Download as PDF, PPTX






![RDD Operations
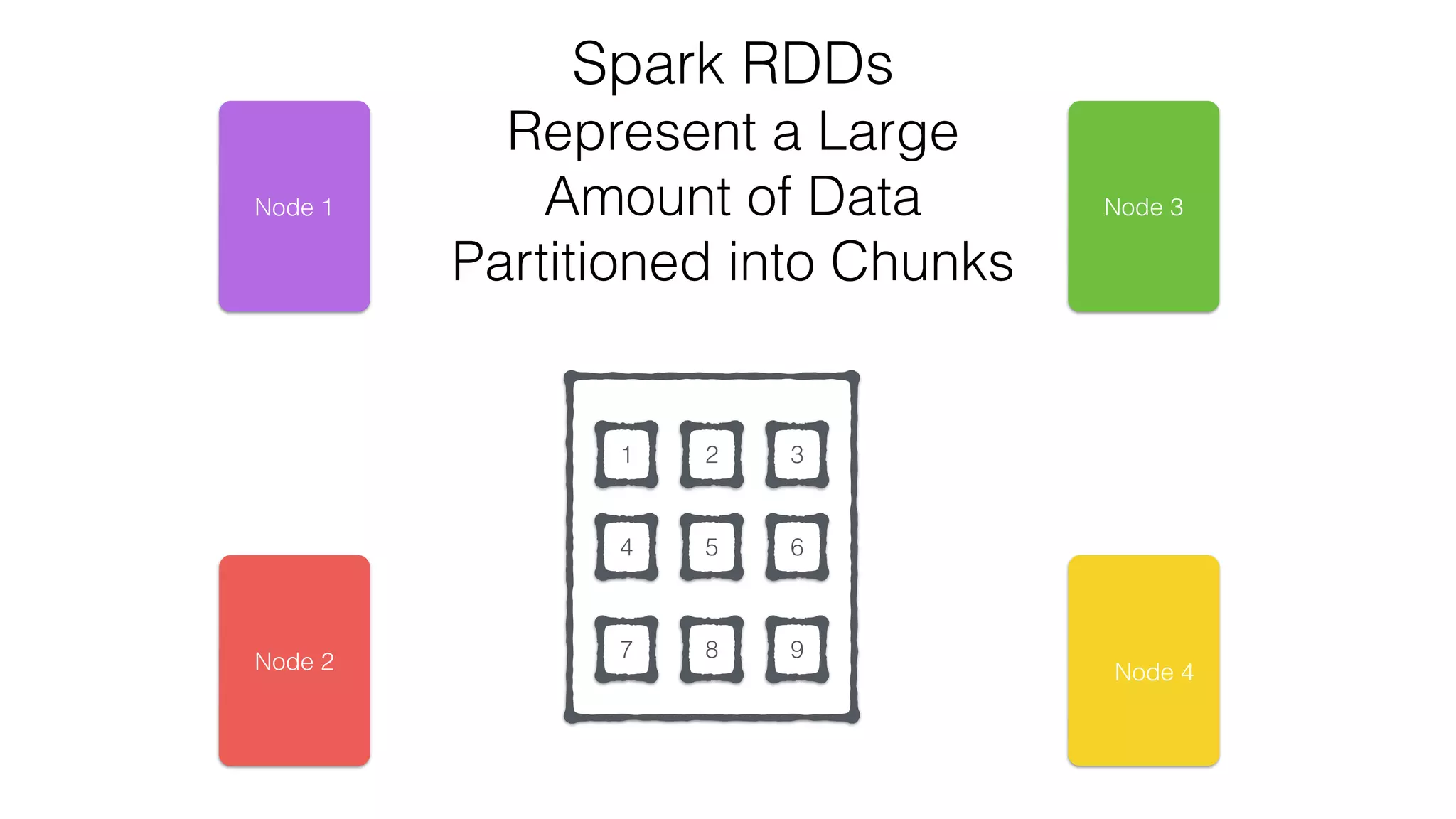
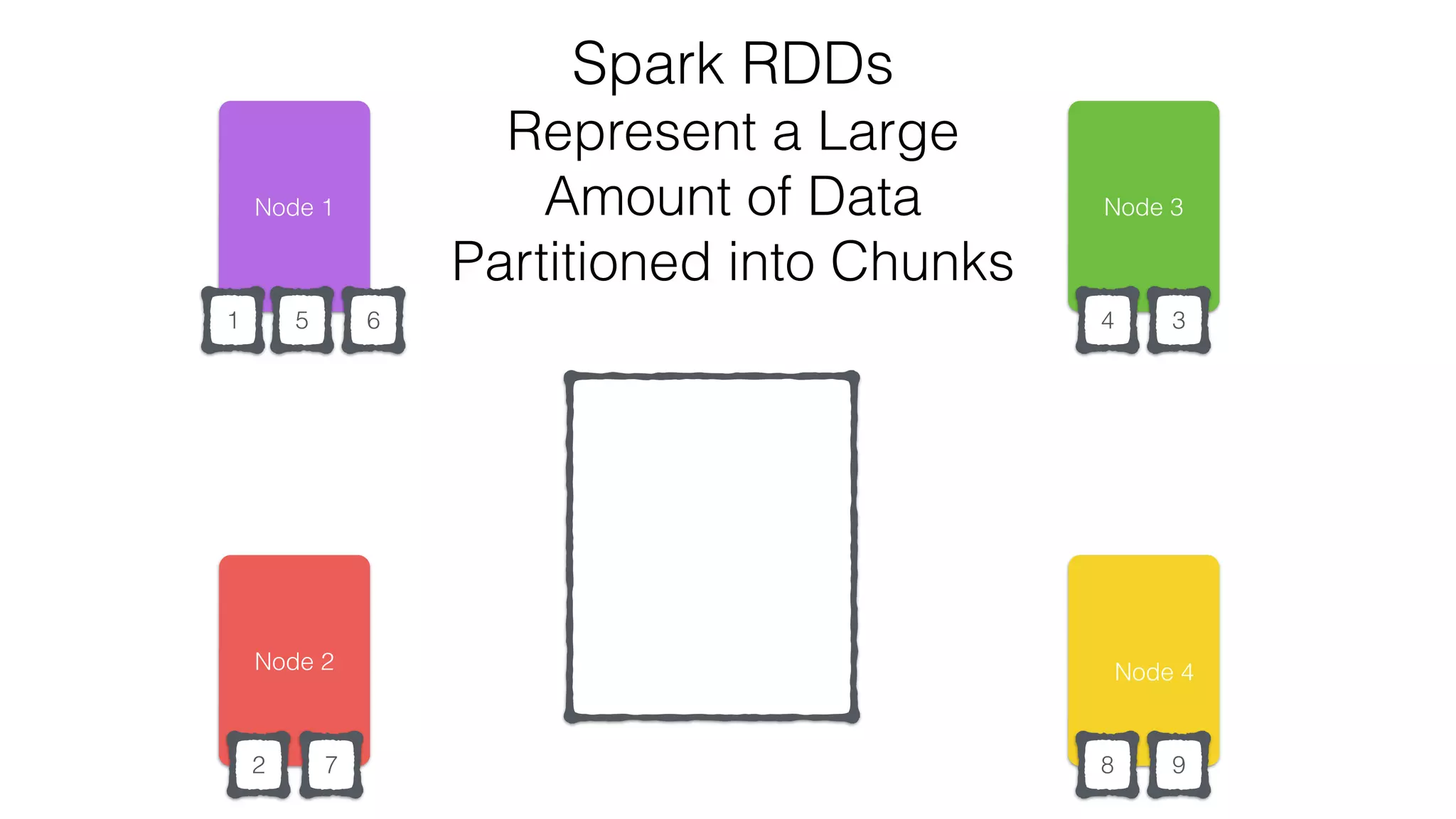
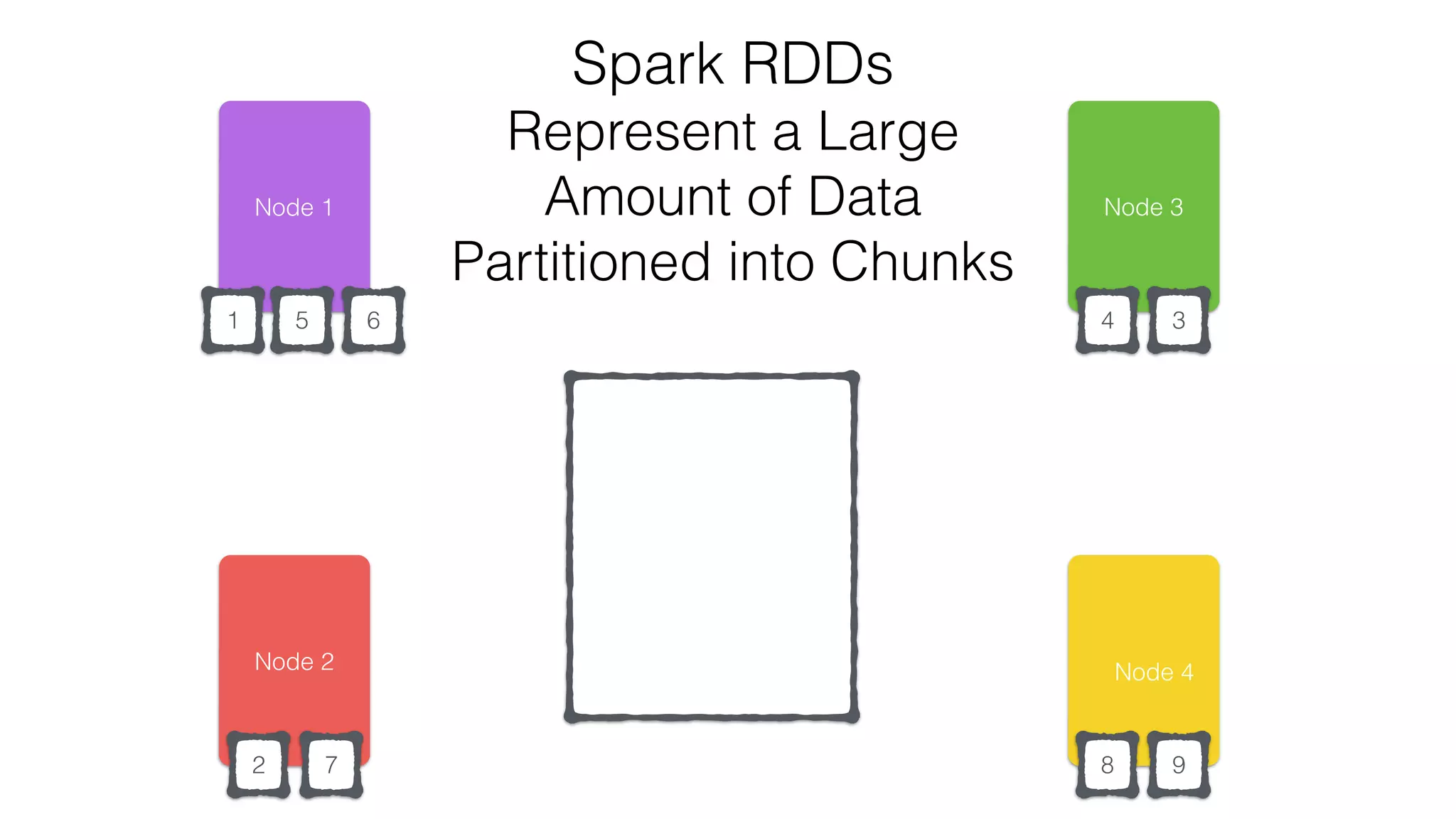
•Transformations - Similar to scala collections API
•Produce new RDDs
•filter, flatmap, map, distinct, groupBy, union, zip,
reduceByKey, subtract
•Actions
•Require materialization of the records to generate a value
•collect: Array[T], count, fold, reduce..](https://image.slidesharecdn.com/apachecassandraandspark-150303113512-conversion-gate01/75/Apache-cassandra-and-spark-you-got-the-the-lighter-let-s-start-the-fire-12-2048.jpg)






