Download as PDF, PPTX














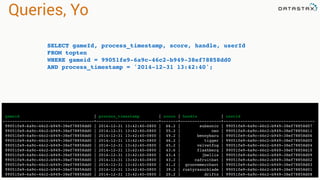

![user Table
• Our standard POJO
• emails are dynamic
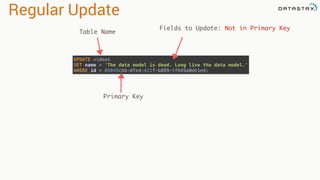
CREATE TABLE user (
username text,
firstname text,
lastname text,
emails list<text>,
PRIMARY KEY (username)
);
INSERT INTO user (username, firstname, lastname, emails)
VALUES (‘pmcfadin’, ‘Patrick’, ‘McFadin’, [‘patrick@datastax.com’,
‘patrick.mcfadin@datastax.com’]
IF NOT EXISTS;](https://image.slidesharecdn.com/advanced-data-modeling-with-apache-cassandra-160219180817/85/Advanced-Data-Modeling-with-Apache-Cassandra-26-320.jpg)







![The race is on
Process 1 Process 2
SELECT firstName, lastName
FROM users
WHERE username = 'pmcfadin';
SELECT firstName, lastName
FROM users
WHERE username = 'pmcfadin';
(0 rows)
(0 rows)
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Patrick','McFadin',
['patrick@datastax.com'],
'ba27e03fd95e507daf2937c937d499ab',
'2011-06-20 13:50:00');
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Paul','McFadin',
['paul@oracle.com'],
'ea24e13ad95a209ded8912e937d499de',
'2011-06-20 13:51:00');
T0
T1
T2
T3
Got nothing! Good to go!
This one wins](https://image.slidesharecdn.com/advanced-data-modeling-with-apache-cassandra-160219180817/85/Advanced-Data-Modeling-with-Apache-Cassandra-35-320.jpg)


![Solution LWT
Process 1
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Patrick','McFadin',
['patrick@datastax.com'],
'ba27e03fd95e507daf2937c937d499ab',
'2011-06-20 13:50:00')
IF NOT EXISTS;
T0
T1
[applied]
-----------
True
•Check performed for record
•Paxos ensures exclusive access
•applied = true: Success](https://image.slidesharecdn.com/advanced-data-modeling-with-apache-cassandra-160219180817/85/Advanced-Data-Modeling-with-Apache-Cassandra-38-320.jpg)
![Solution LWT
Process 2
T2
T3
[applied] | username | created_date | firstname | lastname
-----------+----------+--------------------------+-----------+----------
False | pmcfadin | 2011-06-20 13:50:00-0700 | Patrick | McFadin
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Paul','McFadin',
['paul@oracle.com'],
'ea24e13ad95a209ded8912e937d499de',
'2011-06-20 13:51:00')
IF NOT EXISTS;
•applied = false: Rejected
•No record stomping!](https://image.slidesharecdn.com/advanced-data-modeling-with-apache-cassandra-160219180817/85/Advanced-Data-Modeling-with-Apache-Cassandra-39-320.jpg)










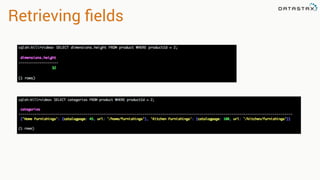




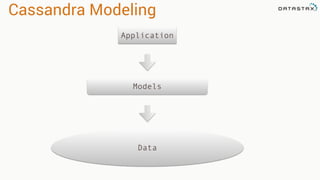
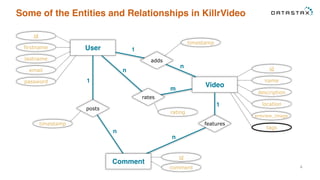
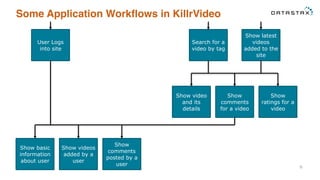
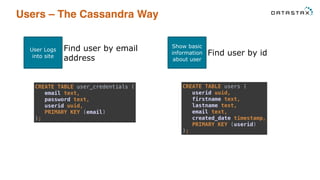
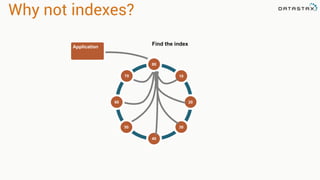
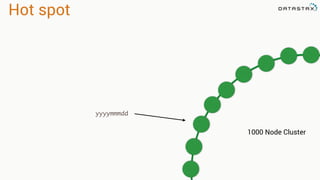
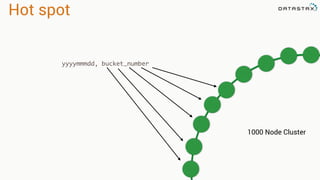
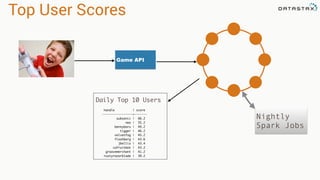
This document provides an overview and examples of modeling data in Apache Cassandra. It begins with an introduction to thinking about data models and queries before modeling, and emphasizes that Cassandra requires modeling around queries due to its limitations on joins and indexes. The document then provides examples of modeling user, video, and other entity data for a video sharing application to support common queries. It also discusses techniques for handling queries that could become hotspots, such as bucketing or adding random values. The examples illustrate best practices for data duplication, materialized views, and time series data storage in Cassandra.























































































