Downloaded 45 times
















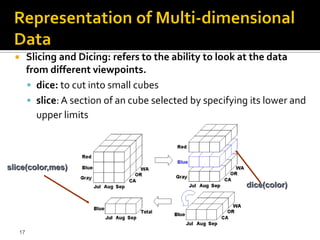






This document discusses data warehousing and multi-dimensional data structures. It explains that multi-dimensional structures store data and relationships in a cube format, with each dimension side of the cube. Cubes allow for pre-aggregation of data to speed up complex queries. Common analytical operations on cubes include consolidation, drill-down, slicing, dicing, and pivoting of the data in the cube. Pre-aggregation and sparse data storage techniques reduce the overall cube size and processing needs.




















































