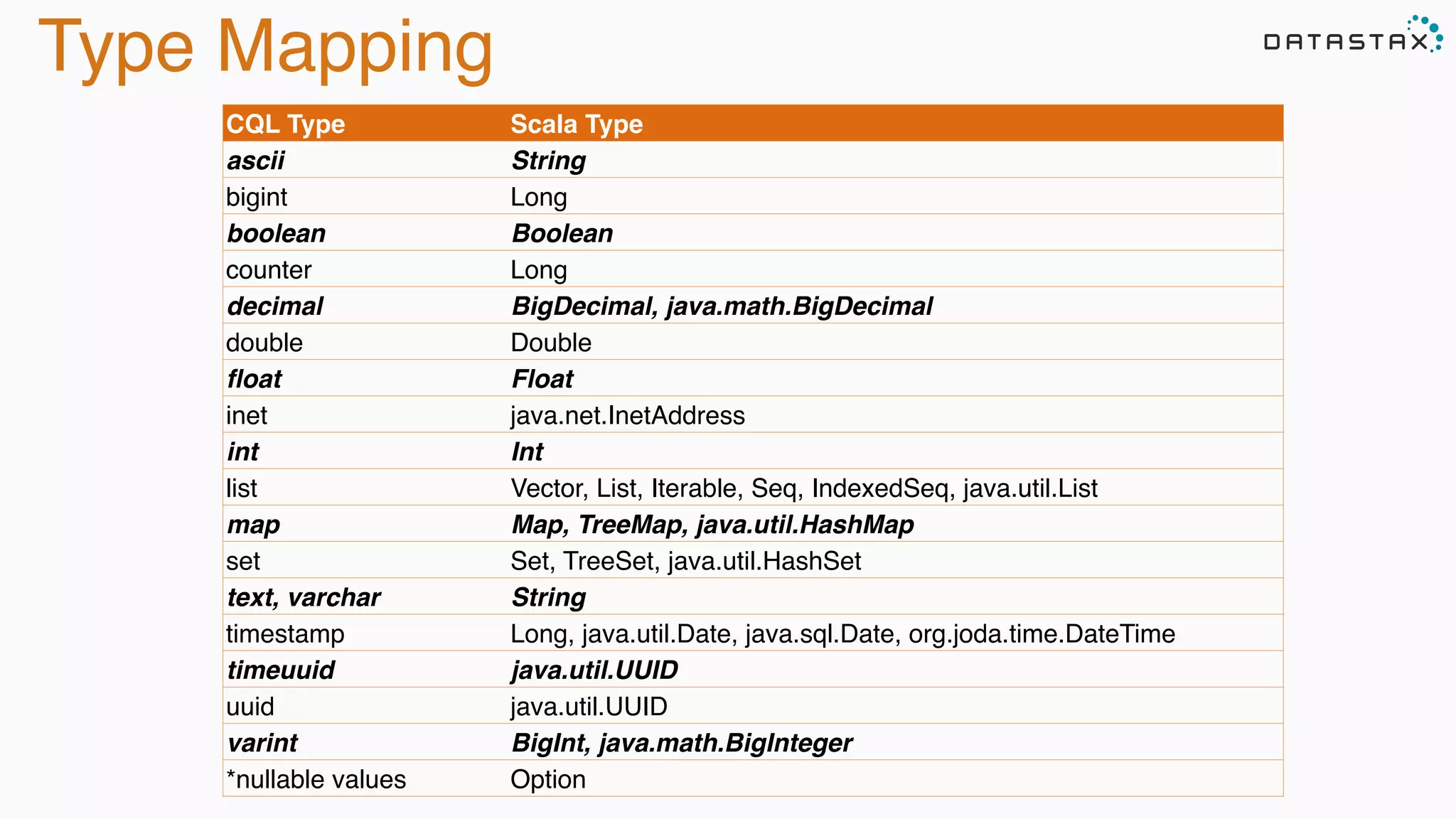
![Accessing Data
CREATE TABLE test.words (word text PRIMARY KEY, count int);
INSERT INTO test.words (word, count) VALUES ('bar', 30);
INSERT INTO test.words (word, count) VALUES ('foo', 20);
// Use table as RDD
val rdd = sc.cassandraTable("test", "words")
// rdd: CassandraRDD[CassandraRow] = CassandraRDD[0]
rdd.toArray.foreach(println)
// CassandraRow[word: bar, count: 30]
// CassandraRow[word: foo, count: 20]
rdd.columnNames // Stream(word, count)
rdd.size // 2
val firstRow = rdd.first // firstRow: CassandraRow = CassandraRow[word: bar,
count: 30]
firstRow.getInt("count") // Int = 30
