Download as PDF, PPTX





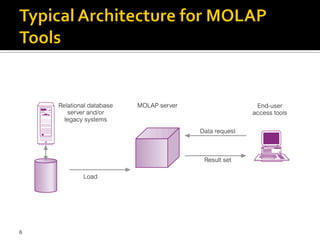

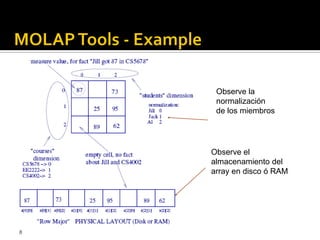



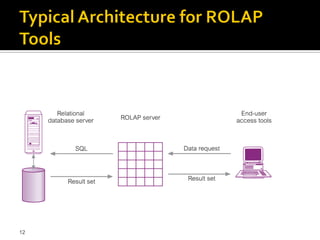



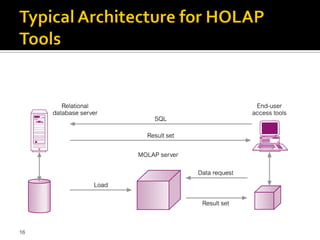




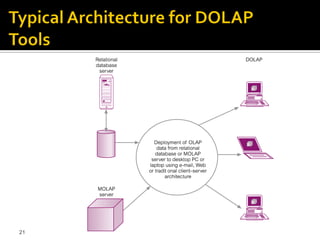




OLAP tools are categorized based on how they store and process multi-dimensional data, with the main categories being MOLAP, ROLAP, HOLAP, and DOLAP. MOLAP uses specialized data structures and MDDBMS to organize and analyze aggregated data for optimal query performance. ROLAP uses relational databases with a metadata layer to facilitate multiple views of data. HOLAP combines aspects of MOLAP and ROLAP. DOLAP provides limited analysis directly from databases or via servers to desktops in the form of datacubes for local storage, analysis and maintenance.


































































































