




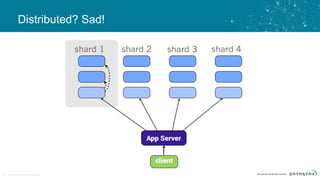

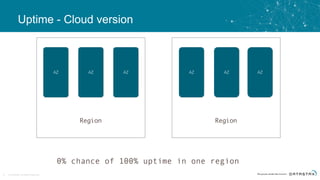


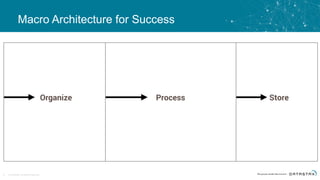

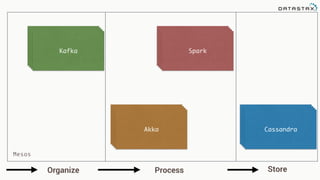
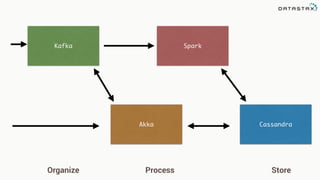


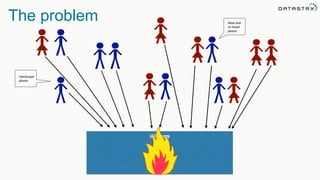
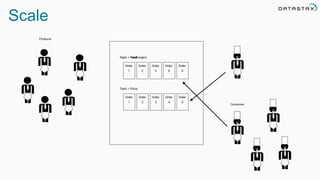

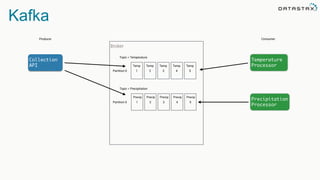
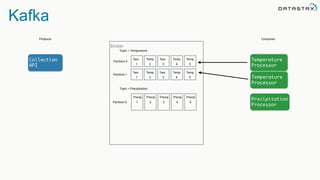

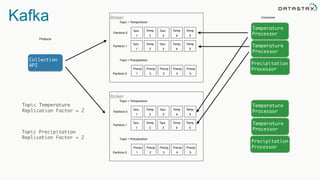


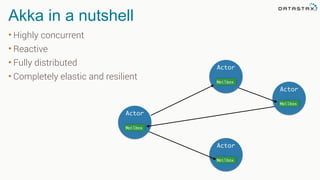
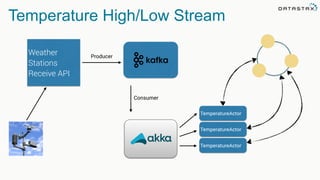

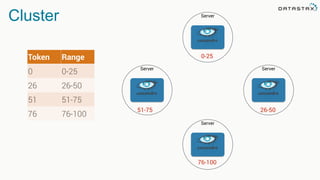
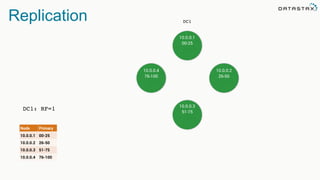
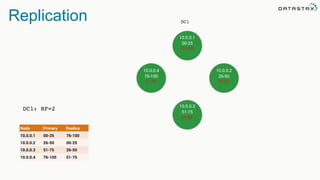

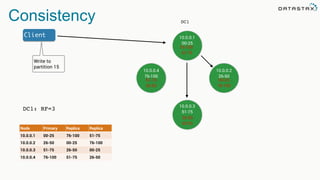

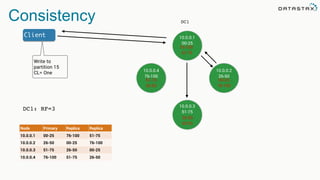
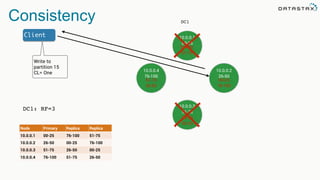
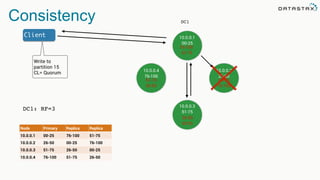
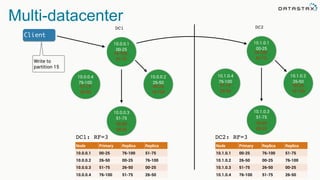
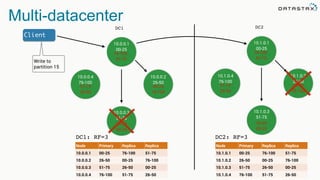
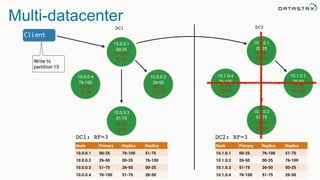

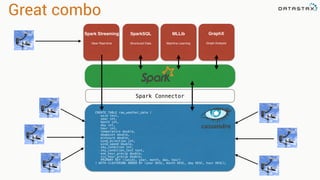
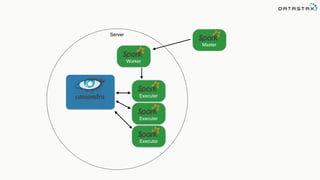
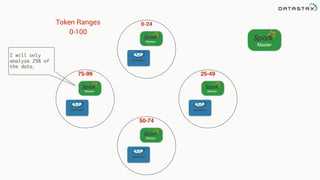
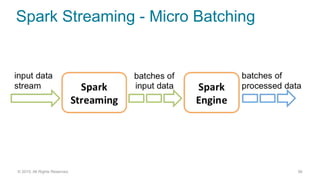





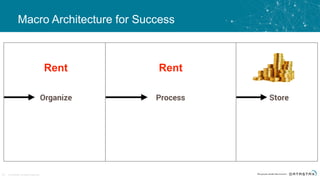
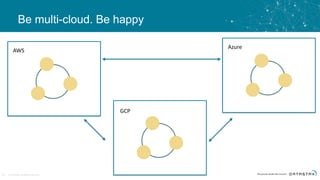




The document discusses the challenges and architecture solutions for handling fast data, which is considered a major issue in data management. It highlights the importance of technologies such as Kafka and Spark for efficient data processing and storage, emphasizing their roles in achieving high availability and scalability. The presentation also addresses the need for a multi-cloud strategy to ensure flexibility and reliability in data architecture.




















































