*Accessing table above as RDD:](https://image.slidesharecdn.com/apachecassandraandspark-150303113512-conversion-gate01/75/Apache-cassandra-and-spark-you-got-the-the-lighter-let-s-start-the-fire-22-2048.jpg)
![Saving Data
val newRdd = sc.parallelize(Seq(("cat", 40), ("fox", 50)))
// newRdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2]
newRdd.saveToCassandra("test", "words", Seq("word", "count"))
SELECT * FROM test.words;
word | count
------+-------
bar | 30
foo | 20
cat | 40
fox | 50
(4 rows)
*RDD above saved to Cassandra:](https://image.slidesharecdn.com/apachecassandraandspark-150303113512-conversion-gate01/75/Apache-cassandra-and-spark-you-got-the-the-lighter-let-s-start-the-fire-23-2048.jpg)
![Spark Cassandra Connector
https://github.com/datastax/spark-‐cassandra-‐connector
Keyspace Table
Cassandra Spark
RDD[CassandraRow]
RDD[Tuples]
Bundled
and
Supported
with
DSE
4.5!](https://image.slidesharecdn.com/apachecassandraandspark-150303113512-conversion-gate01/75/Apache-cassandra-and-spark-you-got-the-the-lighter-let-s-start-the-fire-24-2048.jpg)











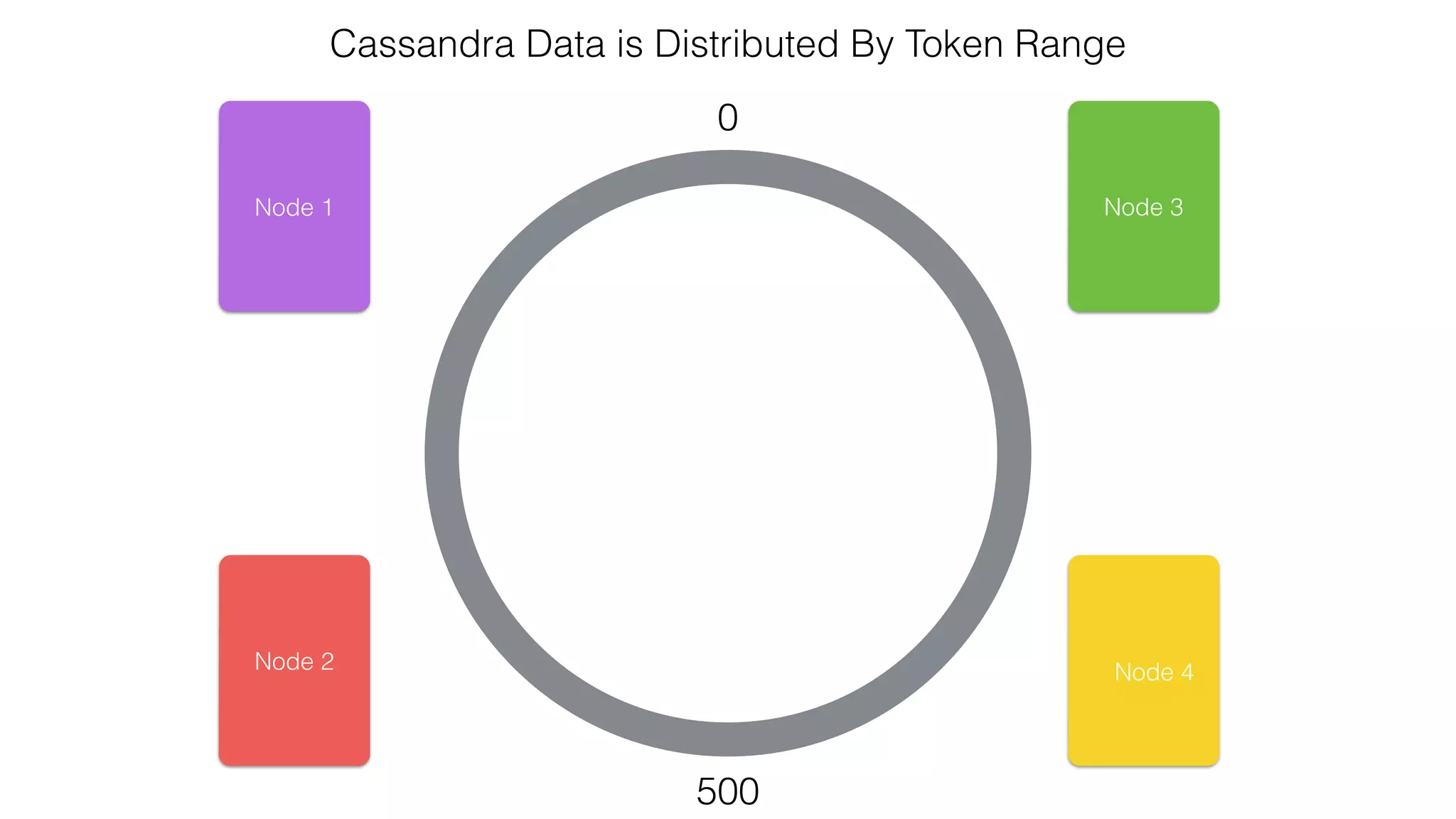
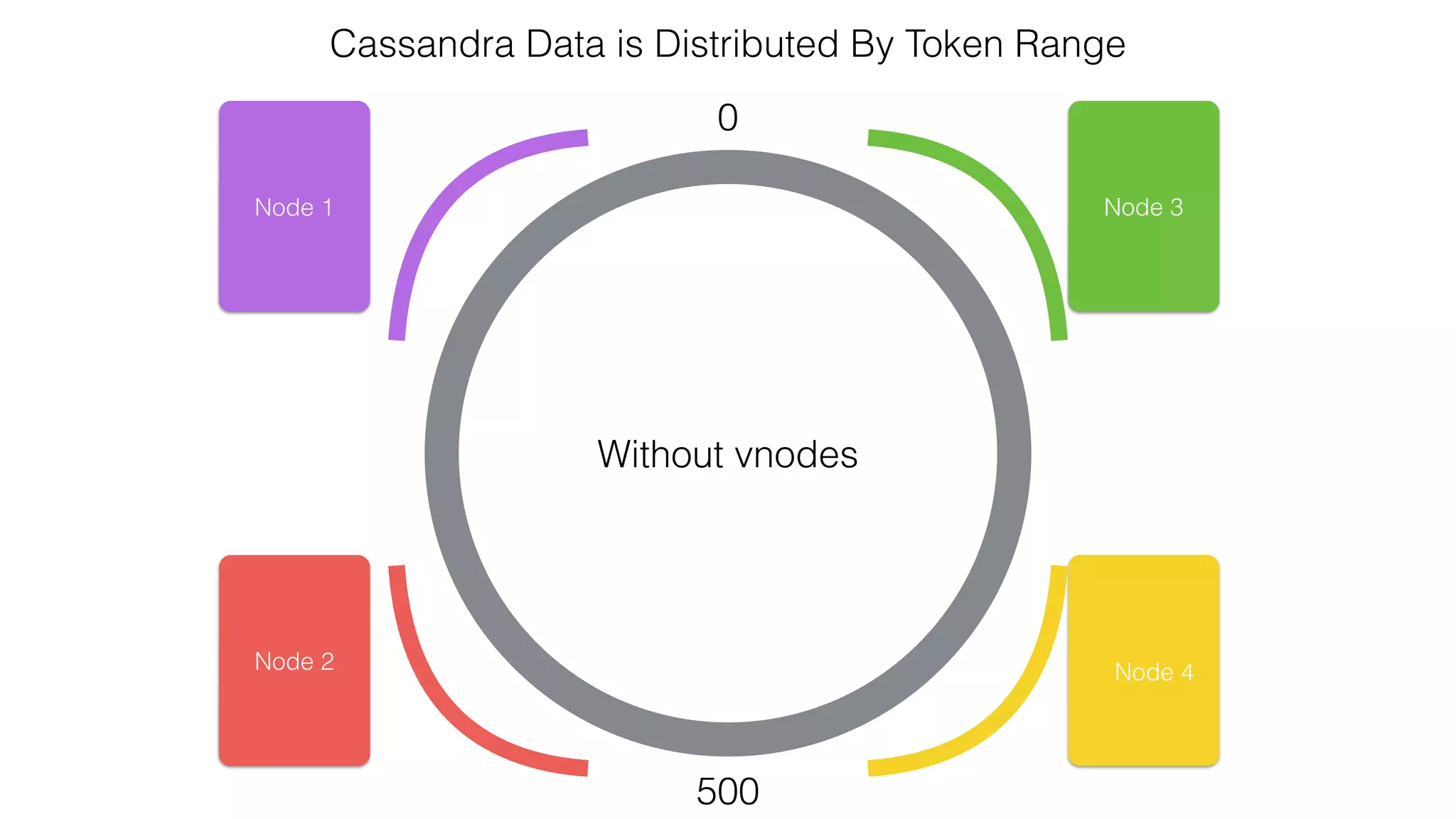
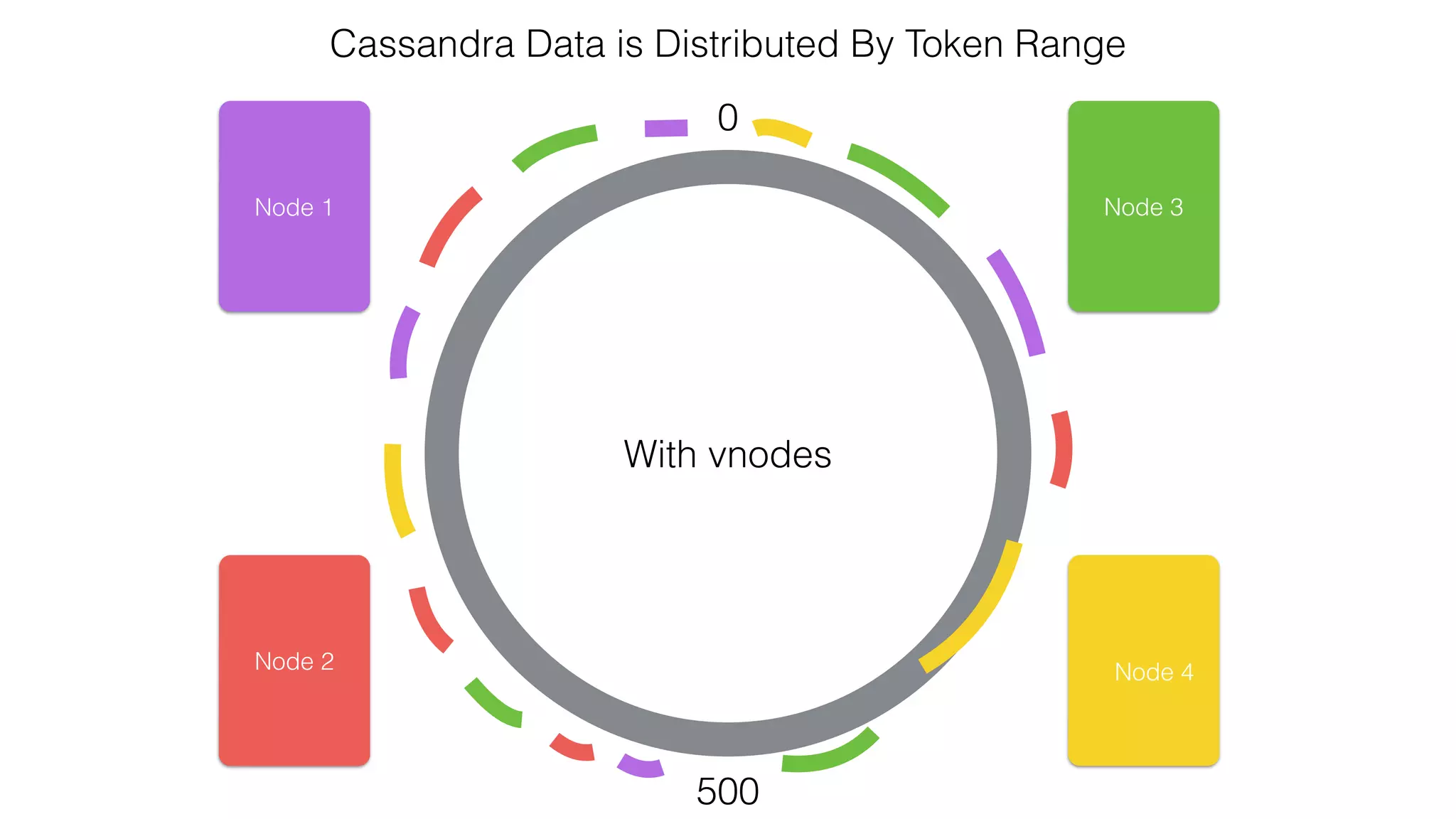
