Download as PDF, PPTX


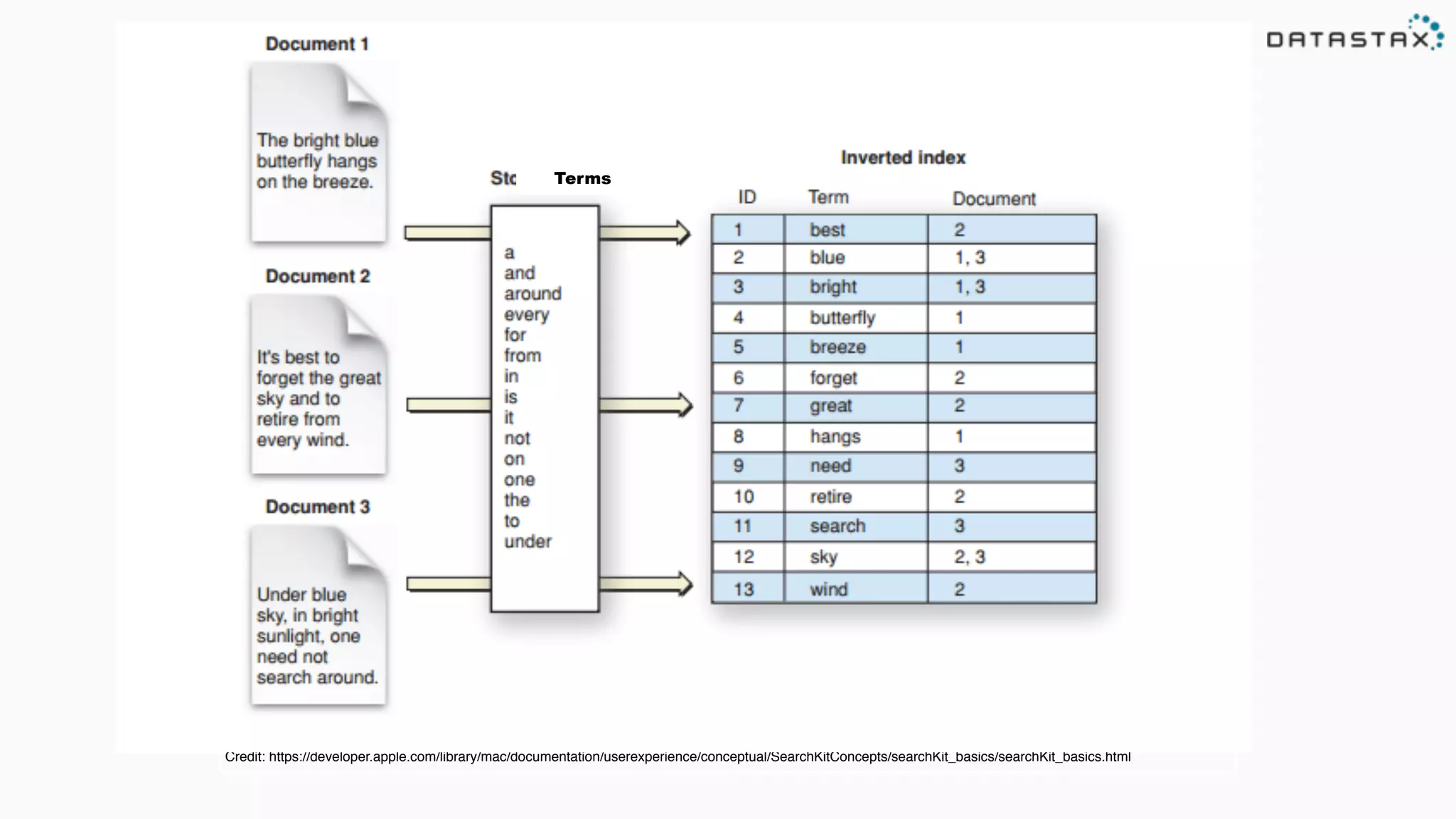
![The bright blue butterfly hangs on the breeze.
[the] [bright] [blue] [butterfly] [hangs] [on] [the] [breeze]
Tokens](https://image.slidesharecdn.com/lovetriangle-150701134944-lva1-app6892/75/A-Cassandra-Solr-Spark-Love-Triangle-Using-DataStax-Enterprise-5-2048.jpg)













