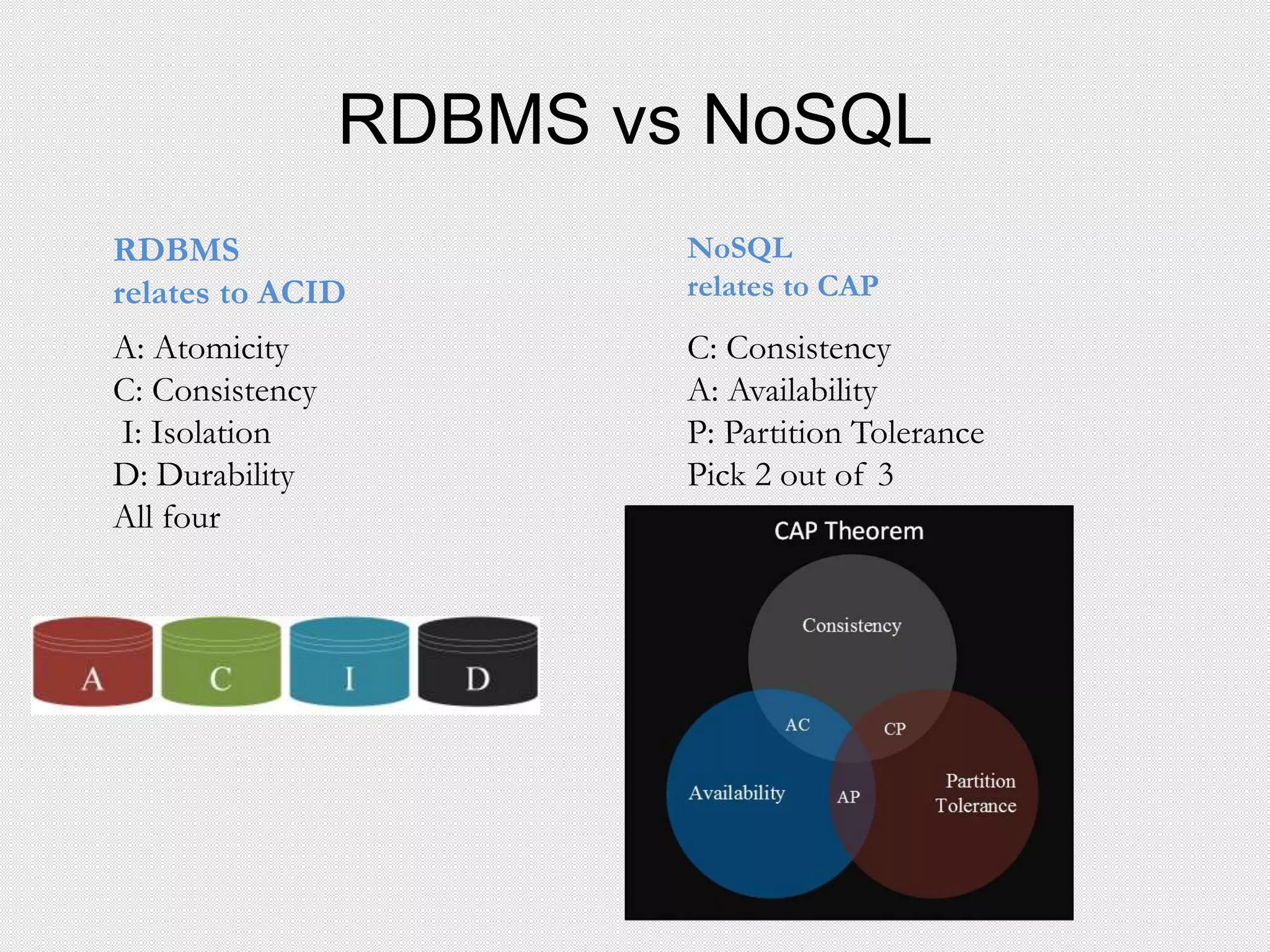
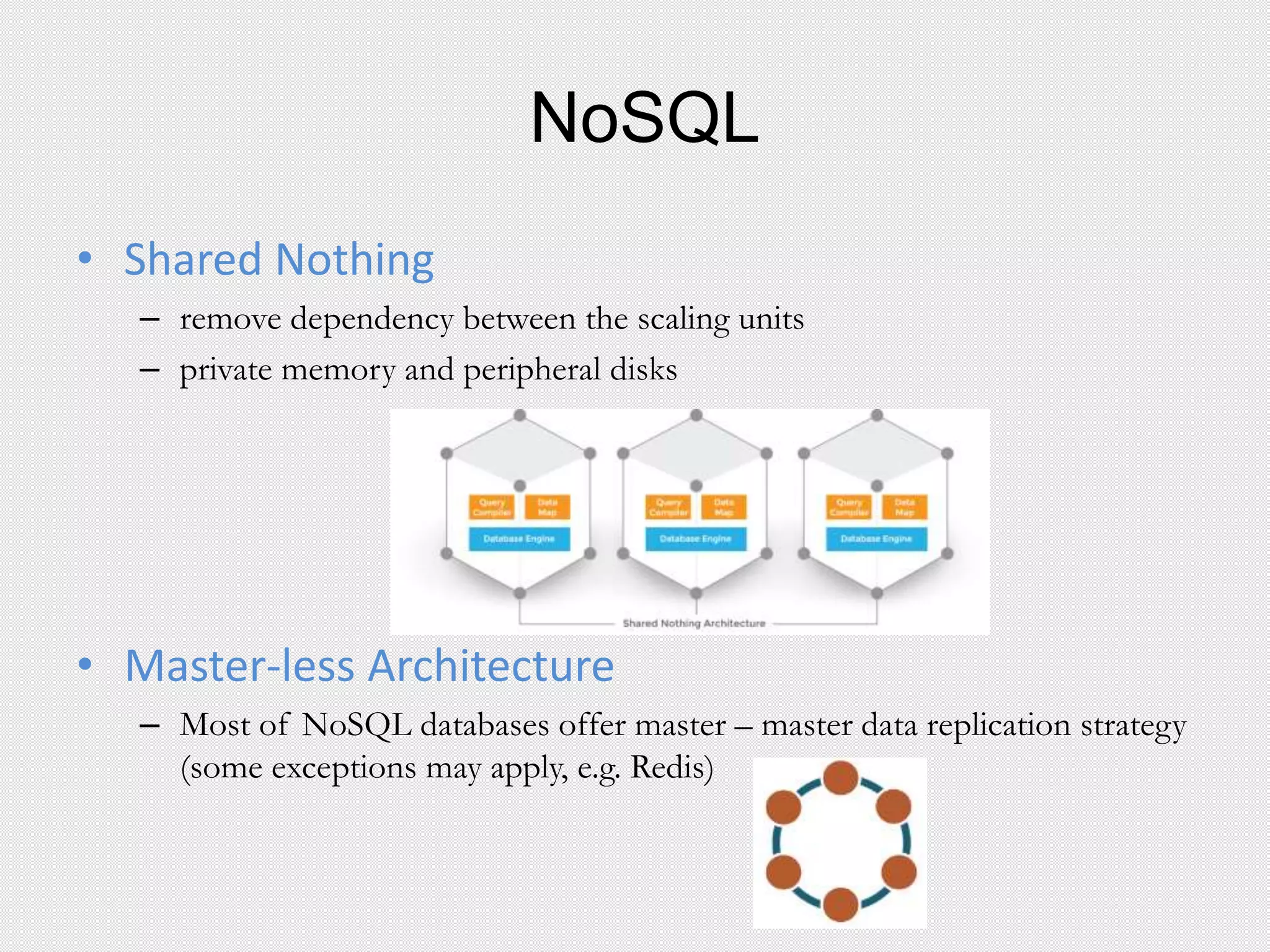
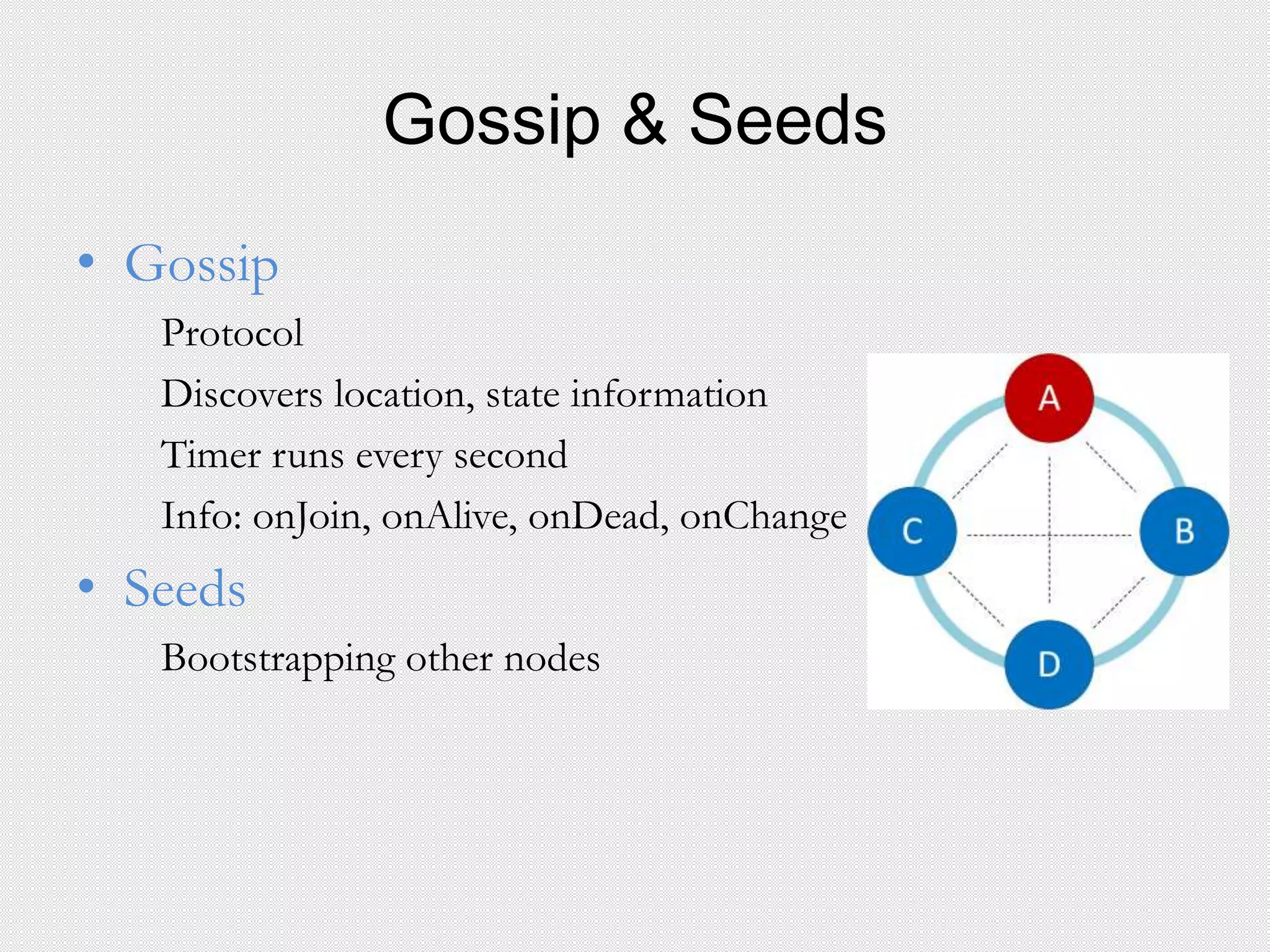
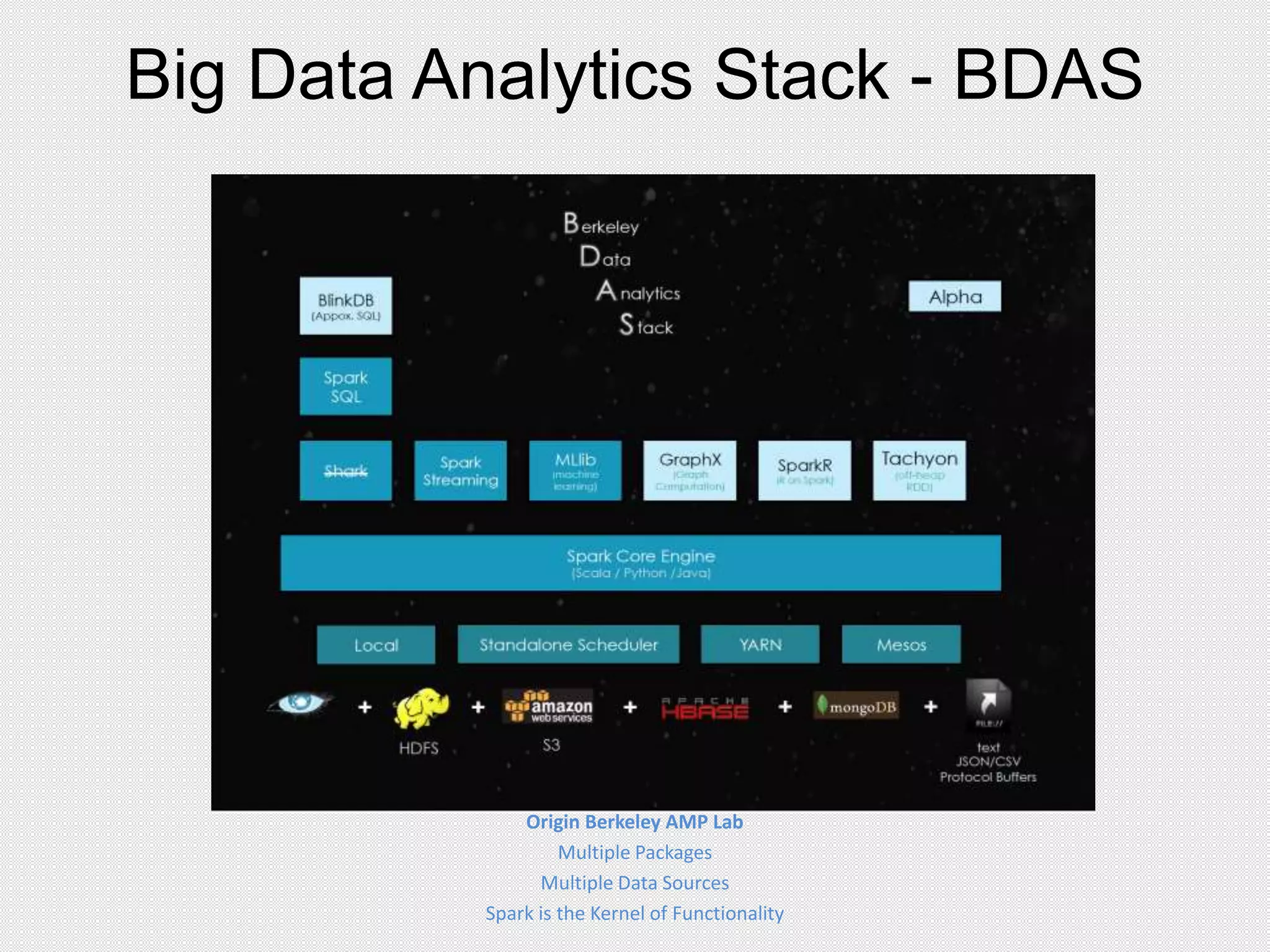