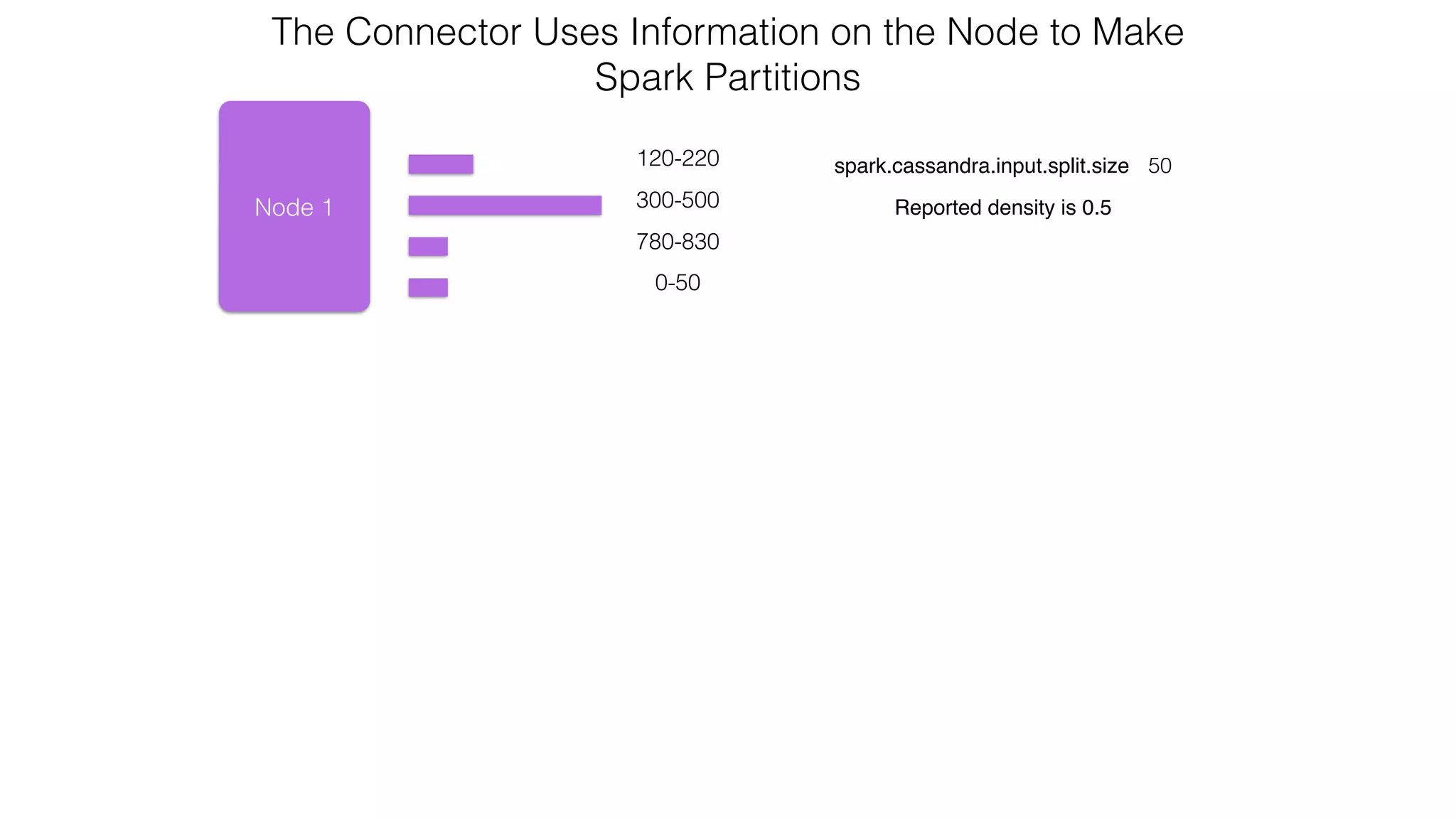
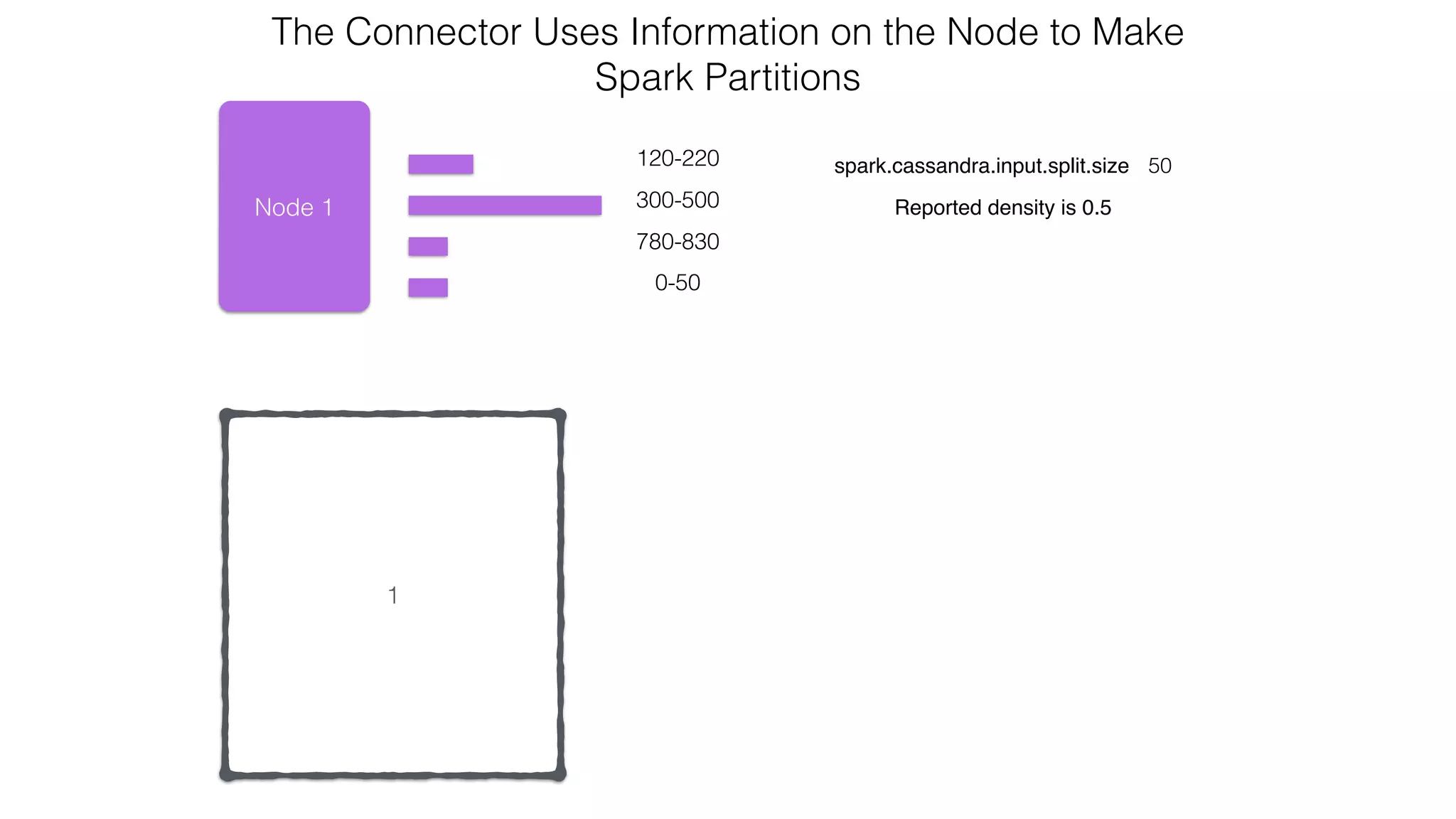
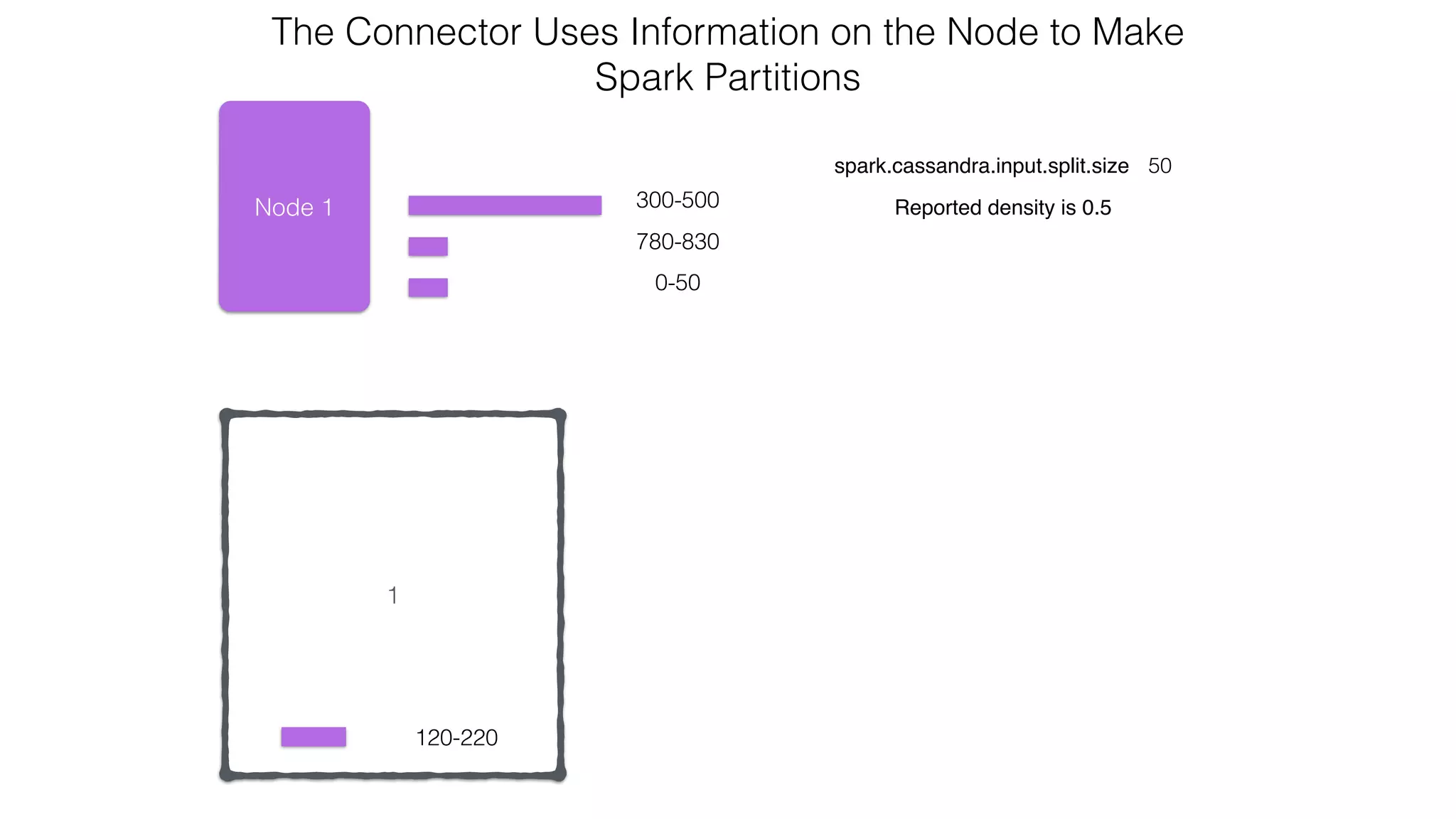
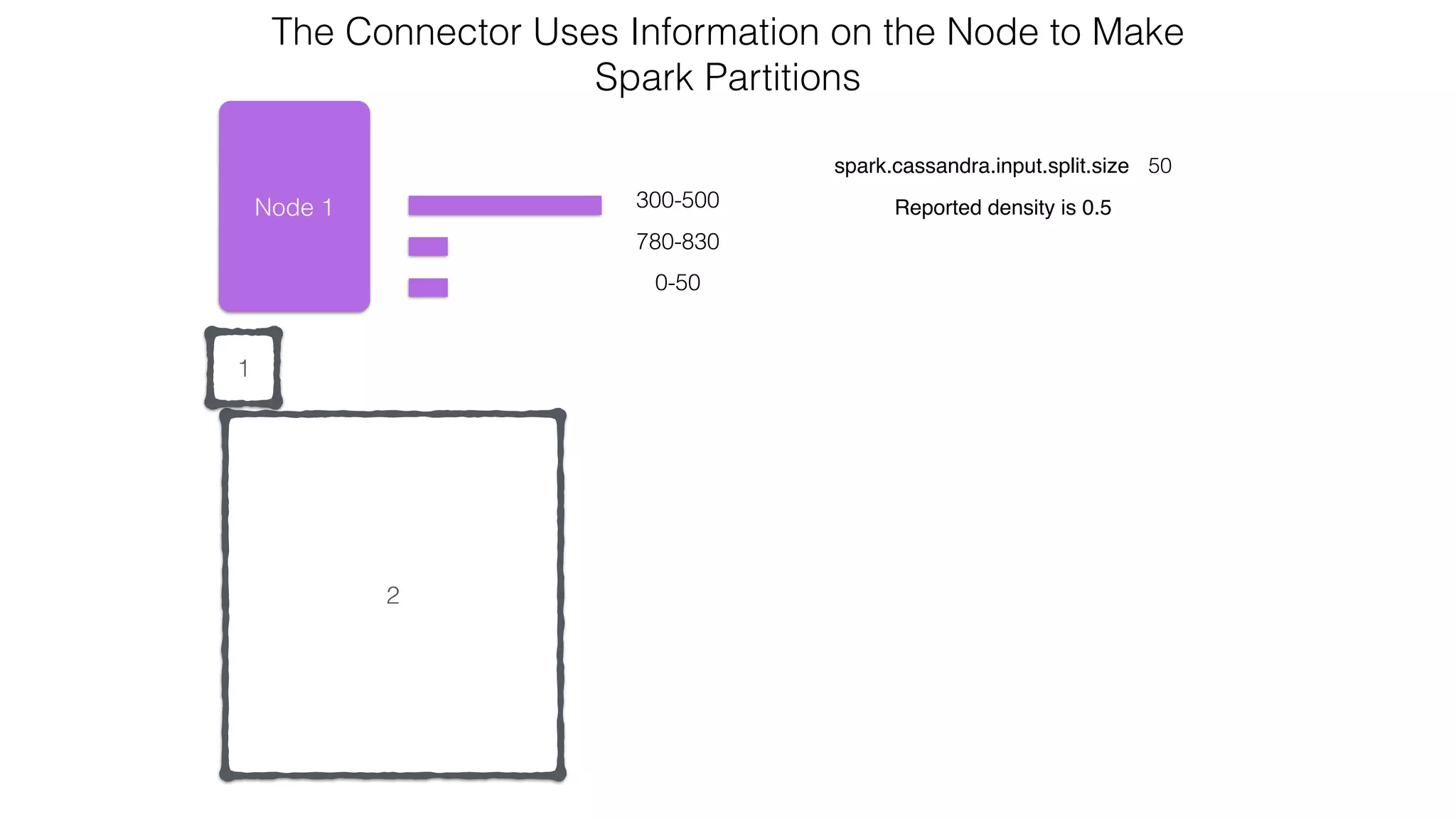
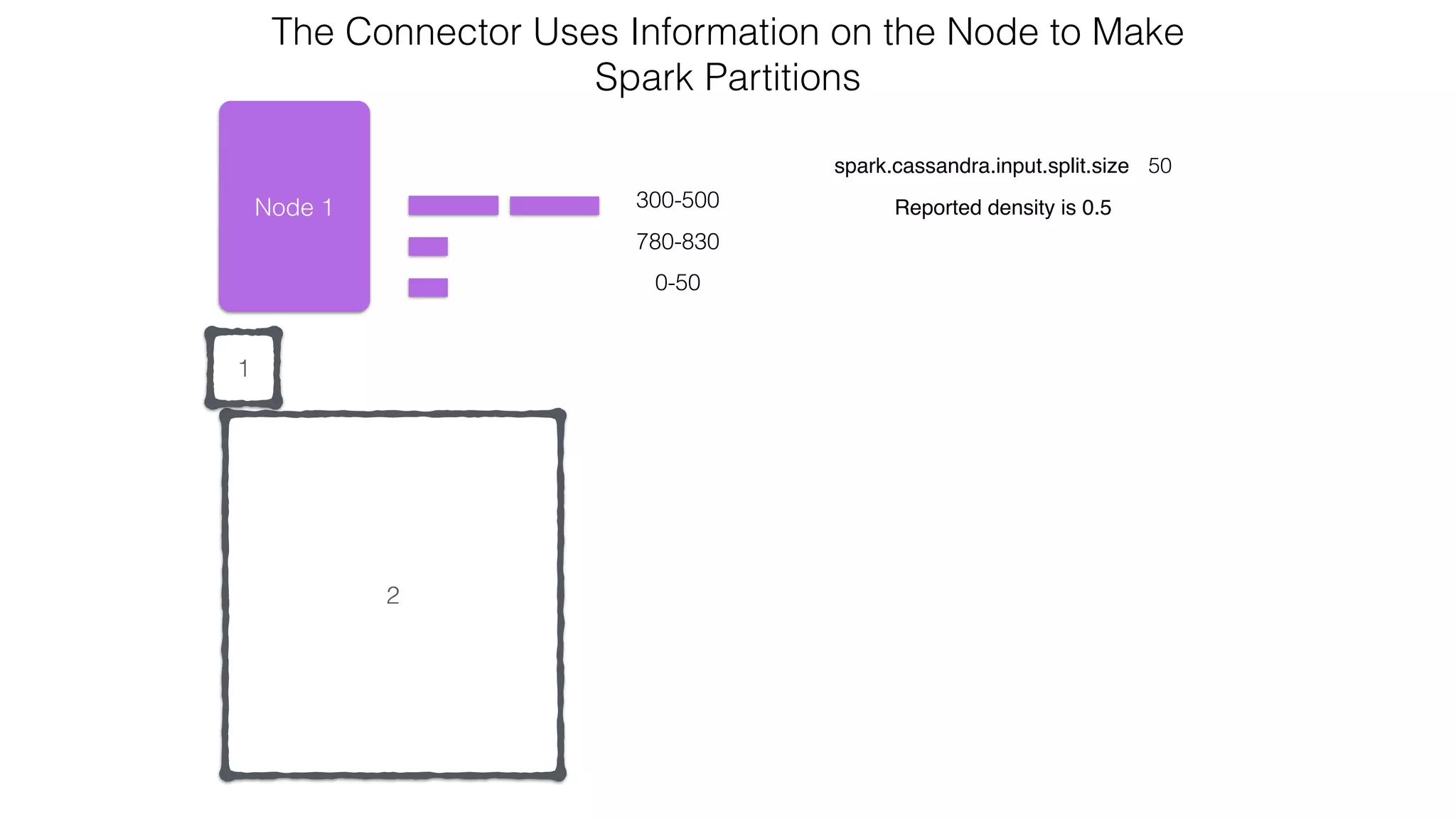
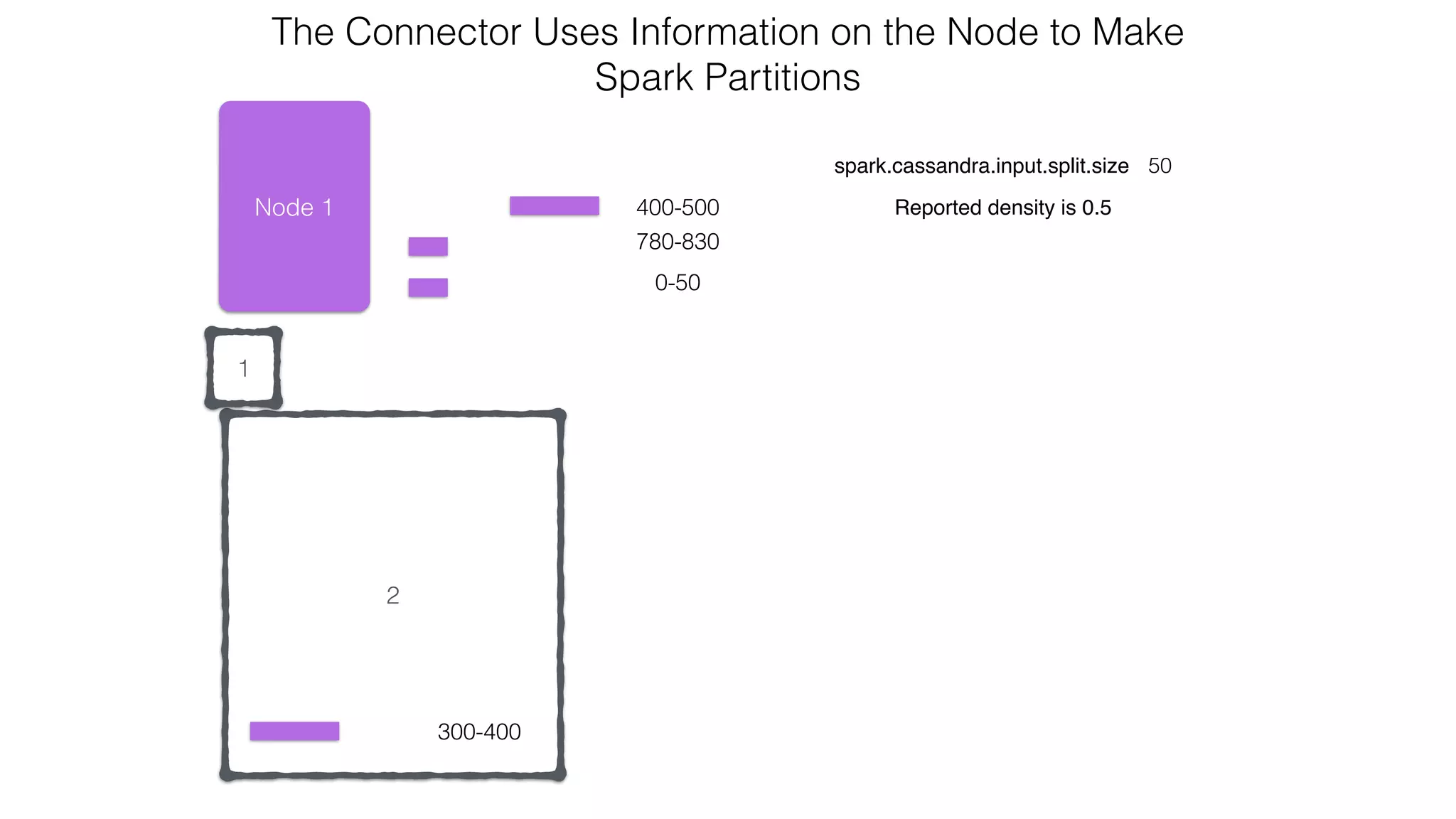
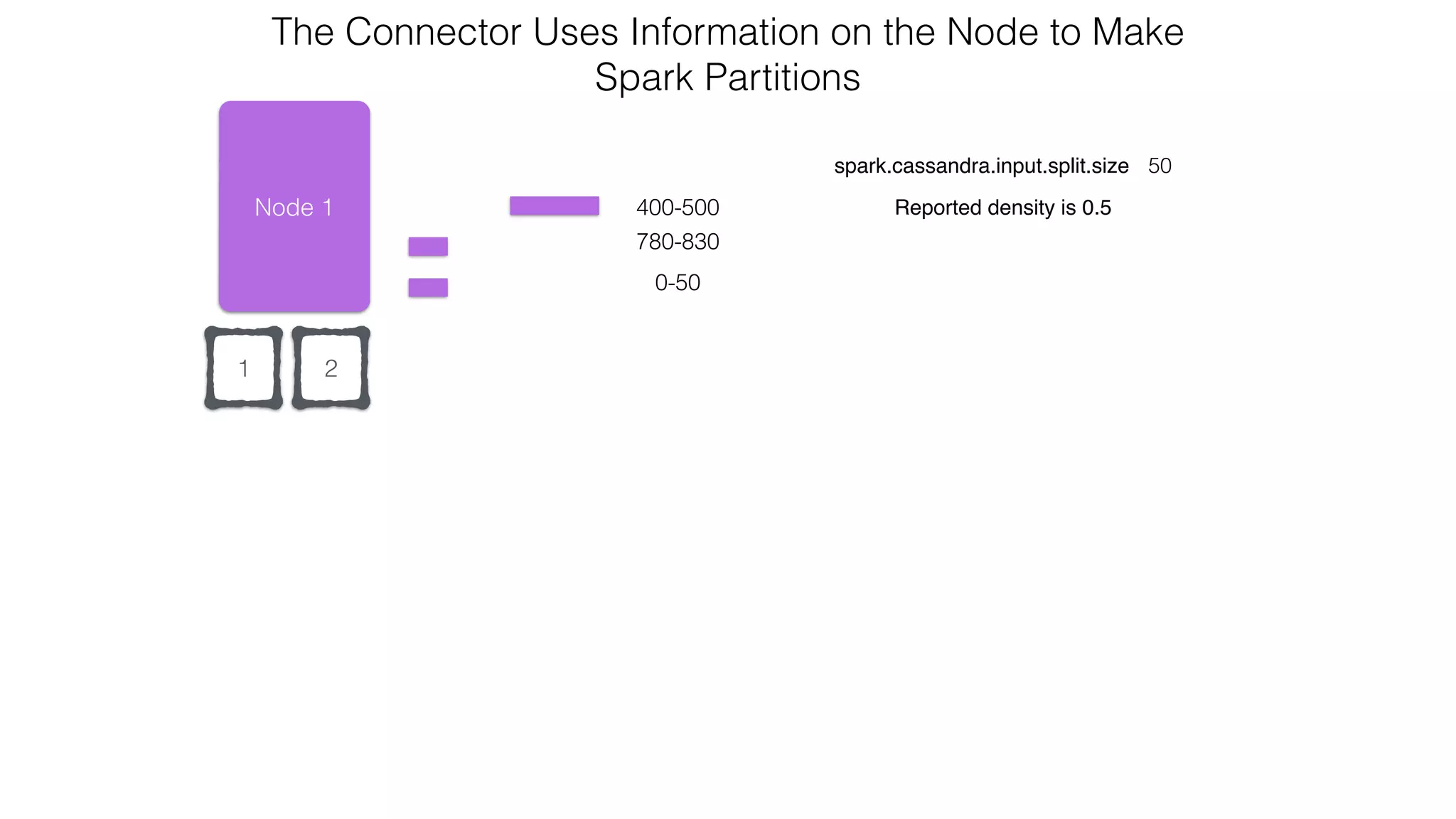
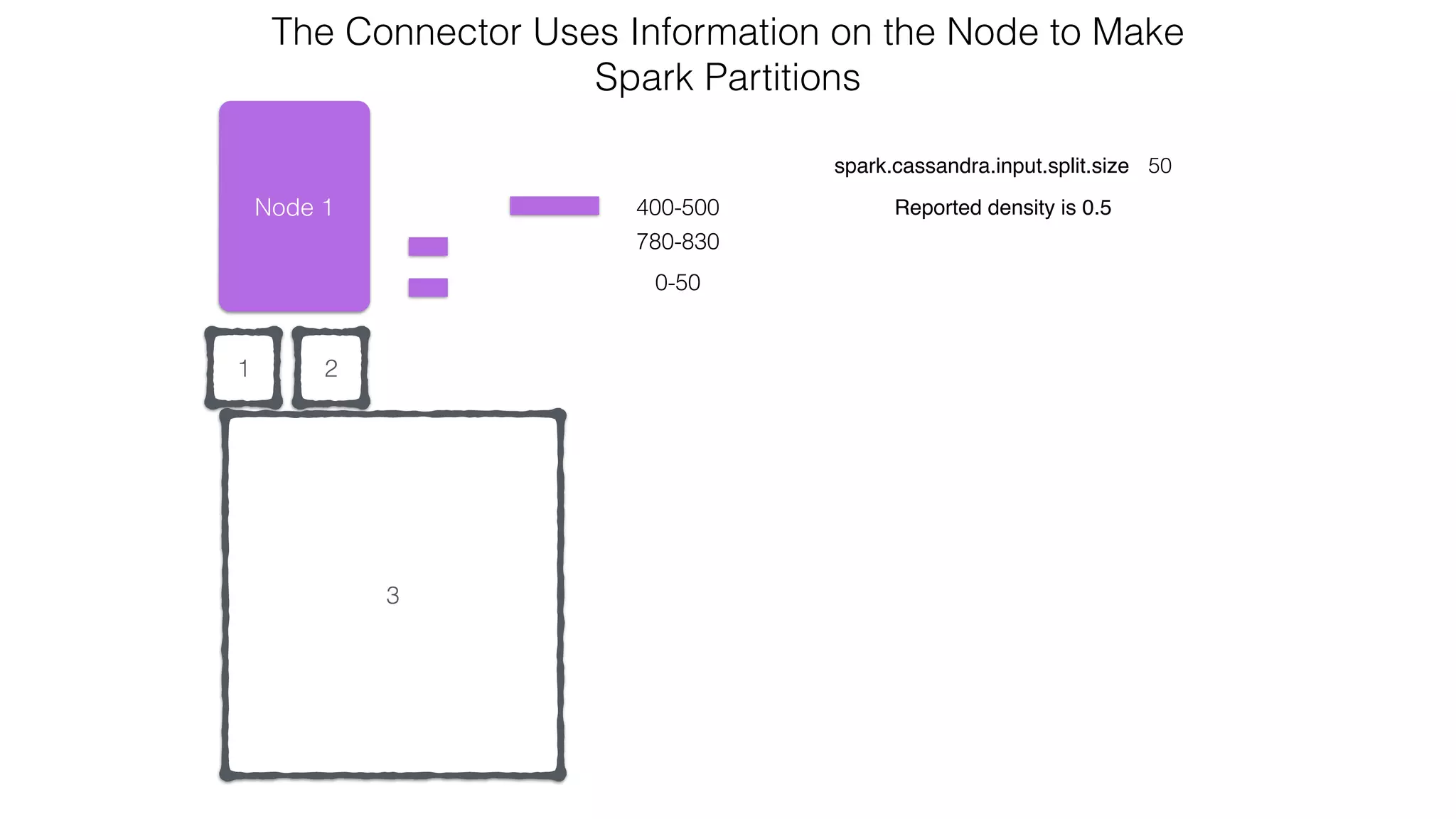
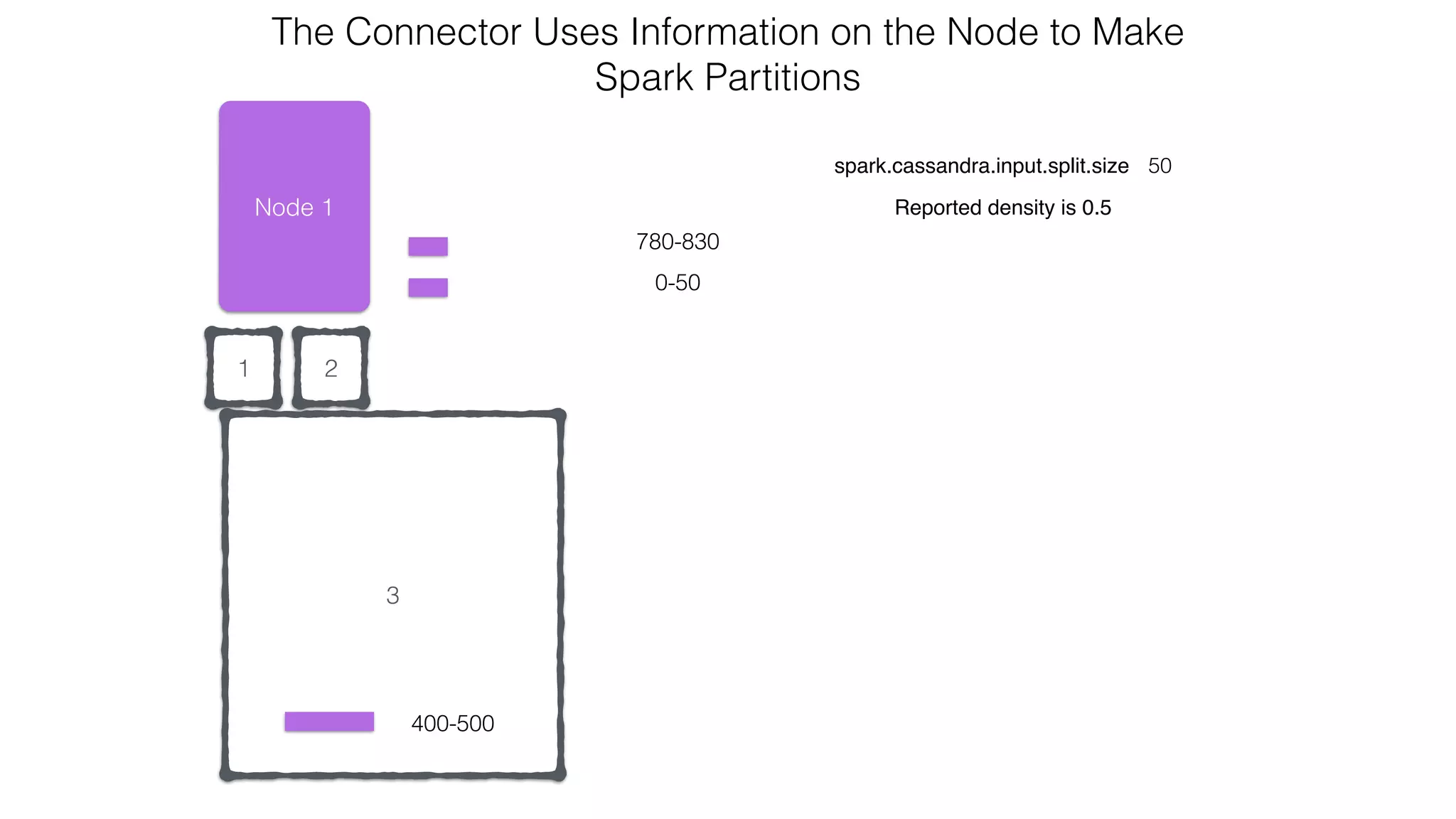
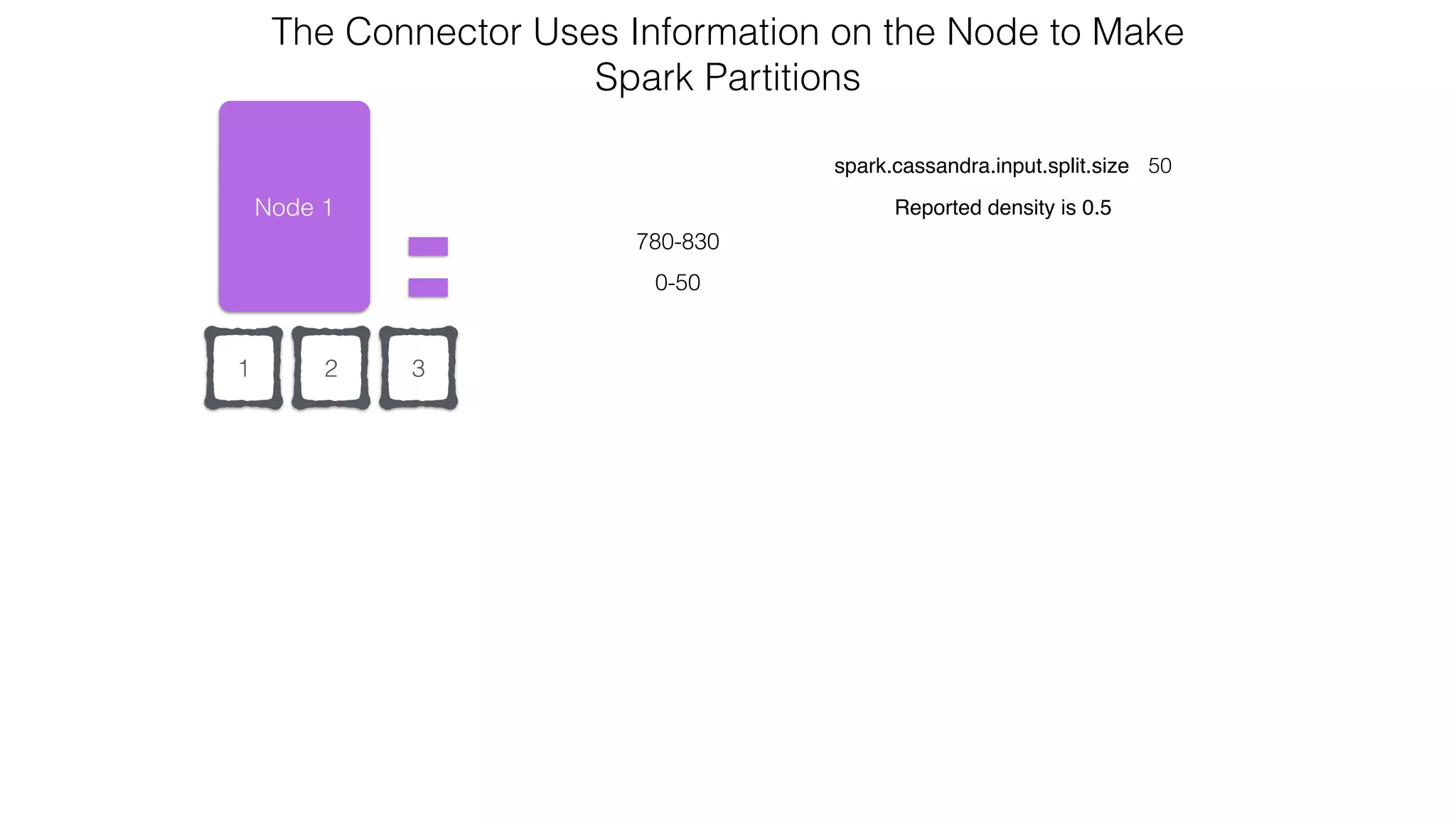
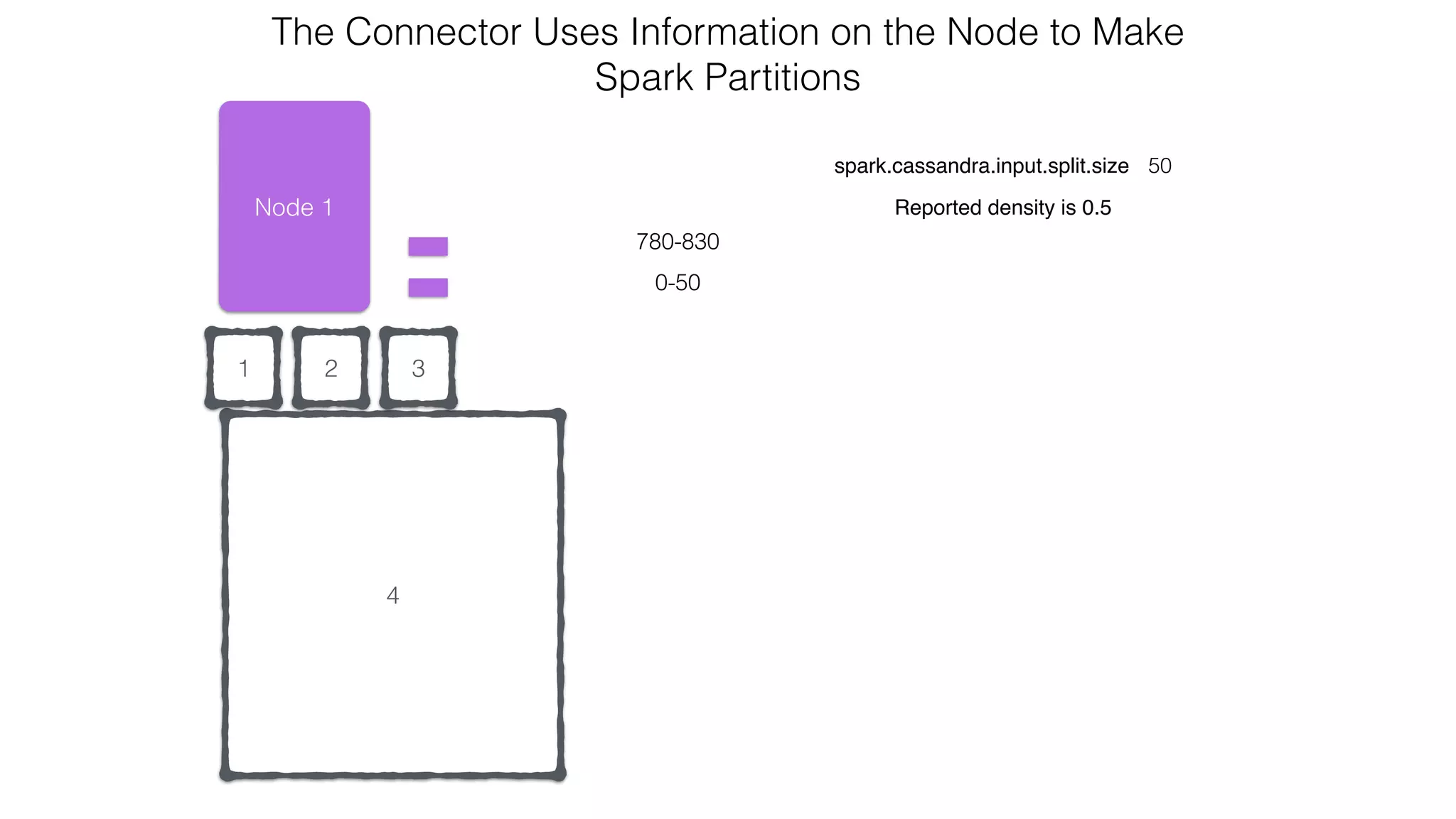
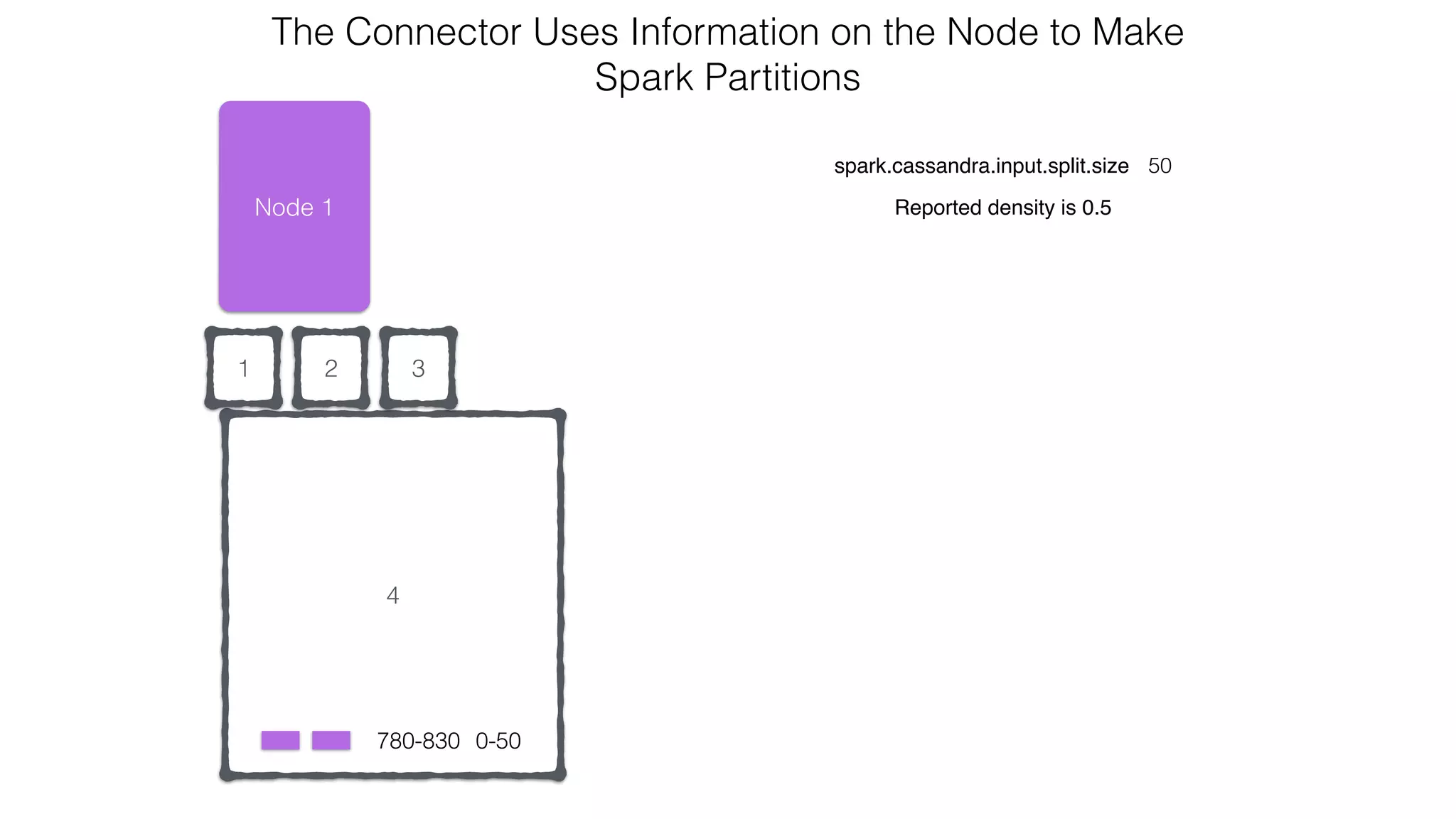
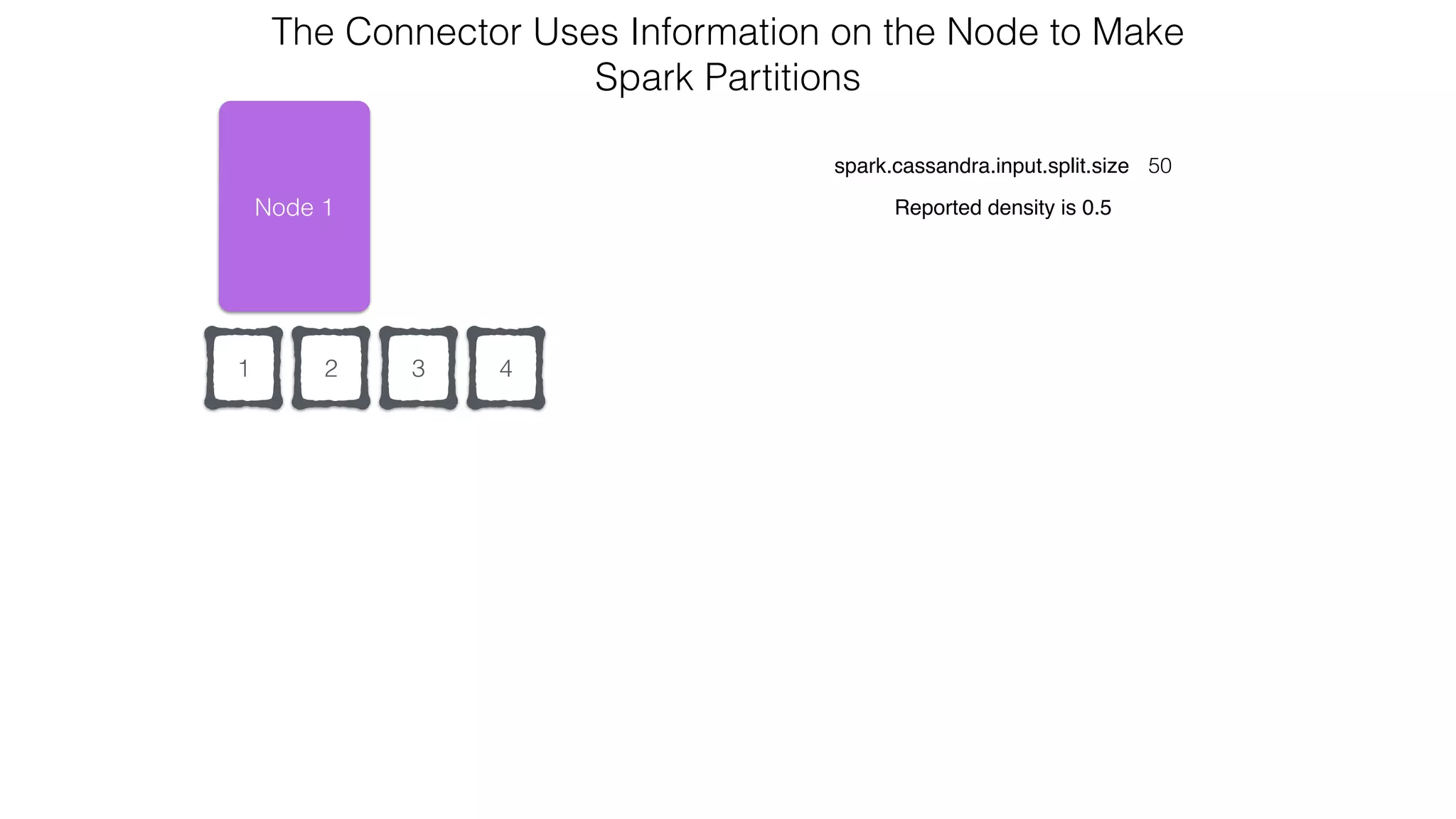
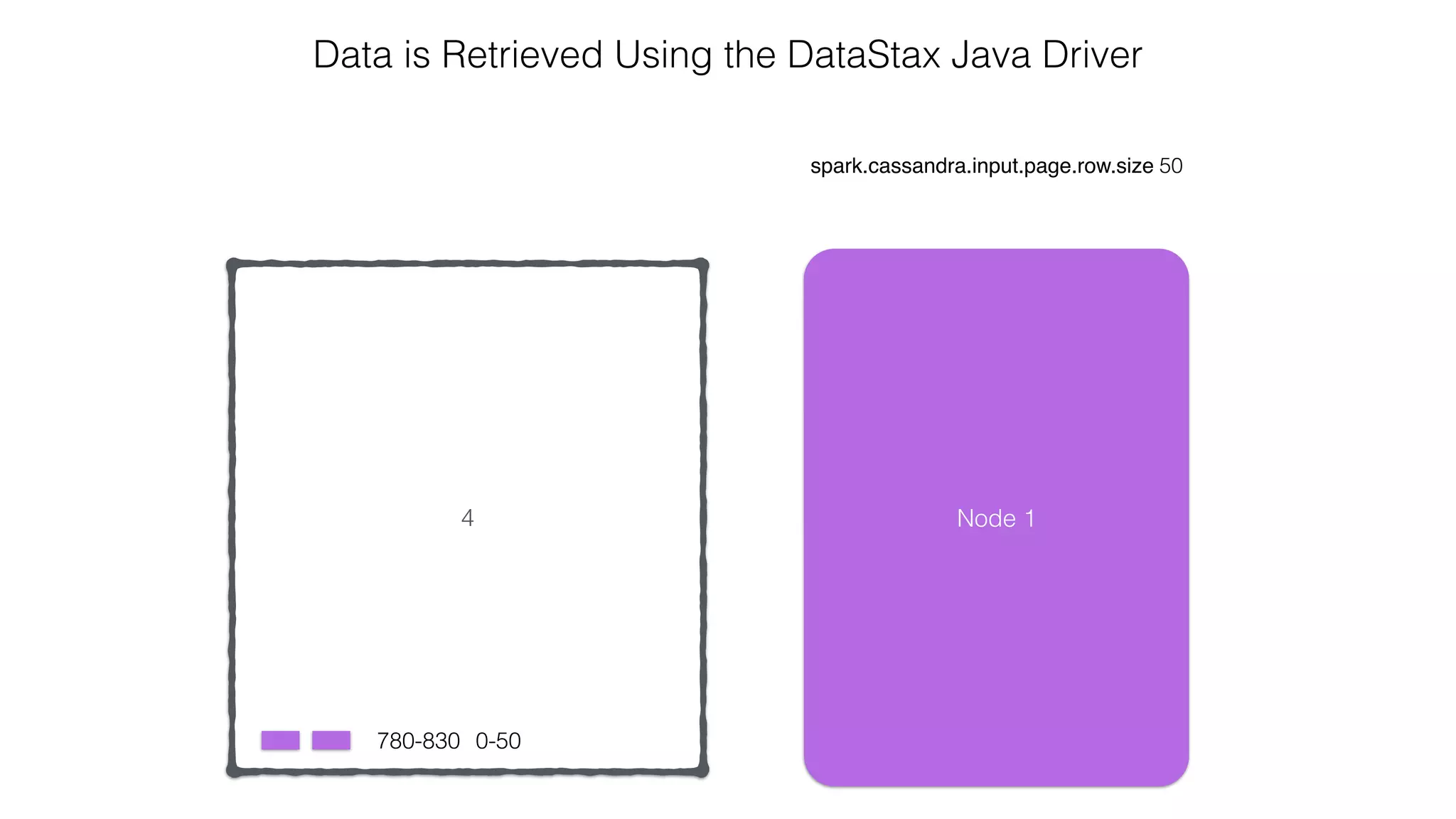


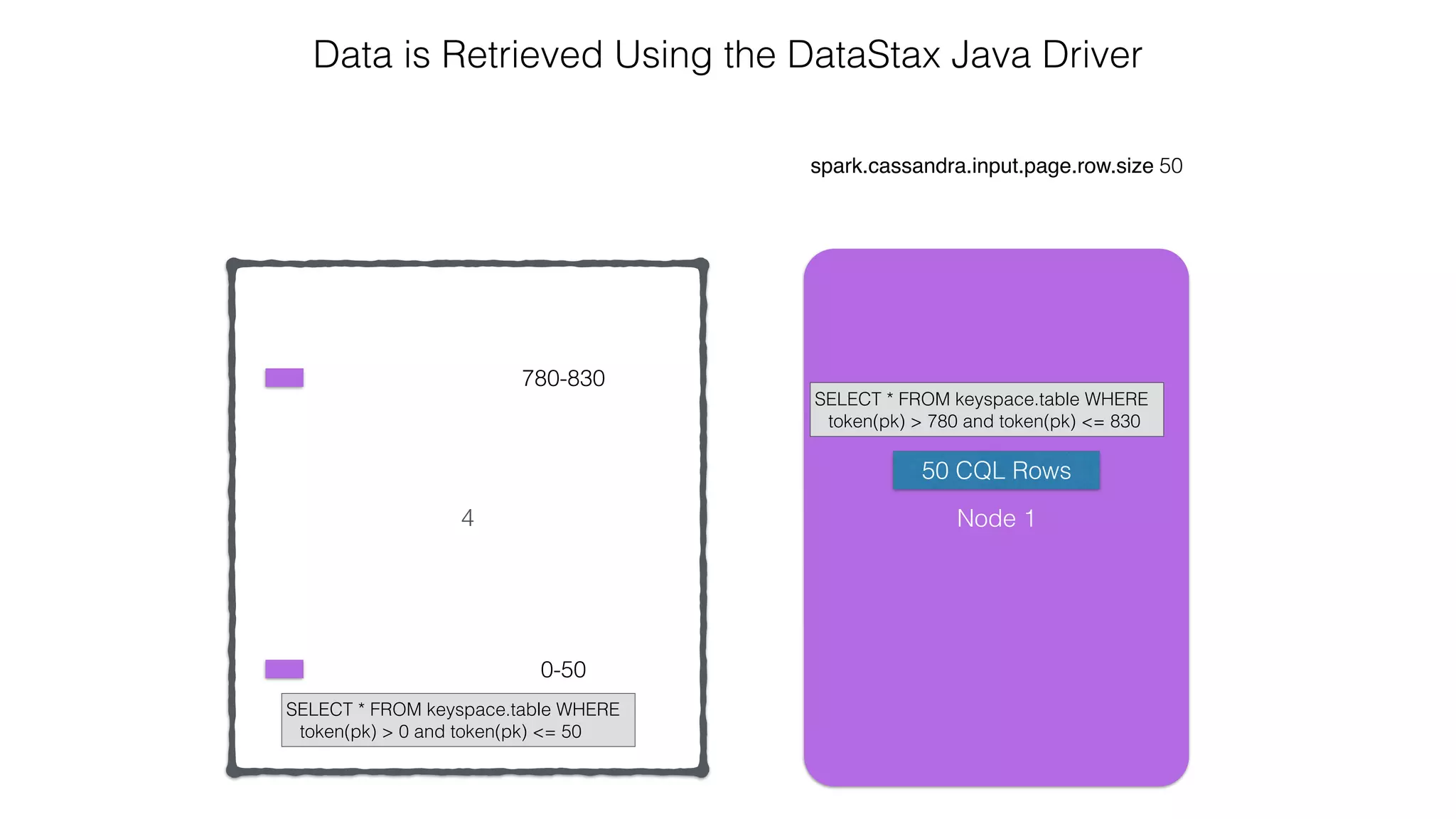


