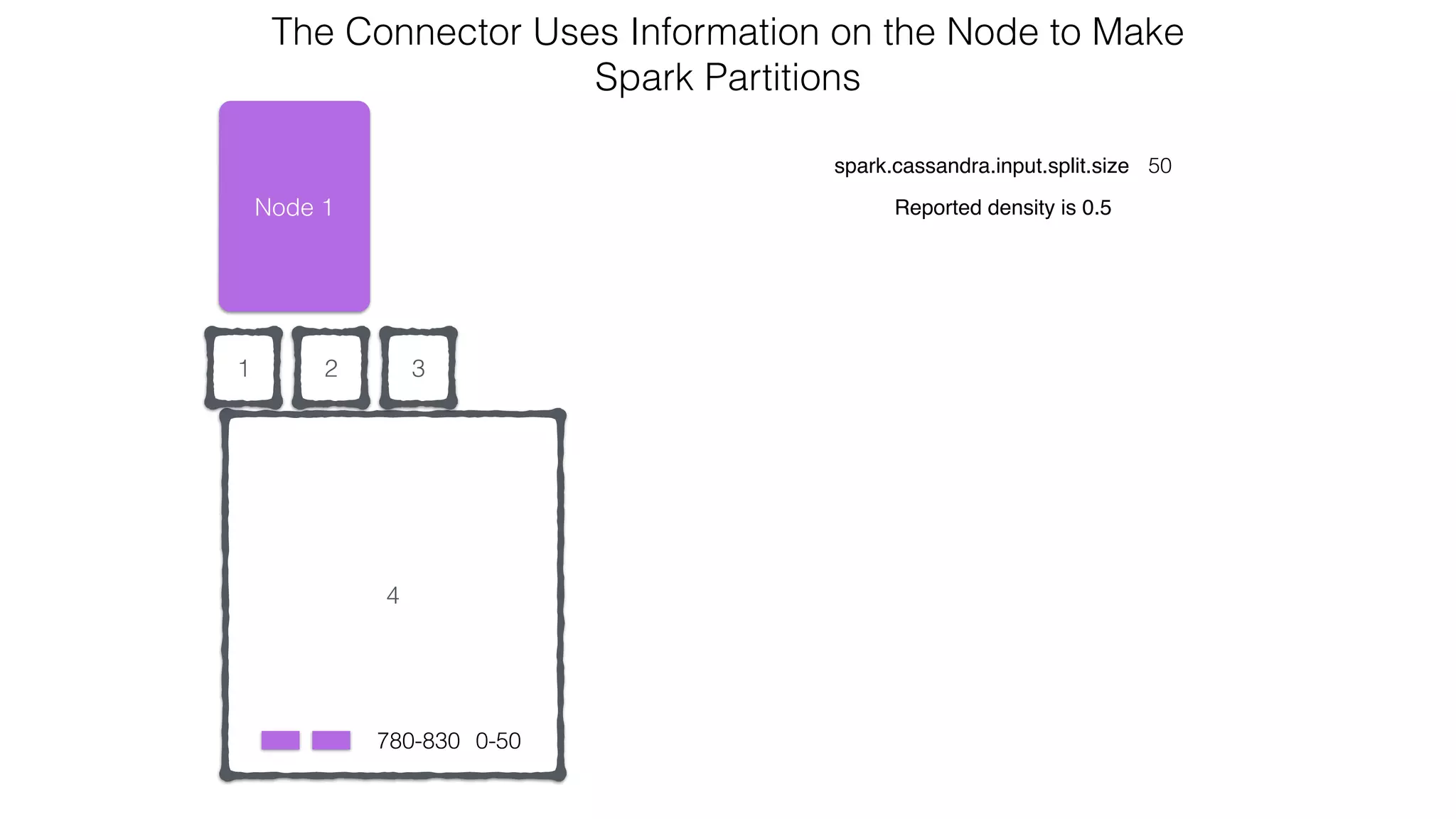
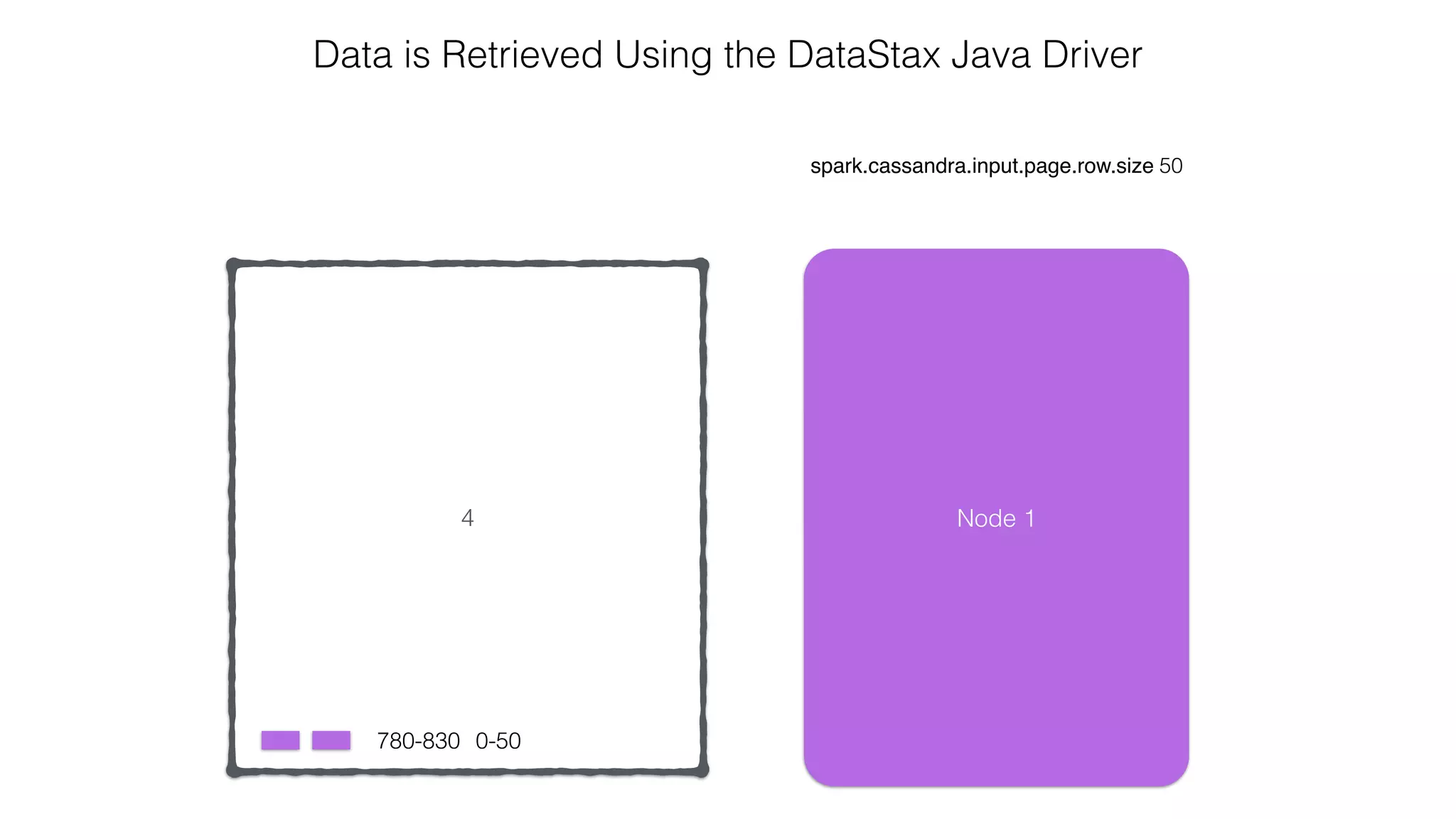
extends RDD[R](...) {
// Splits the table into multiple Spark partitions,
// each processed by single Spark Task
override def getPartitions: Array[Partition]
// Returns names of hosts storing given partition (for data locality!)
override def getPreferredLocations(split: Partition): Seq[String]
// Returns iterator over Cassandra rows in the given partition
override def compute(split: Partition, context: TaskContext): Iterator[R]
}
CassandraRDD](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-63-2048.jpg)
![/** RDD representing a Cassandra table for Spark Streaming.
* @see [[com.datastax.spark.connector.rdd.CassandraRDD]]
*/
class CassandraStreamingRDD[R] private[connector] (
sctx: StreamingContext,
connector: CassandraConnector,
keyspace: String,
table: String,
columns: ColumnSelector = AllColumns,
