Downloaded 2,373 times






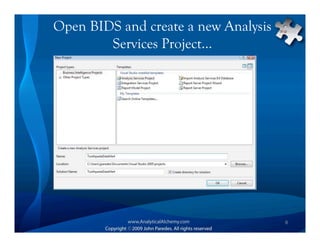
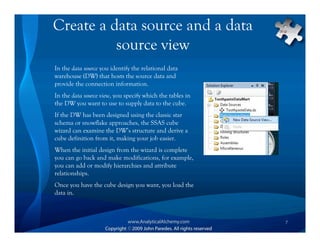
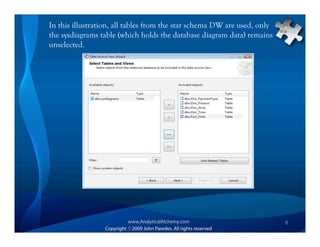

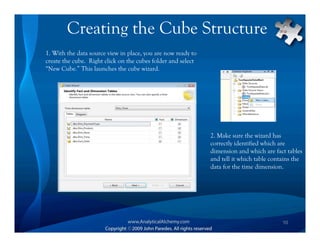
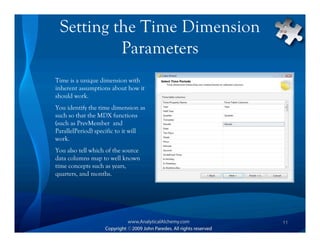
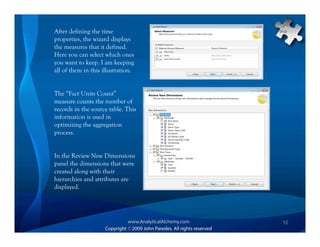
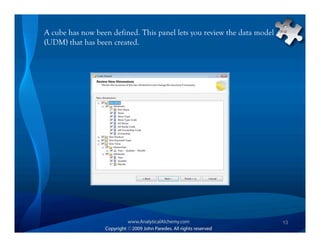
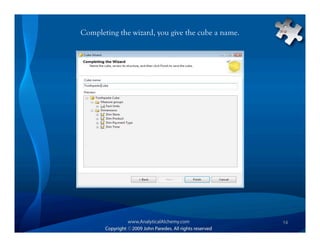
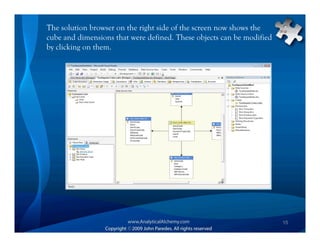
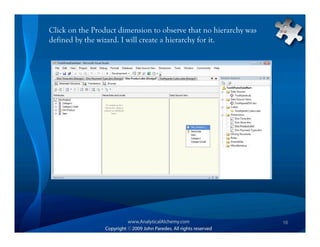
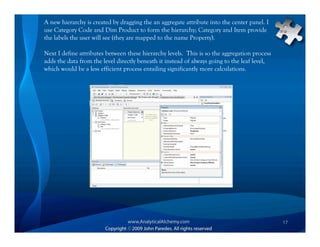
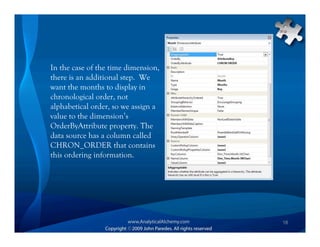


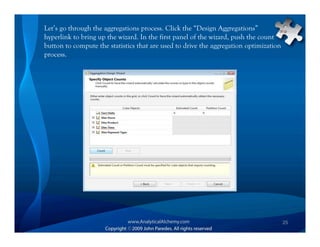
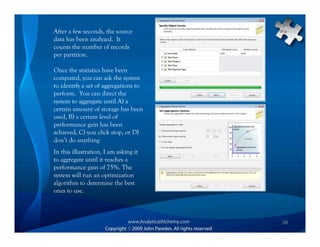
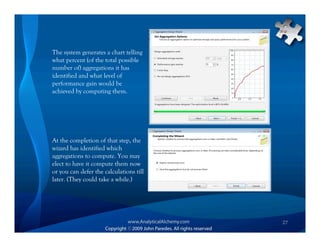
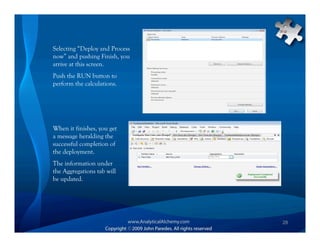


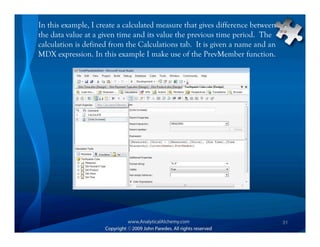



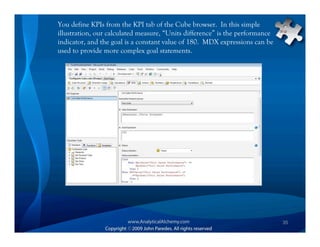
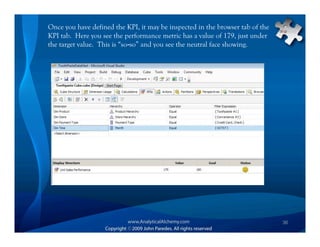

This document provides an overview of Analysis Services and how to create an OLAP cube. It discusses why data is stored in cubes rather than tables, including better query performance, efficient storage and calculations. It then outlines the steps to create an Analysis Services project, define data sources and dimensions, create and process the cube, and optimize query performance through partitioning and pre-aggregating data.



































































