Downloaded 760 times









…From the Vapor of That Last Big Equation](https://image.slidesharecdn.com/seahugnavebayes24042011v5-110502152529-phpapp01/85/Classification-with-Naive-Bayes-9-320.jpg)
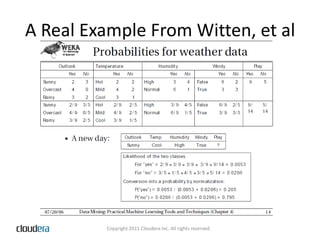


![High Level AlgorithmFor Each Feature(word) in each Doc:Calc: “Weight Normalized Tf-Idf”for a given feature in a label is the Tf-idf calculated using standard idf multiplied by the Weight Normalized TfWe calculate the sum of W-N-Tf-idf for all the features in a label called Sigma_k, and alpha_i == 1.0Weight = Log [ ( W-N-Tf-Idf + alpha_i ) / ( Sigma_k + N ) ]](https://image.slidesharecdn.com/seahugnavebayes24042011v5-110502152529-phpapp01/85/Classification-with-Naive-Bayes-14-320.jpg)










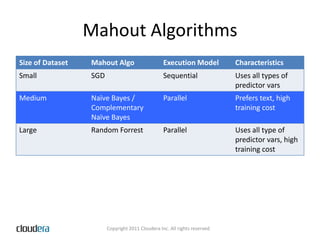
The document discusses classification using Naïve Bayes, focusing on its implementation in Apache Mahout, a scalable machine learning library. It contrasts supervised and unsupervised learning and explains how Naïve Bayes works, including its independence assumptions and application in text classification. It also provides an overview of training workflows, data preparation, and resources for utilizing Mahout effectively.










































