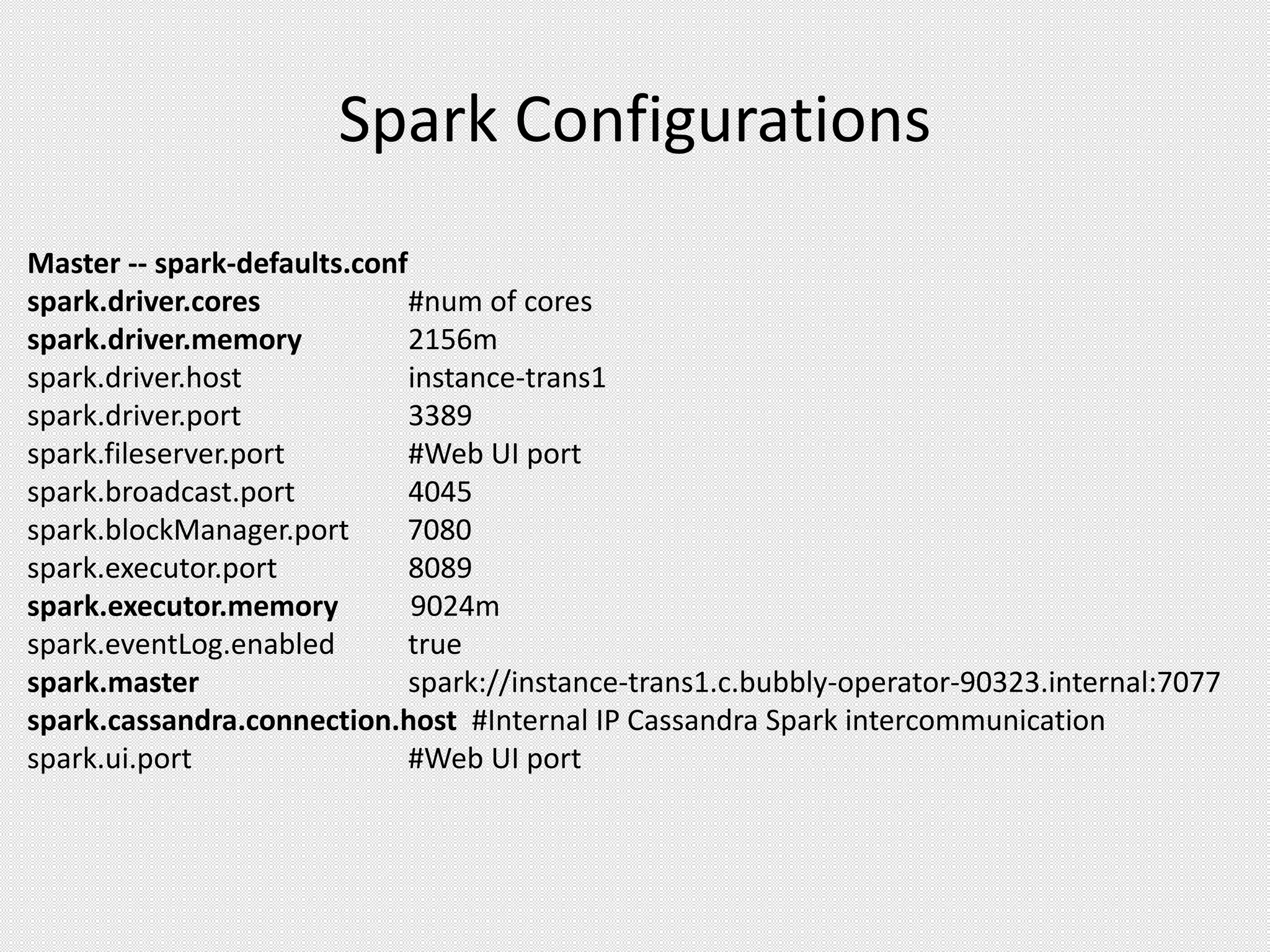
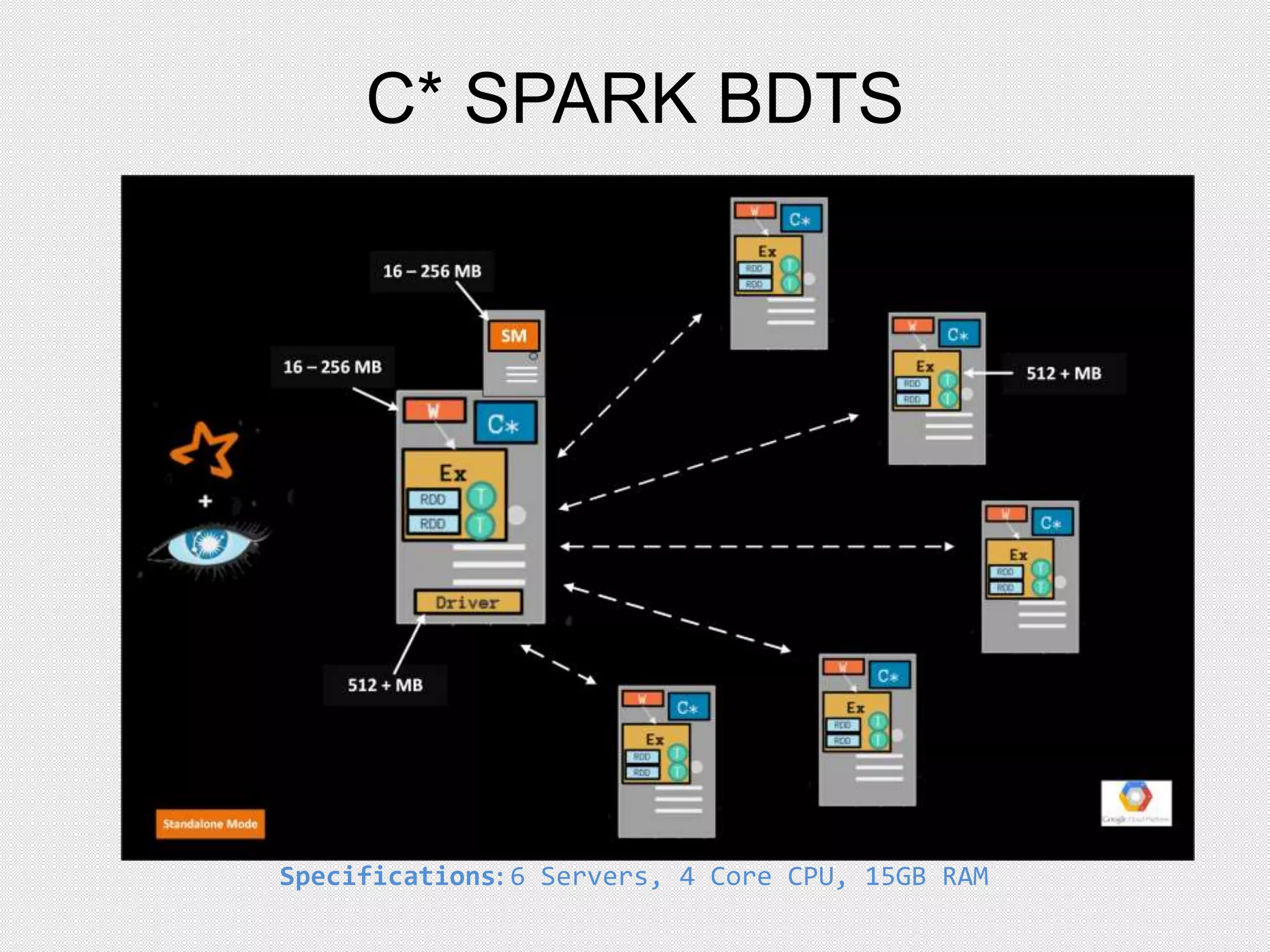
This document provides an agenda for a presentation on integrating Apache Cassandra and Apache Spark. The presentation will cover RDBMS vs NoSQL databases, an overview of Cassandra including data model and queries, and Spark including RDDs and running Spark on Cassandra data. Examples will be shown of performing joins between Cassandra and Spark DataFrames for both simple and complex queries.