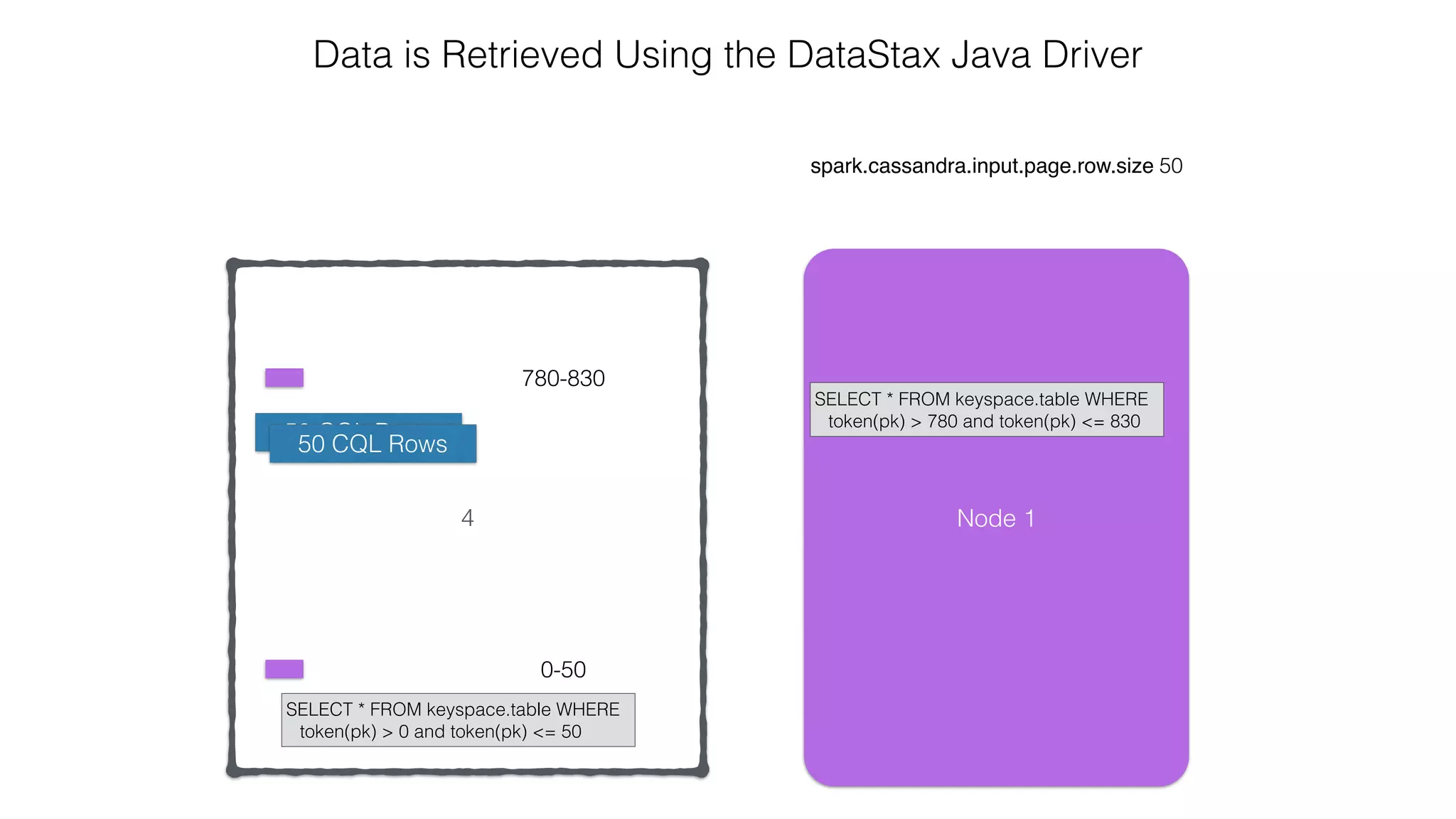
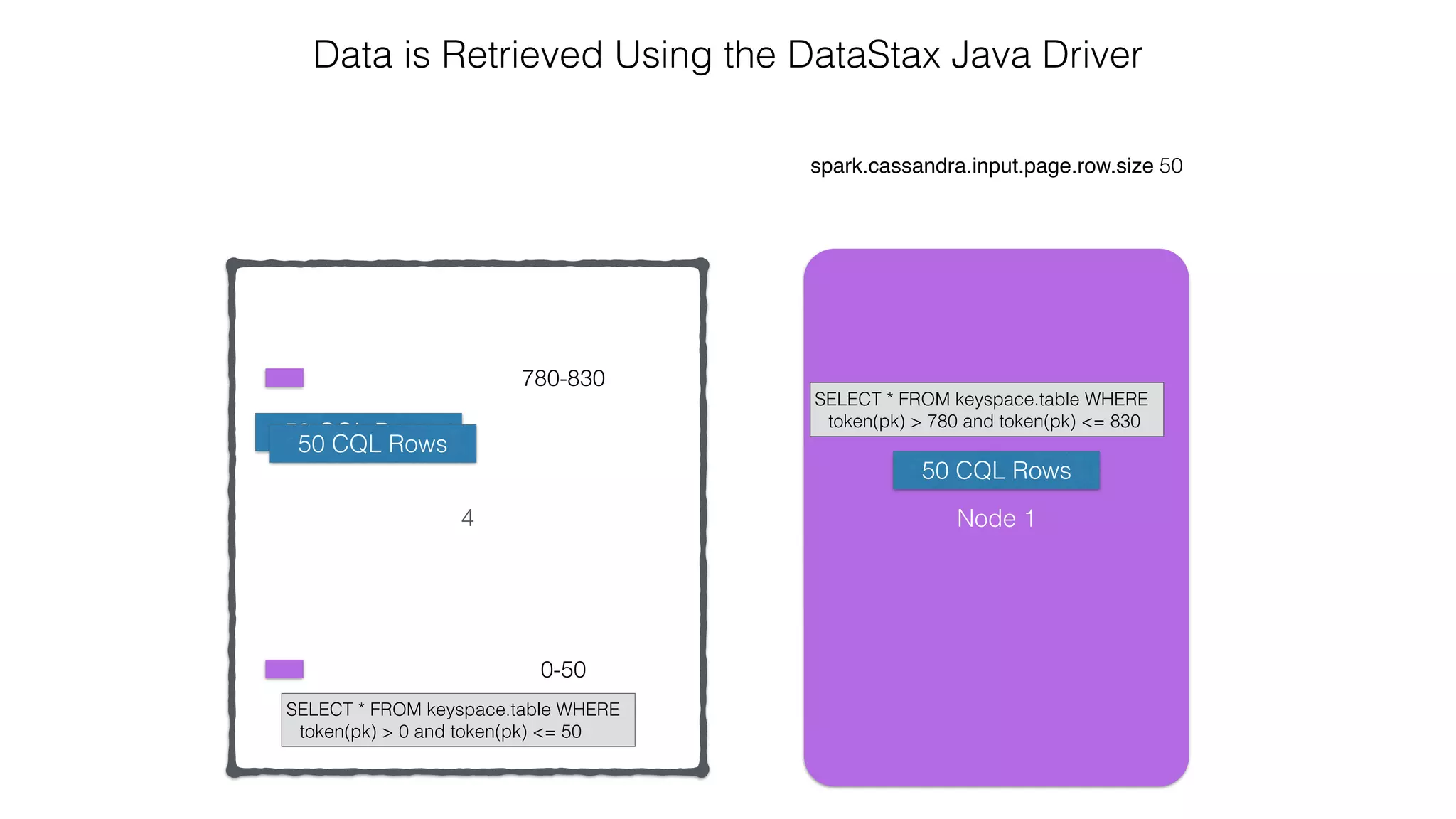
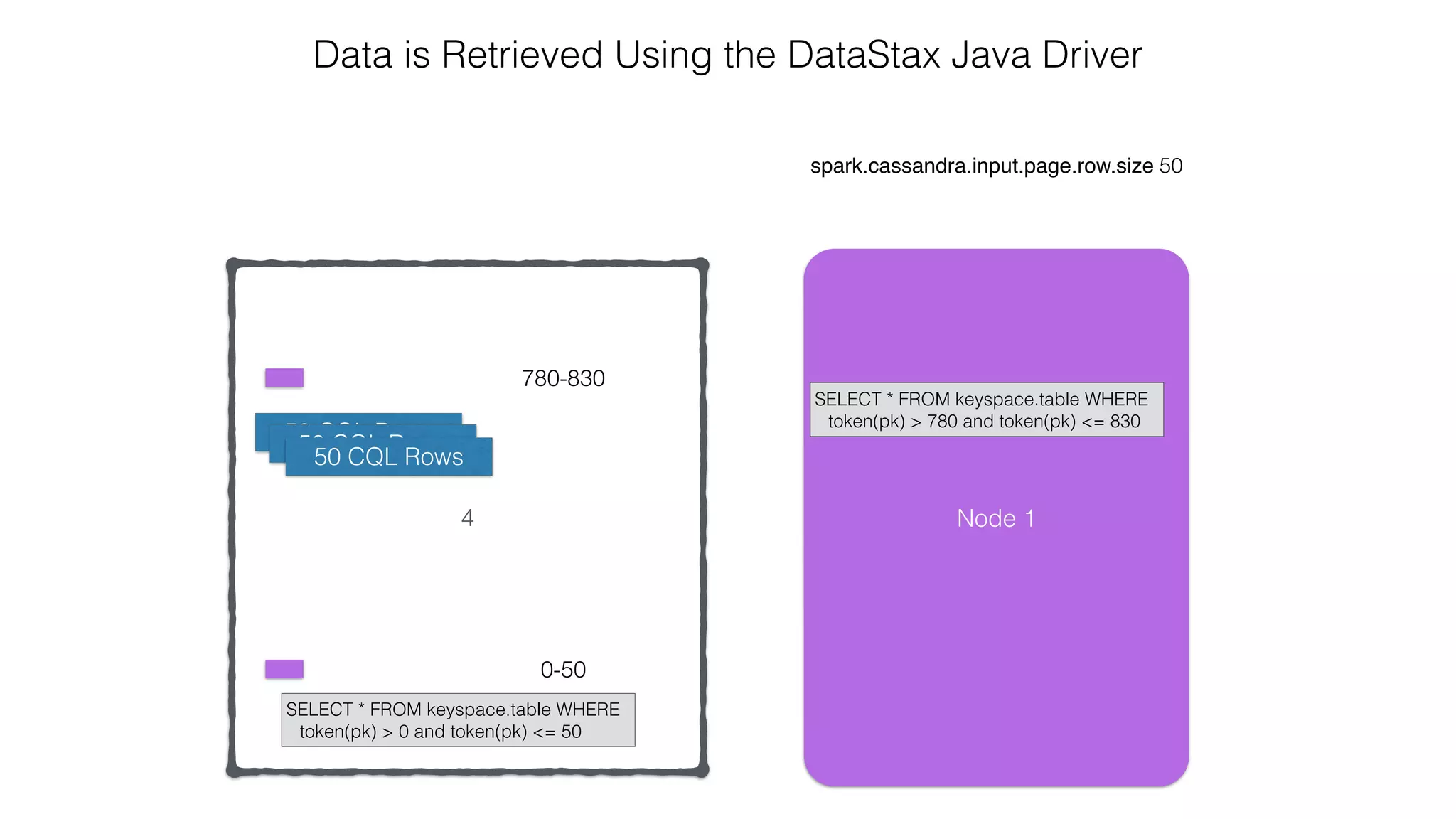
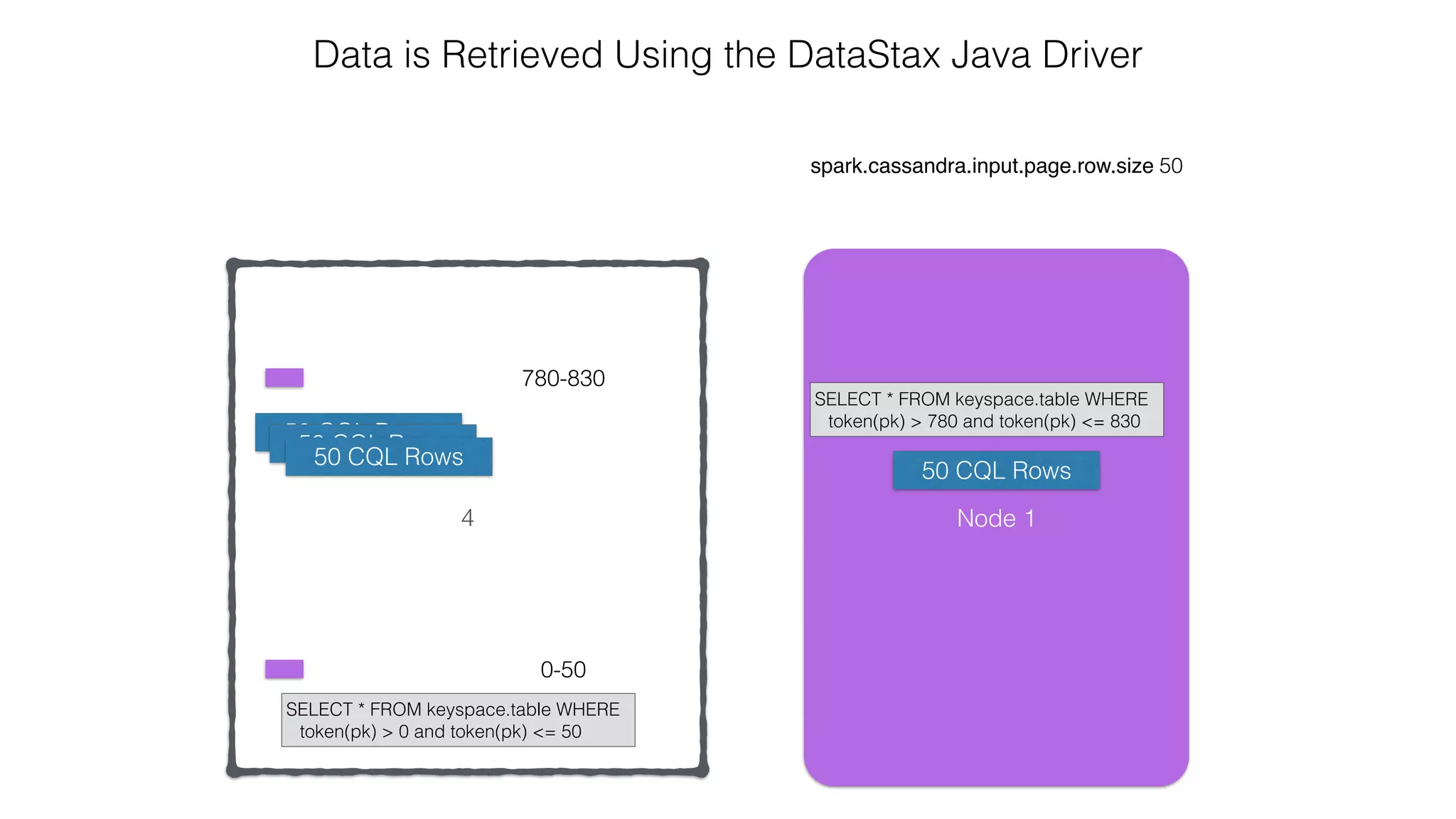
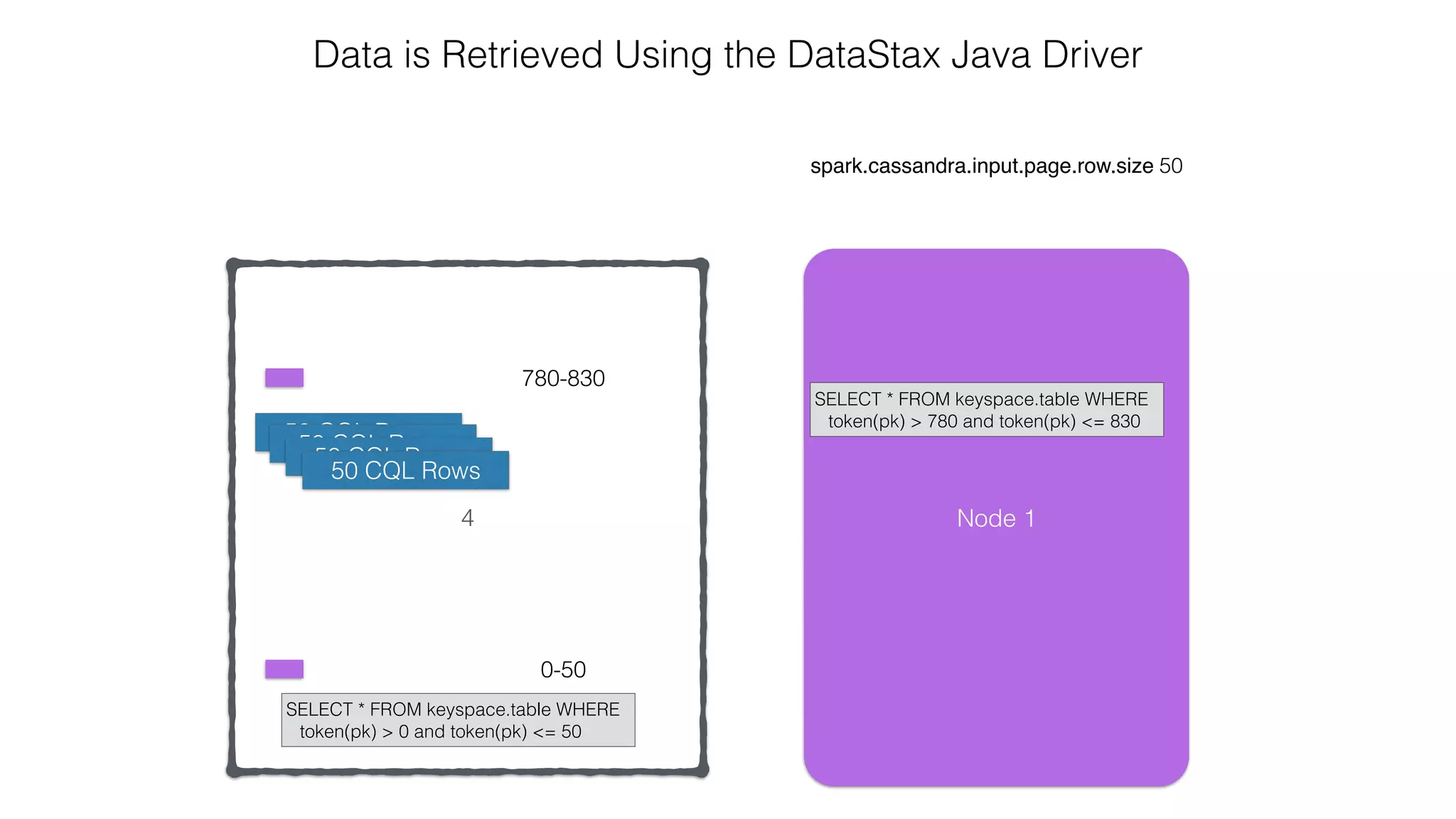
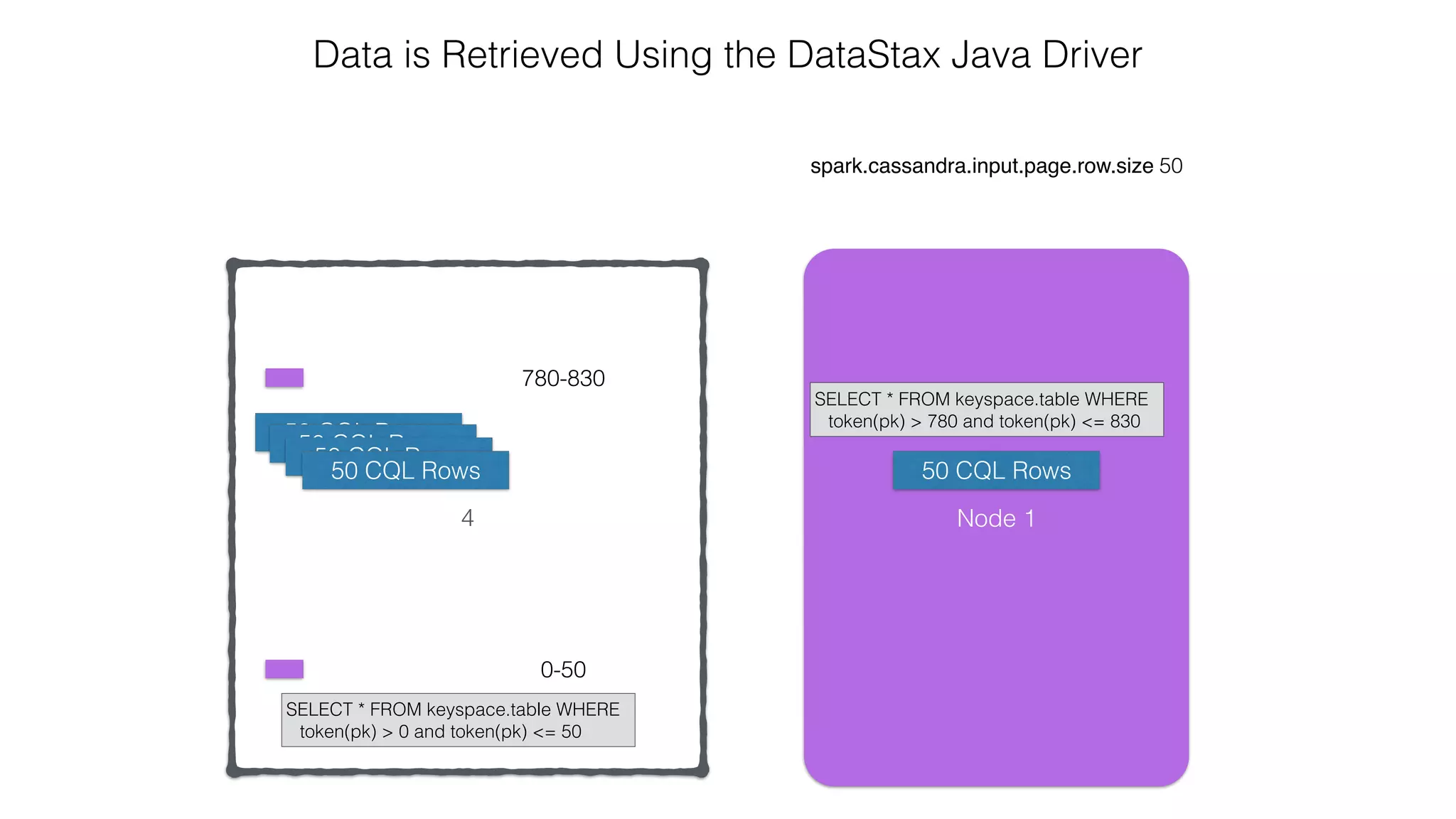





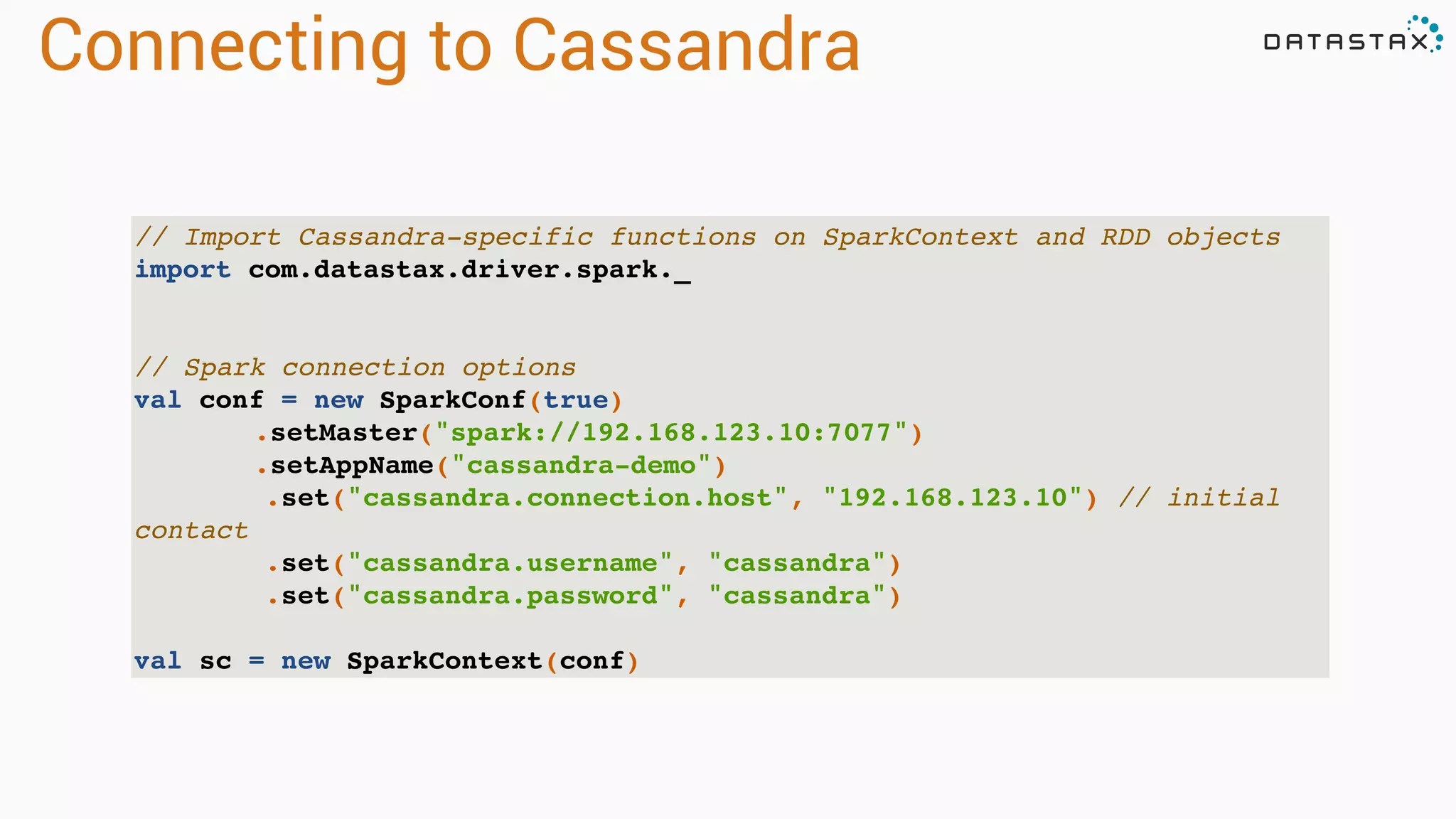
![Spark Streaming Example
val conf = new SparkConf(loadDefaults = true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster("spark://127.0.0.1:7077")
val sc = new SparkContext(conf)
val table: CassandraRDD[CassandraRow] = sc.cassandraTable("keyspace", "tweets")
val ssc = new StreamingContext(sc, Seconds(30))