![Attaching to Spark and Cassandra
// Import Cassandra-specific functions on SparkContext and RDD objects
import org.apache.spark.{SparkContext, SparkConf}
import com.datastax.spark.connector._
/** The setMaster("local") lets us run & test the job right in our IDE */
val conf = new SparkConf(true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster(“local[*]")
.setAppName(getClass.getName)
// Optionally
.set("cassandra.username", "cassandra")
.set("cassandra.password", “cassandra")
val sc = new SparkContext(conf)](https://image.slidesharecdn.com/lovetriangle-150701134944-lva1-app6892/75/A-Cassandra-Solr-Spark-Love-Triangle-Using-DataStax-Enterprise-46-2048.jpg)


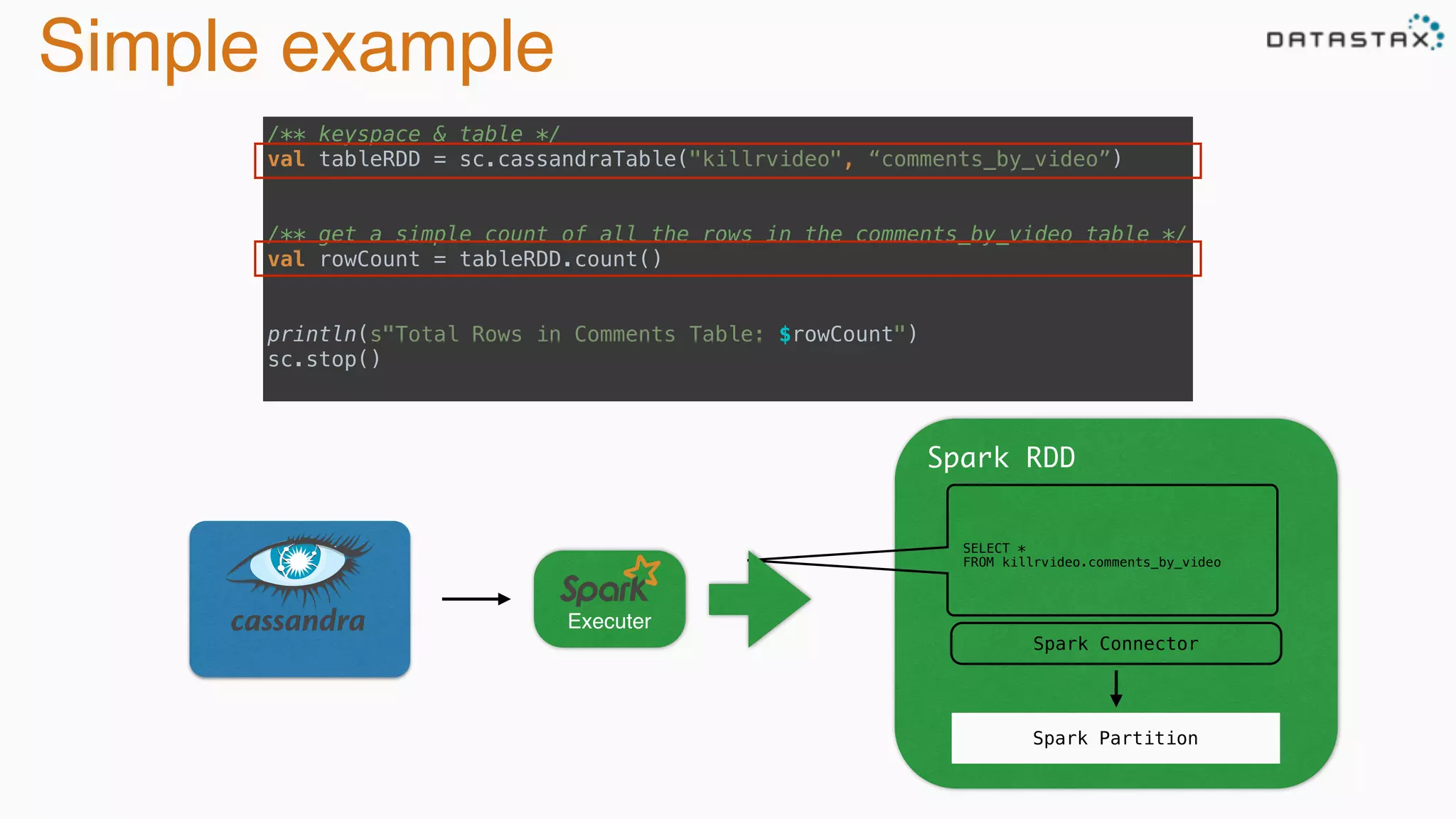
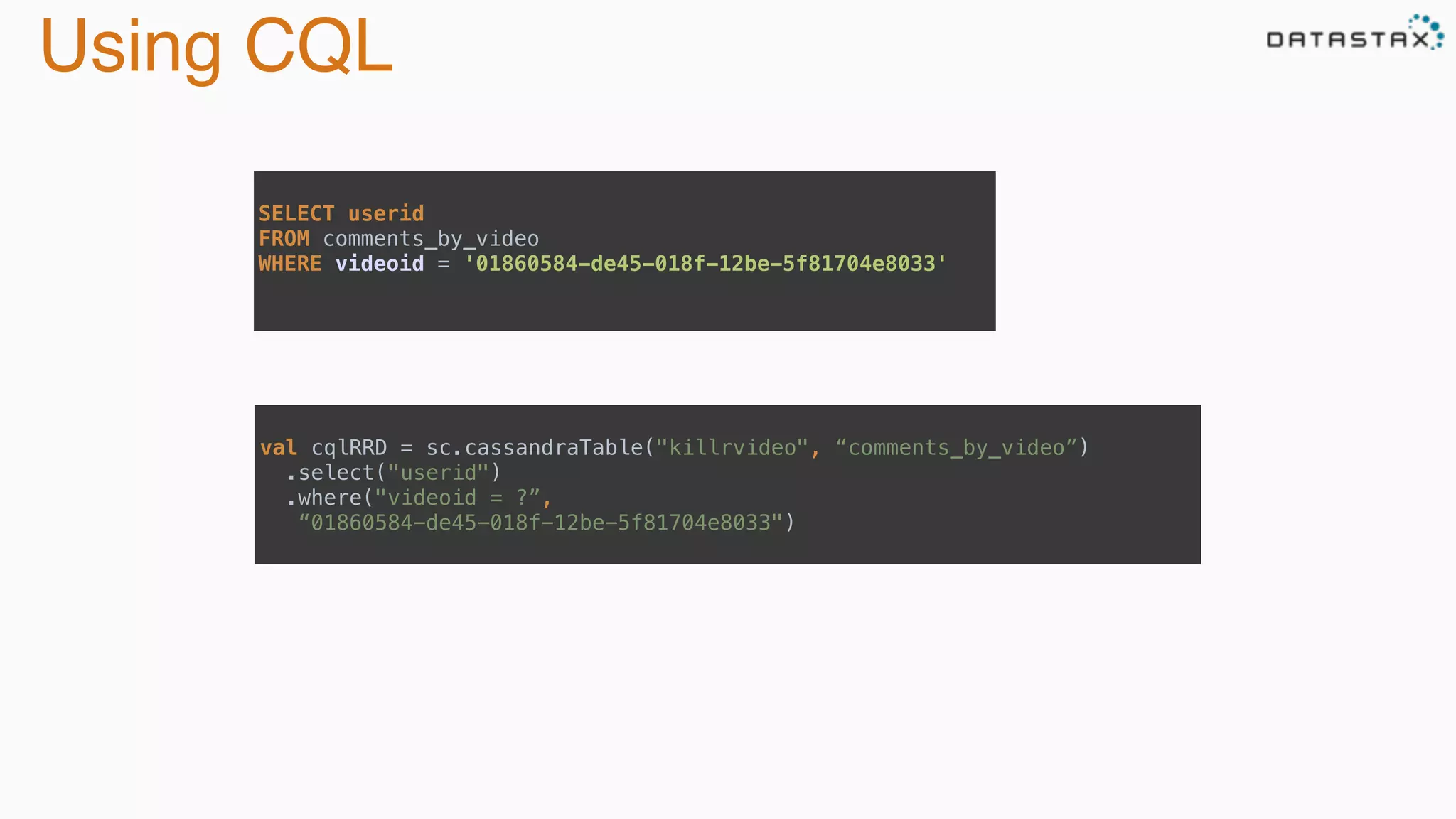
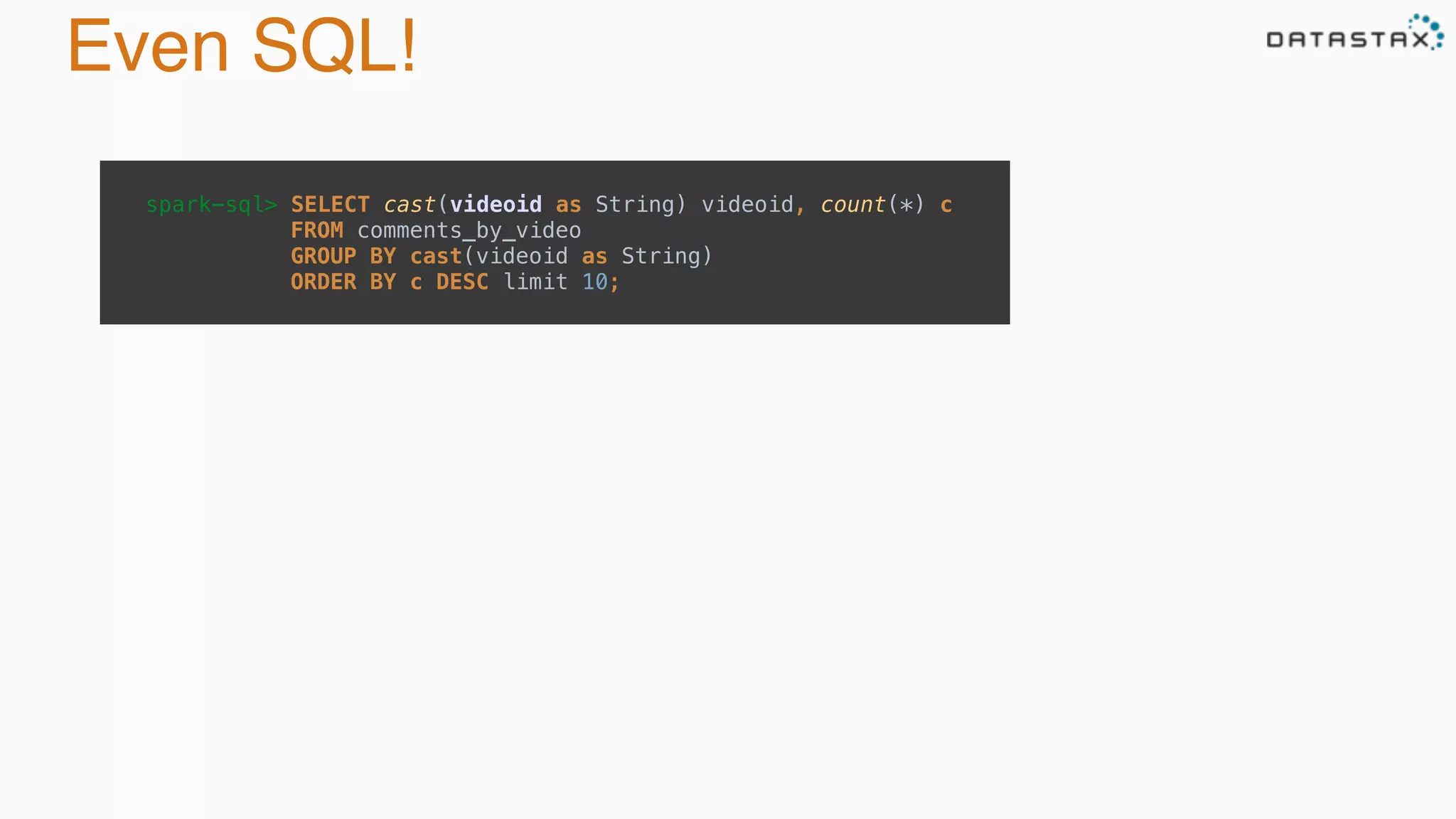

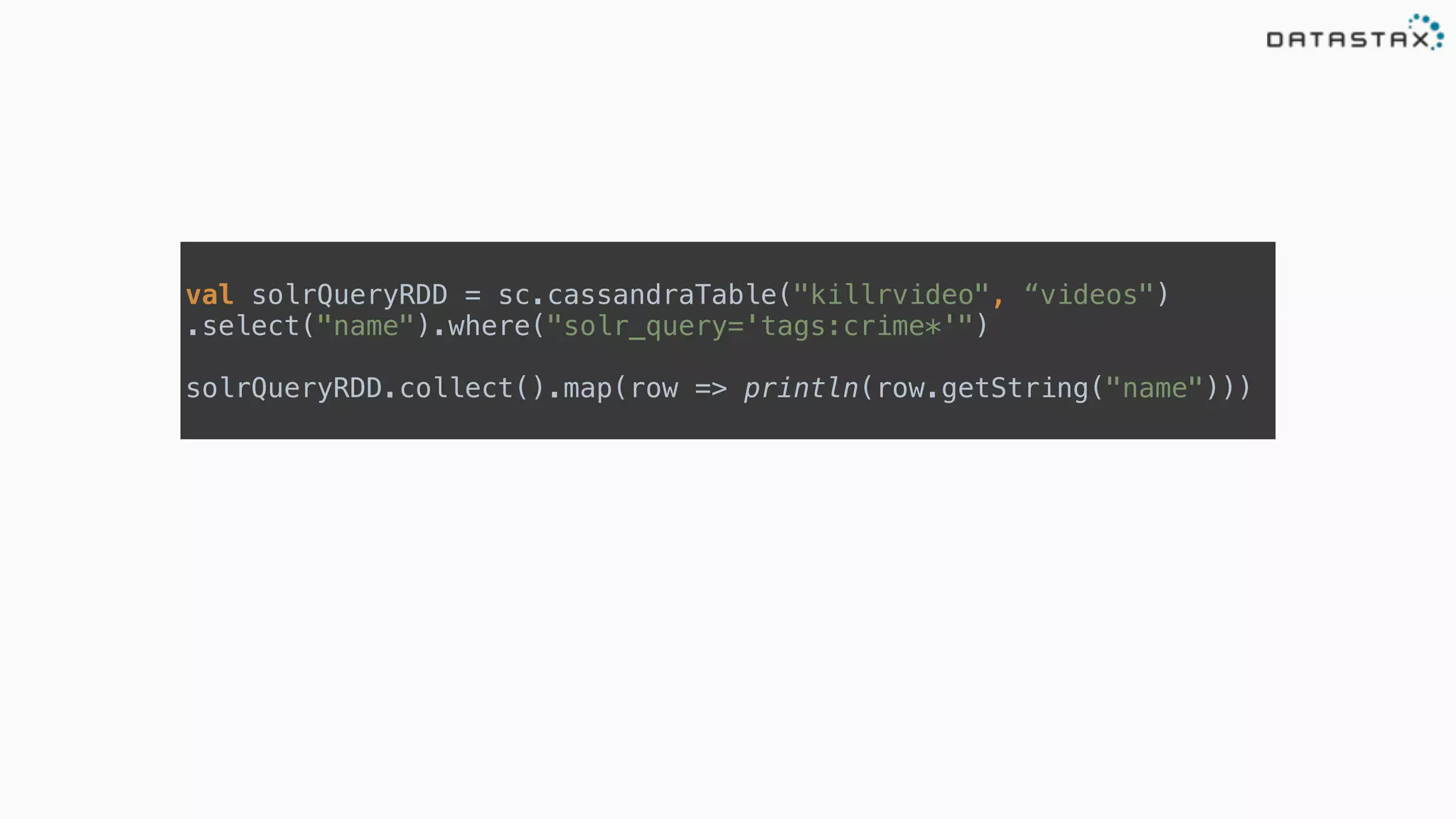



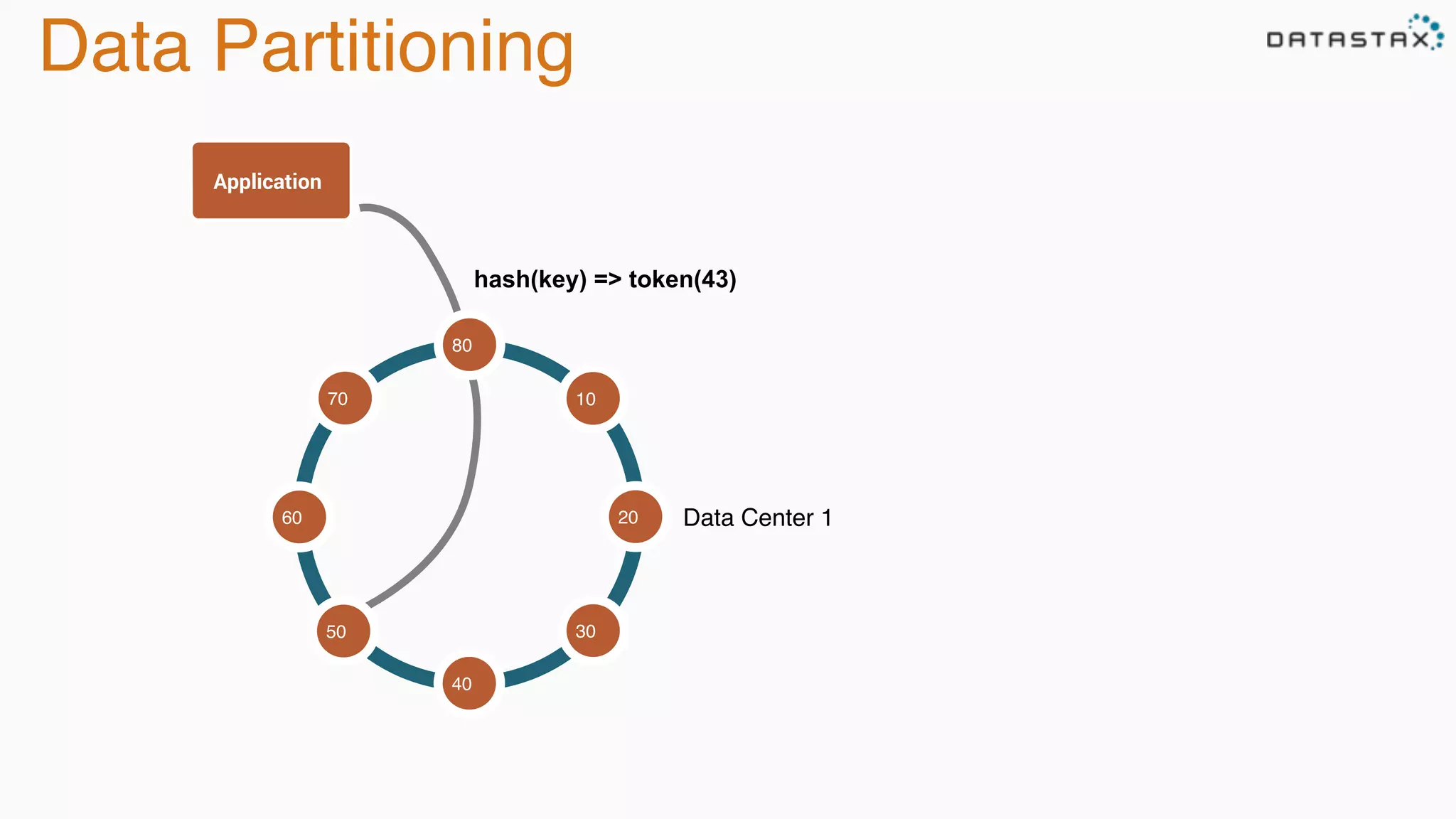
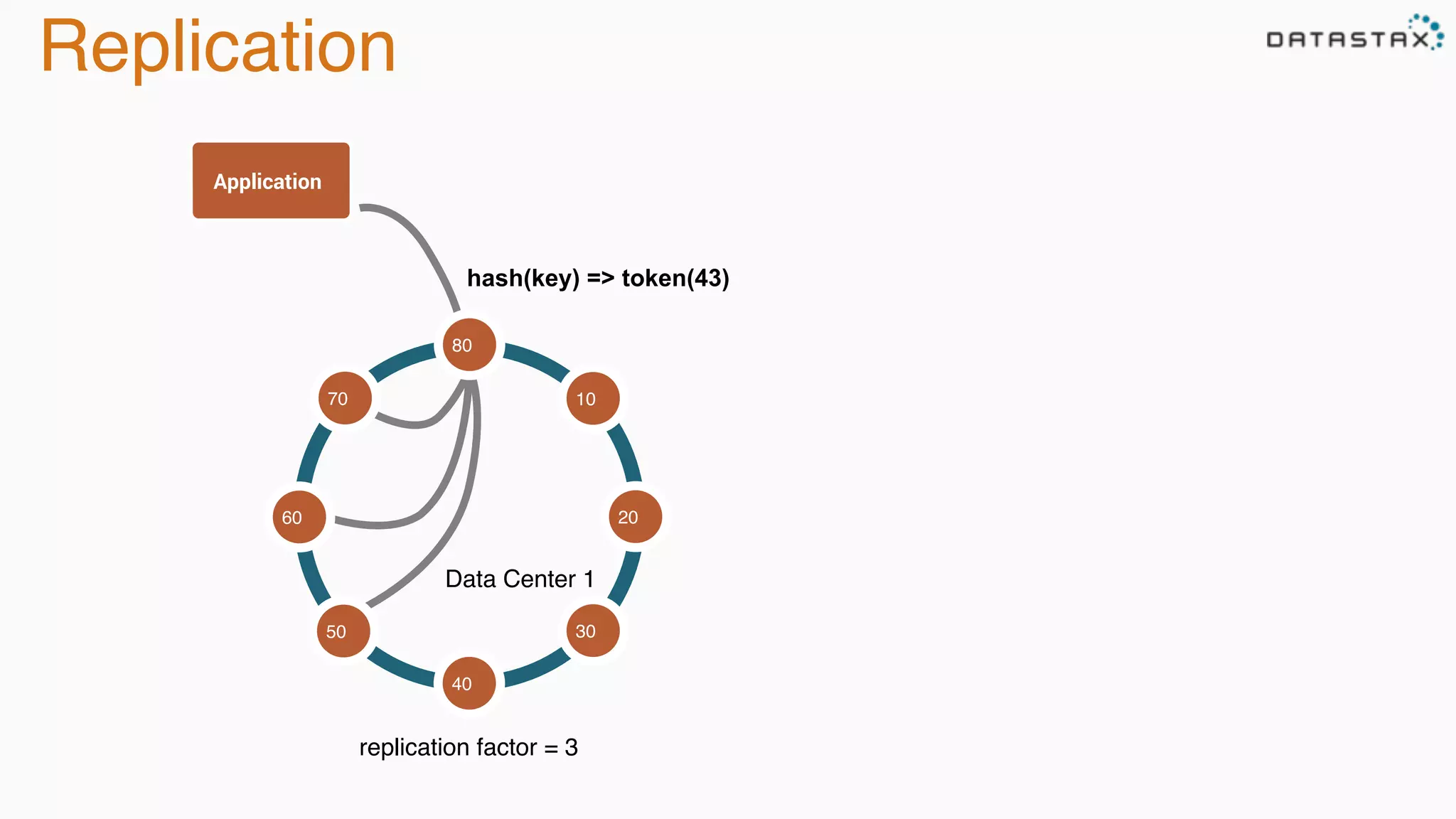