where: CqlWhereClause = CqlWhereClause.empty,
readConf: ReadConf = ReadConf())(
implicit ct : ClassTag[R], @transient rrf: RowReaderFactory[R])
extends CassandraRDD[R](sctx.sparkContext, connector, keyspace, table, columns, where, readConf)
CassandraStreamingRDD](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-64-2048.jpg)




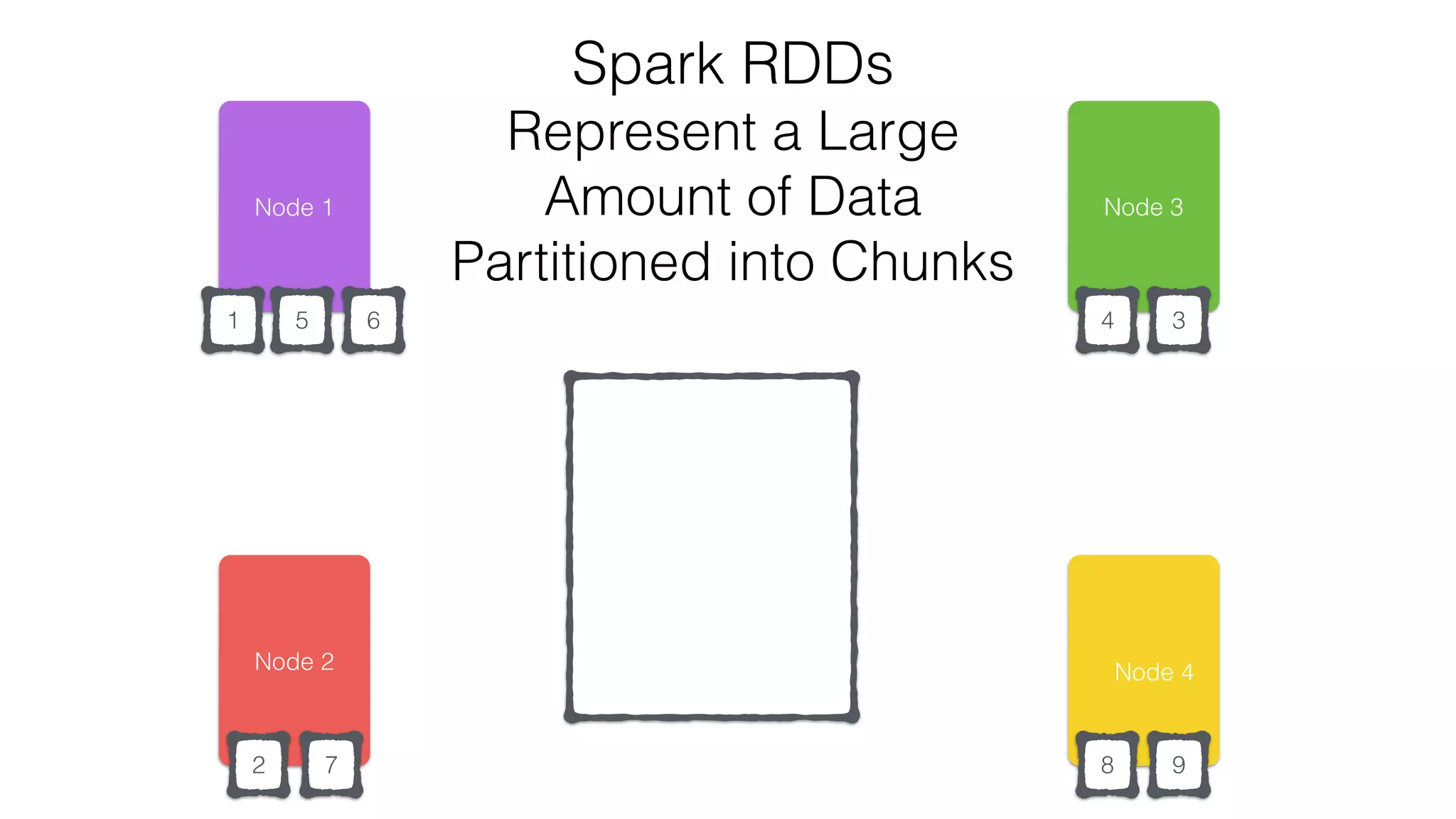

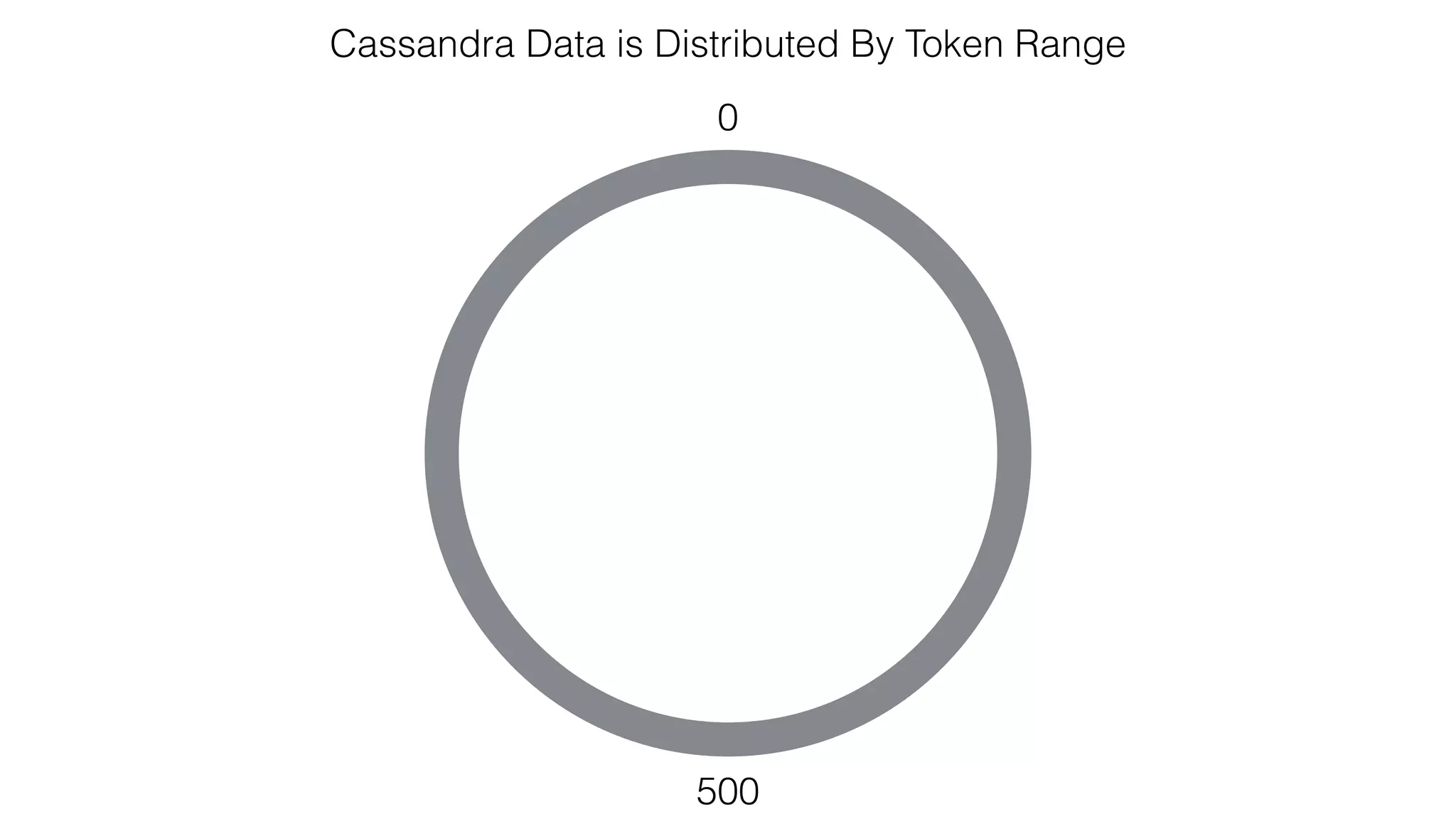
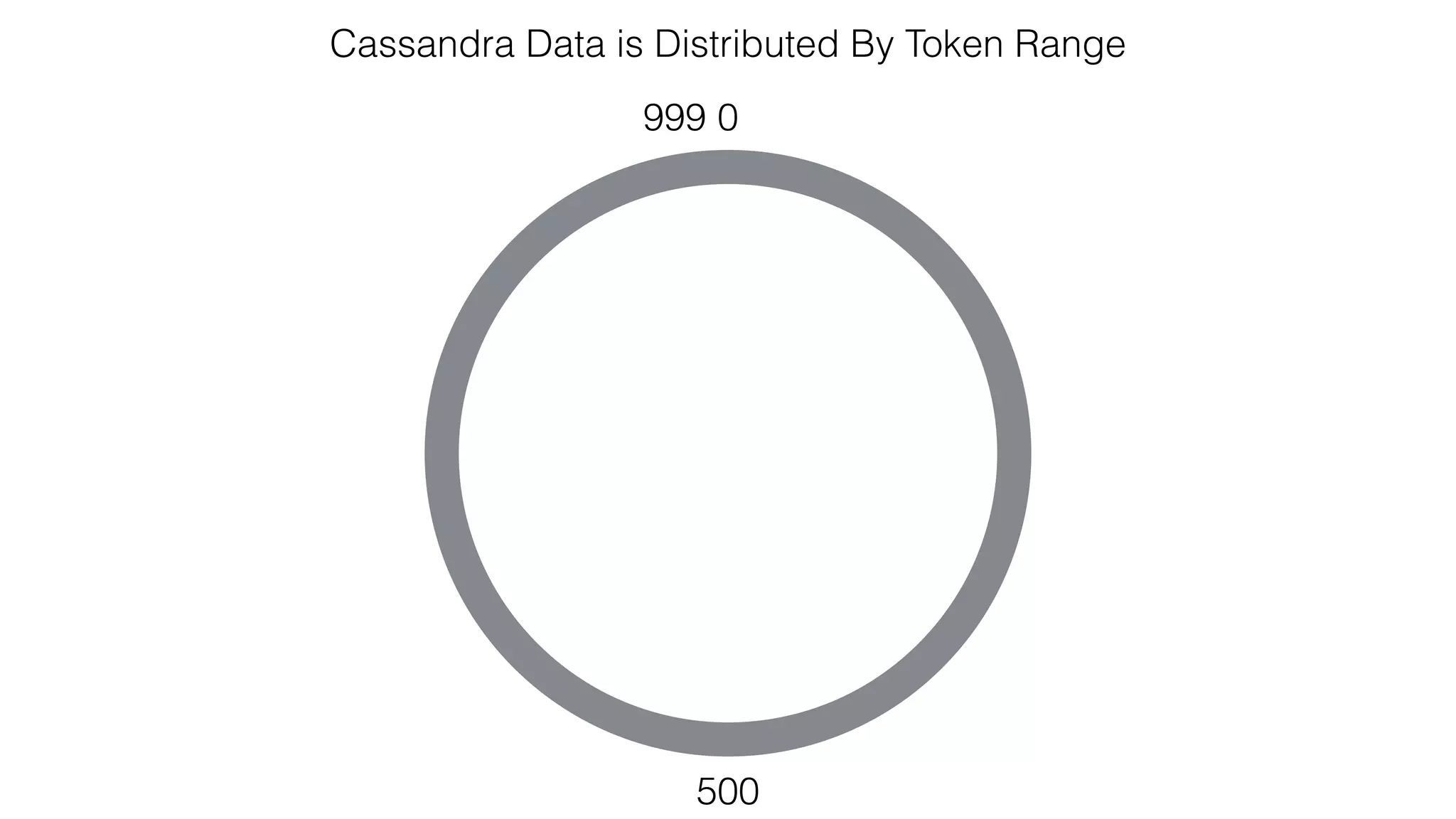
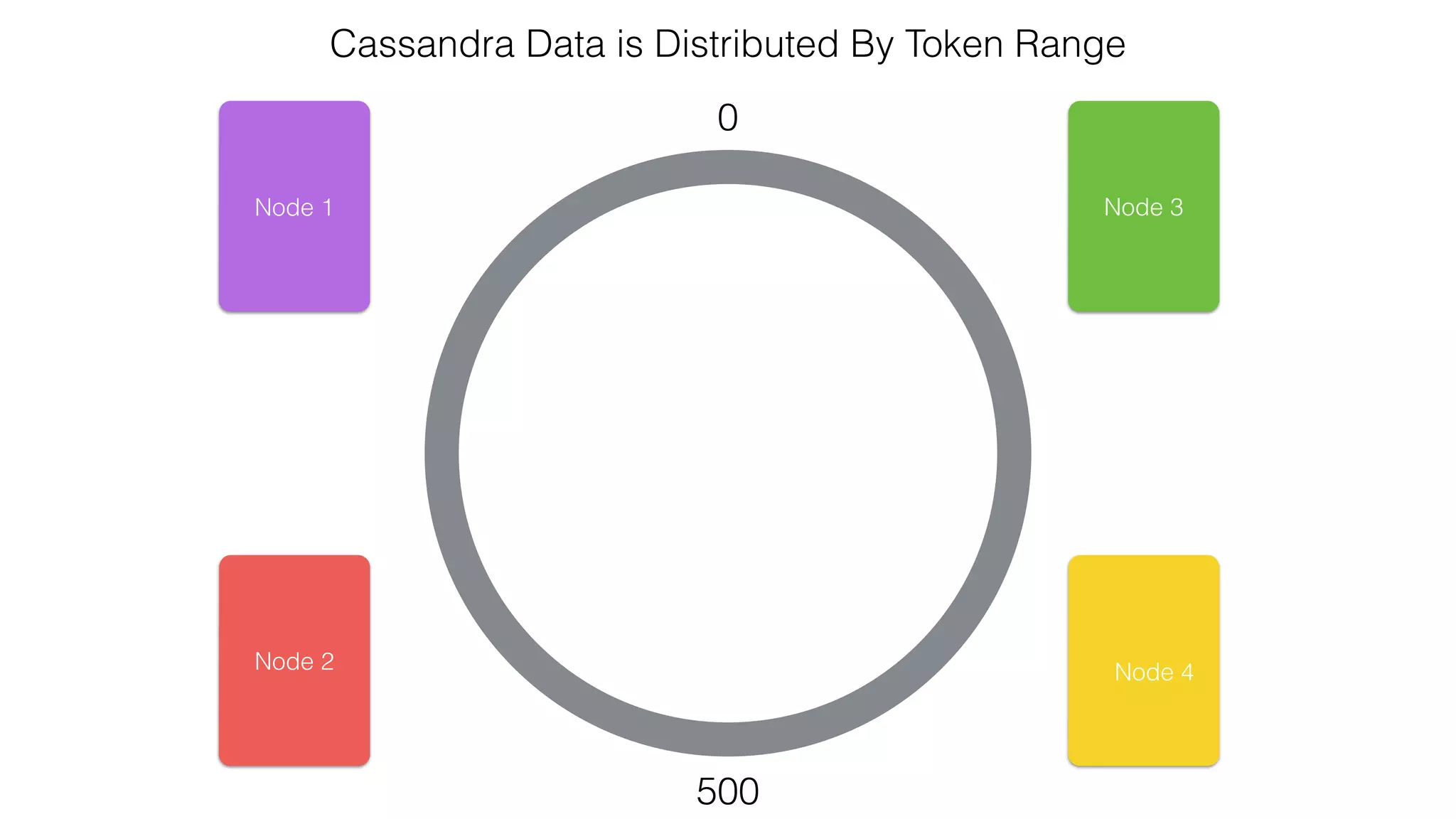
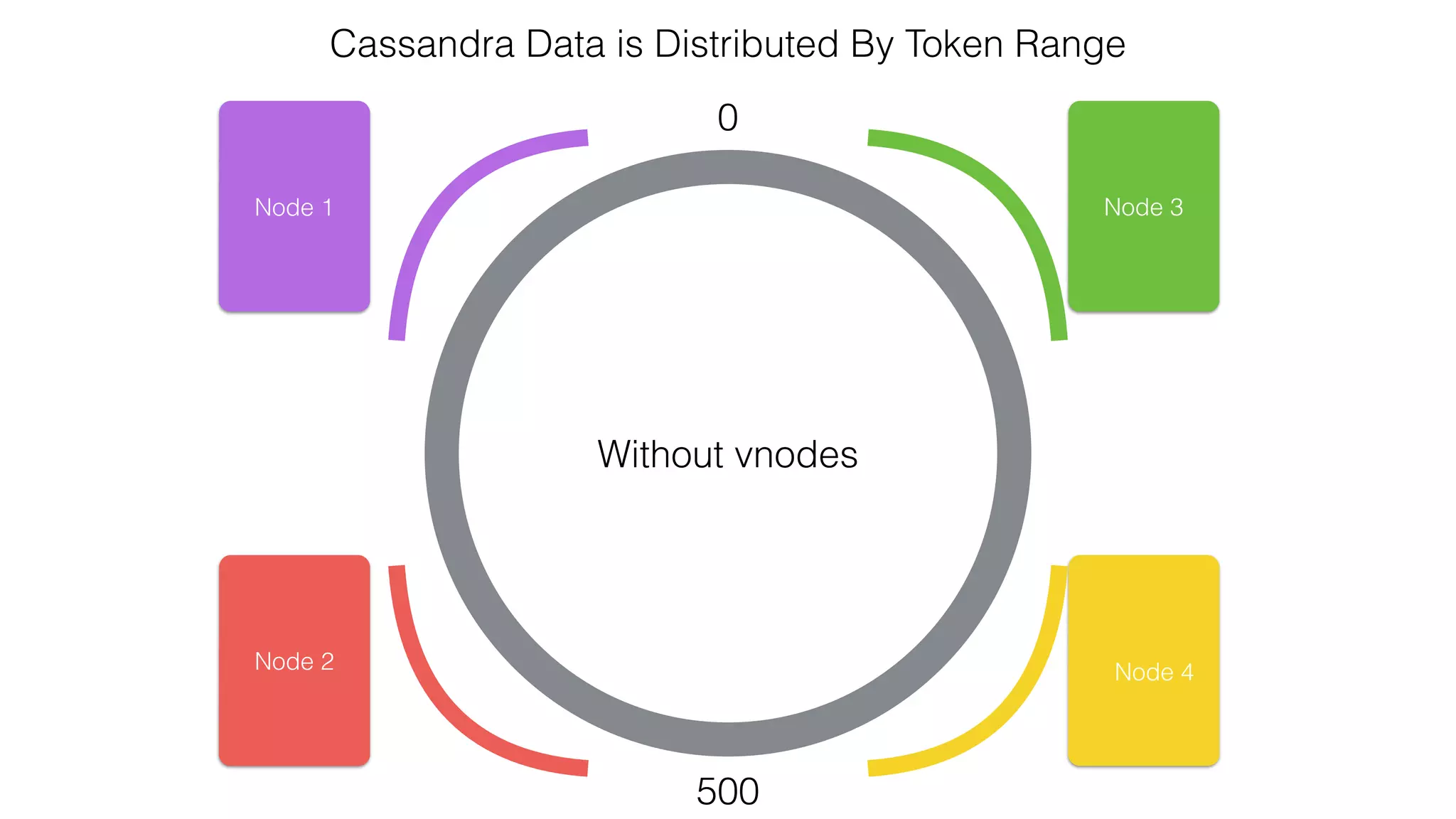
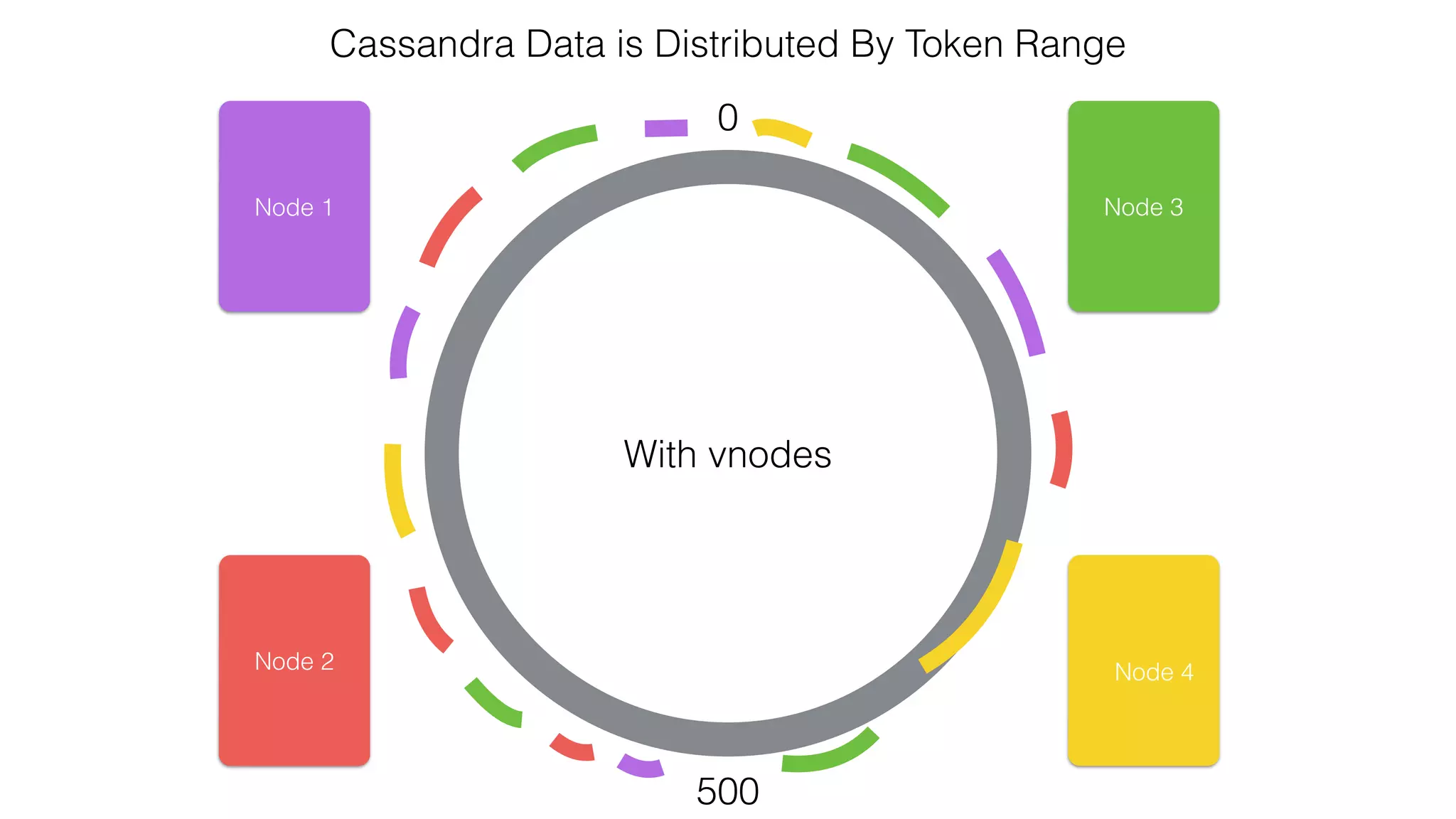
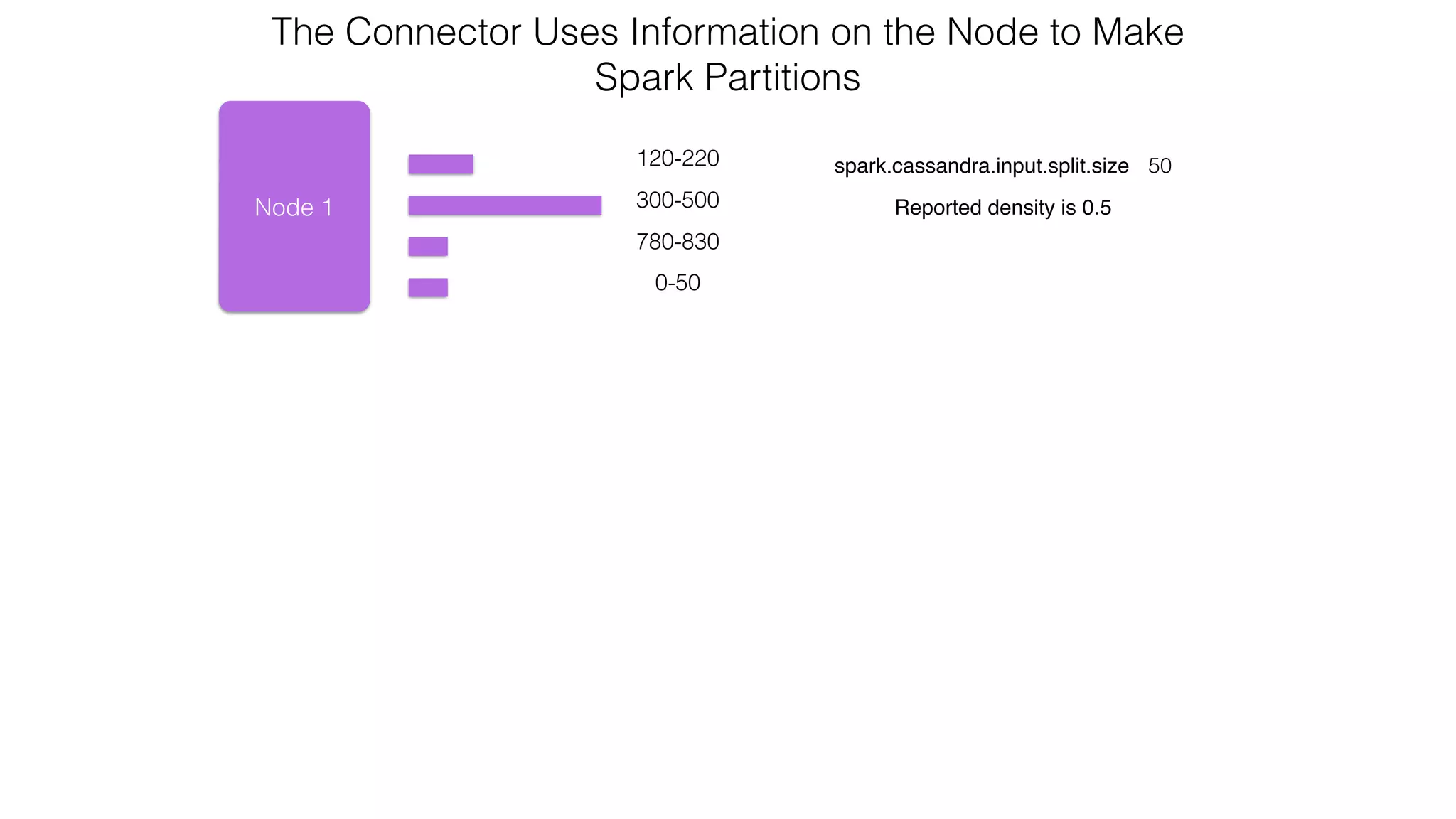
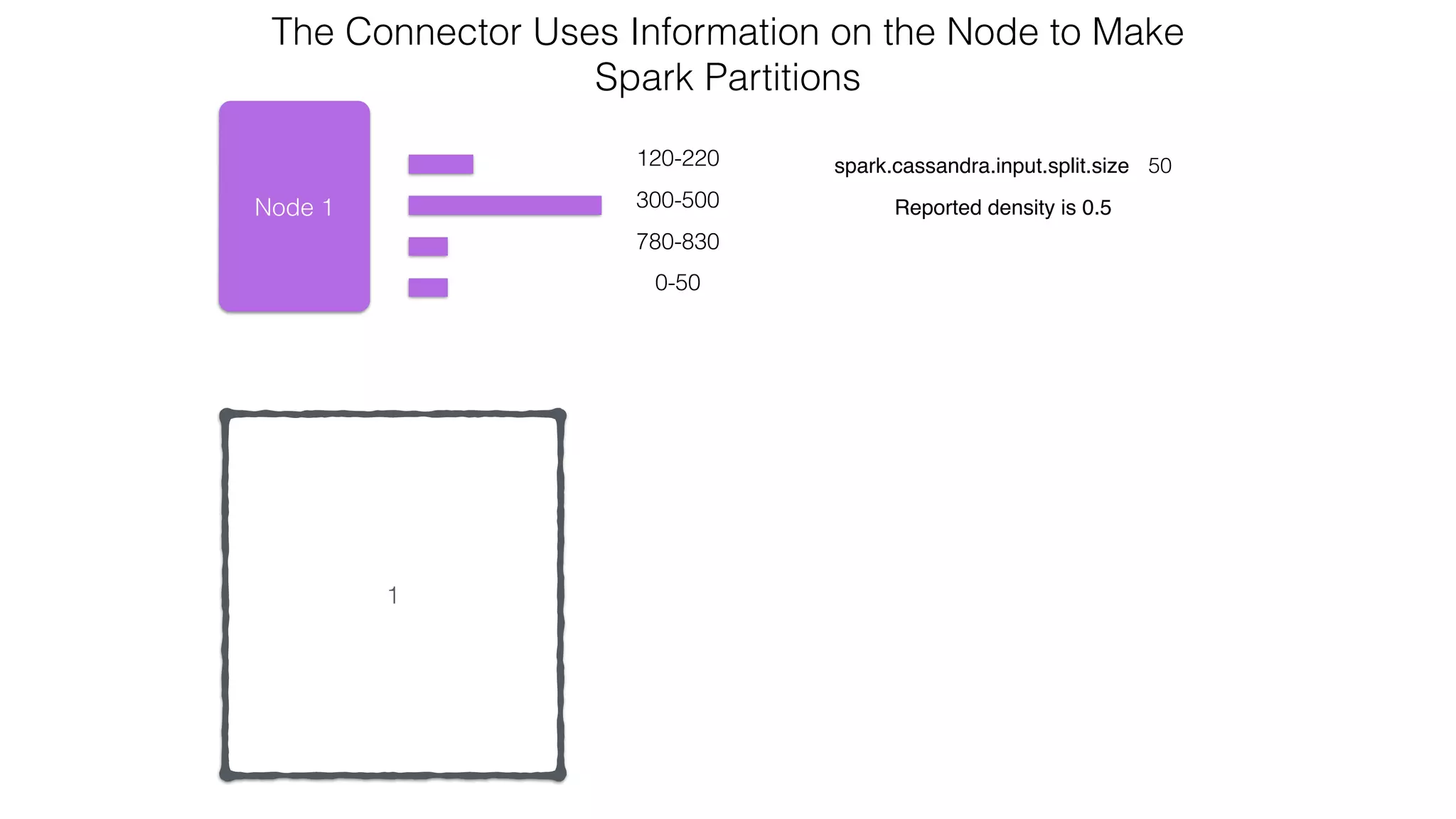
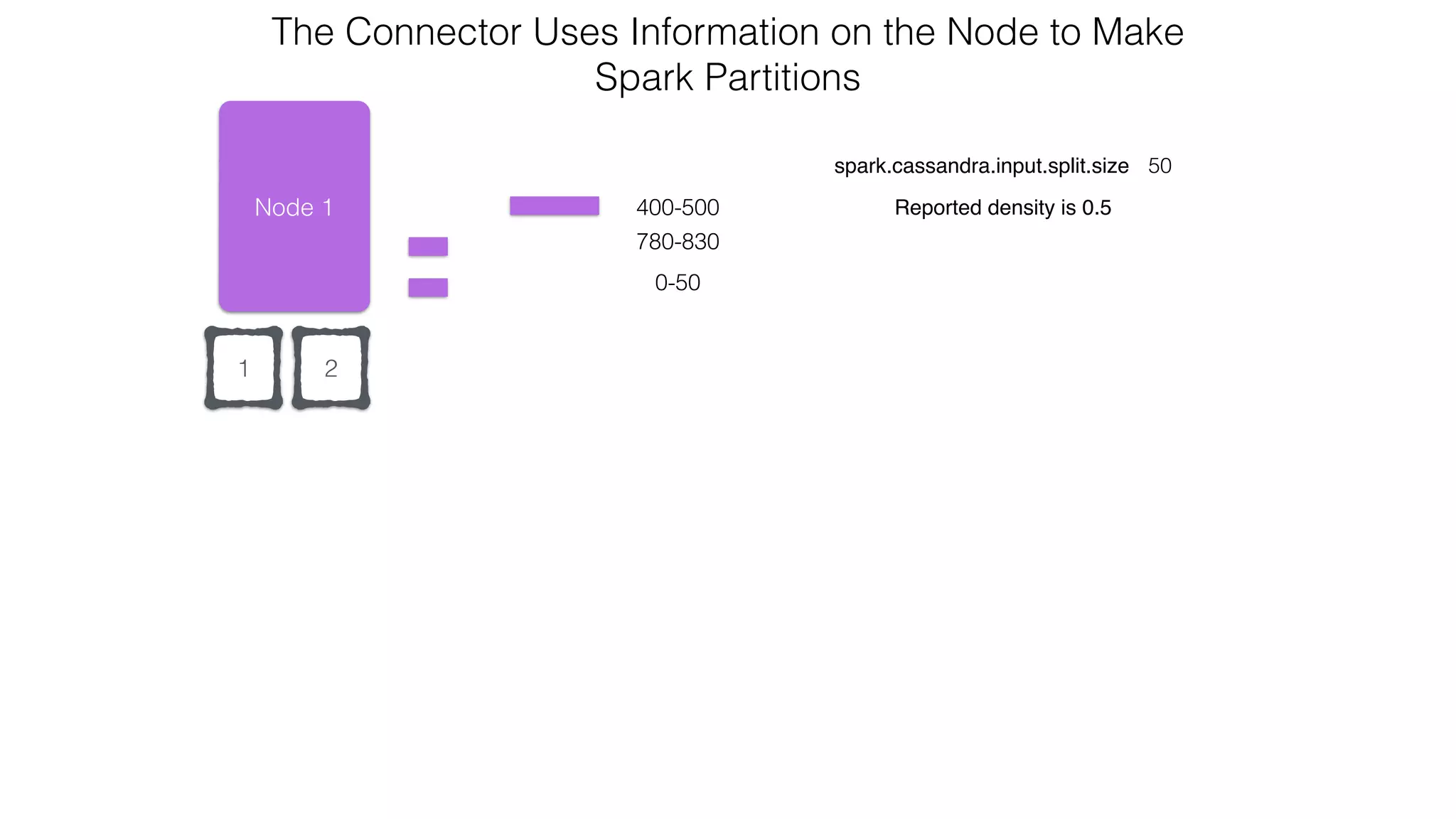
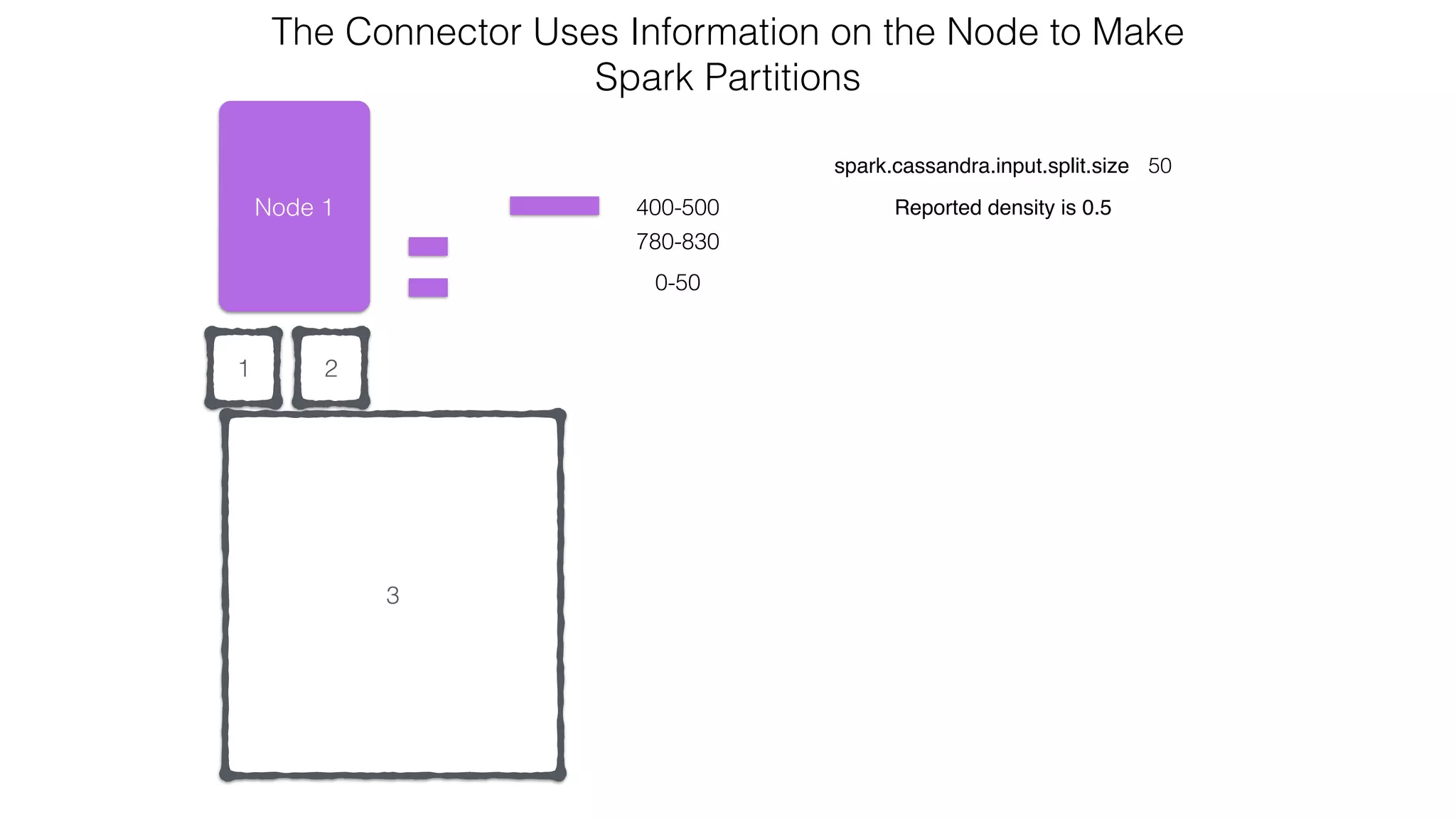
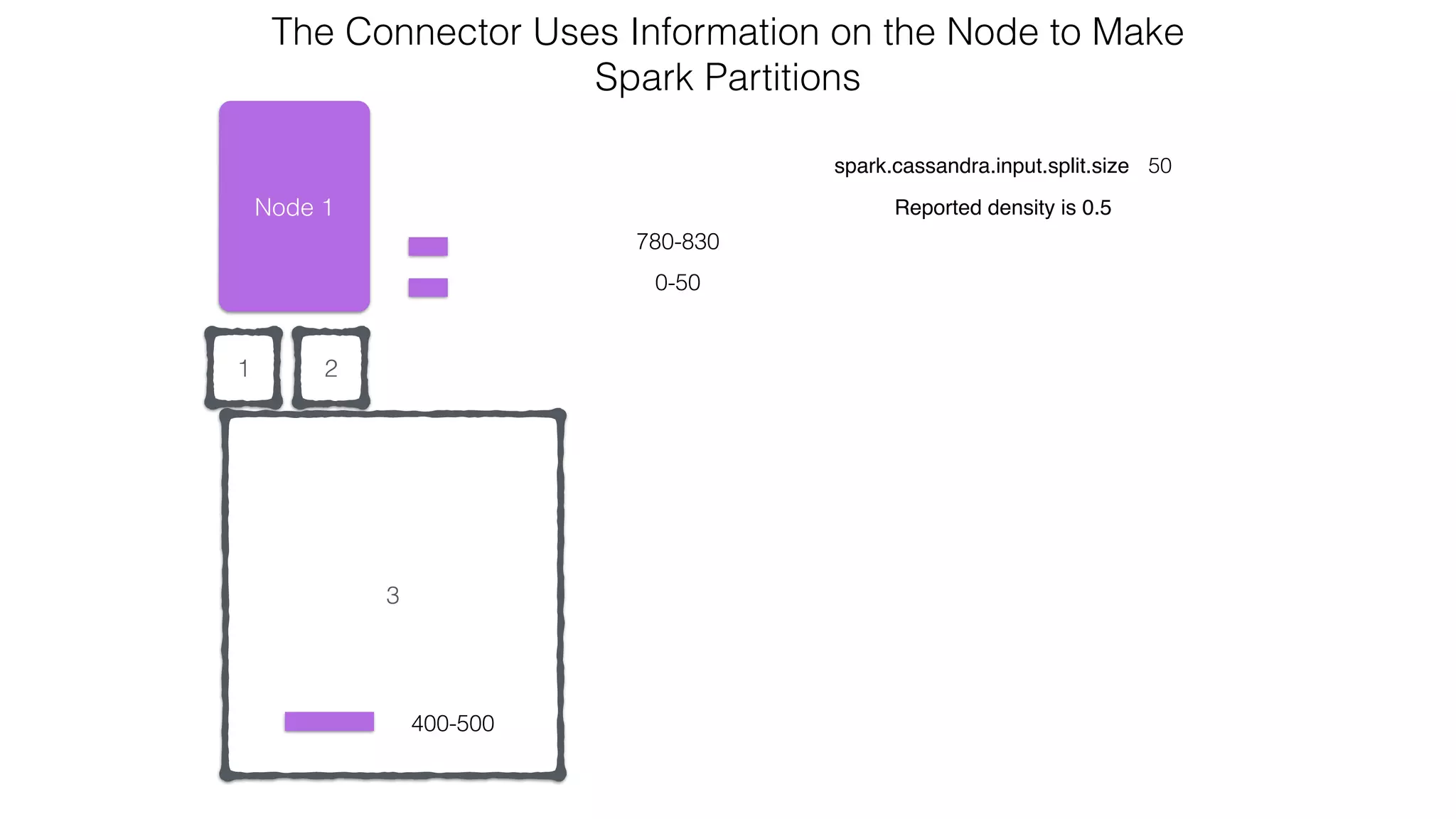
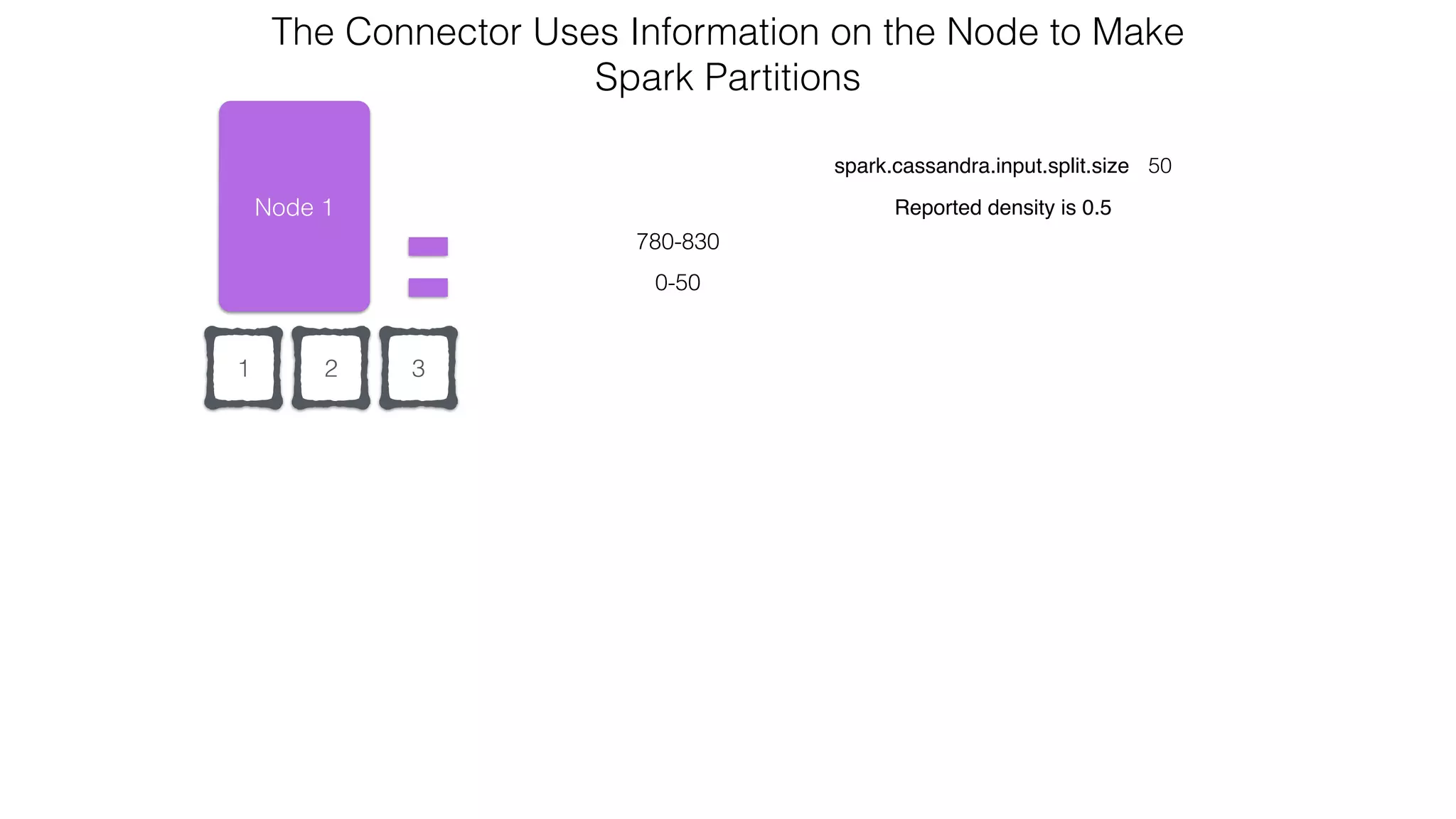




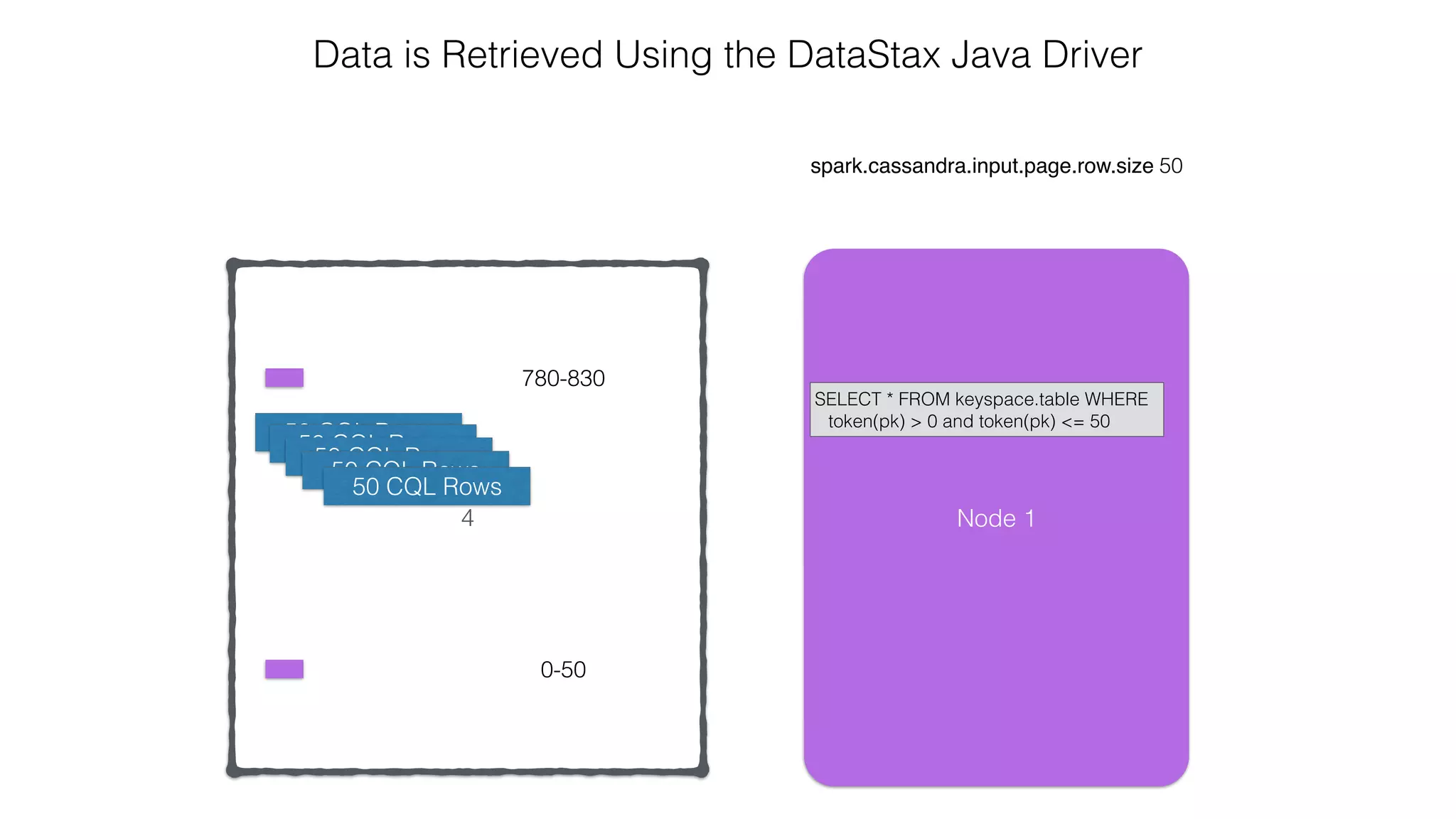
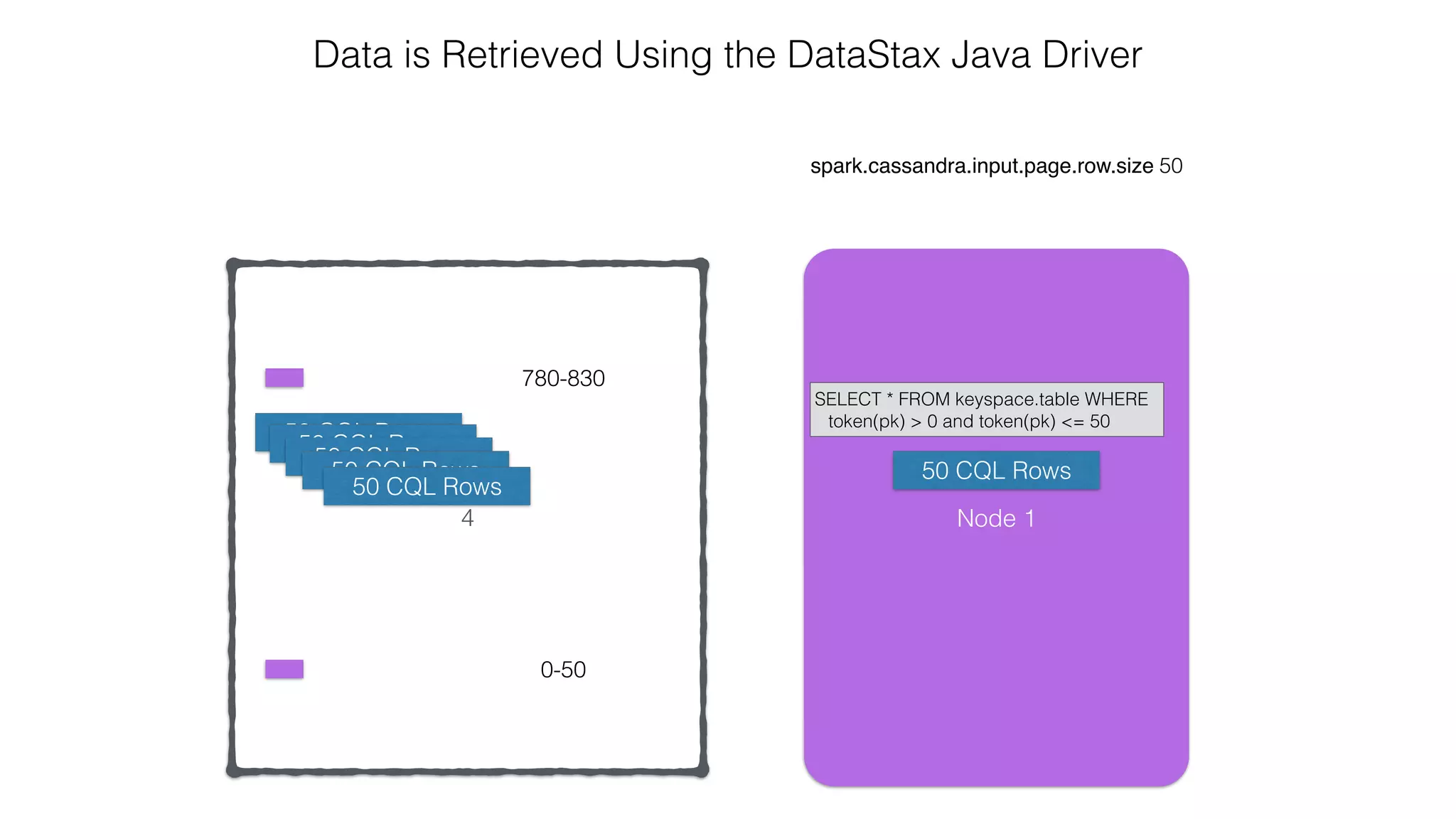
