Download as PDF, PPTX





























![Spark Cassandra Connector
https://github.com/datastax/spark-‐cassandra-‐connector
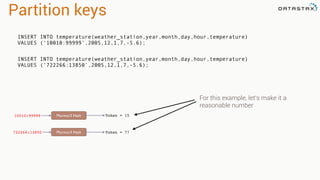
Keyspace Table
Cassandra Spark
RDD[CassandraRow]
RDD[Tuples]
Bundled
and
Supported
with
DSE
4.5!](https://image.slidesharecdn.com/niketechtalk-doubledownonapachecassandraandspark-150123091147-conversion-gate02/85/Nike-Tech-Talk-Double-Down-on-Apache-Cassandra-and-Spark-45-320.jpg)

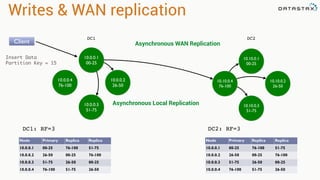
![Accessing Data
CREATE TABLE test.words (word text PRIMARY KEY, count int);
INSERT INTO test.words (word, count) VALUES ('bar', 30);
INSERT INTO test.words (word, count) VALUES ('foo', 20);
// Use table as RDD
val rdd = sc.cassandraTable("test", "words")
// rdd: CassandraRDD[CassandraRow] = CassandraRDD[0]
rdd.toArray.foreach(println)
// CassandraRow[word: bar, count: 30]
// CassandraRow[word: foo, count: 20]
rdd.columnNames // Stream(word, count)
rdd.size // 2
val firstRow = rdd.first // firstRow: CassandraRow = CassandraRow[word: bar,
count: 30]
firstRow.getInt("count") // Int = 30
*Accessing table above as RDD:](https://image.slidesharecdn.com/niketechtalk-doubledownonapachecassandraandspark-150123091147-conversion-gate02/85/Nike-Tech-Talk-Double-Down-on-Apache-Cassandra-and-Spark-50-320.jpg)
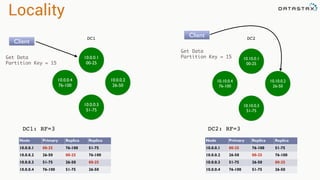
![Saving Data
val newRdd = sc.parallelize(Seq(("cat", 40), ("fox", 50)))
// newRdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2]
newRdd.saveToCassandra("test", "words", Seq("word", "count"))
SELECT * FROM test.words;
word | count
------+-------
bar | 30
foo | 20
cat | 40
fox | 50
(4 rows)
*RDD above saved to Cassandra:](https://image.slidesharecdn.com/niketechtalk-doubledownonapachecassandraandspark-150123091147-conversion-gate02/85/Nike-Tech-Talk-Double-Down-on-Apache-Cassandra-and-Spark-51-320.jpg)
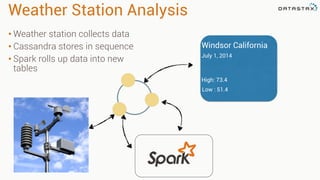

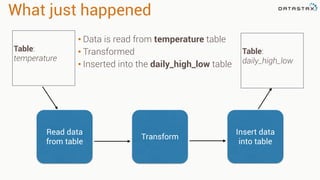

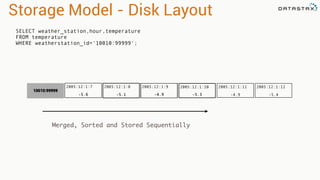
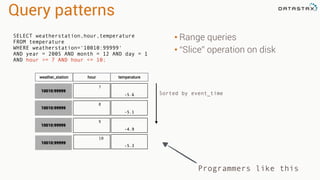
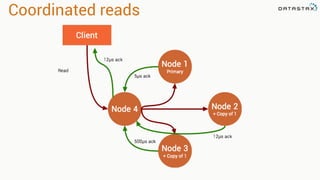
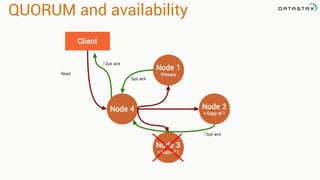
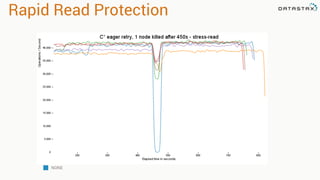
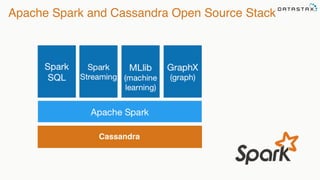
Patrick McFadin's presentation discusses the functionalities and use cases of Apache Cassandra and its integration with Apache Spark. He highlights Cassandra's features including reliability, performance, and scalability for handling large datasets, particularly through examples like a weather station data model. The presentation also outlines how to utilize the Spark-Cassandra connector for advanced data processing and analytics.


















































































