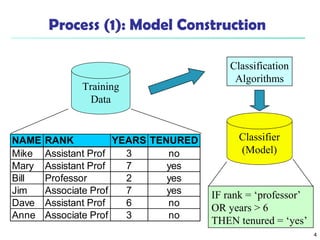
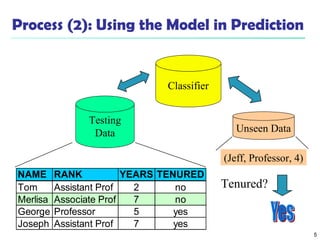
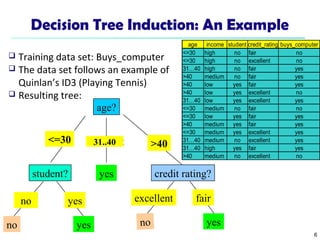
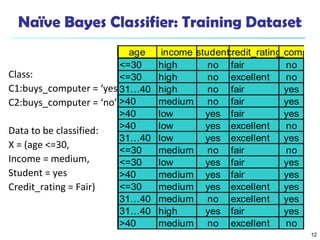
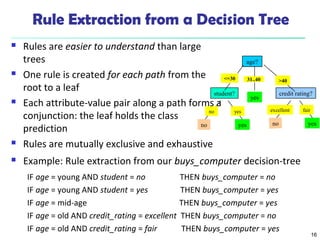
The document discusses various classification techniques in machine learning. It begins by distinguishing between supervised and unsupervised learning, with classification being a form of supervised learning where training data is labeled. It then describes classification as a two-step process of model construction using a training set, and model usage to classify new data. Several specific classification algorithms are covered, including decision trees, naive Bayes classification, and rule-based classification. The document also discusses evaluating classifier accuracy using methods like holdout validation, cross-validation, and bootstrap.