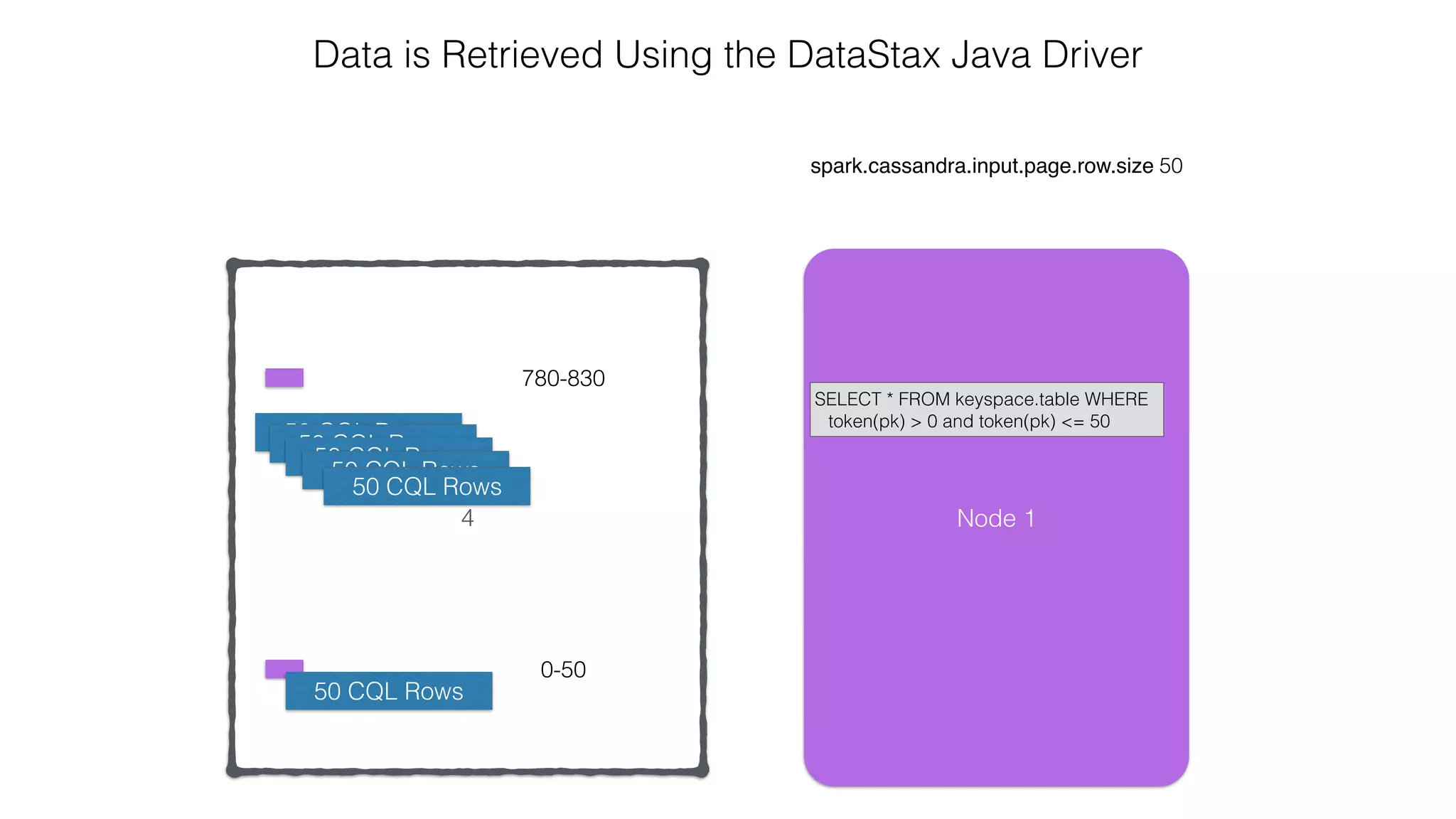
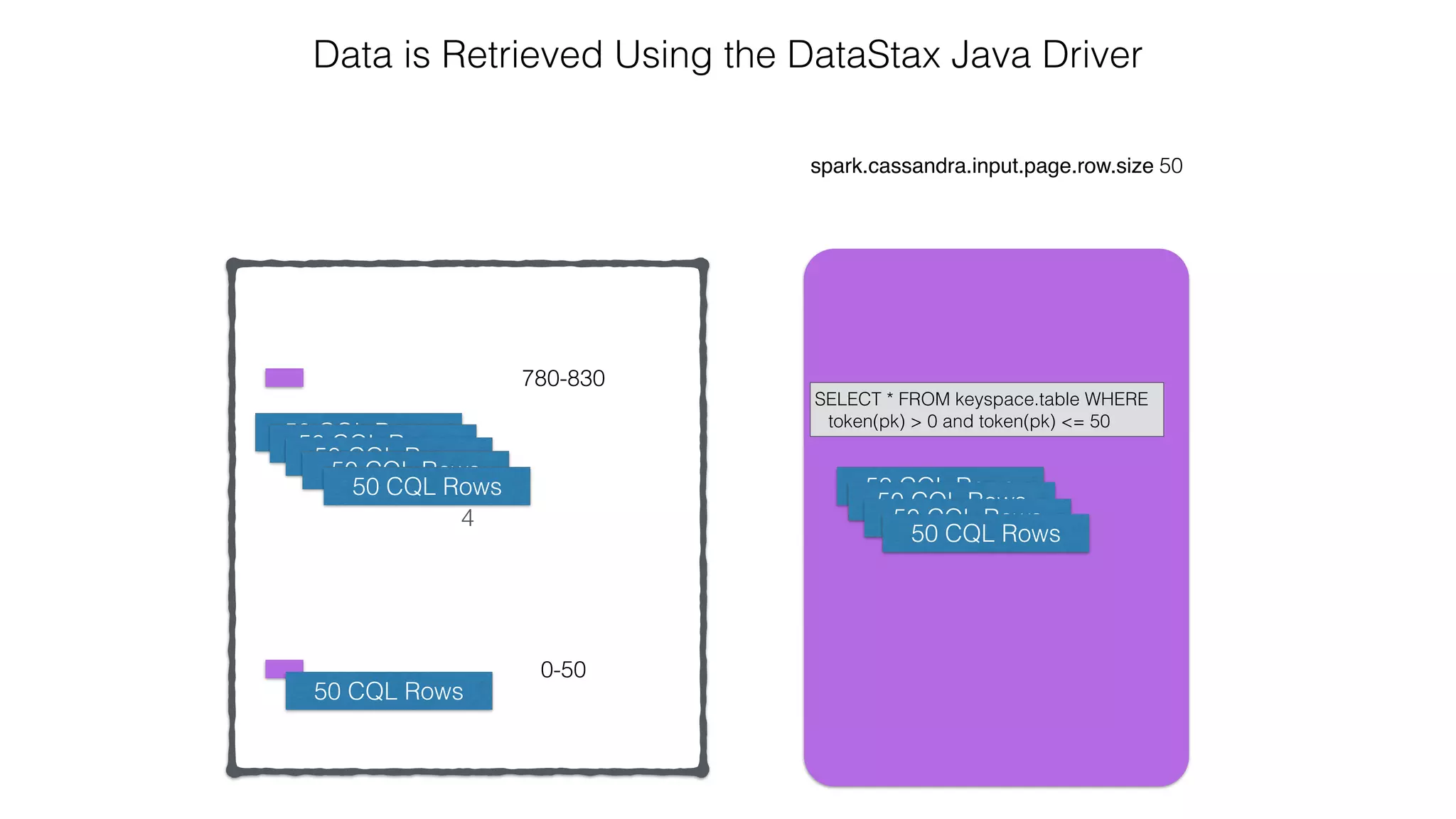




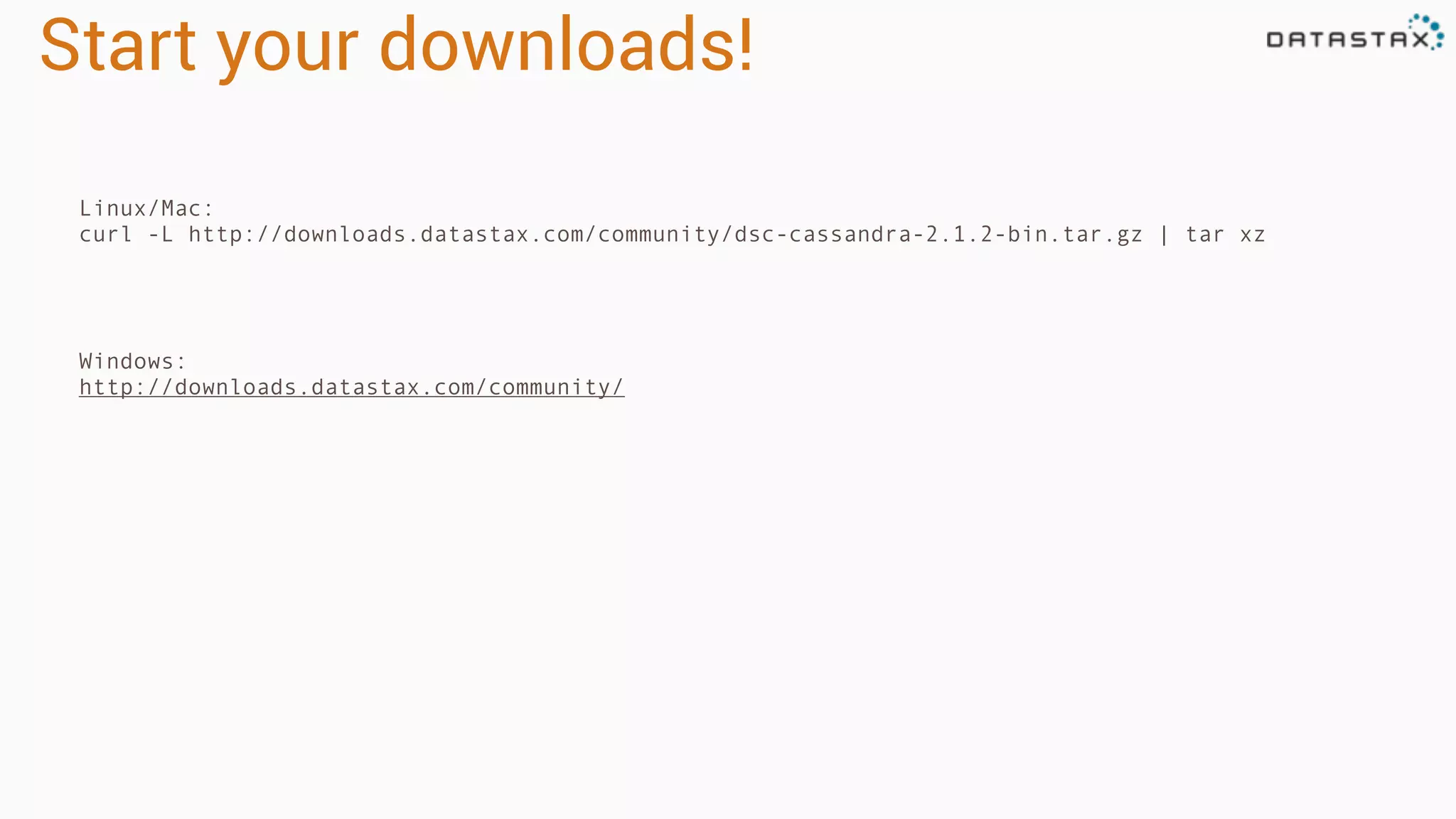
![Verify install
Run cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.0 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>
cd Program FilesDataStax Communityapache-cassandrabin
cqlsh
<from dsc-cassandra-2.1.0/bin>
./cqlsh
Expected output](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-119-2048.jpg)
![Load schema
Go to data directory
> cd killrweather/data
> ls
> 2005.csv.gz create-timeseries.cql load-timeseries.cqlweather_stations.csv
Load data
> <cassandra_dir>/bin/cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.0 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh> source 'create-timeseries.cql';
cqlsh> source 'load-timeseries.cql';
cqlsh> describe keyspace isd_weather_data;
cqlsh> use isd_weather_data;
cqlsh:isd_weather_data> select * from weather_station limit 10;
