Download as PDF, PPTX

















![RDD Operations
•Transformations - Similar to scala collections API
•Produce new RDDs
•filter, flatmap, map, distinct, groupBy, union, zip,
reduceByKey, subtract
•Actions
•Require materialization of the records to generate a value
•collect: Array[T], count, fold, reduce..](https://image.slidesharecdn.com/apachecassandraapachesparkfortimeseriesdata-141119122809-conversion-gate01/85/Apache-cassandra-apache-spark-for-time-series-data-30-320.jpg)

![Collections and Files To RDD
scala> val distData = sc.parallelize(Seq(1,2,3,4,5)
distData: spark.RDD[Int] = spark.ParallelCollection@10d13e3e
val distFile: RDD[String] = sc.textFile(“directory/*.txt”)
val distFile = sc.textFile(“hdfs://namenode:9000/path/file”)
val distFile = sc.sequenceFile(“hdfs://namenode:9000/path/file”)](https://image.slidesharecdn.com/apachecassandraapachesparkfortimeseriesdata-141119122809-conversion-gate01/85/Apache-cassandra-apache-spark-for-time-series-data-32-320.jpg)



![Spark Cassandra Example
val conf = new SparkConf(loadDefaults = true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster("spark://127.0.0.1:7077")
val sc = new SparkContext(conf)
val table: CassandraRDD[CassandraRow] = sc.cassandraTable("keyspace", "tweets")
val ssc = new StreamingContext(sc, Seconds(30))
val stream = KafkaUtils.createStream[String, String, StringDecoder,
StringDecoder](
ssc, kafka.kafkaParams, Map(topic -> 1), StorageLevel.MEMORY_ONLY)
stream.map(_._2).countByValue().saveToCassandra("demo", "wordcount")
ssc.start()
ssc.awaitTermination()
Initialization
CassandraRDD
Stream Initialization
Transformations
and Action](https://image.slidesharecdn.com/apachecassandraapachesparkfortimeseriesdata-141119122809-conversion-gate01/85/Apache-cassandra-apache-spark-for-time-series-data-37-320.jpg)

![Setup connection
def main(args: Array[String]): Unit = {
// the setMaster("local") lets us run & test the job right in our IDE
val conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setMaster("local")
// "local" here is the master, meaning we don't explicitly have a spark master set up
val sc = new SparkContext("local", "weather", conf)
val connector = CassandraConnector(conf)
val cc = new CassandraSQLContext(sc)
cc.setKeyspace("isd_weather_data")](https://image.slidesharecdn.com/apachecassandraapachesparkfortimeseriesdata-141119122809-conversion-gate01/85/Apache-cassandra-apache-spark-for-time-series-data-40-320.jpg)
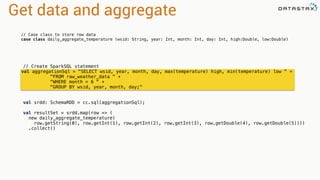

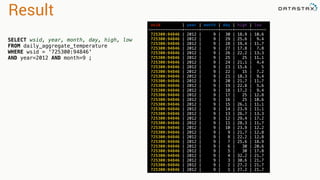
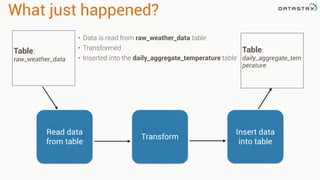
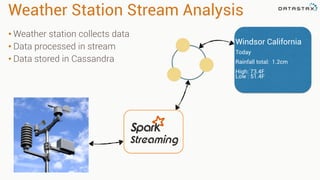

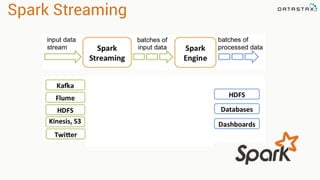
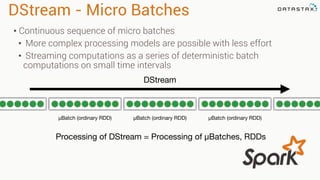

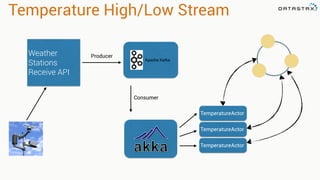




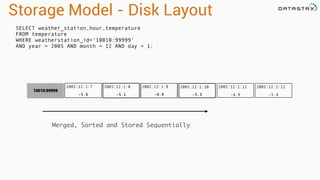
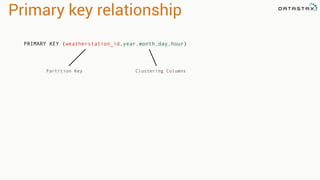
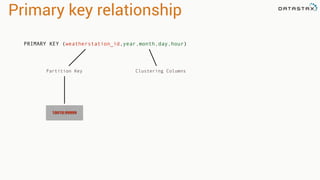
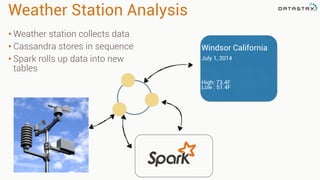
Apache Cassandra is a distributed database that stores time series data in a partitioned and ordered format. Apache Spark can efficiently query this Cassandra data using Resilient Distributed Datasets (RDDs) and perform analytics like aggregations. For example, weather station data stored sequentially in Cassandra by time can be aggregated into daily high and low temperatures with Spark and written back to a roll-up Cassandra table.







































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














