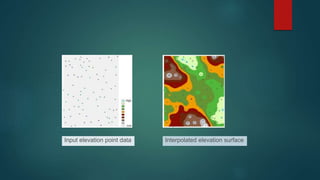
Raster data is represented by a grid of cells, where each cell contains numeric or qualitative values. Raster data comes from sources like images, maps, and satellite imagery. Common analyses of raster data include buffering, reclassification, hillshades, interpolation, and surface calculation. Buffering assigns "in" and "out" values to cells based on their distance from a feature. Reclassification reassigns cell values. Hillshades create shaded relief maps from elevation data. Interpolation estimates values between known data points. Surface calculation performs cell-by-cell mathematical functions on rasters.