![Partitioners
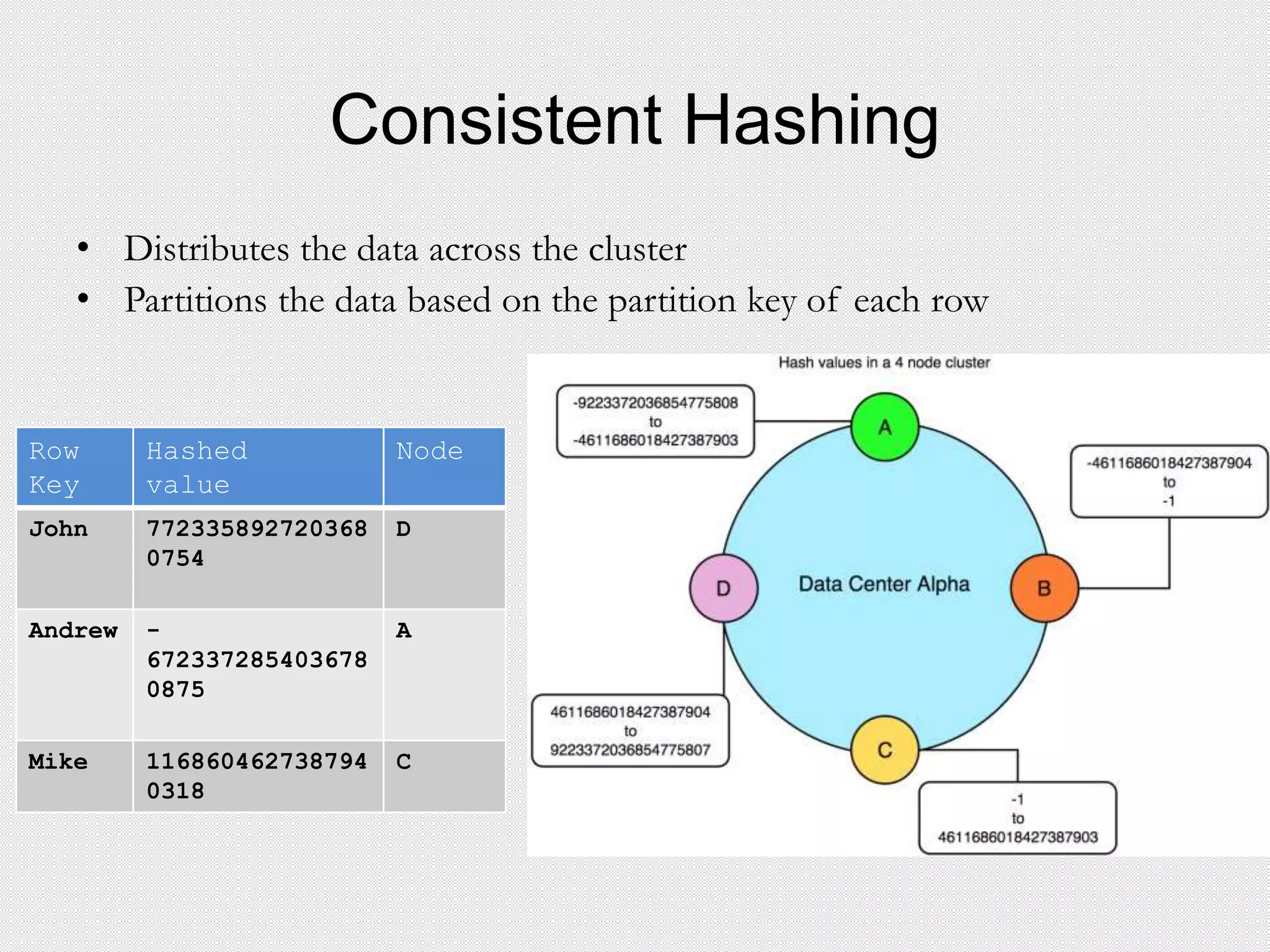
• Defines the Hash function for Consistent Hashing
• Compute the token for each row key
Types
Murmur3Partitioner
Values: [ -263 … 0 …. +263 ]
Random Partitioner
Values: [ 0…2127 – 1 ]
ByteOrderedPartitioner (Not Recommended)](https://image.slidesharecdn.com/presentationfinal-150629023645-lva1-app6892/75/Presentation-11-2048.jpg)





![C* Data Model
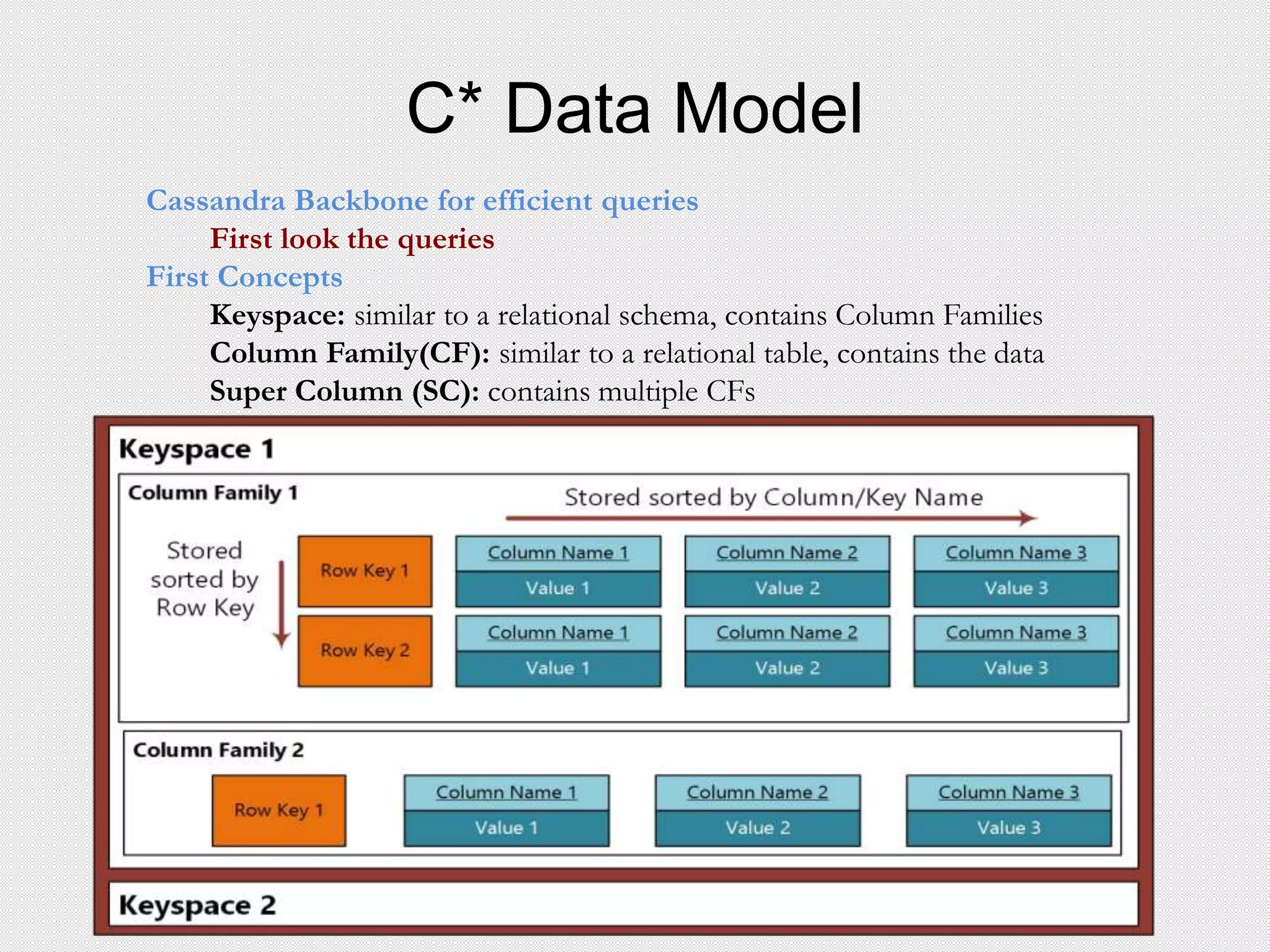
Next Concepts
– Column based key value store (multi level dictionary)
– Think of it as a JSON representation or Map [String, Map [String, Data] ]
– SST: Sorted String Table
Column Family
| Columns
↓ |
{"Street Monitor": ↓
{"Hollywood": { "avg.speed": 75,
↑ "vehicles": 45,
| "time": "2015-03-02 09:35” }
| ↑
Keys |
| Values
↓
{"Santa Monica": { "avg_speed": 35,
"vehicles": 50,
"time": "2015–03–02 10:35"
}
