Downloaded 60 times



![SELECT * FROM users
WHERE username = ’jbellis’
[empty resultset]
Session 1
SELECT * FROM users
WHERE username = ’jbellis’
[empty resultset]
Session 2
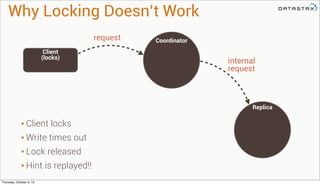
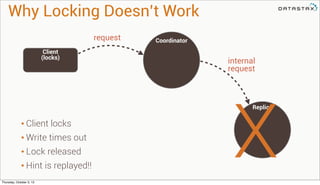
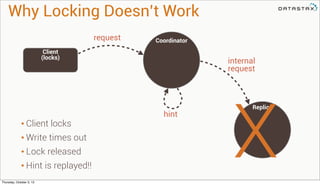
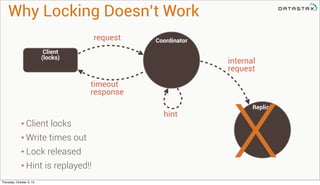
Lightweight transactions: the problem
INSERT INTO users
(username,password)
VALUES (’jbellis’,‘xdg44hh’)
INSERT INTO users
(userName,password)
VALUES (’jbellis’,‘8dhh43k’)
It’s a Race!
Who wins?
Thursday, October 3, 13](https://image.slidesharecdn.com/cassandra2-131011113742-phpapp02/85/Cassandra-2-0-better-faster-stronger-4-320.jpg)


![Triggers
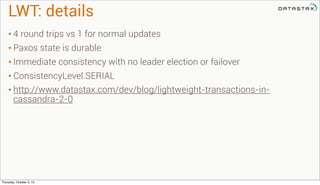
CREATE TRIGGER <name> ON <table> USING <classname>;
DROP TRIGGER <name> ON [<keyspace>.]<table>;
• Executed on the coordinator before mutation
• Takes original mutation and adds any new
• Jars deployed per server
Thursday, October 3, 13](https://image.slidesharecdn.com/cassandra2-131011113742-phpapp02/85/Cassandra-2-0-better-faster-stronger-13-320.jpg)











The document discusses the key features and improvements introduced in Cassandra 2.0, including lightweight transactions for consistency, new triggers for data mutations, and enhanced CQL capabilities. It emphasizes performance upgrades such as faster read times and improved server efficiency, while also noting the removal of certain outdated features. Overall, Cassandra 2.0 offers significant advancements for developers and database management, targeting increased usability and speed.


















































![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