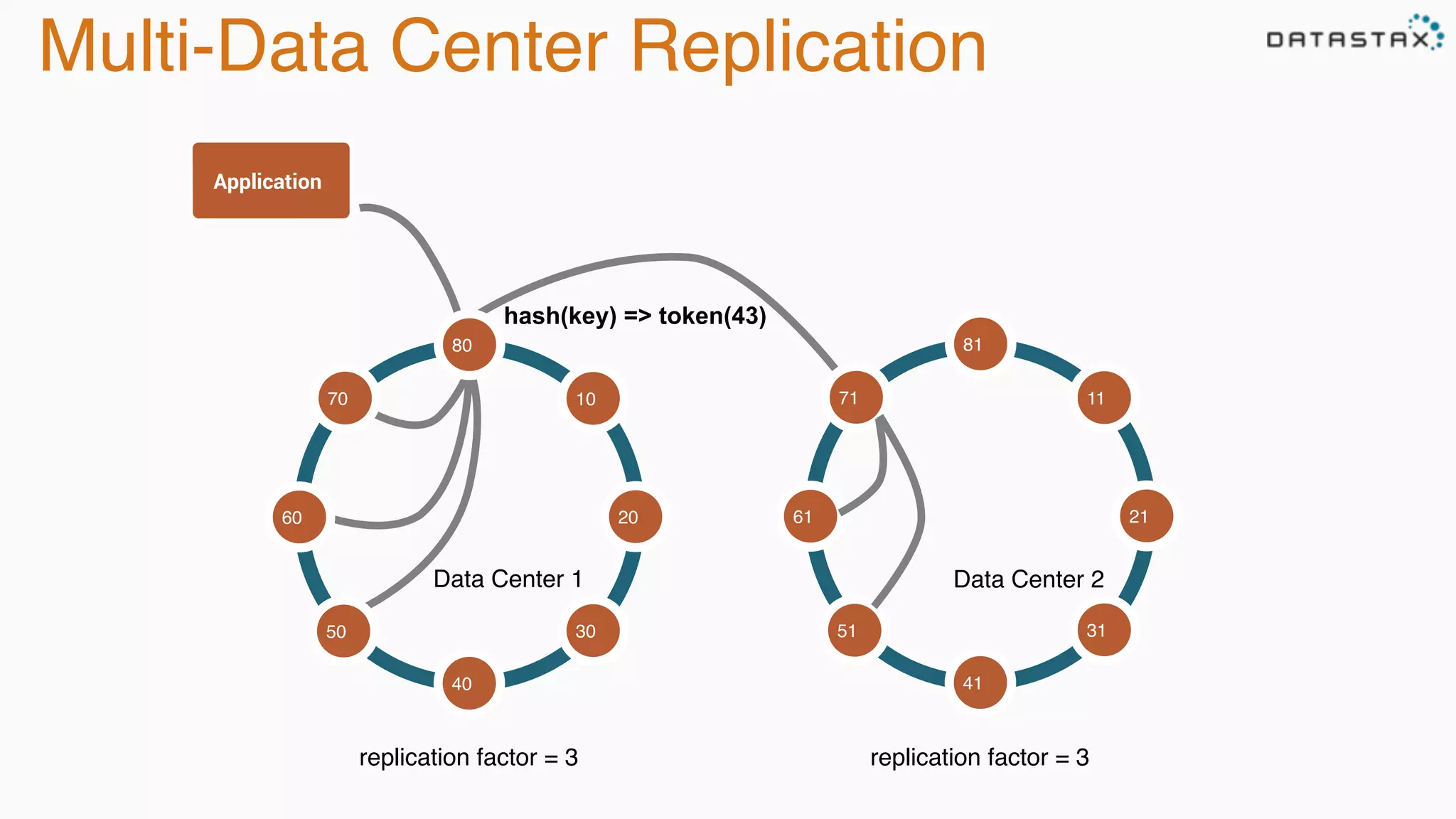
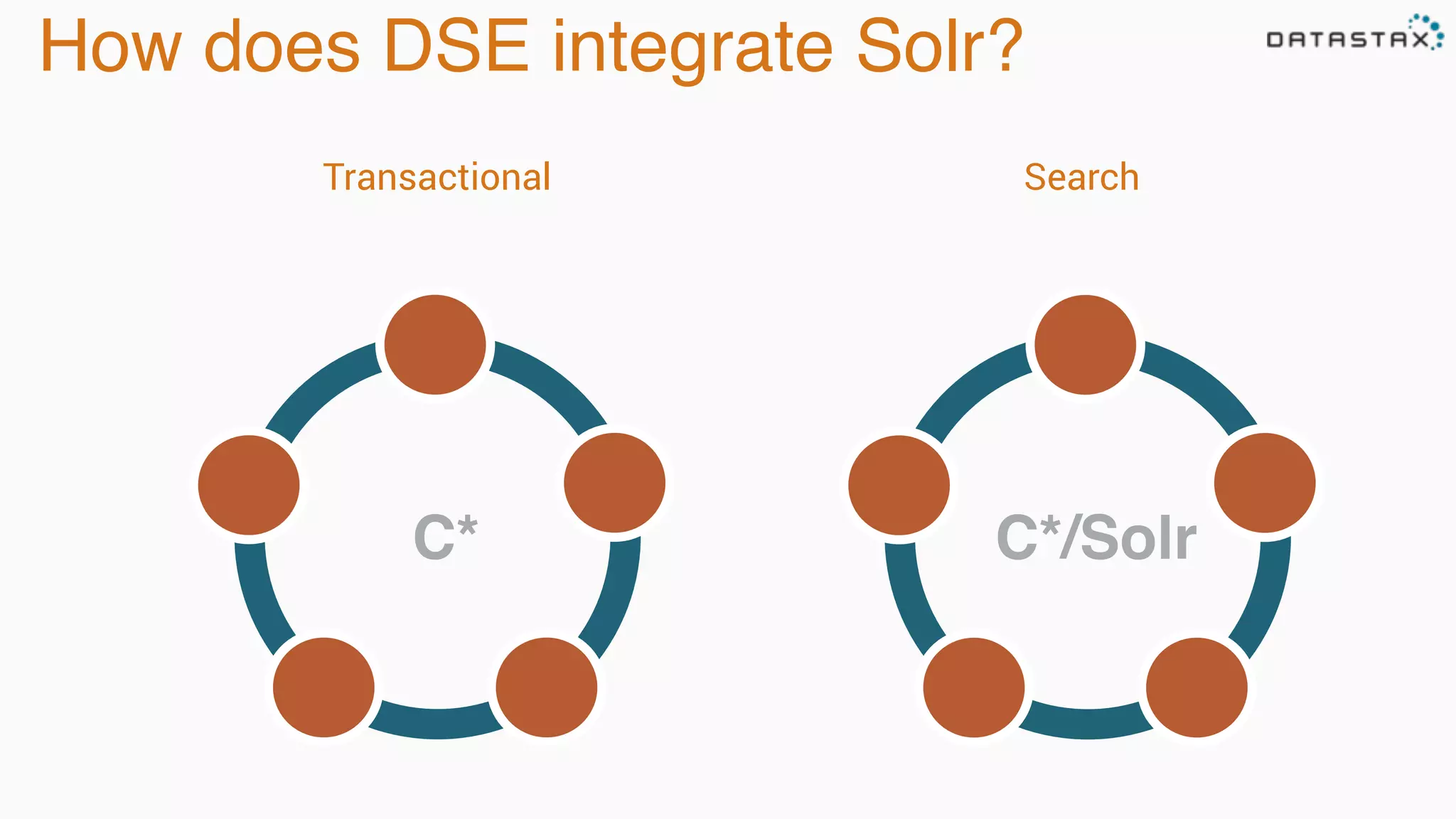
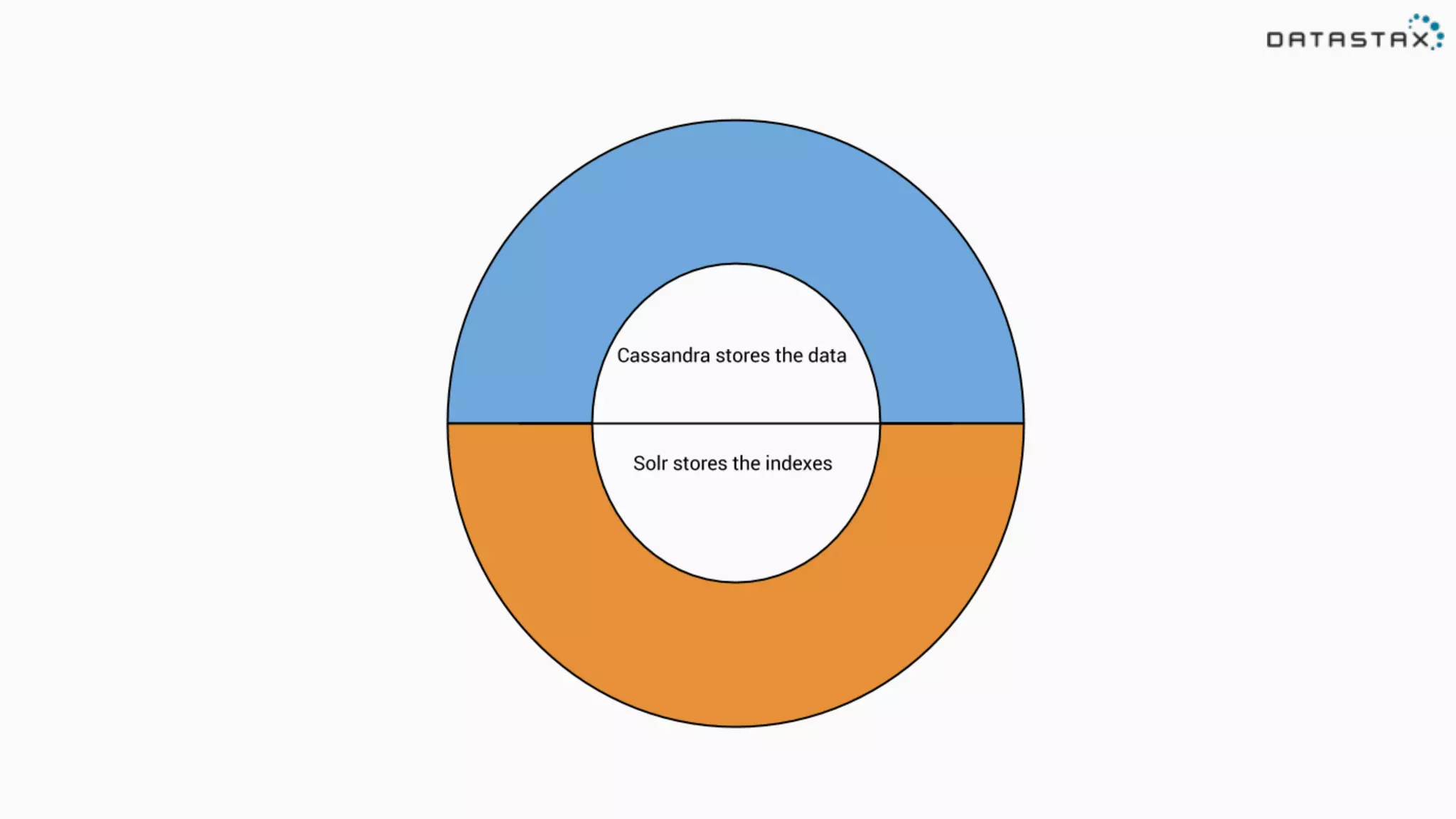
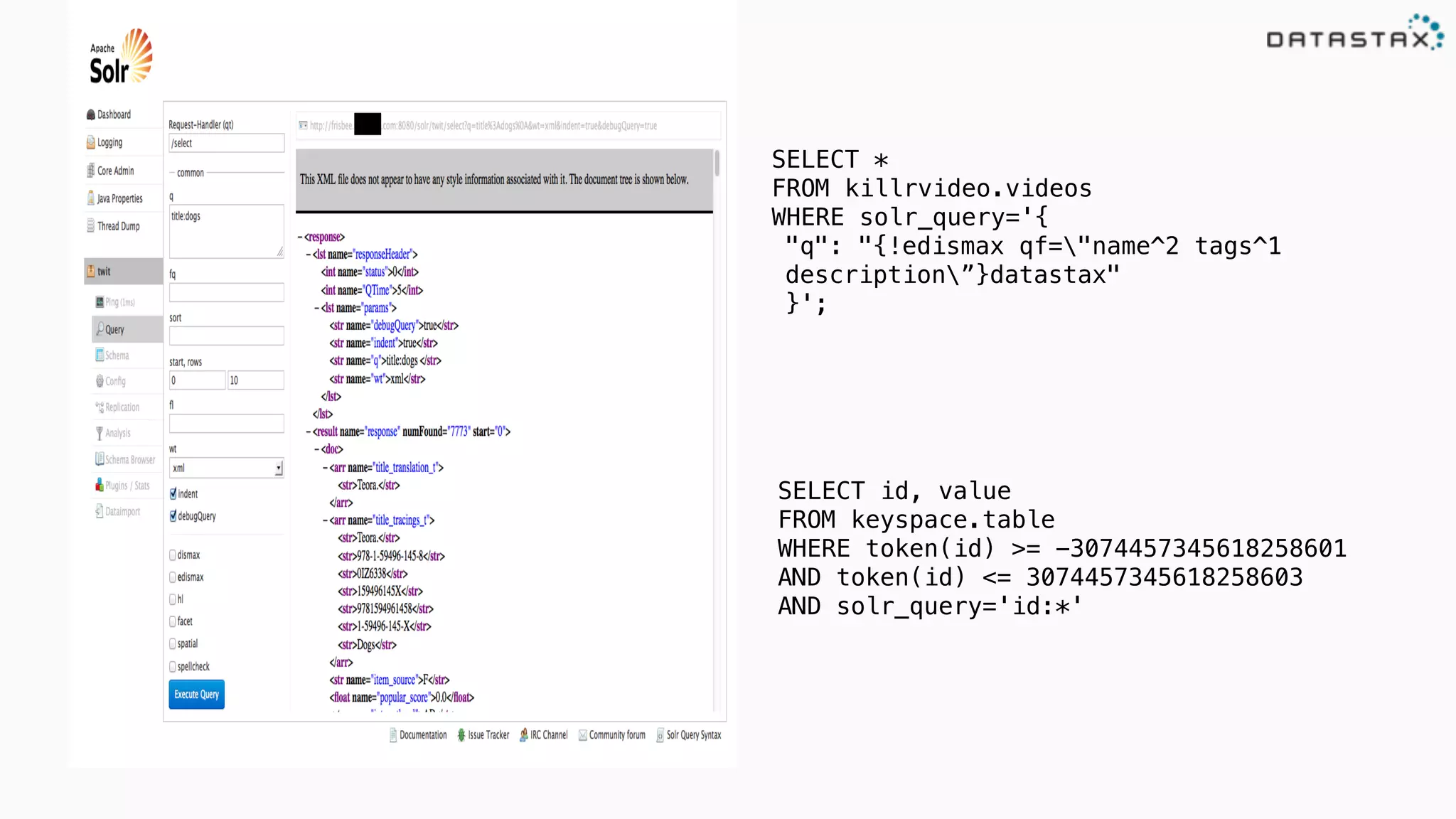
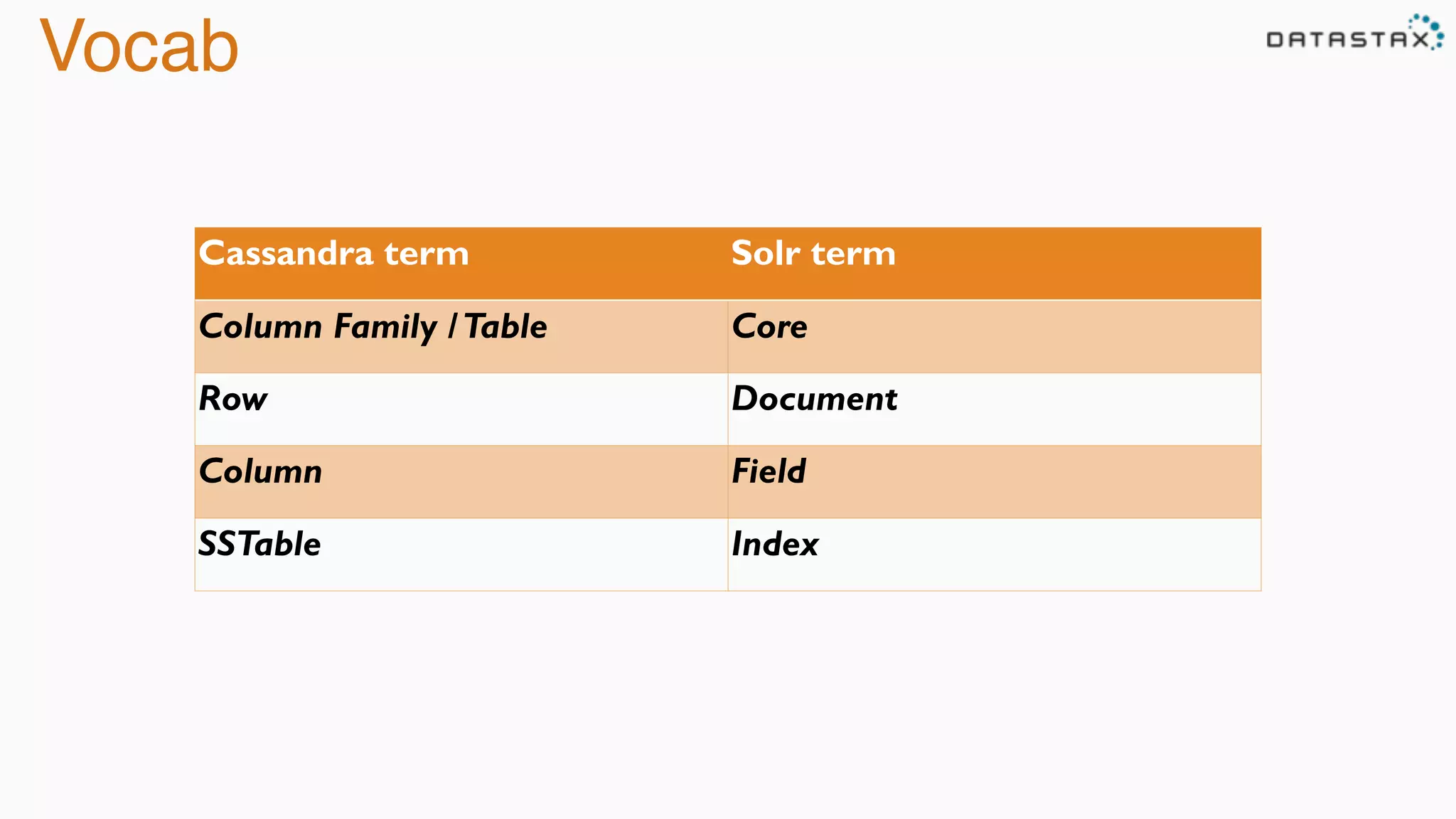
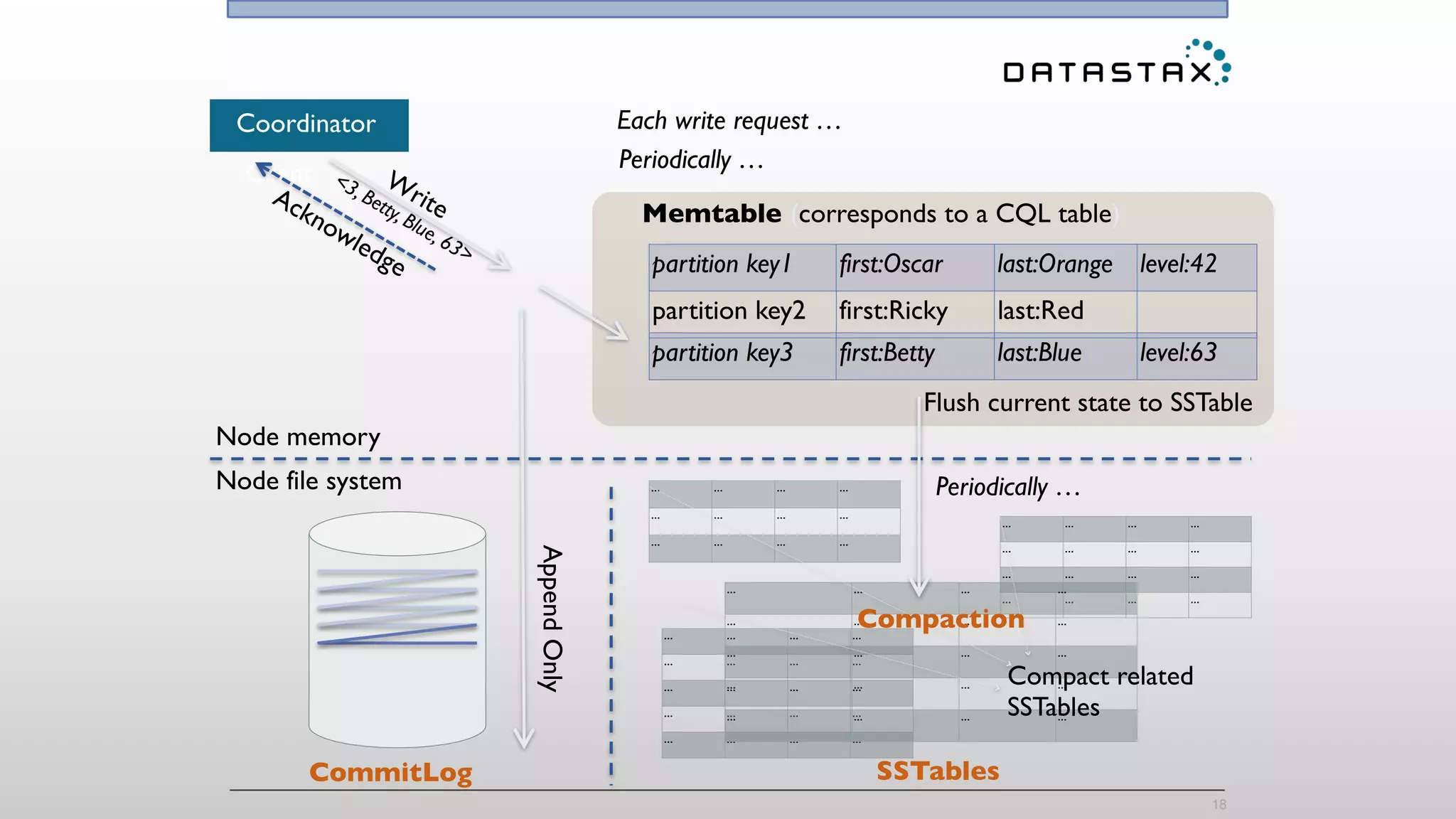
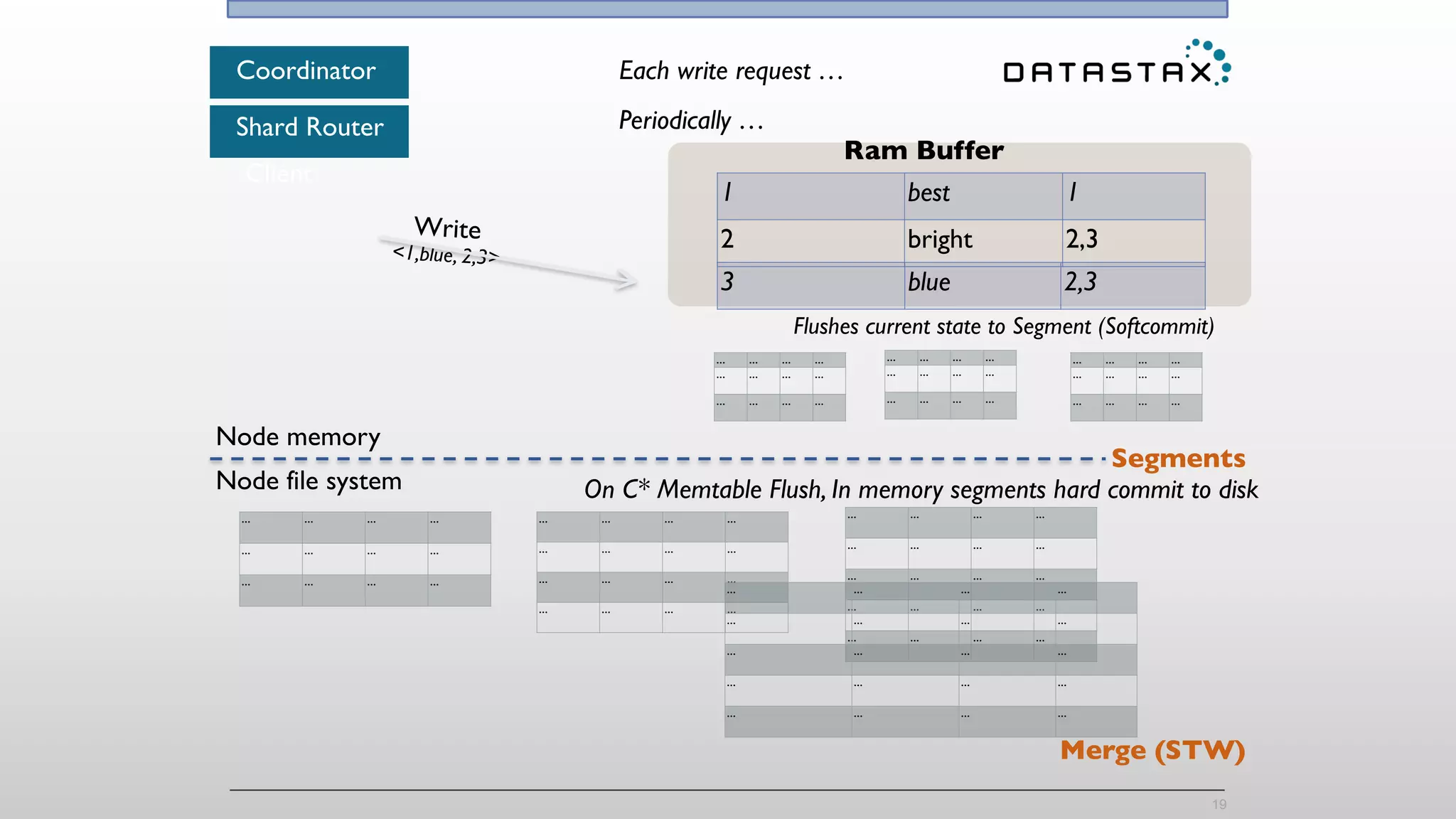