}](https://image.slidesharecdn.com/presentationfinal-150629023645-lva1-app6892/75/Presentation-20-2048.jpg)



![C* Queries
• Pure CQL does not support:
JOINS, and Sub queries || GroupBy and OrderBy only on clustering columns
• No Aggregate Functions supported at Cassandra 2.0.+, later versions will
• Always need to restrict the preceding part of subject
Guidelines:
Partition key columns support the = operator
The last column in the partition key supports the IN operator
Clustering columns support the =, >, >=, <, and <= operators
Secondary index columns support the = operator
Query1 – Some parts of Partition key
SELECT * FROM highway.street_monitoring WHERE onstreet=‘I-10’ AND month=3
Error Message: cassandra.InvalidRequest: code=2200 [Invalid query] message="Partition key part year must be
restricted since preceding part is”
Query2 – Full partition key
SELECT * FROM highway.street_monitoring WHERE onstreet=‘I-10’ AND year=2015 AND month
IN(2,4)
Error Message: None](https://image.slidesharecdn.com/presentationfinal-150629023645-lva1-app6892/75/Presentation-24-2048.jpg)
![C* Queries
Query3 – Range on Partition Key
SELECT * FROM highway.street_monitoring WHERE onstreet=‘I-10’ AND year=2014 AND
month<=1
Error Message: cassandra.InvalidRequest: code=2200 [Invalid query] message="Only EQ and IN relation are
supported on the partition key (unless you use the token() function)"
Query4 – Only secondary index
SELECT * FROM highway.street_monitoring WHERE day>=2 AND day<=3
Bad Request: Cannot execute this query as it might involve data filtering and thus may have unpredictable
performance. If you want to execute this query despite the performance unpredictability, use ALLOW
FILTERING
Query5 – Range on Secondary Index
SELECT * FROM highway.street_monitoring WHERE onstreet='47' AND year=2014 AND month=2