id | call_sign | country_code | elevation | lat | long | name | state_code
--------------+-----------+--------------+-----------+--------+---------+-----------------------+------------
408930:99999 | OIZJ | IR | 4 | 25.65 | 57.767 | JASK | null
725500:14942 | KOMA | US | 299.3 | 41.317 | -95.9 | OMAHA EPPLEY AIRFIELD | NE
725474:99999 | KCSQ | US | 394 | 41.017 | -94.367 | CRESTON | IA
480350:99999 | VBLS | BM | 749 | 22.933 | 97.75 | LASHIO | null
719380:99999 | CYCO | CN | 22 | 67.817 | -115.15 | COPPERMINE AIRPORT | null
992790:99999 | DB279 | US | 3 | 40.5 | -69.467 | ENVIRONM BUOY 44008 | null
85120:99999 | LPPD | PO | 72 | 37.733 | -25.7 | PONTA DELGADA/NORDE | null
150140:99999 | LRBM | RO | 218 | 47.667 | 23.583 | BAIA MARE | null
435330:99999 | null | MV | 1 | 6.733 | 73.15 | HANIMADU | null
536150:99999 | null | CI | 1005 | 38.467 | 106.27 |](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-120-2048.jpg)






![Setup connection
def main(args: Array[String]): Unit = {
// the setMaster("local") lets us run & test the job right in our IDE
val conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setMaster("local")
// "local" here is the master, meaning we don't explicitly have a spark master set up
val sc = new SparkContext("local", "weather", conf)
val connector = CassandraConnector(conf)
val cc = new CassandraSQLContext(sc)
cc.setKeyspace("isd_weather_data")](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-132-2048.jpg)



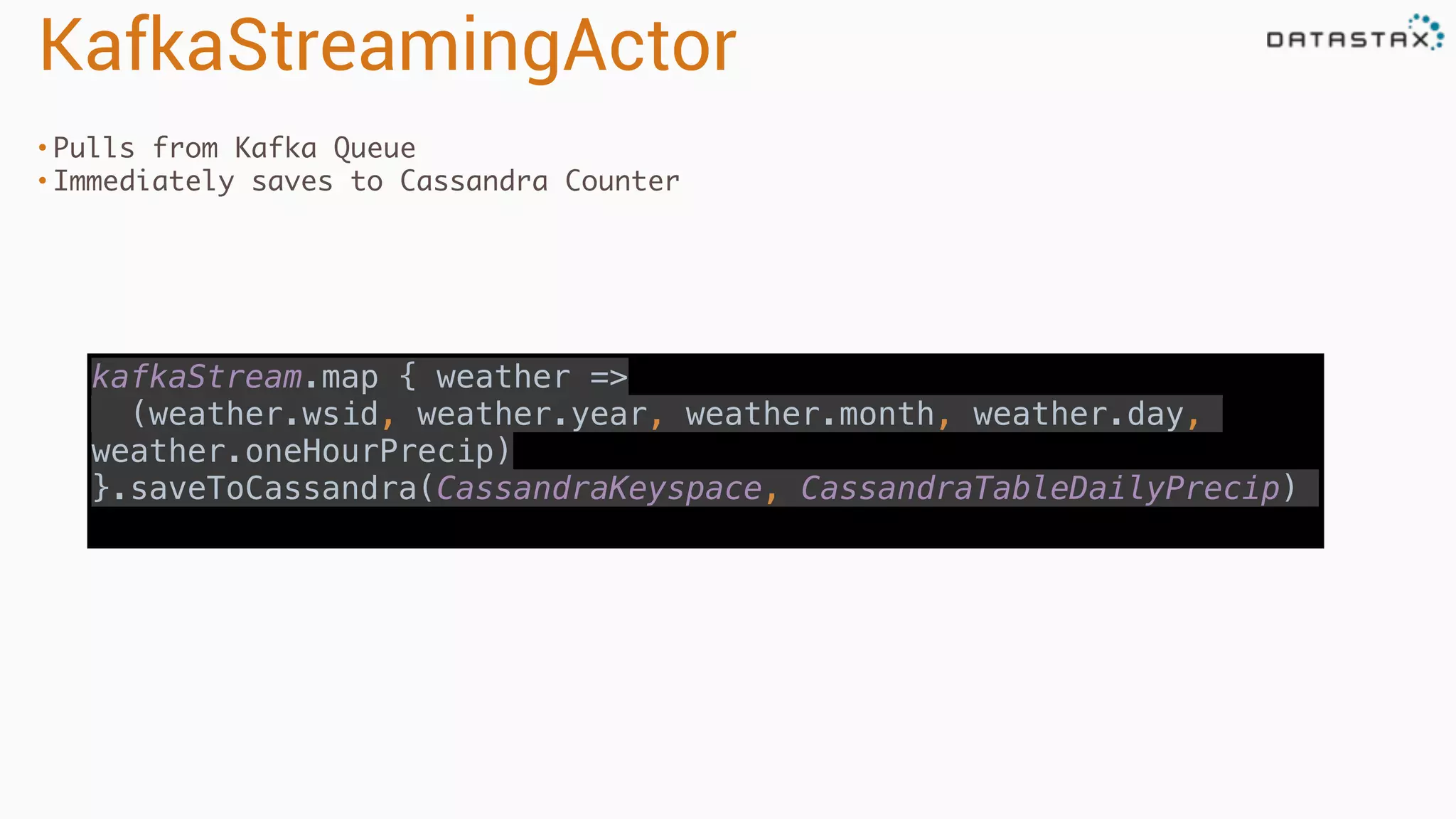


.select("temperature").where("wsid = ? AND year = ? AND month = ? AND day = ?",
day.wsid, day.year, day.month, day.day)
.collectAsync()
} yield forDay(day, aggregate)) pipeTo requester](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-142-2048.jpg)
![TemperatureActor