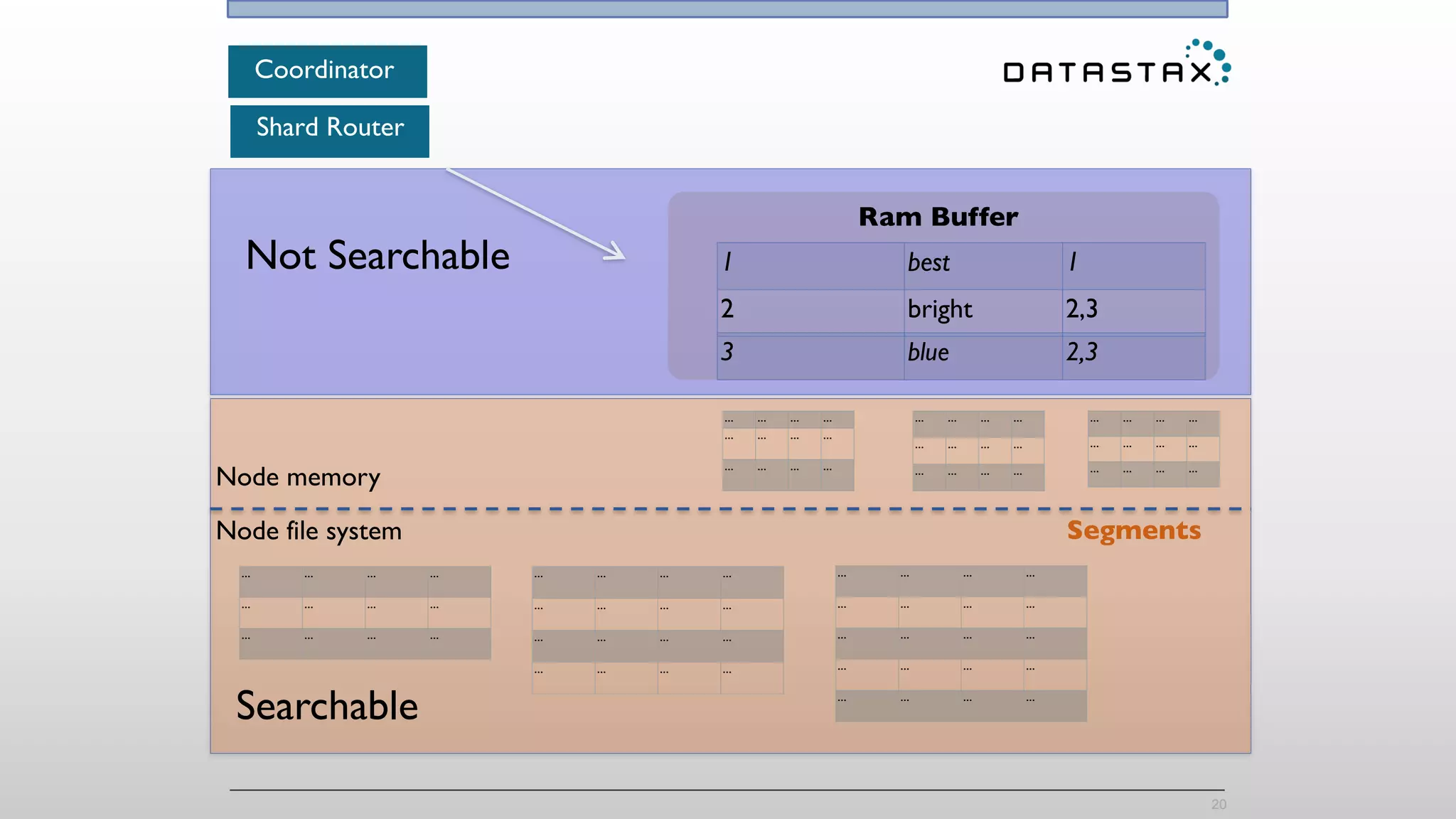
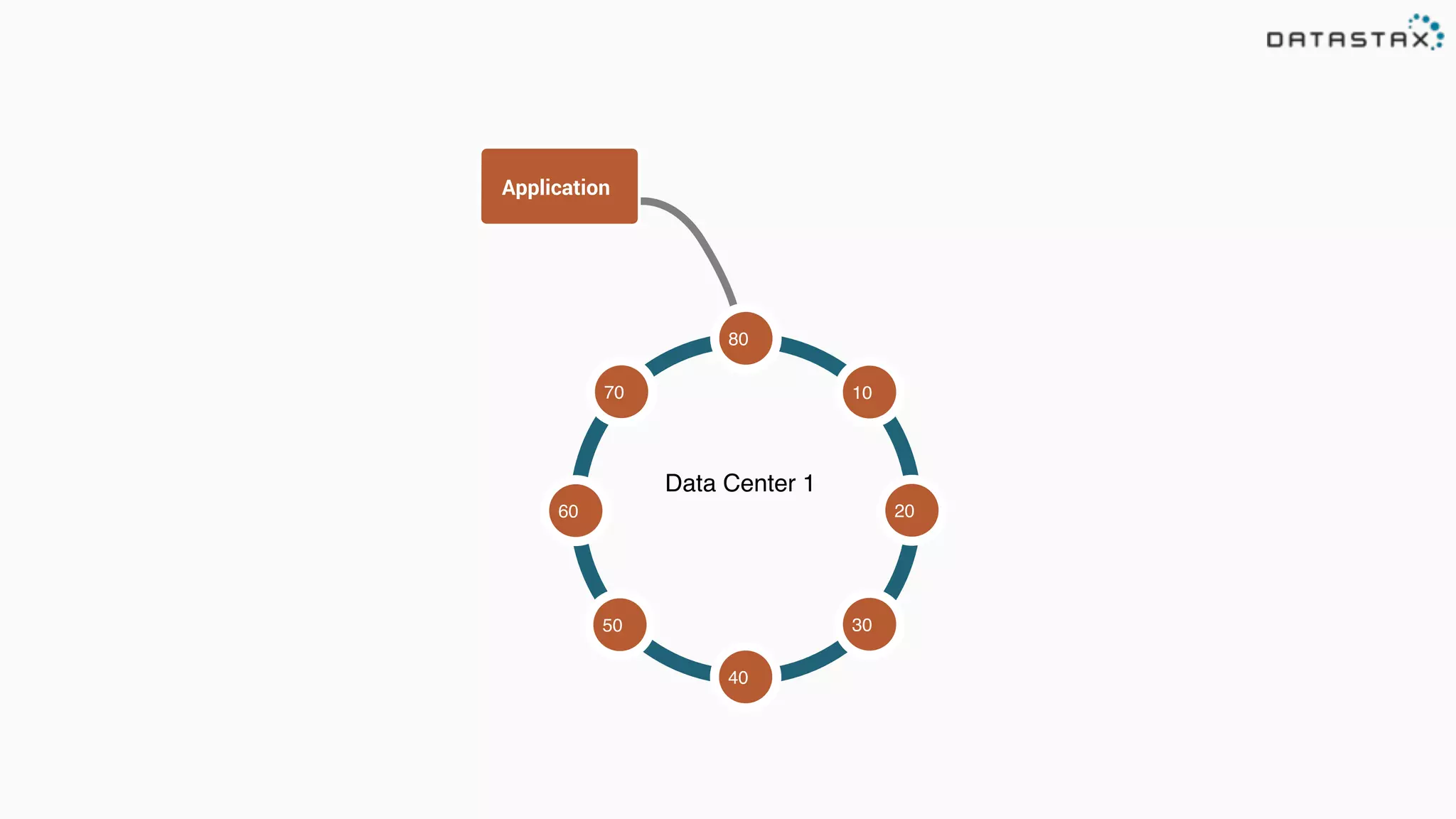
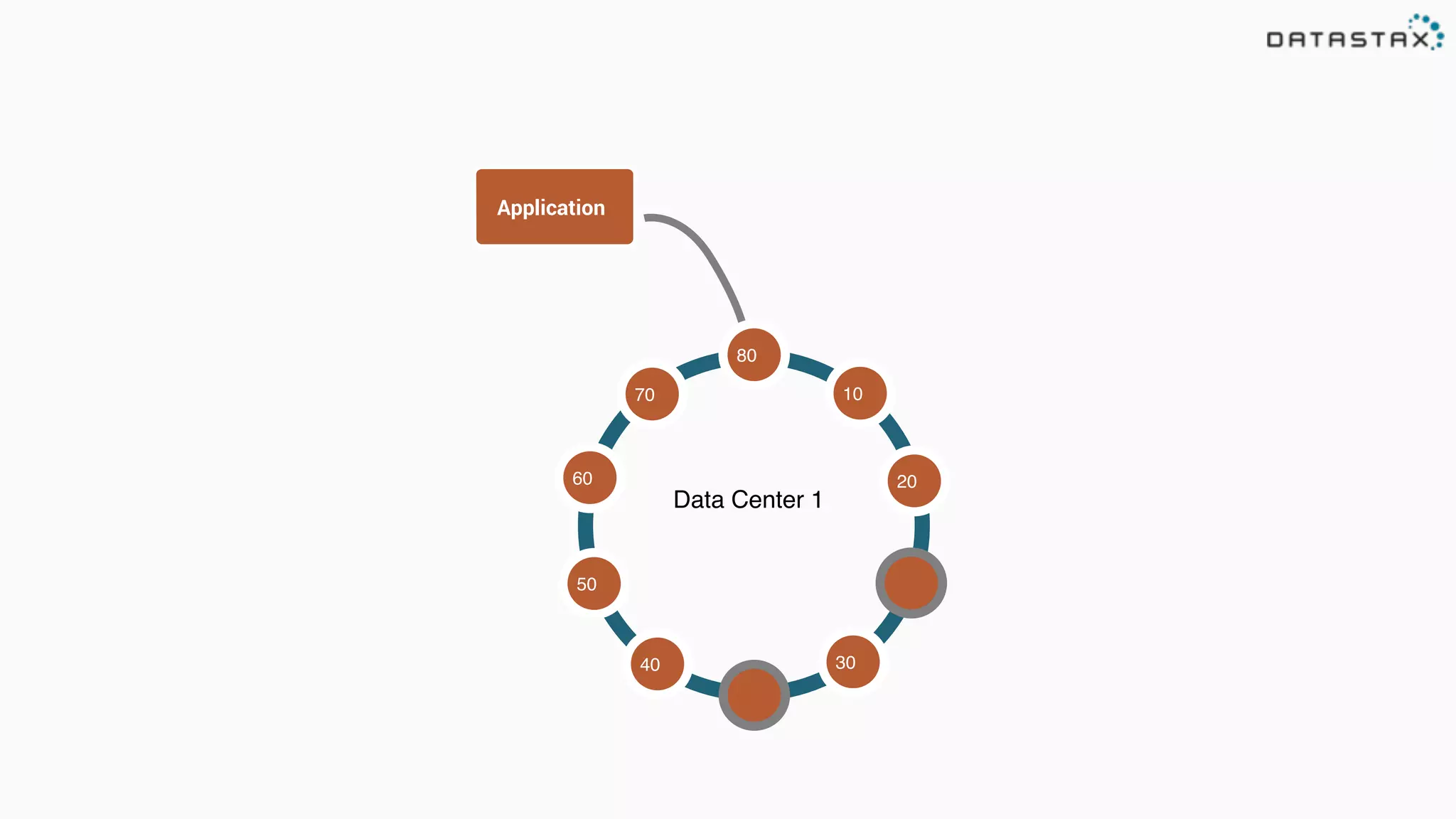
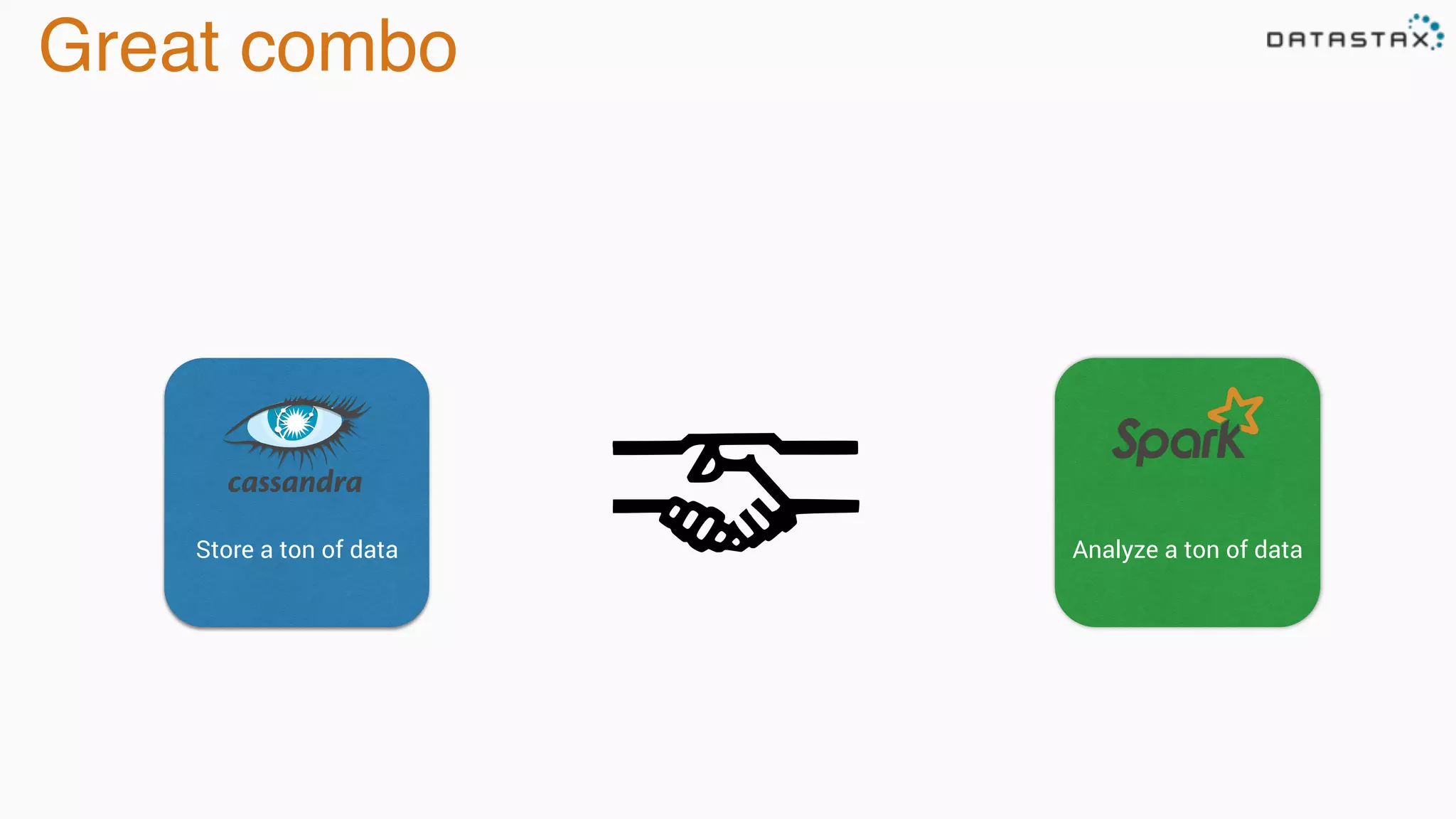
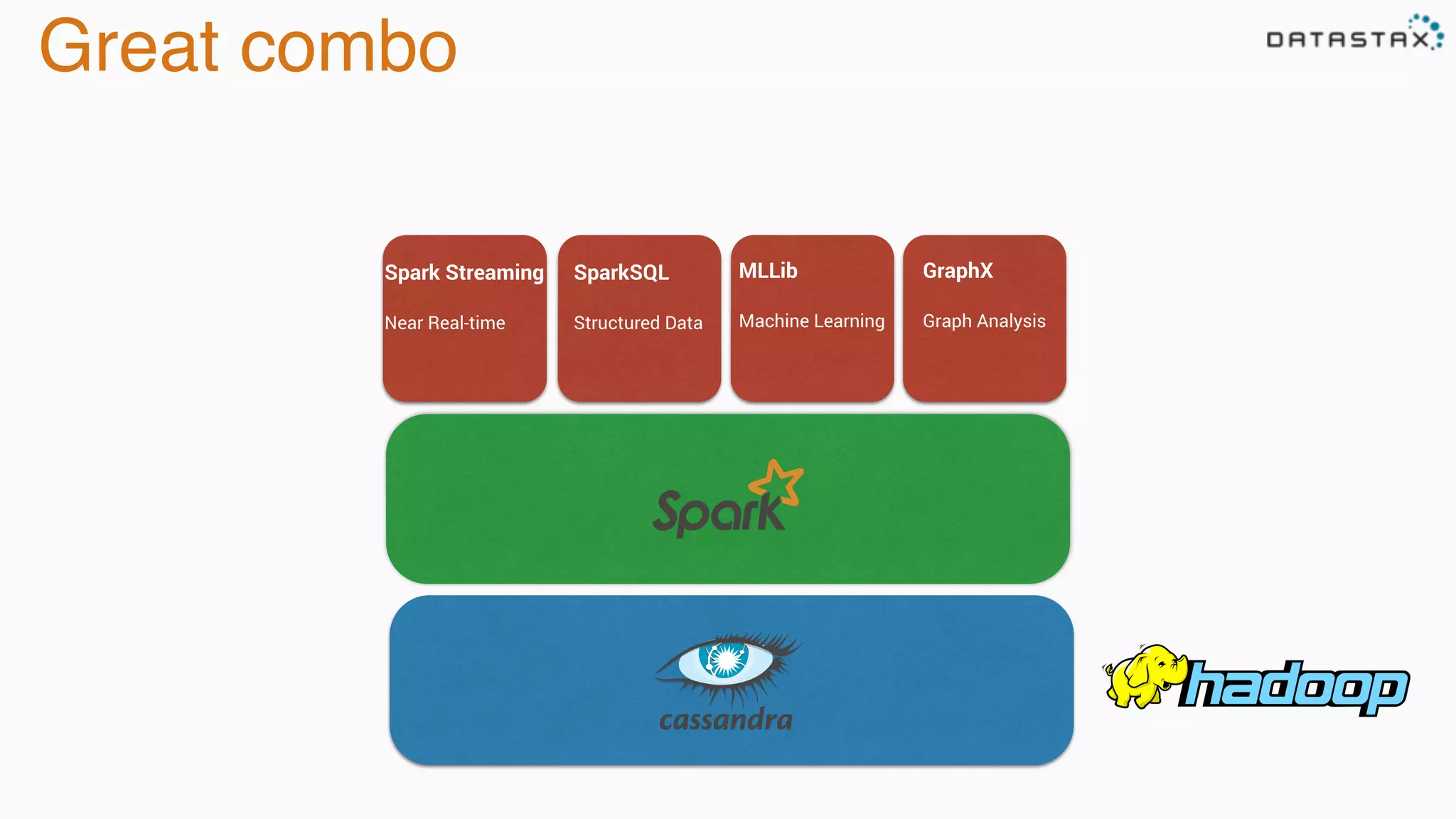
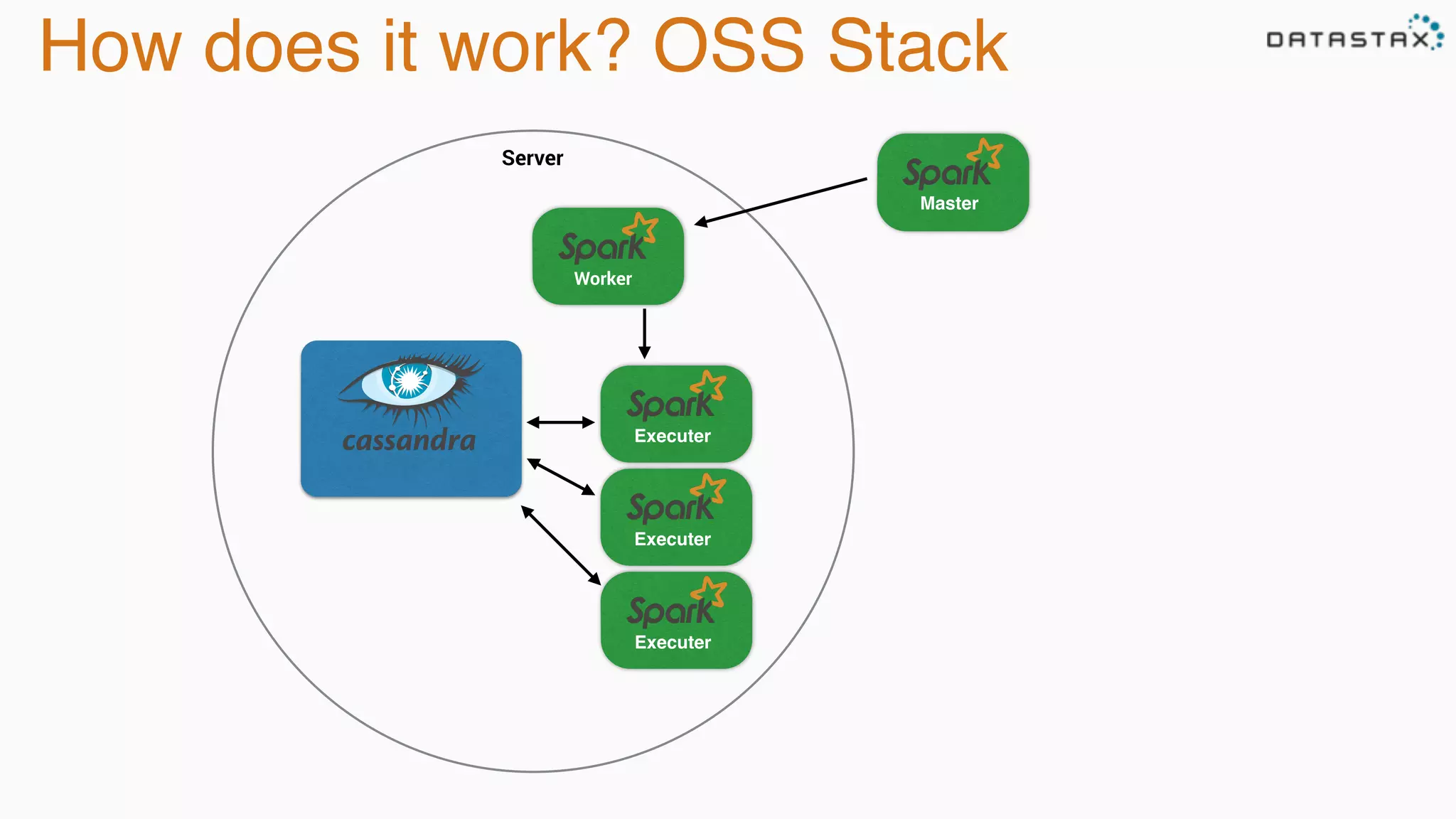
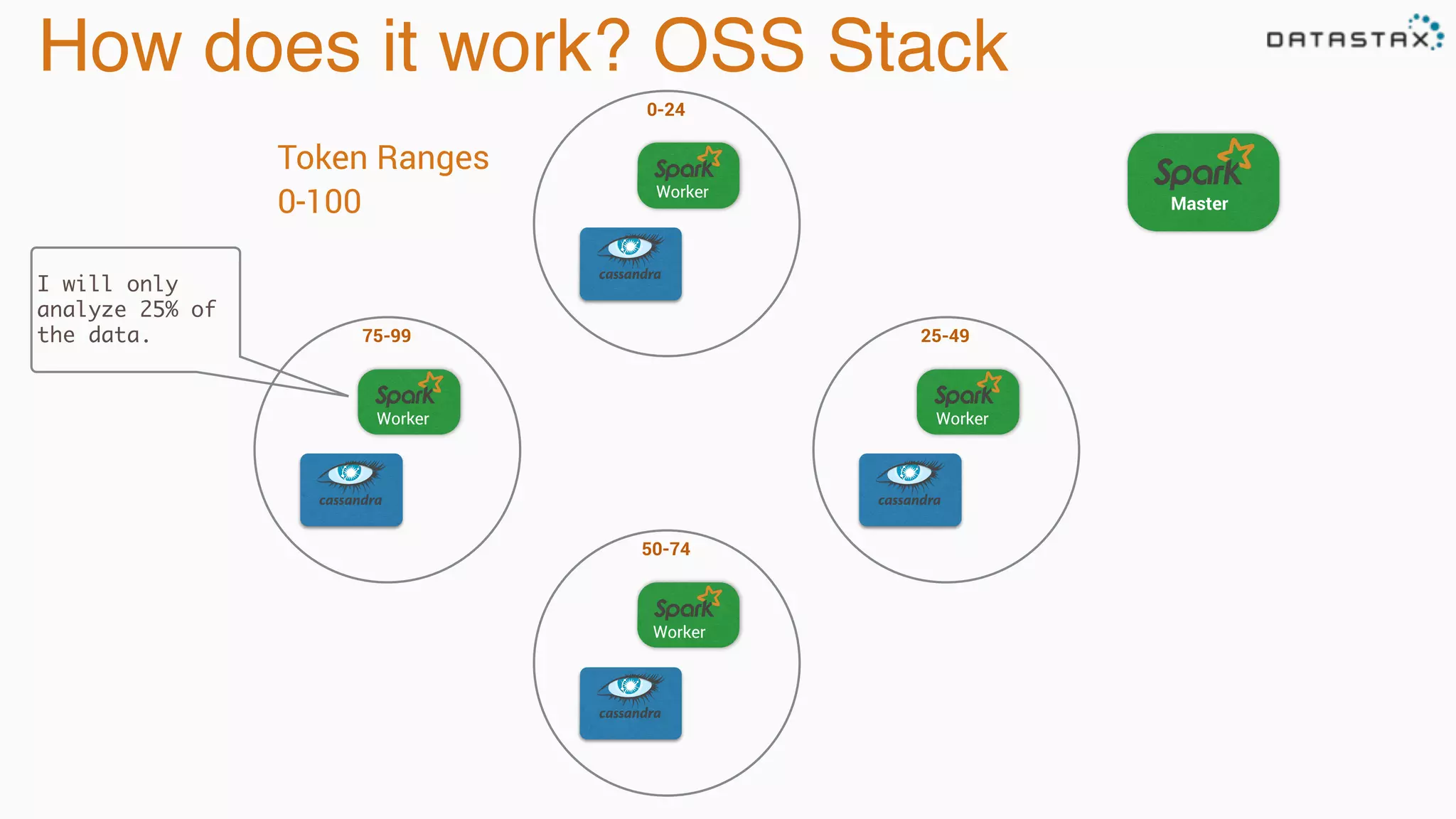
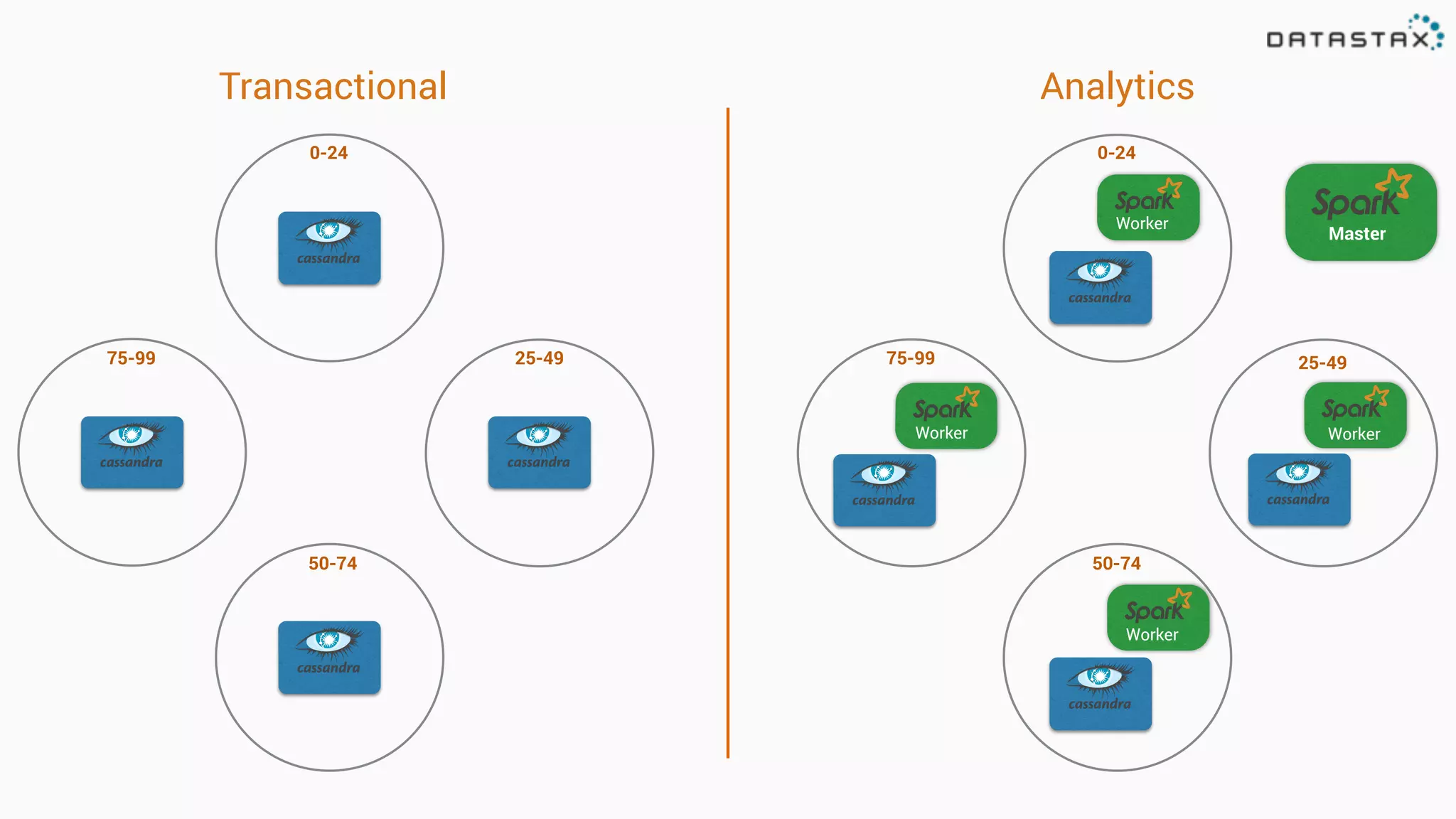