val stream = KafkaUtils.createStream[String, String, StringDecoder,
StringDecoder](
ssc, kafka.kafkaParams, Map(topic -> 1), StorageLevel.MEMORY_ONLY)
stream.map(_._2).countByValue().saveToCassandra("demo", "wordcount")
ssc.start()
ssc.awaitTermination()
Initialization
Transformations
and Action
CassandraRDD
Stream Initialization](https://image.slidesharecdn.com/apachecassandraandspark-150303113512-conversion-gate01/75/Apache-cassandra-and-spark-you-got-the-the-lighter-let-s-start-the-fire-90-2048.jpg)
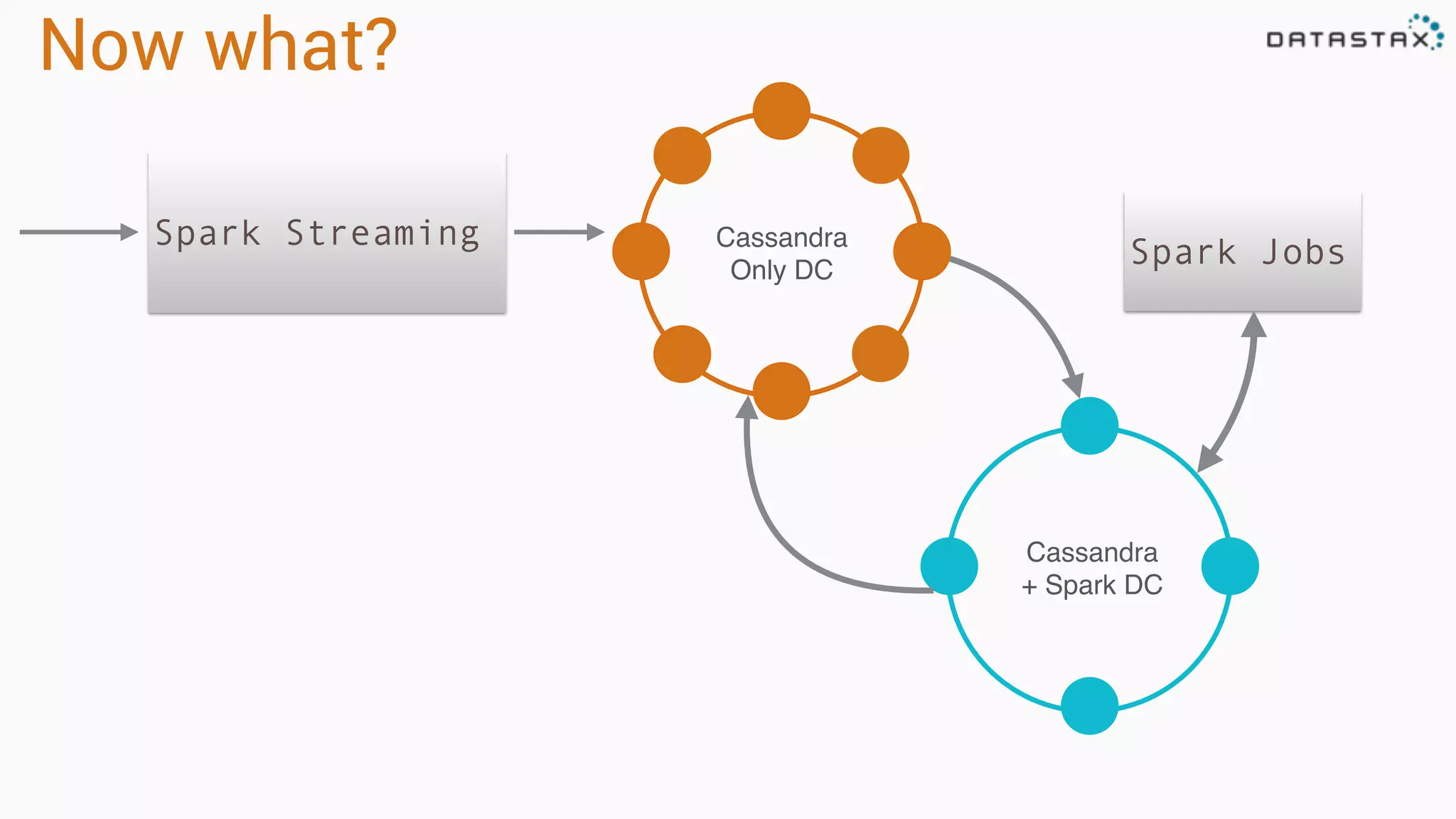

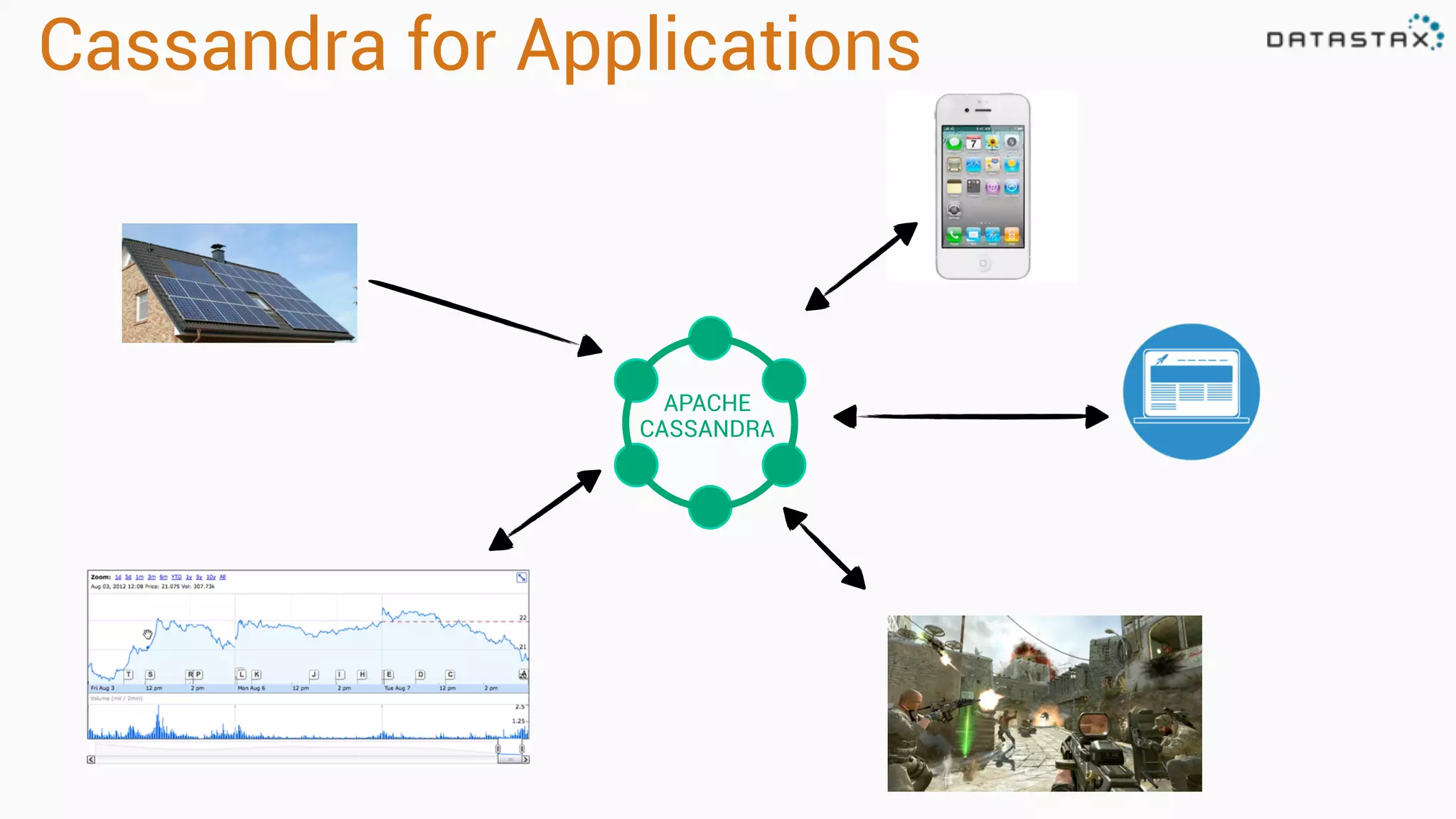
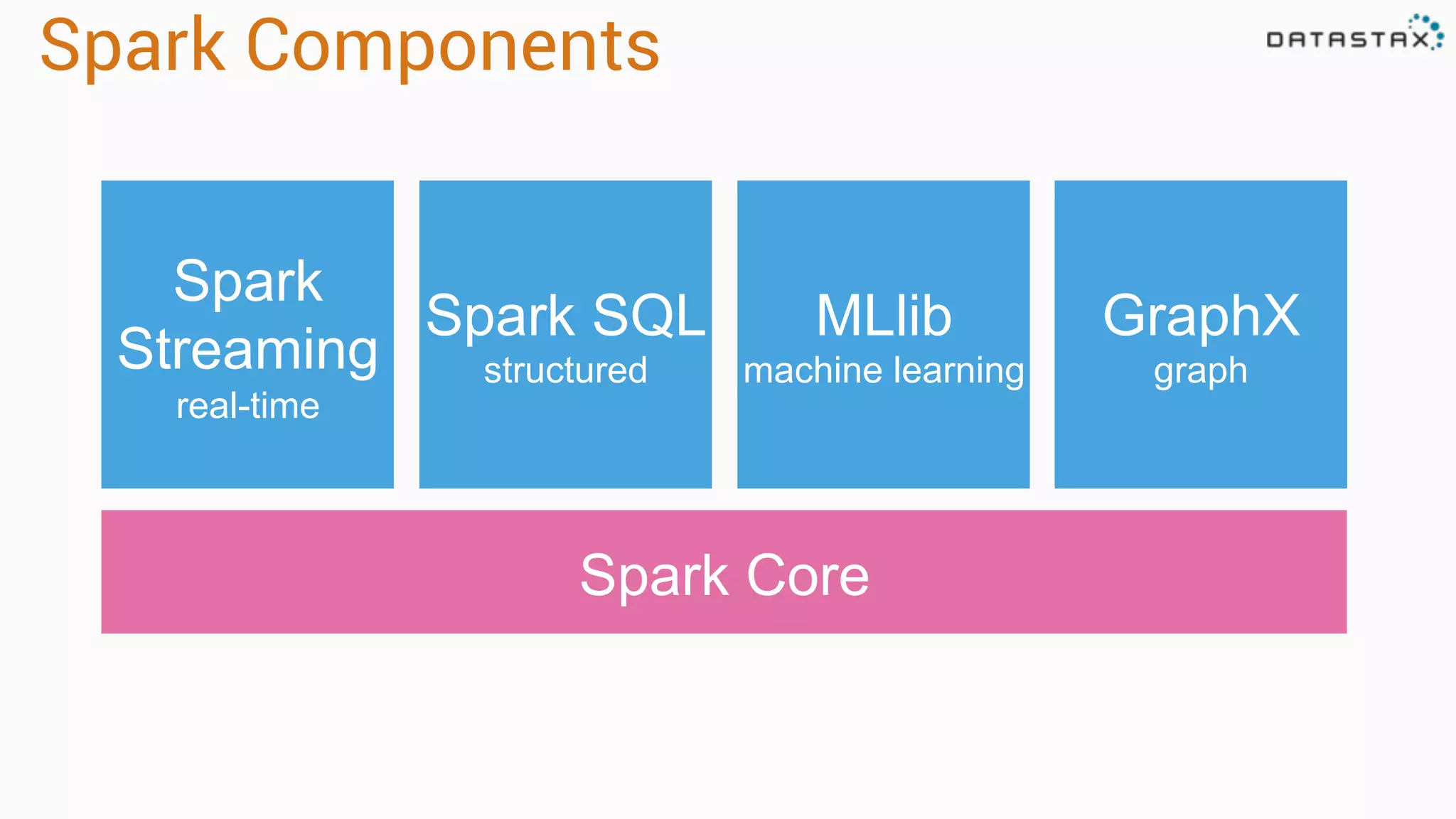