/**
* Would only be handling handles 0-23 small items or fewer.
*/
private def forDay(key: Day, temps: Seq[Double]): WeatherAggregate =
if (temps.nonEmpty) {
val stats = StatCounter(temps)
val data = DailyTemperature(
key.wsid, key.year, key.month, key.day,
high = stats.max, low = stats.min,
mean = stats.mean, variance = stats.variance, stdev = stats.stdev)
self ! data
data
} else NoDataAvailable(key.wsid, key.year, classOf[DailyTemperature])](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-143-2048.jpg)



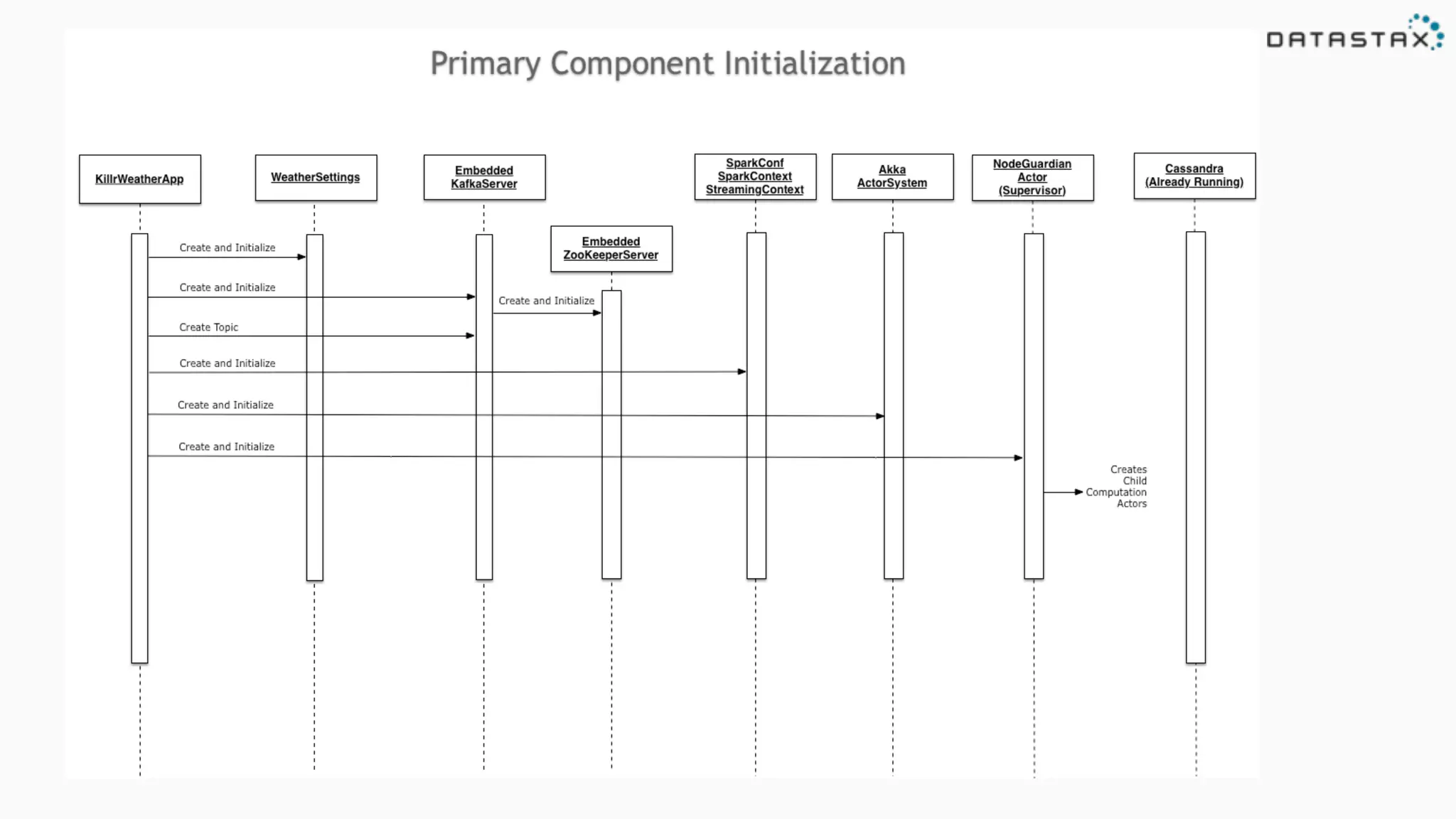

![Run code
> sbt clients/run
[1] com.datastax.killrweather.DataFeedApp
[2] com.datastax.killrweather.KillrWeatherClientApp
Enter number: 1
[DEBUG] [2015-02-18 06:49:12,073]
[com.datastax.killrweather.FileFeedActor]: Sending
'725030:14732,2008,12,15,12,10.0,6.7,1028.3,160,2.6,8,0.0,-0.1'
> sbt clients/run
[1] com.datastax.killrweather.DataFeedApp