AND day=21 AND time>=360 AND time<=7560 AND speed>30
Error Message: cassandra.InvalidRequest: code=2200 [Invalid query] message="No indexed columns present in
by-columns clause with Equal operator"](https://image.slidesharecdn.com/presentationfinal-150629023645-lva1-app6892/75/Presentation-25-2048.jpg)



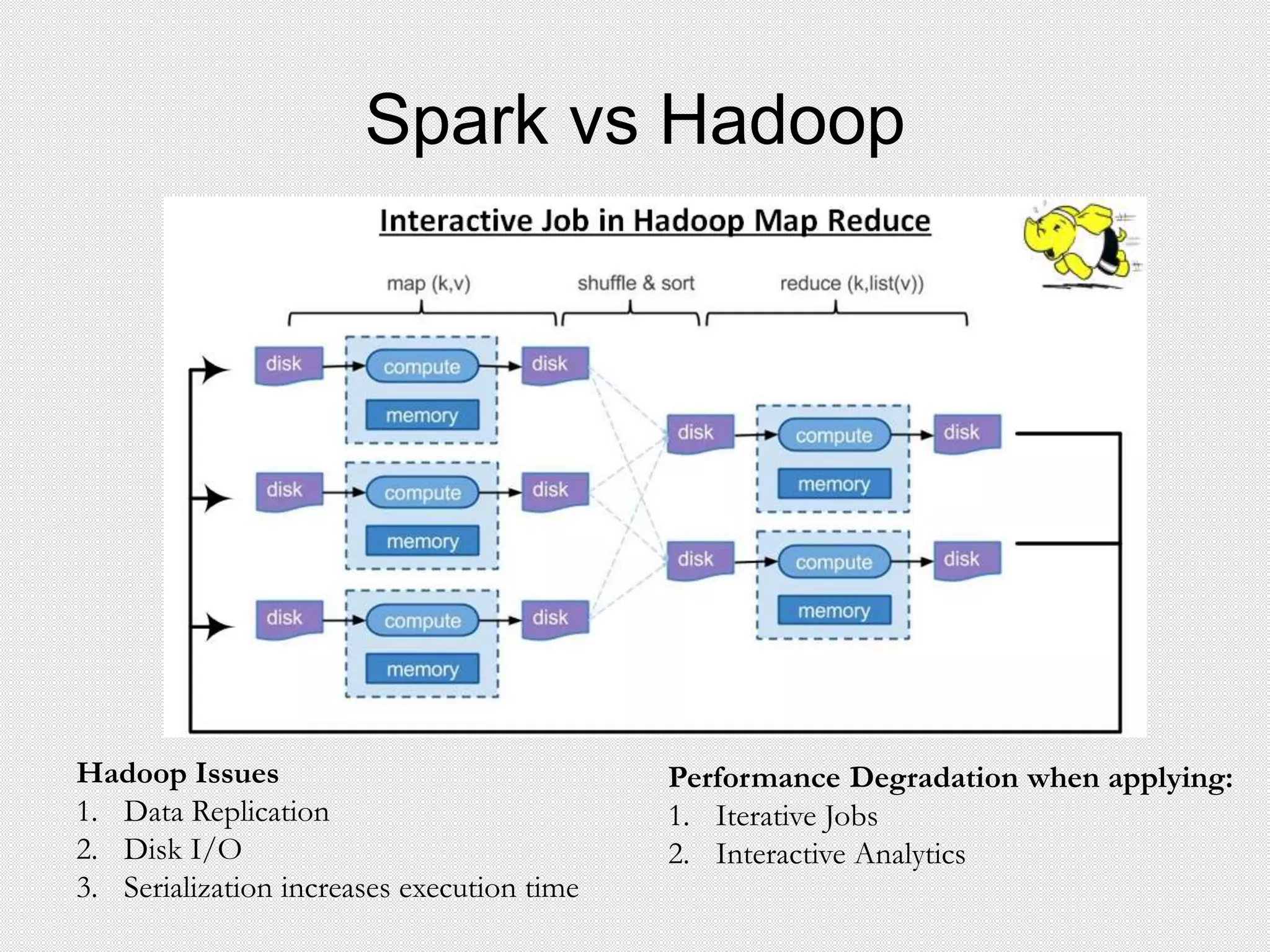

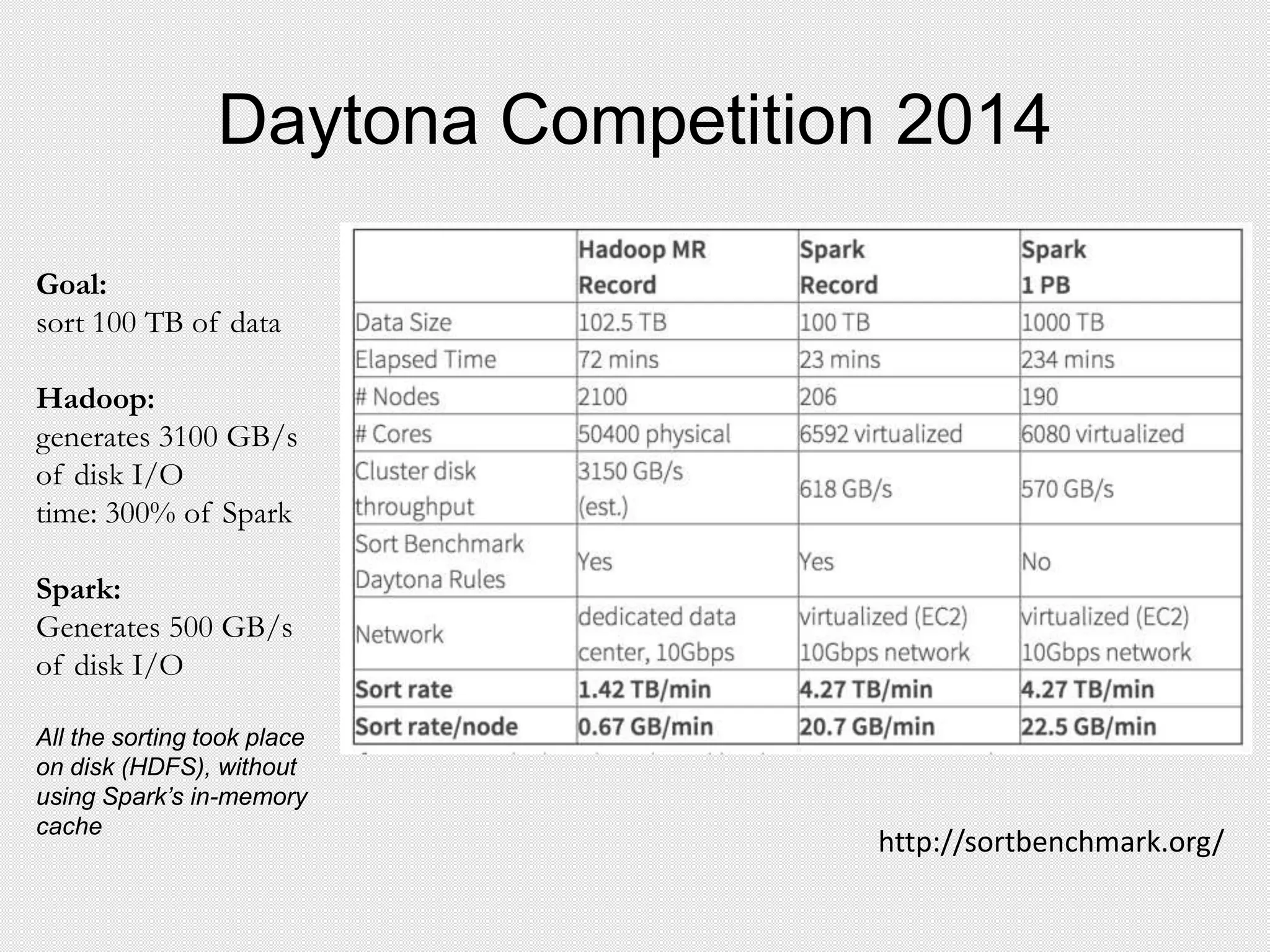
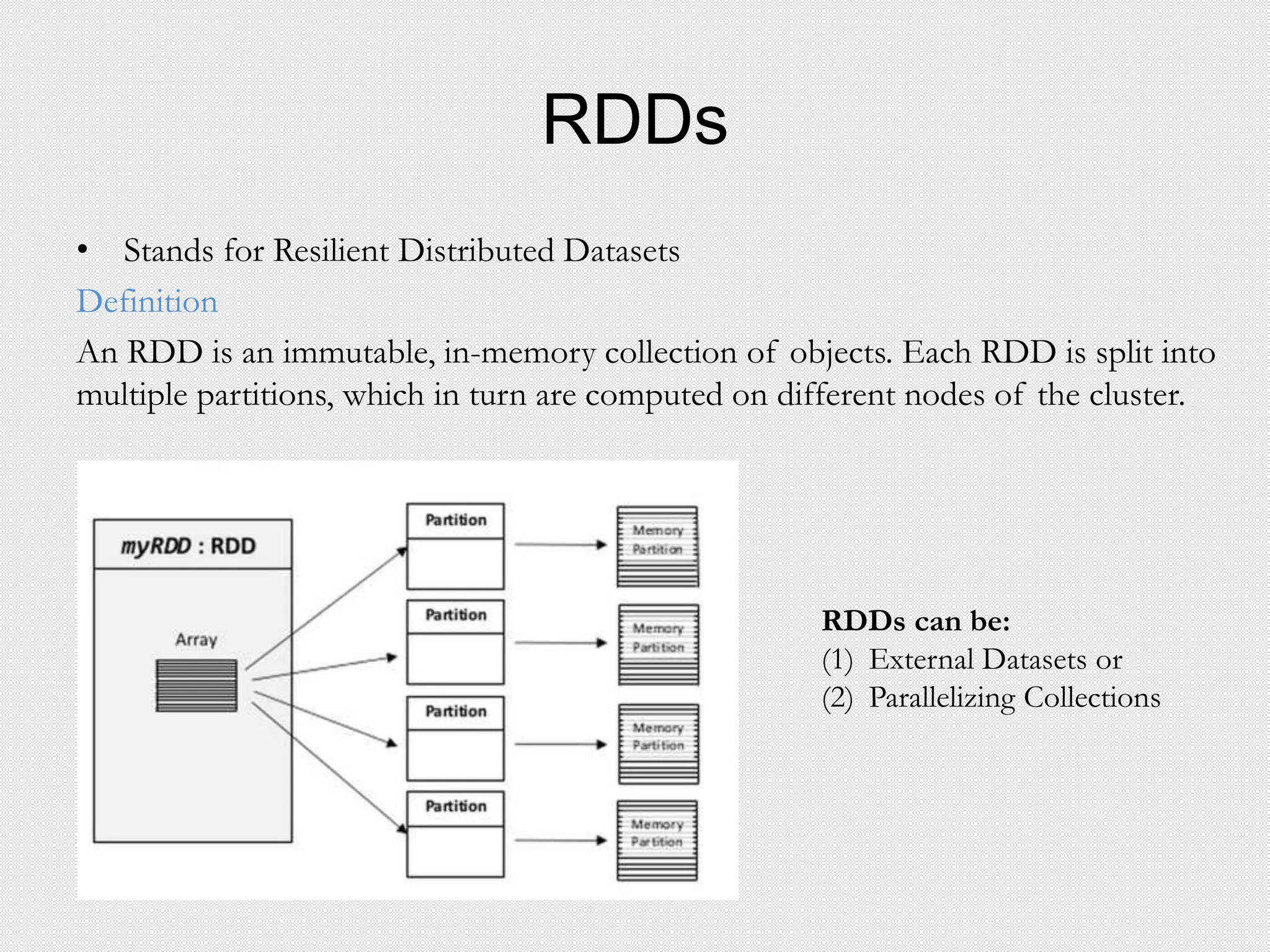


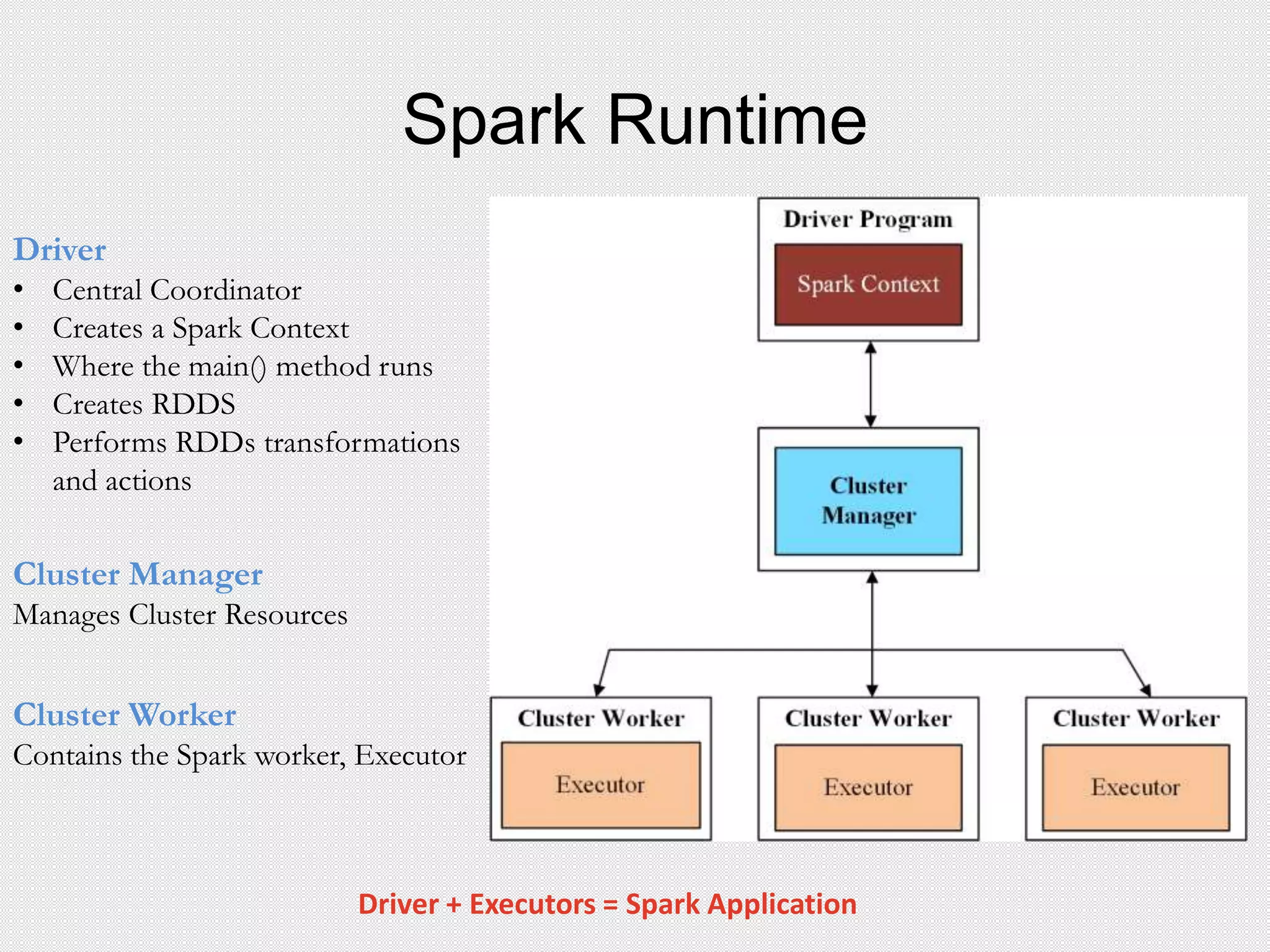

![Executors
• Properties
Worker Processes
Launch at the start
Die when application ends
• Mission
1. Run individual Tasks &
return results to the Spark Driver
2. In memory storage for the RDDs
[ .cache() | .persist() ]](https://image.slidesharecdn.com/presentationfinal-150629023645-lva1-app6892/75/Presentation-38-2048.jpg)




























































![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)