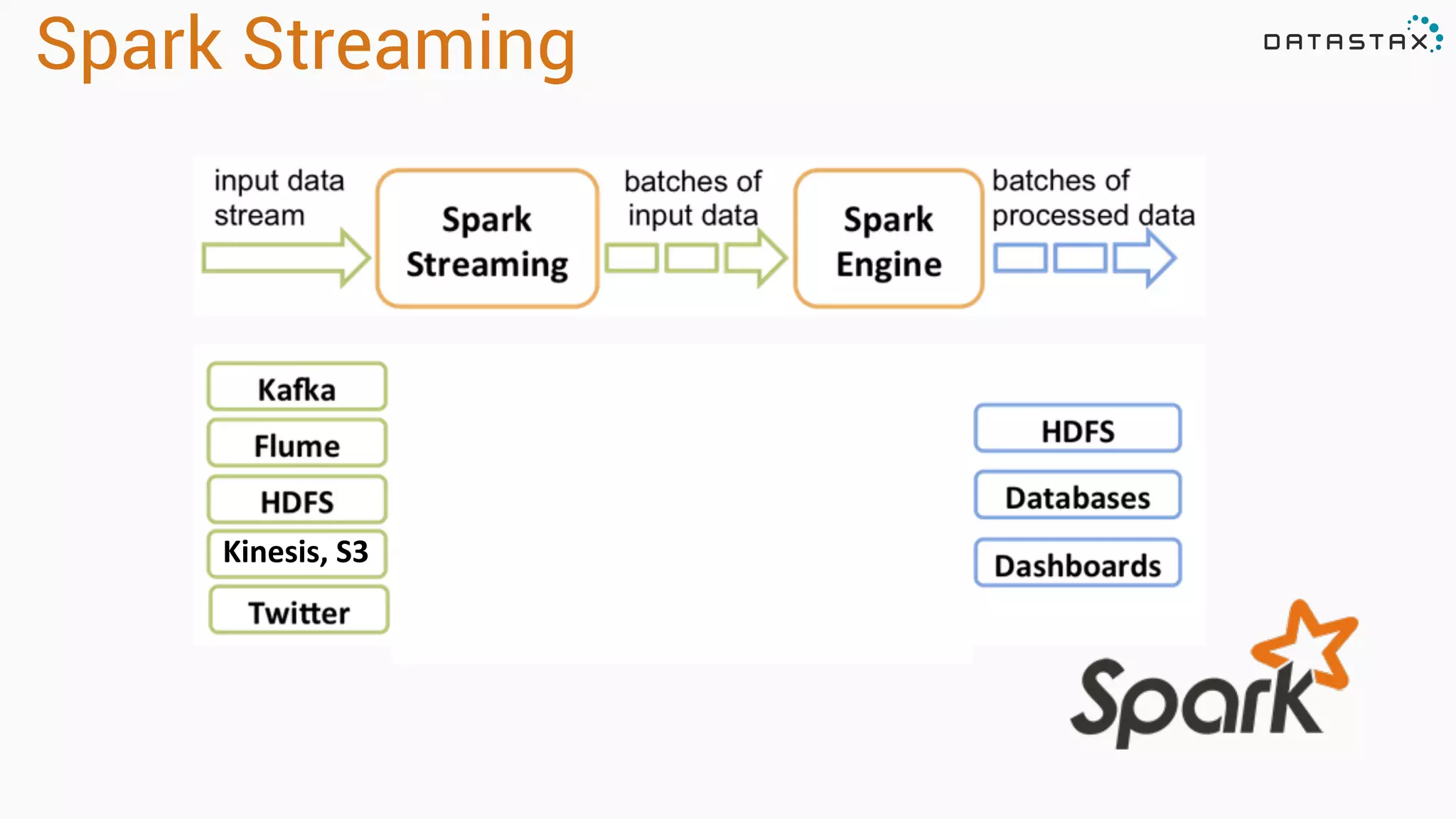
The document discusses the integration of Apache Cassandra and Apache Spark, highlighting their scalability, resilience, and performance enhancements for data processing. It details the features of both technologies, including the capabilities of Spark's RDDs and the use of the Spark-Cassandra connector for seamless data access. Additionally, it provides technical examples of creating and accessing tables in Cassandra while utilizing Spark for advanced data analysis and manipulation.










































