[2] com.datastax.killrweather.KillrWeatherClientApp
Enter number: 2
[INFO] [2015-02-18 06:50:10,369]
[com.datastax.killrweather.WeatherApiQueries]: Requesting the current
weather for weather station 722020:12839
[INFO] [2015-02-18 06:50:10,369]
[com.datastax.killrweather.WeatherApiQueries]: Requesting annual
precipitation for weather station 722020:12839 in year 2008
[INFO] [2015-02-18 06:50:10,369]
[com.datastax.killrweather.WeatherApiQueries]: Requesting top-k
Precipitation for weather station 722020:12839
[INFO] [2015-02-18 06:50:10,369]
[com.datastax.killrweather.WeatherApiQueries]: Requesting the daily
temperature aggregate for weather station 722020:12839
[INFO] [2015-02-18 06:50:10,370]
[com.datastax.killrweather.WeatherApiQueries]: Requesting the high-low
temperature aggregate for weather station 722020:12839
[INFO] [2015-02-18 06:50:10,370]
[com.datastax.killrweather.WeatherApiQueries]: Requesting weather
station 722020:12839
Terminal 1 Terminal 2](https://image.slidesharecdn.com/owningtimeserieswithteamapache-stratasj2015-150220153210-conversion-gate01/75/Owning-time-series-with-team-apache-Strata-San-Jose-2015-149-2048.jpg)
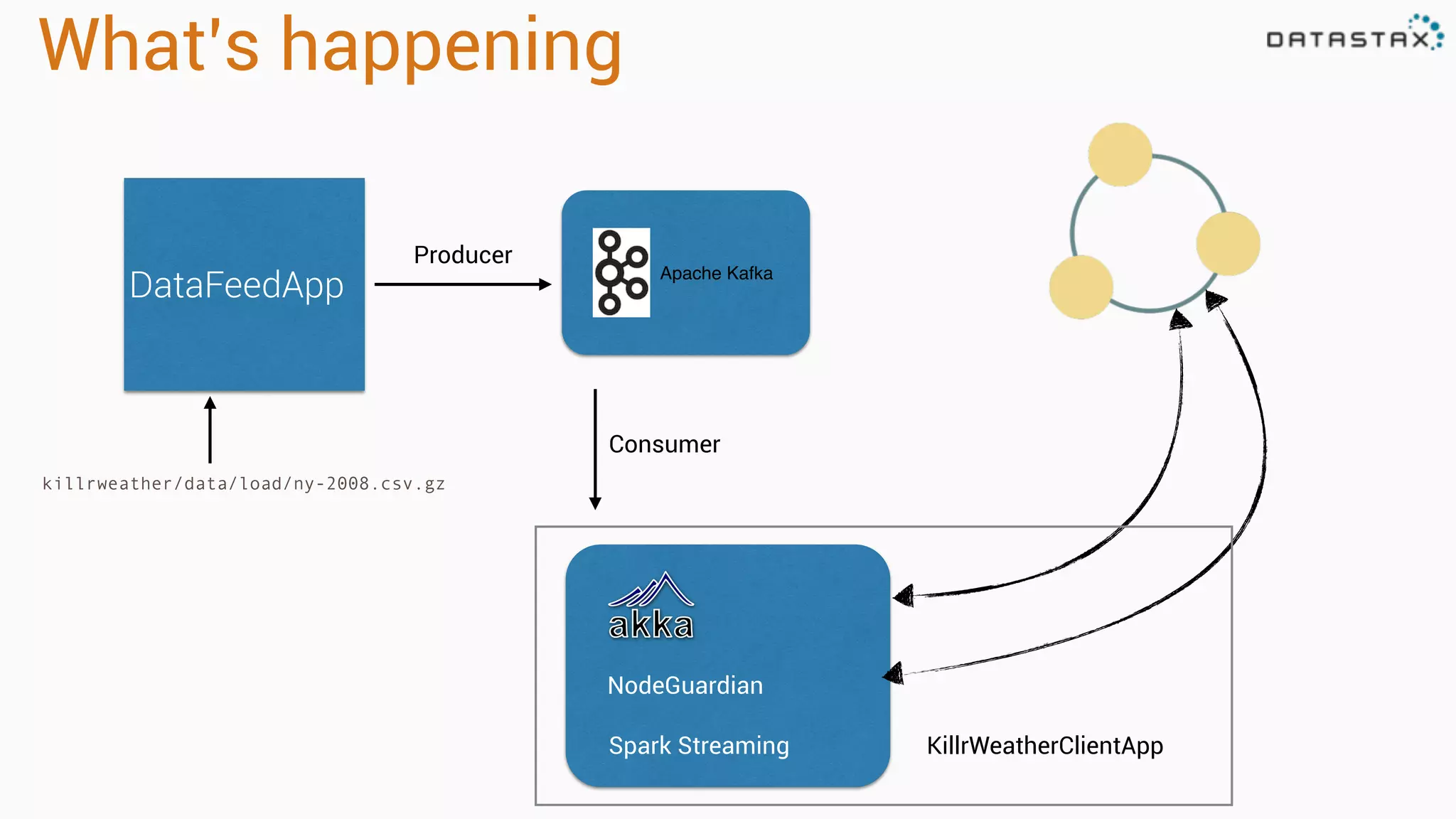


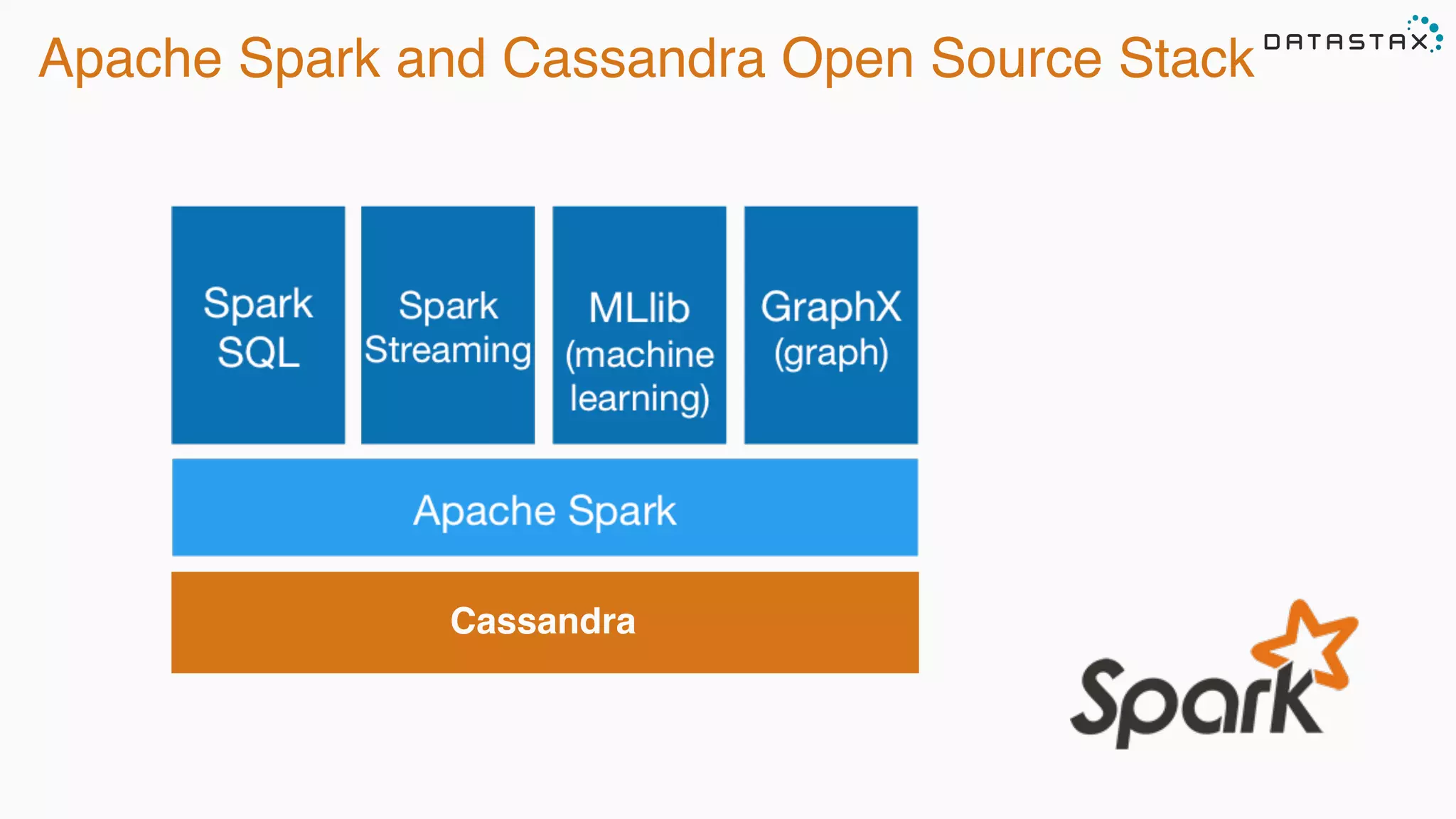
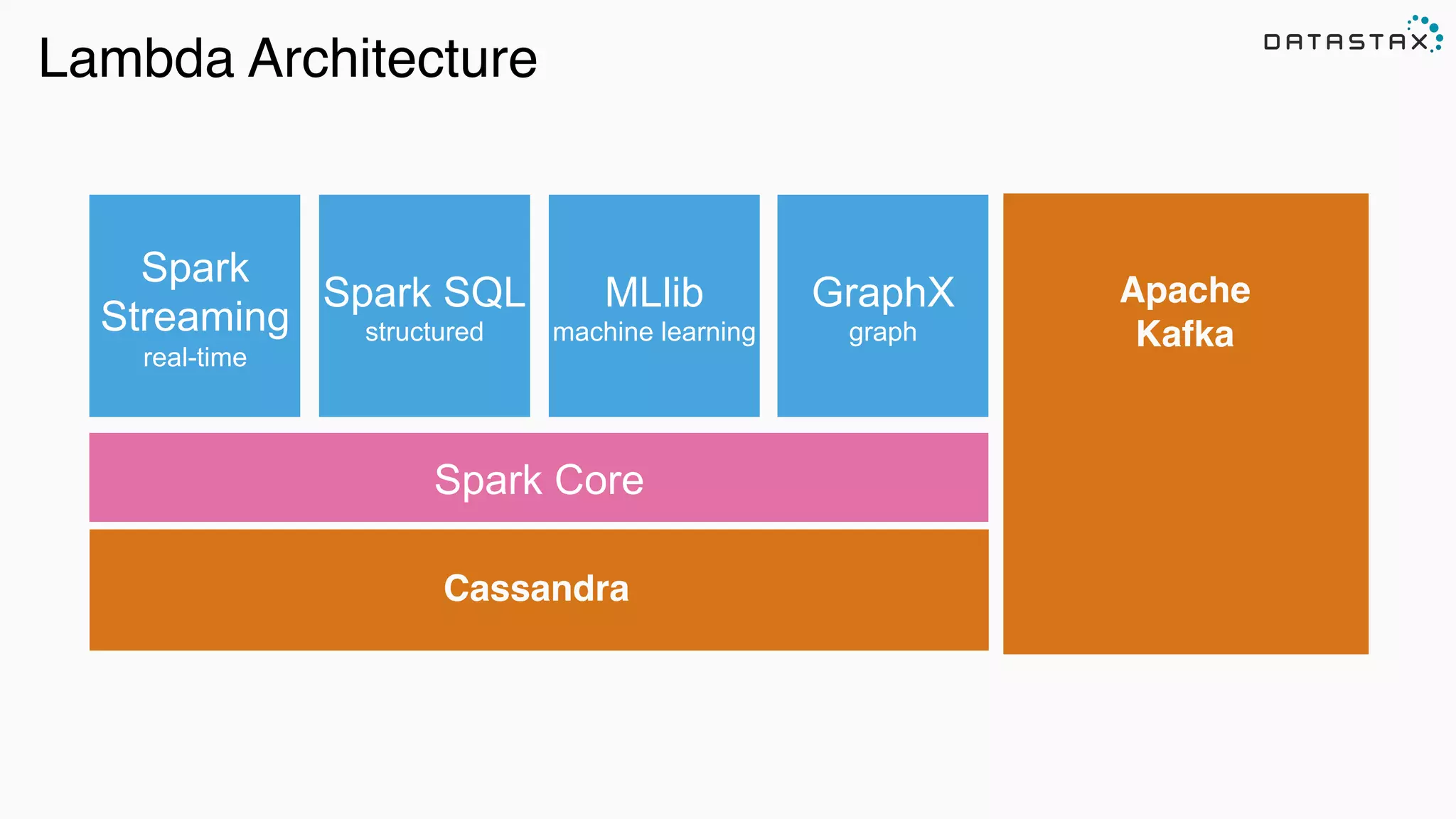
The document outlines a tutorial and presentation on using Apache Cassandra, Apache Spark, and Kafka for managing time series data. It covers foundational concepts such as data modeling, integration techniques, and how to set up an end-to-end data pipeline using these technologies. Specific examples, including data ingestion and query patterns for time series, are discussed, highlighting the advantages of using Cassandra and Spark together.





















































