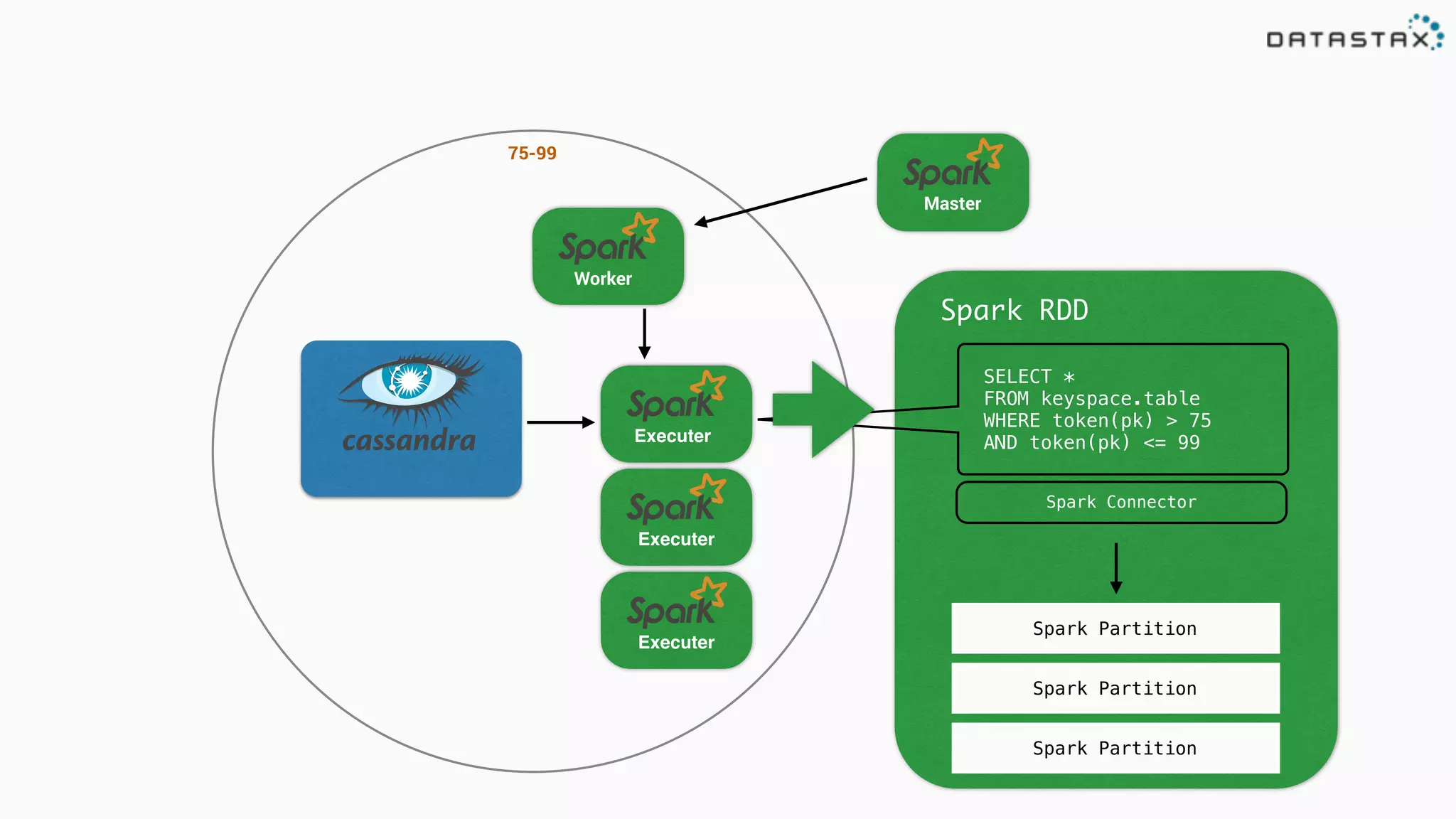
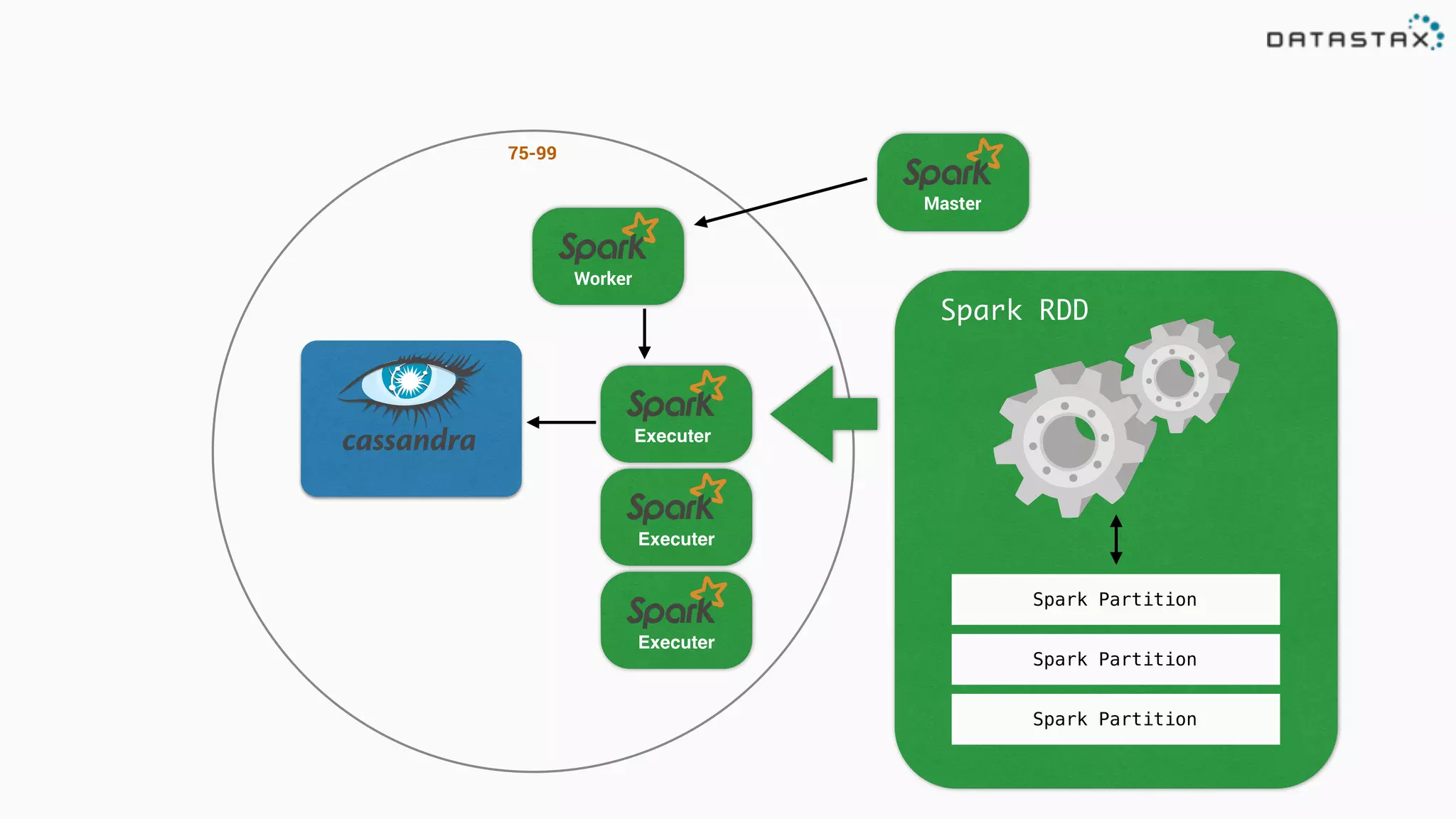
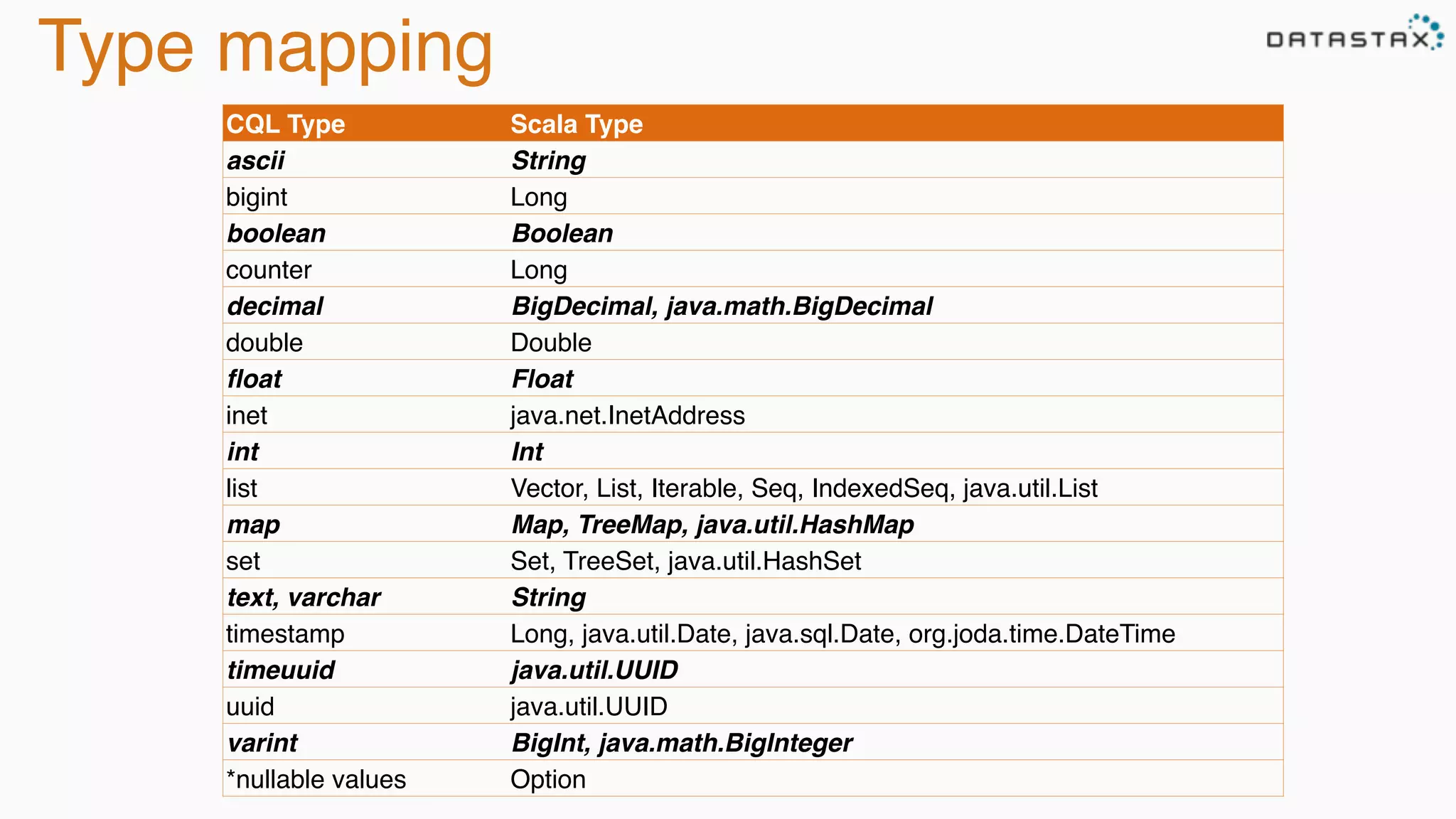
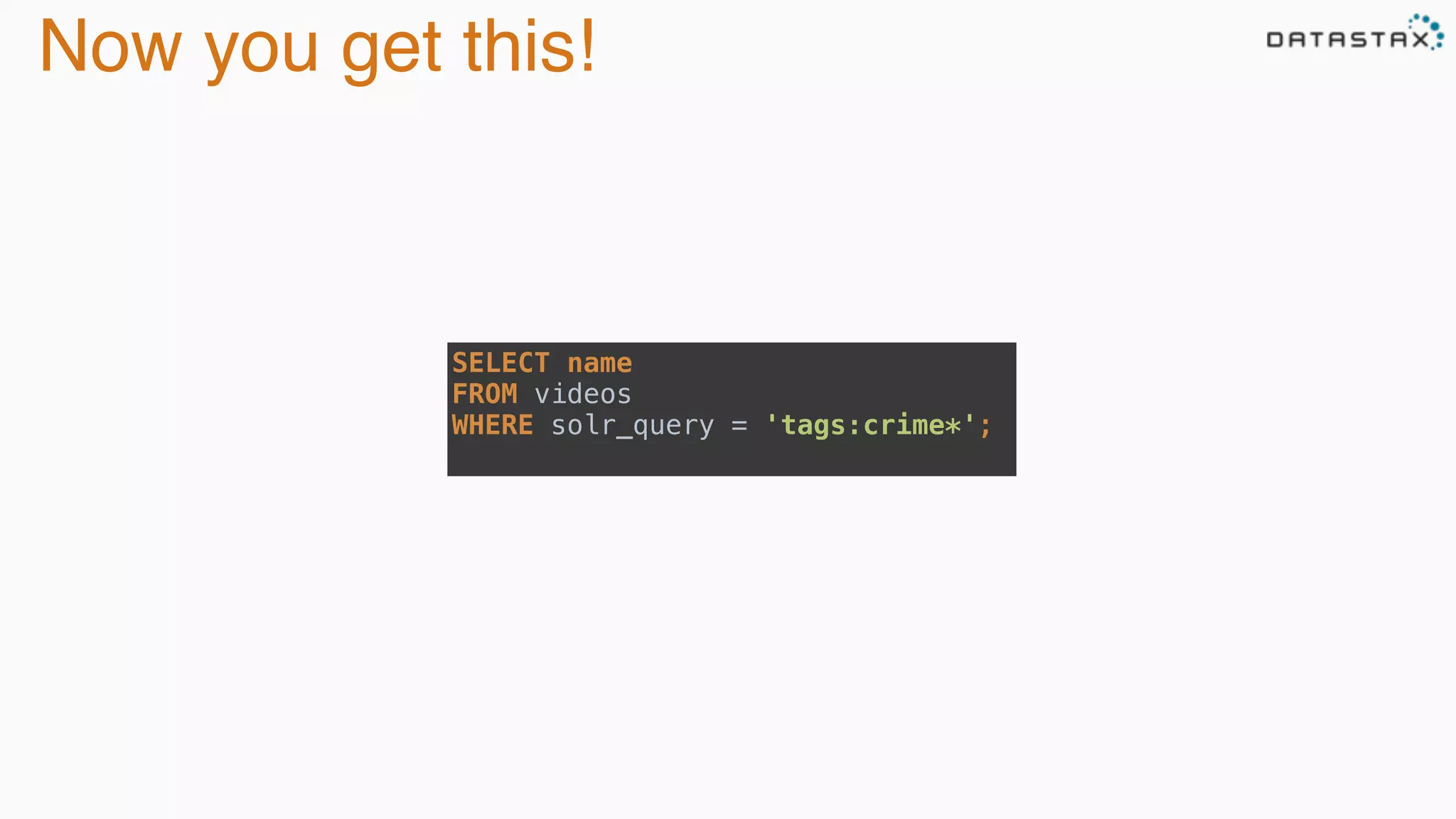
The document discusses the integration of Cassandra, Solr, and Spark using DataStax Enterprise for enhanced search capabilities and analytics. It covers topics such as schema creation, data partitioning, and real-time data processing with examples of queries and data management. Additionally, the document highlights the benefits of using this technology stack together for handling large datasets efficiently.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











